
Это вторая часть статьи про голосового помощника. Первую часть можно наути тут.
База данных
Теперь про сохранение вопросов и ответов. Структура данных Trie хорошо подходит, чтобы быстро определять есть ли у нас такой вопрос в базе и каков ответ. Для хранения узлов дерева и связей между ними я воспользовался графовой базой данных Dgraph. Я создал бесплатное облачное хранилище на dgraph.io. Схема для TrieNode выглядит следующим образом:
type TrieNode { id: ID! text: String! isEnd: Boolean! isAnswer: Boolean! isRoot: Boolean! @search nodes: [TrieNode] }Параметр search нужен, чтобы это поле индексировалось и можно было быстро найти корень дерева запустив запрос:
const query = ` query { roots(func: eq(TrieNode.isRoot, true)) { uid } } `;Для отправки запросов я воспользовался библиотекой dgraph-io/dgraph-js-http, а для получения всех дочерних элементов для узла запросом:
const query = ` query all($a: string) { words(func: uid($a)) { uid TrieNode.nodes { uid TrieNode.text TrieNode.isAnswer TrieNode.isEnd TrieNode.isRoot } } } `;Это всё, что потребовалось, чтобы обходить дерево в глубину. В случае, если вопрос заканчивается словом, для которого существует узел со свойством isEnd равным true, ответом будет его дочерний элемент со значением true для поля isAnswer. Кроме результатов запроса dgraph-js-http возвращает дополнительную информацию в поле extensions, например server_latency, которое можно мониторить по ходу наполнения базы данных большим количеством узлов.
Чтобы настроить доступ сервиса к базе данных нам нужен URL, его можно найти наверху главной страницы хранилища.
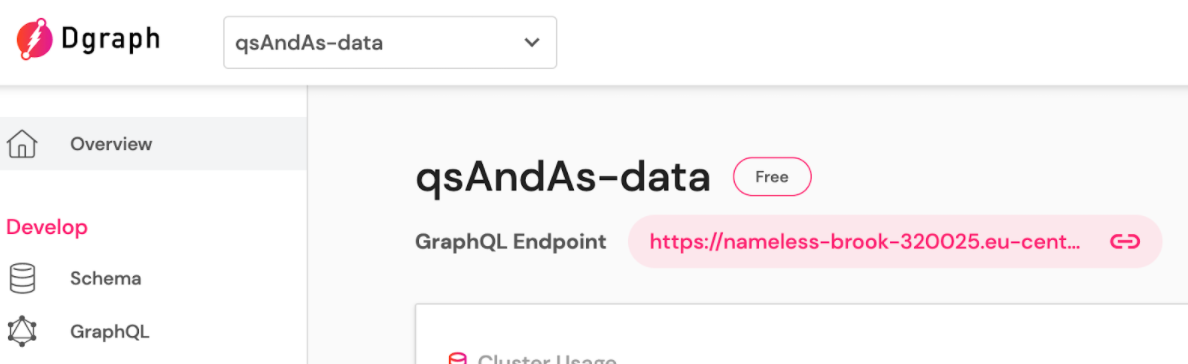
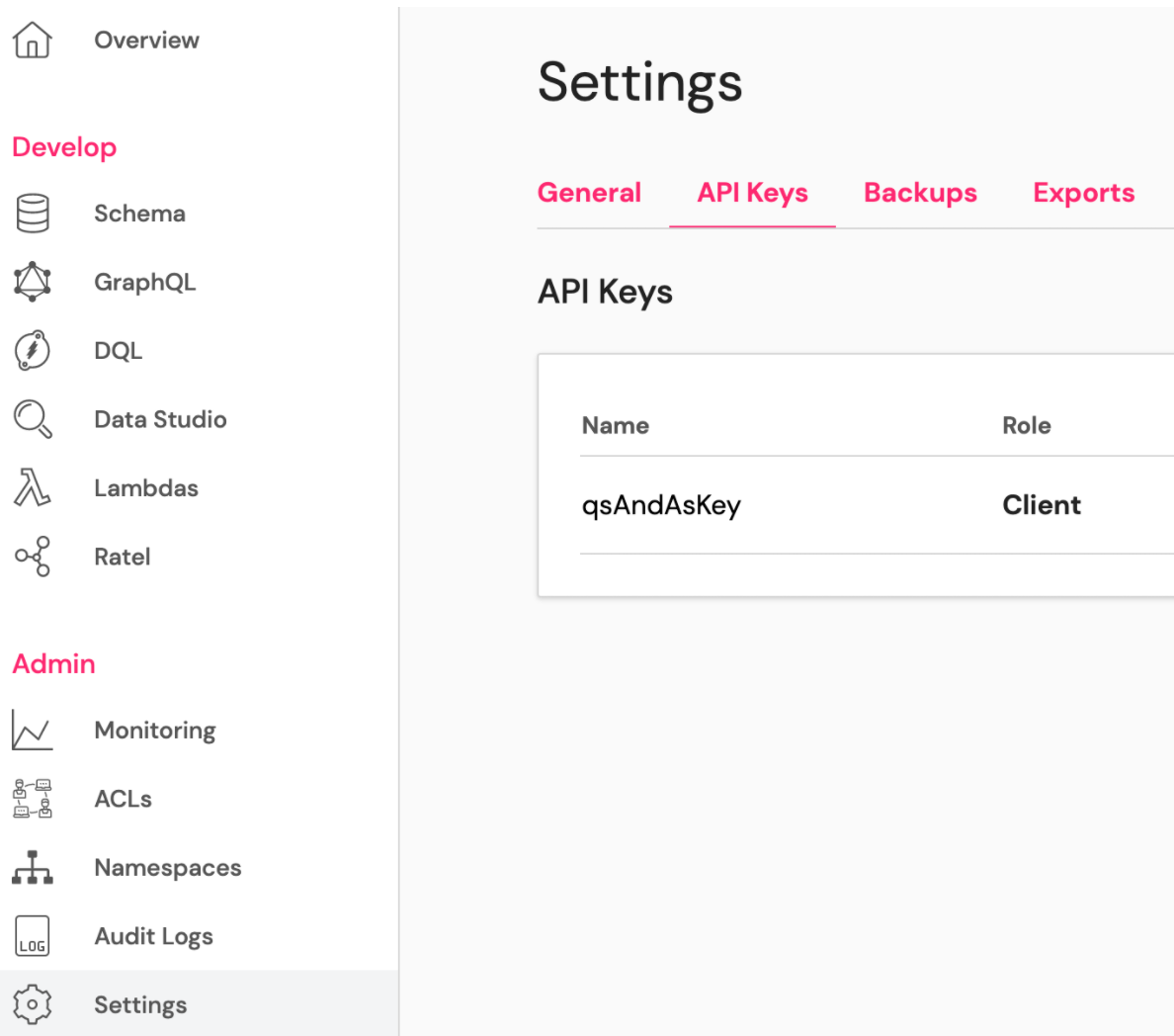
Второй необходимый параметр — это API ключ. Его нужно создать в разделе Settings, во вкладке API Keys:
Docker и Nginx
Для удобства разработки, я добавил docker и nginx. Соответствующие файлы конфигураций можно найти в github репозиторие qsAndAs. Три значения в разделе environment для сервиса, которые нужно заполнить, чтобы всё заработало — это
-
DGRAPH_HOST — URL к cloud.dgraph.io хранилищу с деревом вопросов и ответов без /graphql в конце, примерно так: https://somthing.something.eu-central-1.aws.cloud.dgraph.io;
-
DGRAPH_KEY — API ключ от cloud.dgraph.io хранилища;
-
GOOGLE_APPLICATION_CREDENTIALS — Путь к json файлу с ключом от google cloud проекта;
Ненормативная лексика
Нецензурные слова и выражения я решил взять из английского языка.
Для начала я проверил насколько Text-to-Speech защищён от использования английского мата. Заменил фразу “I don’t have an answer for you!” на “F**k off! I don’t have an answer for you!” и получил корректный аудио файл без какой-либо цензуры. Потоя я спросил “why did that son of a b*tch insult my family?” и опять получил полную расшифровку. Потом я попробовал несколько фраз из отрывка “Tony, you motherfkers!” из известного сериала и опять всё получилось.
Вместо заключения
-
За всё время создания и тестирования моего проекта я не заплатил ни копейки;
-
За исключением случаев, когда аудио, которое отправлялось на расшифровку, я сам едва ли мог понять, Speech-to-Text отработал на отлично;
-
Я попробовал расшифровать часовой диалог программистов, загрузив его в Google Cloud Storage. Результат получился не безупречным, но наличие возможности добавить адаптивные модели к расшифровке должно улучшить результат;
-
Работать с google cloud было удобно, как через веб-интерфейс, так и через gcloud CLI, но я предпочитаю интерфейс;
-
Приятно удивило меня наличие бесплатного аккаунта в облаке для Dgraph;
-
Веб-интерфейс Dgraph оказался удобным, а возможность играть с запросами и мутациями через Ratel очень ускорила моё обучение. Должен сказать, что до этого я не имел возможности попробовать графовые базы данных;
-
По трудоёмкости, оказалось, что рабочий прототип можно сделать за одни выходные. А с учётом наличия рабочих примеров для обращения к google cloud для Go, Java, Python и Node.js, технологии для прототипа можно выбрать из очень широкого списка;
-
В дальнейшем можно заменить Trie на классификатор текста в Vertex AI;
ссылка на оригинал статьи https://habr.com/ru/post/655867/
Добавить комментарий