
Ссылка на репозиторий GitHub.
О себе
Здравствуйте, меня зовут Ыдырыс Олжас. Учусь на 3 курсе в Национальном исследовательском технологическом университете “МИСИС” по специальности металлургия, но также в свободное время я изучаю Data Science. Данный проект я реализовал, чтобы показать насколько эффективно можно применять методы машинного обучения для оптимизации и улучшения металлургических процессов. Так что давайте я начну с маленькой теоретического введения.
Примечание: Не всегда легко найти базы данных реальных производственных предприятий, особенно металлургических. Надеюсь что данная статья поможет развитию такого узкого направления и крупные предприятия начнут выкладывать данные для учебной практики.
Введение
Железные руды — это горные породы и минералы, из которых можно экономично извлечь металлическое железо. Кремнезем является основной примесью в железной руде. Высокое ее содержание может привести к большому объему шлака. Это, в свою очередь, приводит загрязнению окружающей среды. Прогнозируя содержание примеси в руде, мы можем помочь инженерам на заводе проводить необходимые расчеты на ранних стадиях производства.
Прогнозирование содержания кремнезема включает в себя множество химических анализов, которые отнимают много времени и требуют больших операционных затрат. Использование ML-моделей упростит наш процесс, решив все наши проблемы одним махом…
Данные
Данные были получены на сайте Kaggle.
# Выводим информацию о датафрейме df.info()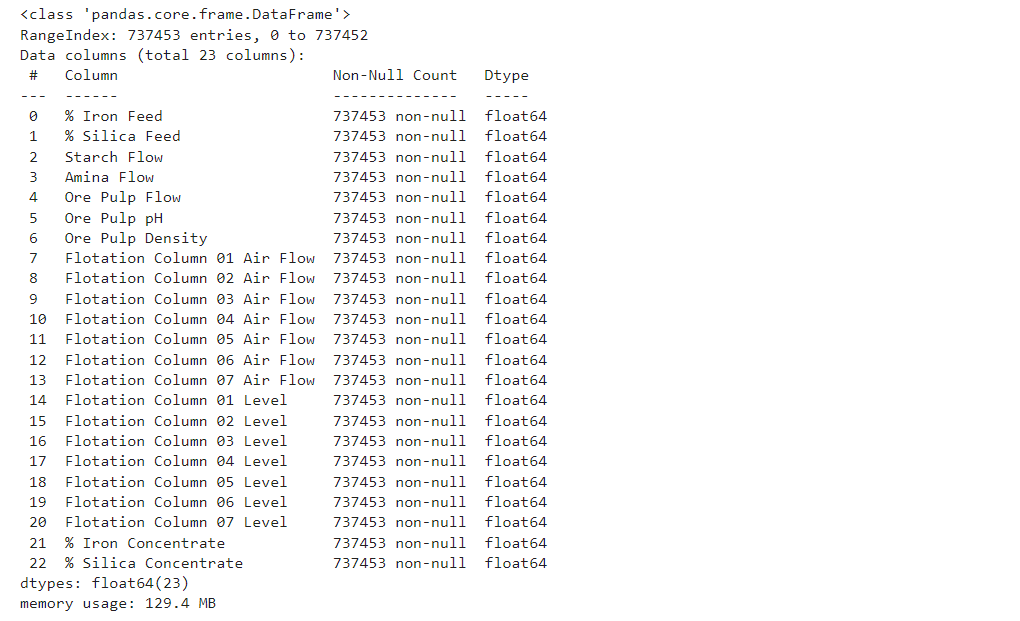
Второй и третий столбец — это показатели качества железорудной пульпы непосредственно перед ее подачей на флотационную установку. Столбцы с четвертого по восьмой — это наиболее важные переменные, которые влияют на качество исходной продукции в конце процесса. С столбца 9 по столбец 22 мы можем видеть данные процесса (уровень и поток воздуха внутри флотационных колонн, которые также влияют на качество процесса. Последние два столбца — это окончательные измерения качества пульпы железной руды, полученные в лаборатории. Цель — предсказать последний столбец, который представляет собой процент кремнезема в железорудном концентрате.
Разведочный анализ данных
Разведочный анализ данных (EDA) — это подход к анализу наборов данных для обобщения их основных характеристик, часто с использованием визуальных методов.
# Выводим статистическую информацию df.describe()
В первую очередь я рассмотрел статистическую информацию для этого я применил метод df.describe(). Из выведенного столбца мы можем увидеть что максимальный процент кремнезема после флотации равно 5.5%, а минимальное 0.6%. Процент железного концентрата после флотации 62-68%.
Гистограмма столбцов
С помощью гистограмм мы можем более наглядно увидеть статистическую информацию.
df.hist(figsize= (20,20)) plt.show("png")
Матрица корреляций
Коэффициент корреляции характеризует величину отражающую степень взаимосвязи двух переменных между собой. Из этой диаграммы можно сделать вывод, что существует взаимосвязь между железным сырьем и кремнеземом. Также существует связь между концентратом кремнезема и концентратом железа.
plt.figure(figsize=(18,18)) sns.heatmap(df.corr(), annot=True) plt.show("png")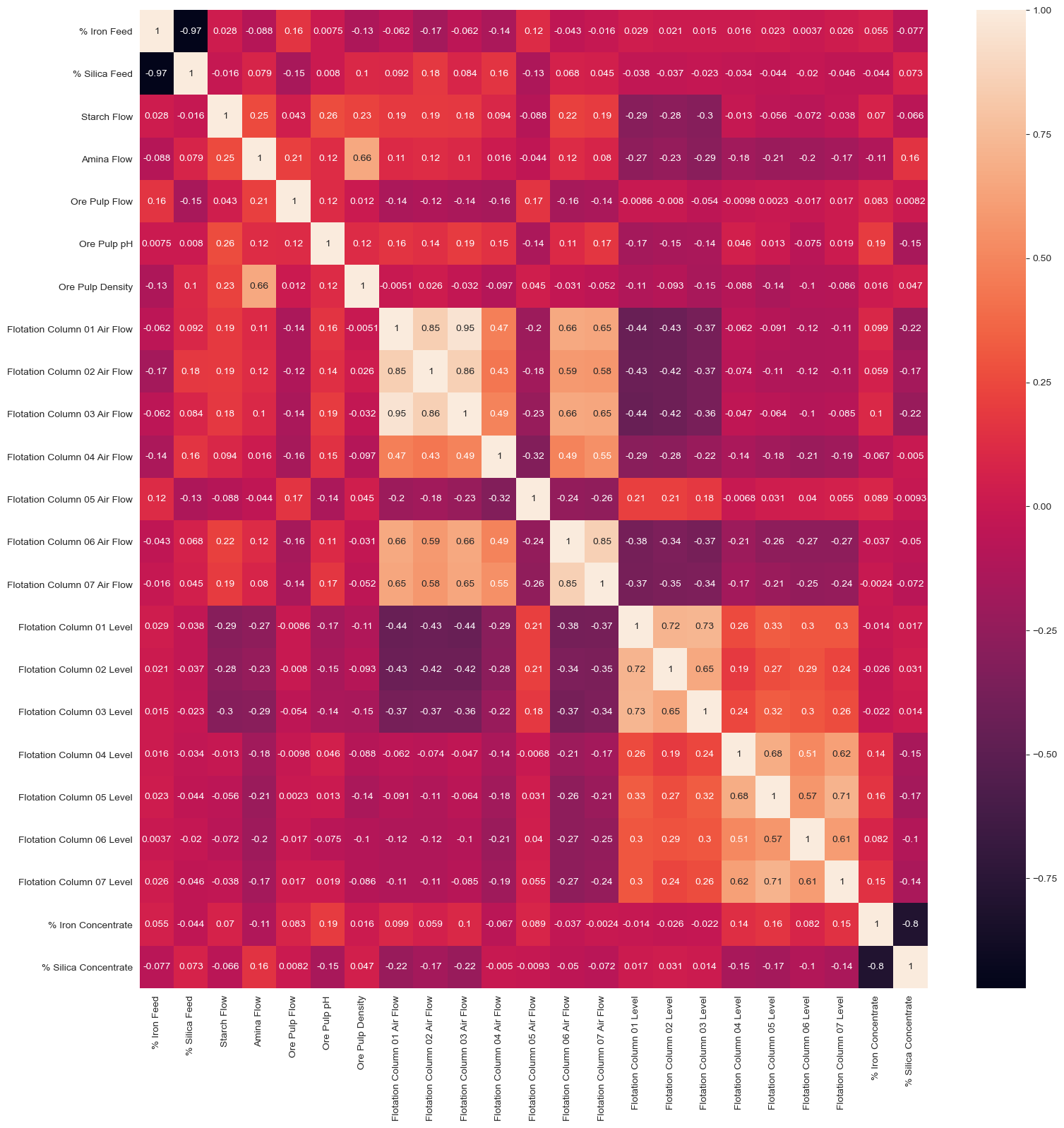
Строим и оцениваем модель
В этом практическом проекте я буду использовать LightGBM и Optuna для лучшей эффективности модели. Также для оценки модели я и использовал перекрестную проверку, что поможет мне избежать переобучения модели.
LightGBM
LightGBM — это фреймворк, который предоставляет реализацию деревьев принятия решений с градиентным бустингом. Он создан группой исследователей и разработчиков Microsoft. Основные преимуществами:
-
Более высокая скорость обучения и высокая эффективность.
-
Меньшее использование памяти.
-
Более высокая точность.
-
Поддержка параллельного, распределенного и GPU-обучения.
-
Возможность работы с большими объемами данных.
Optuna
Optuna — это программный фреймворк для автоматической оптимизации гиперпараметров, разработанный специально для машинного обучения.
-
Масштабируемость
-
Параллелизация вычислении
-
Быстрая визуализация
from optuna.integration import LightGBMPruningCallback import optuna from sklearn.metrics import mean_squared_error from sklearn.model_selection import KFold import lightgbm as lgbm EPS = 1e-8 # Создаем функцию objective для optuna def objective(trial, X, y): # Параметры обучения param_grid = { "verbosity": -1, "boosting_type": "gbdt", "n_estimators": trial.suggest_categorical("n_estimators", [10000]), "learning_rate": trial.suggest_categorical("learning_rate", [0.0125, 0.025, 0.05, 0.1]), "num_leaves": trial.suggest_int("num_leaves", 2, 2048), "max_depth": trial.suggest_int("max_depth", 3, 12), "min_data_in_leaf": trial.suggest_int("min_data_in_leaf", 1, 100), "lambda_l1": trial.suggest_float("lambda_l1", 1e-8, 10.0, log=True), "lambda_l2": trial.suggest_float("lambda_l2", 1e-8, 10.0, log=True), "min_gain_to_split": trial.suggest_float("min_gain_to_split", 0, 15), "bagging_fraction": min(trial.suggest_float("bagging_fraction", 0.3, 1.0 + EPS), 1.0), "bagging_freq": trial.suggest_int("bagging_freq", 1, 7), "feature_fraction": min(trial.suggest_float("feature_fraction", 0.3, 1.0 + EPS), 1.0), "feature_pre_filter": False, "extra_trees": trial.suggest_categorical("extra_trees", [True, False]), } # Перекрестная проверка cv = KFold(n_splits=5, shuffle=True) # Массив куда мы сохраняем результаты проверки cv_scores = np.empty(5) for idx, (train_idx, test_idx) in enumerate(cv.split(X, y)): X_train, X_test = X.iloc[train_idx], X.iloc[test_idx] y_train, y_test = y[train_idx], y[test_idx] # Создаем регрессионную модель LightGBM model = lgbm.LGBMRegressor( **param_grid) # Обучаем модель model.fit( X_train, y_train, eval_set=[(X_test, y_test)], eval_metric="rmse", early_stopping_rounds=100, callbacks=[ LightGBMPruningCallback(trial, "rmse") ], ) preds = model.predict(X_test) # Сохраняем в массив результаты проверки cv_scores[idx] = mean_squared_error(y_test, preds) return np.mean(cv_scores) # Возращаем среднее значение всех проверок# Создаем новое обучение. study = optuna.create_study(direction="minimize", study_name="LGBM Classifier") func = lambda trial: objective(trial, X, y) # Вызываем оптимизацию функций objective. study.optimize(func, n_trials=20)Для оценки модели я использую метрику RMSE (Среднеквадратическая ошибка)
Для каждой точки вычисляется квадратная разница между прогнозами и целью, а затем усредняются эти значения и возводится в корень. Чем выше это значение, тем хуже модель.
print(f"\tНаилучшее значение (rmse): {study.best_value:.5f}") print(f"\tНаилучшие параметры:") for key, value in study.best_params.items(): print(f"\t\t{key}: {value}") -------------------------------------------------------------------------------- Наилучшее значение (rmse): 0.01053 Наилучшие параметры: n_estimators: 10000 learning_rate: 0.025 num_leaves: 628 max_depth: 11 min_data_in_leaf: 1 lambda_l1: 1.970304366797382e-06 lambda_l2: 3.183217431386711e-08 min_gain_to_split: 0.06980772043041306 bagging_fraction: 0.9383496311685677 bagging_freq: 7 feature_fraction: 0.978126829339409 extra_trees: FalseЗаключение
На основании проведённых исследований мы можем увидеть насколько эффективно применять методы машинного обучения в отличие от лабораторных исследований. Потратив час на написание кода и обучения модели мы получаем невероятную точность предсказании (99%).
Ссылки
ссылка на оригинал статьи https://habr.com/ru/post/652835/
Добавить комментарий