
Fix by MacRebisz
Привет, я Андрей Квапил, Solution Architect в компании «Флант». Моя специализация — архитектурные решения на базе Kubernetes, в том числе на bare metal, а также разработка и эксплуатация облачных платформ и software-defined storage.
В Kubernetes часто можно столкнуться с ограничениями, immutable-полями и прочими особенностями. Я хочу показать, что при необходимости такие ограничения можно обходить, а также познакомить вас с паттерном controller и наглядно продемонстрировать работу CNI-, CSI- и CRI-плагинов.
Статья написана на основе моего выступления на VK Kubernetes Conference, вы можете посмотреть его в записи.
Начнем с базы: составляющие Kubernetes и принципы его работы
Kubernetes — расширяемая платформа для управления контейнеризированными рабочими нагрузками и сервисами, которая облегчает декларативную настройку и автоматизацию.

Компоненты Kubernetes
Kubernetes построен на микросервисной архитектуре, в которой каждый компонент играет отдельную роль. Разберем подробнее его устройство.
Kubernetes API — сердце нашего кластера, он состоит из двух компонентов:
- kube-apiserver — главный компонент, в котором хранятся все ресурсы;
- etcd — key-value-база данных, в которой kube-apiserver хранит информацию и состояние созданных ресурсов.
Еще в Kubernetes есть контроллеры, которые взаимодействуют с API:
- kube-scheduler — основной шедулер ресурсов;
- kube-controller-manager — контроллер, который обслуживает логику для всех стандартных ресурсов кластера;
- kubelet — работает на каждой ноде и запускает контейнеры.
Разумеется, контроллеров может быть и больше. По сути, любой компонент, который подписывается и следит за изменениями ресурсов в Kubernetes API, называют контроллером.
Контроллеры взаимодействуют с ресурсами Kubernetes, причем с одним типом ресурсов могут работать сразу несколько контроллеров. Вы можете посмотреть, как выглядит их работа, подписавшись на изменения соответствующих типов ресурсов:
$ kubectl get pod -w Эта команда поддерживает также настройки формата -o json или -o yaml. Так что вы можете увидеть, как изменился весь ресурс целиком, или только факт его обновления в API. В выводе мы видим каждую итерацию объектов кластера — это и есть так называемый reconciliation loop.
Например, так выглядит процесс создания и запуска пода на ноде, где два разных контроллера (kubelet и scheduler) работают с одним и тем же ресурсом (Pod), попутно обновляя и добавляя в него различные поля.

Также нужно понимать, что Kubernetes не решает все задачи самостоятельно, а частично делегирует их внешним компонентам. Например, управление сетью, провижининг томов, запуск контейнеров — всем этим занимаются внешние компоненты, которые в идеале должны быть взаимозаменяемыми.
Для этого в Kubernetes придумали и определили три стандартизированных интерфейса. Через них и осуществляется все взаимодействие с этими компонентами:
- CNI (Container Network Interface, контейнерный сетевой интерфейс);
- CSI (Container Storage Interface, интерфейс хранения контейнеров);
- CRI (Container Runtime Interface, интерфейс среды выполнения контейнеров).
В Kubernetes не предусмотрена прямая замена CNI-, CSI- и CRI-компонентов. Но при необходимости сделать это все-таки можно, если детально изучить работу ресурсов и ответственных за них контроллеров.
Внимание. Все сказанное в этой статье отражает мой собственный опыт, его не стоит воспринимать как руководство к действию. Надеюсь, что описанные здесь трюки вам вообще никогда не пригодятся ?
Сеть в Kubernetes
За сеть в Kubernetes отвечает СNI-плагин и kube-proxy — отдельный контроллер, работающий на каждой ноде. Для общего понимания давайте разделим все сетевое взаимодействие в Kubernetes на четыре логические сети.
Для базовой коммуникации на каждой ноде нам необходим сетевой интерфейс с IP. Давайте называть его сетью ноды — она нужна для обеспечения общей связности внутри нашего кластера.
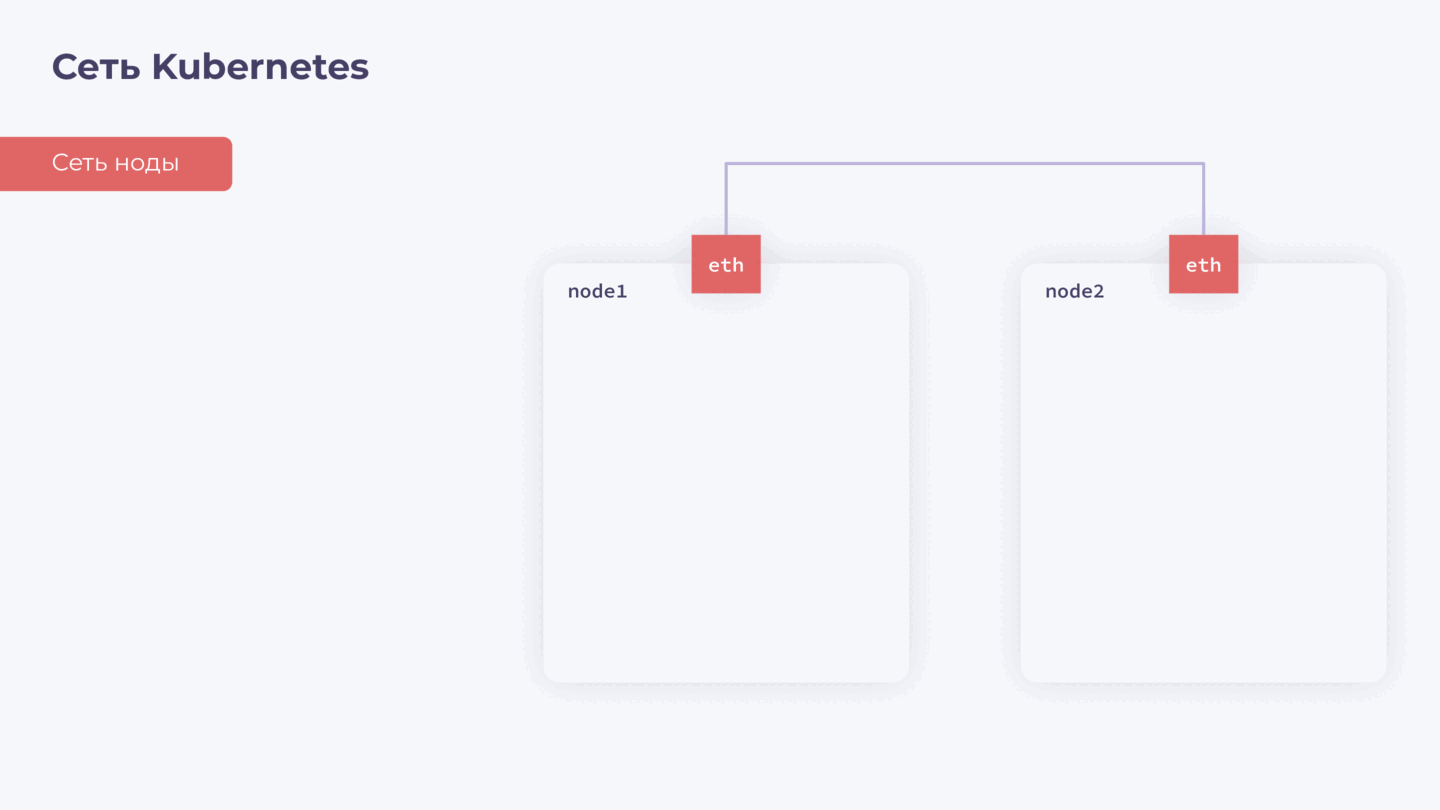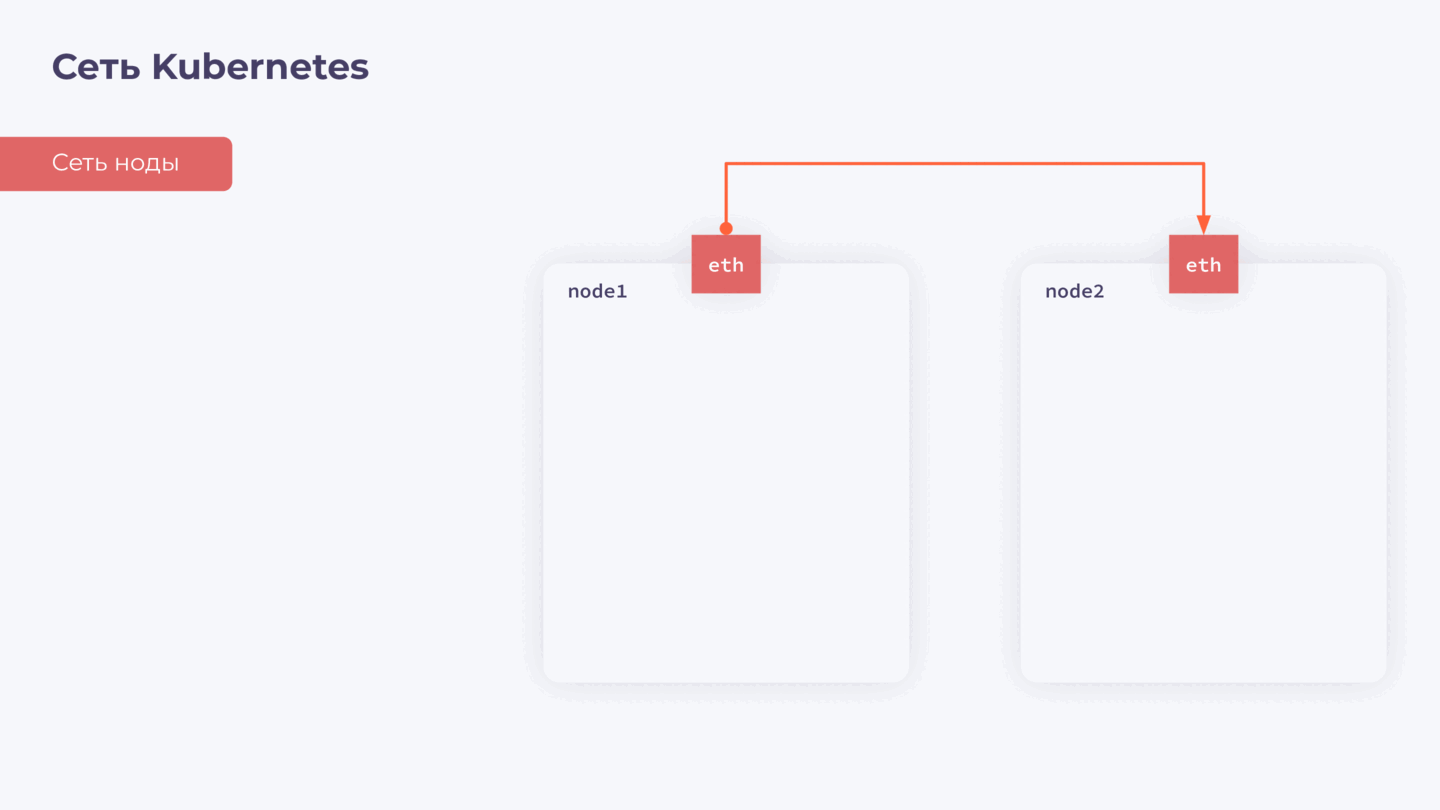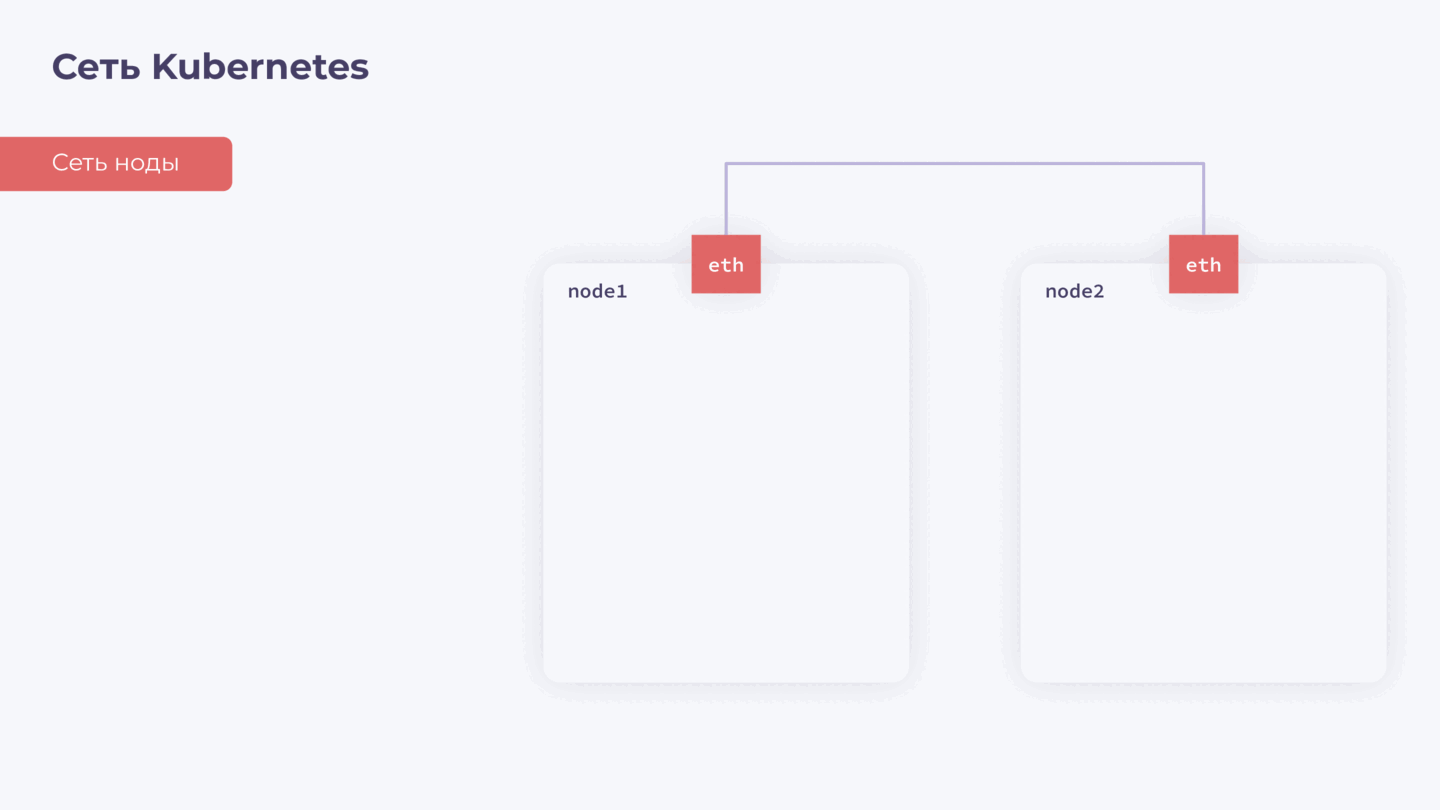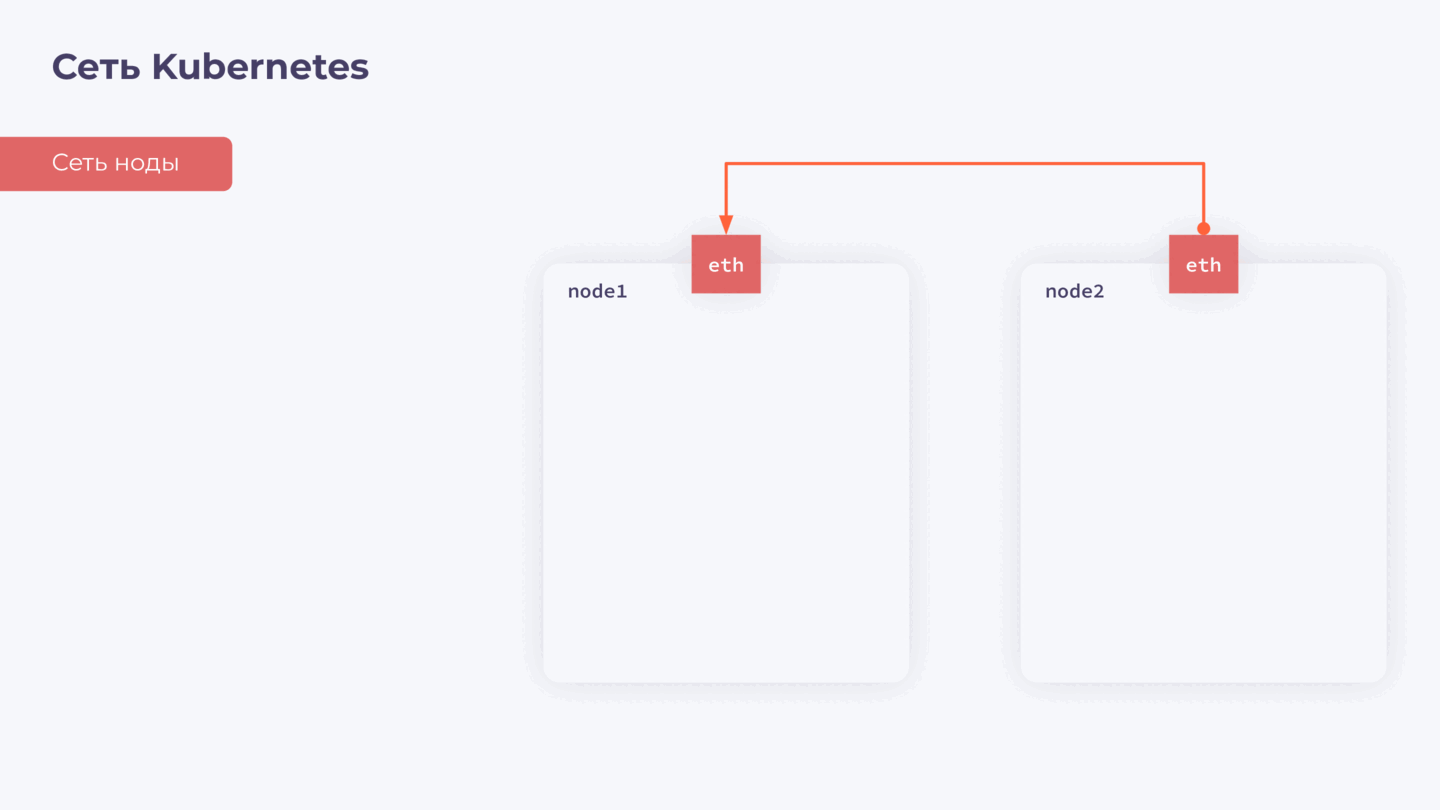
Дальше мы знаем, что у нас есть контейнеры. У каждого контейнера также должен быть свой сетевой интерфейс, через который он взаимодействует с другими контейнерами и нодами в кластере. Обеспечить это взаимодействие — задача CNI-плагина. Назовем его сетью подов.

Но, как мы с вами знаем, по своей природе поды имеют динамические IP-адреса. И чтобы нам не приходилось каждый раз переконфигурировать наши приложения, у Kubernetes есть встроенный service discovery. Не считая DNS, kube-proxy предоставляет нам статический IP-адрес, который неизменен, доступен на любой ноде и запросы к которому всегда будут сбалансированы в нужные поды — это называется сетью сервисов.

На этом можно было бы остановиться. Но часто возникает необходимость направить внешние пользовательские запросы в наше приложение. И для этого требуется позаботиться о том, как внешний трафик попадет в кластер — этим занимается внешний балансировщик нагрузки. Он, в свою очередь, отправит все внешние запросы в нашу сеть сервисов.

Замена CNI-плагина в работающем Kubernetes-кластере

Замена CNI-плагина — довольно нестандартная задача. Я решал ее на живом кластере дважды. Мигрировал с cni-bridge на kube-router, позволяющий использовать политики, и с него — на Cilium.
Обычно для этого рассматривают multus, но в нашем случае все критические компоненты приложений запускались с отдельным сетевым стеком, никак не завязанным на Kubernetes, другие компоненты могли пережить небольшой даунтайм. Поэтому решили выполнить миграцию проще:
- Удалить текущий плагин и созданную им конфигурацию: бриджи, правила iptables, а также конфиг в
/etc/cniна каждой ноде. Применить новый CSI-плагин. - Перезапустить поды, использующие нашу сеть подов.

После обновления новый плагин подхватывает настройки старого из Kubernetes API, и все содержимое кластера возвращается к работе с небольшим даунтаймом.
Пара слов про podСIDR
При необходимости можно обновить и podCIDR — отдельную подсеть, в рамках которой нодам выделяются адреса для подов. Это часто необходимо, например, если выделенный рейндж адресов слишком маленький. Проблема заключается в том, что это поле иммутабельно и обновить его просто так не получится.
Для этого нам потребуется:
- Остановить controller-manager.
- Скачать объект ноды.
- Удалить podCIDR из объекта ноды и обратно залить в кластер.
- Активировать controller-manager.
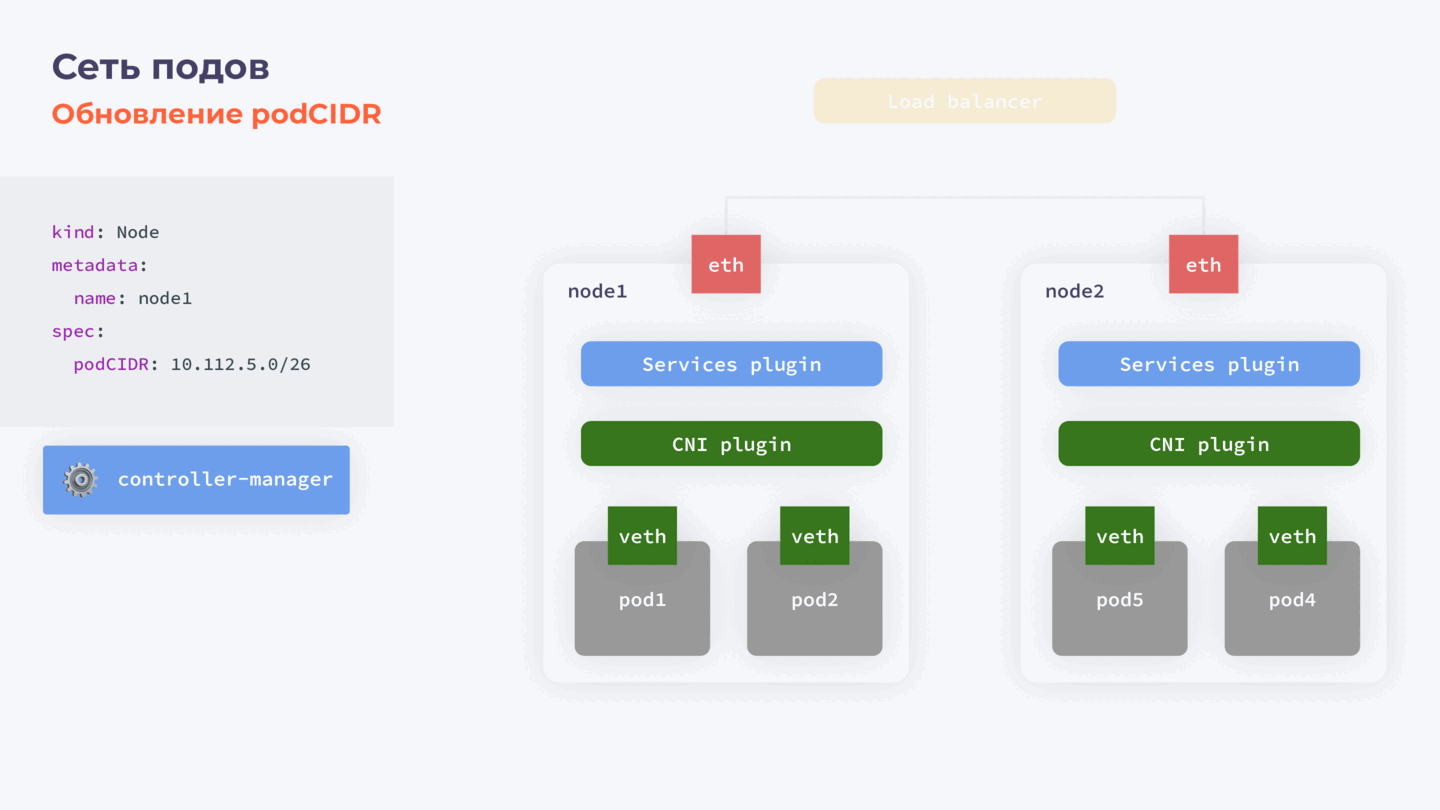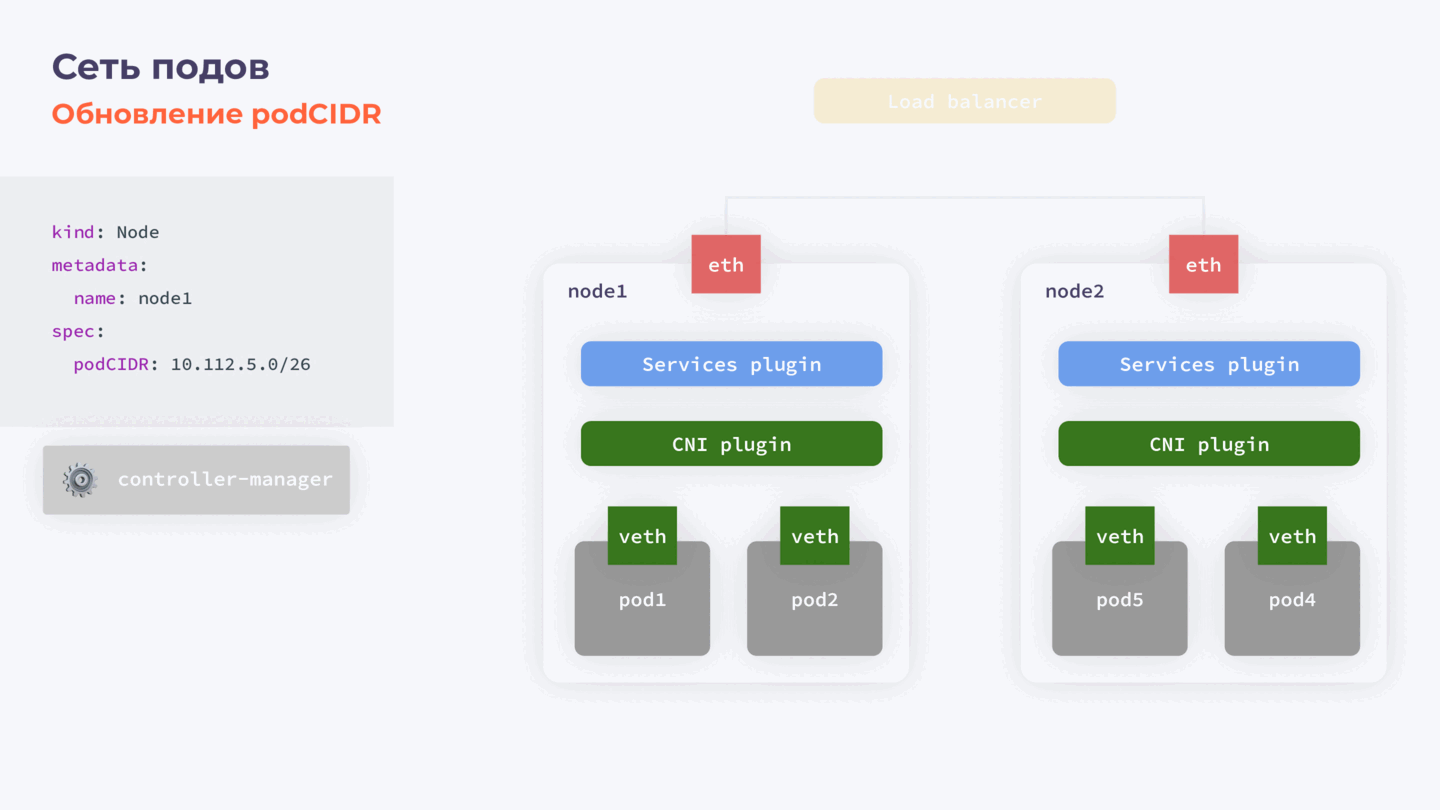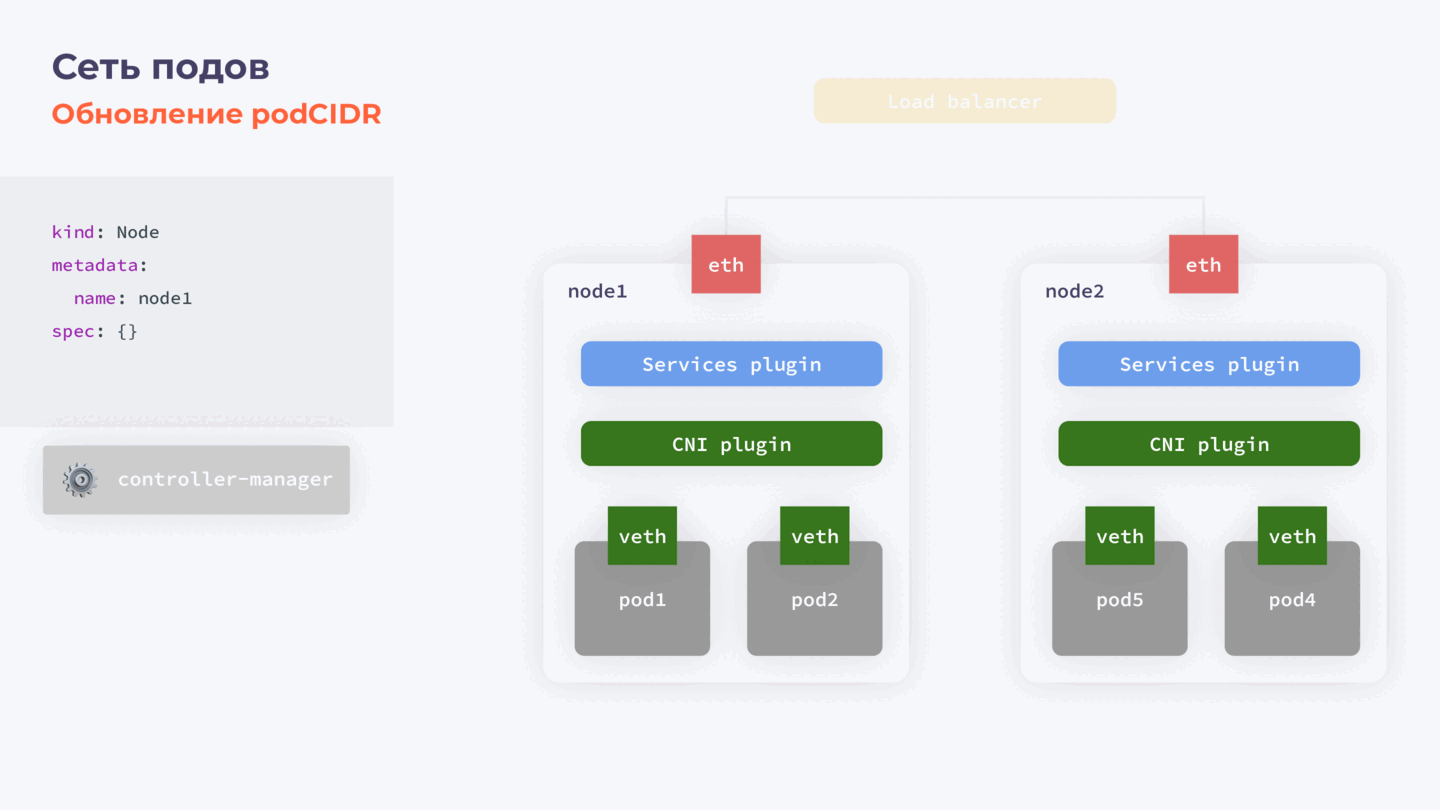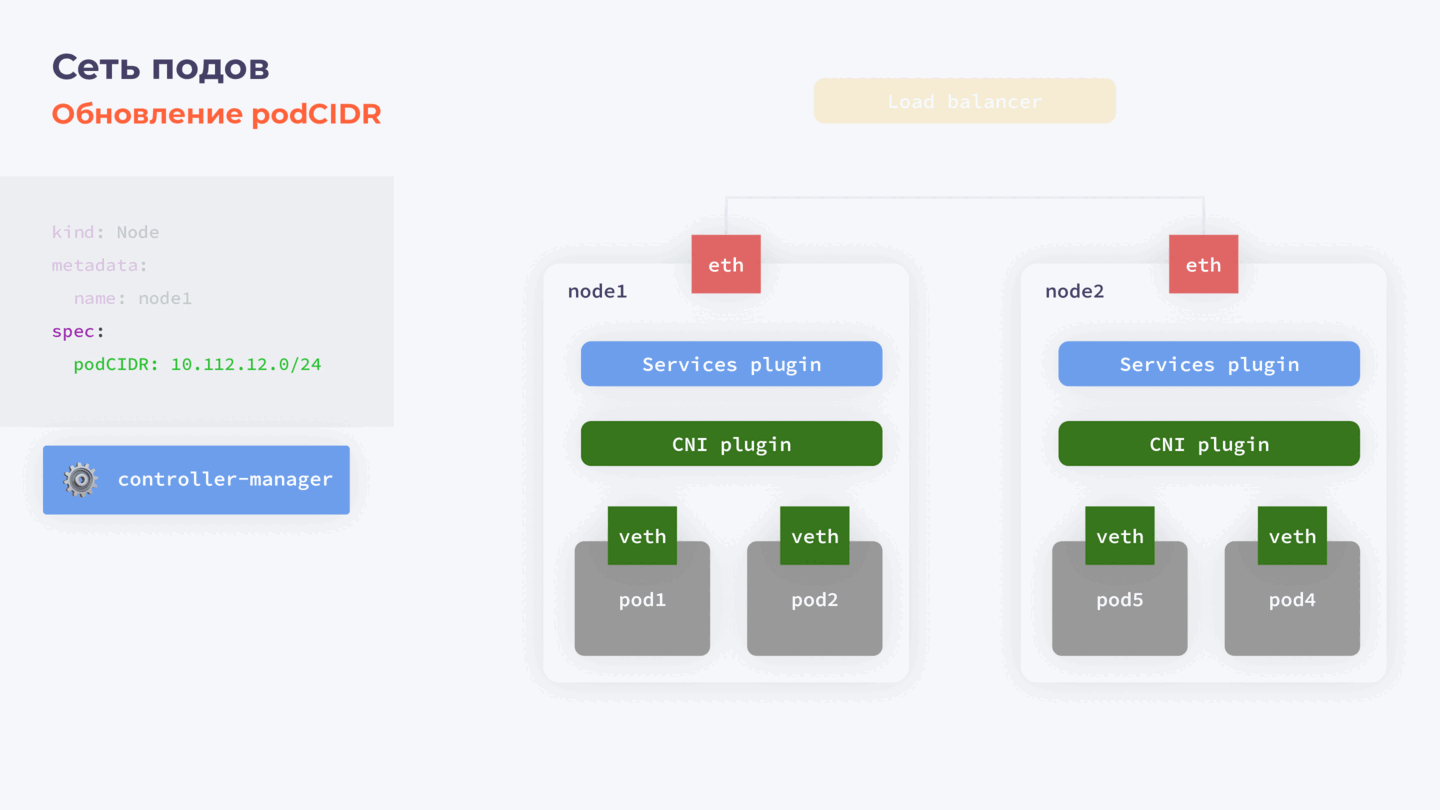
Этапы обновления podСIDR
После запуска controller-manager выделяет на ноду новый podCIDR. Что особенно важно, поды на этой ноде удалены не будут. Пока нода отсутствовала как объект в нашем кластере, controller-manager был остановлен и не работал, и, соответственно, некому было удалить поды.
Замена плагина services network в работающем Kubernetes-кластере
В отличие от CNI, у которого сложнее логика взаимодействия компонентов и протоколы динамической маршрутизации, kube-proxy (он же services network плагин) работает на каждой ноде независимо. И переключение режимов (iptables/IPVS), как и замена всего плагина, происходит заметно проще и, как правило, без даунтайма.
- Останавливаем действующий services plugin.
- Запускаем новый плагин с новой конфигурацией.
- На каждой ноде удаляем конфигурацию, которую сгенерировал старый плагин.
Эти действия можно выполнять для каждой ноды как параллельно, так и последовательно.
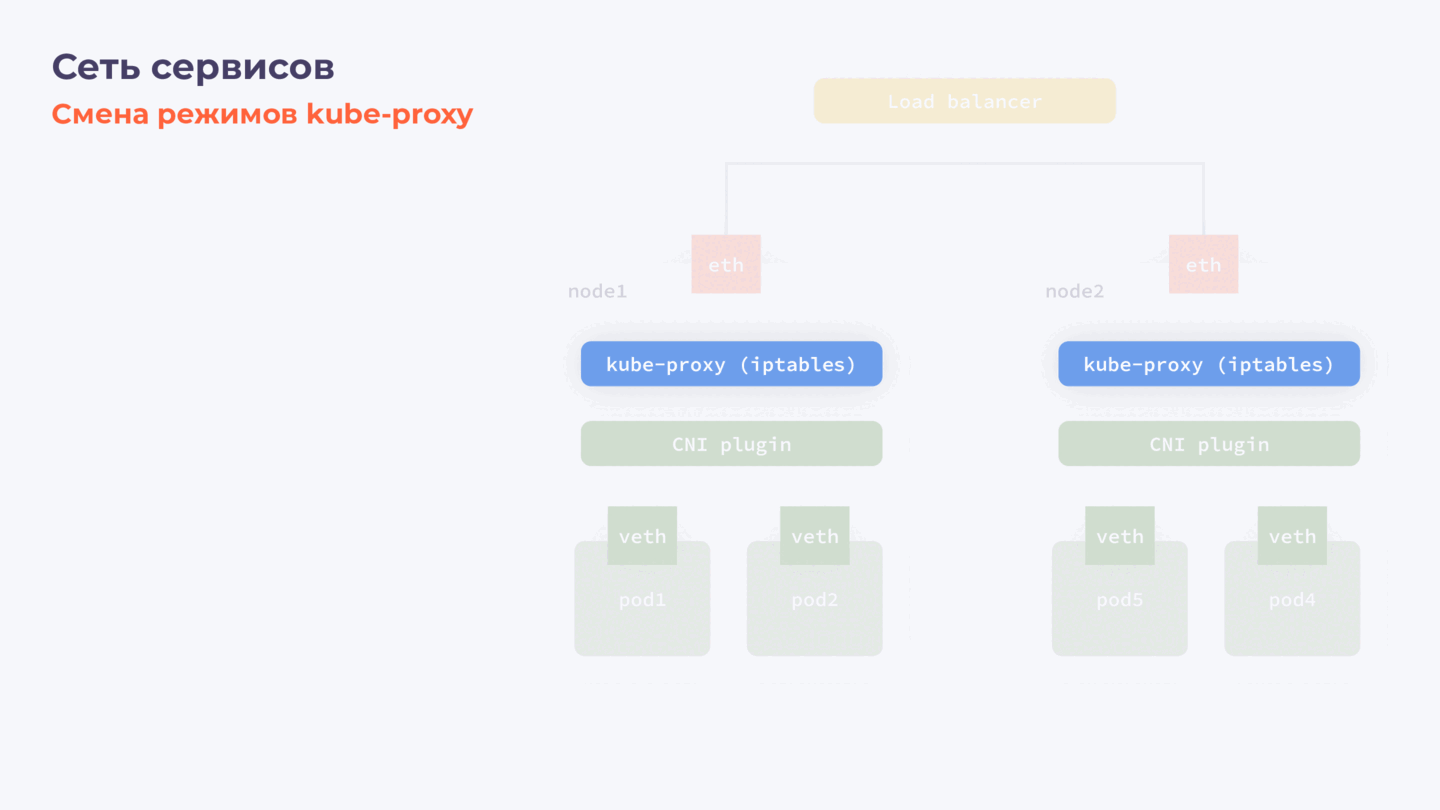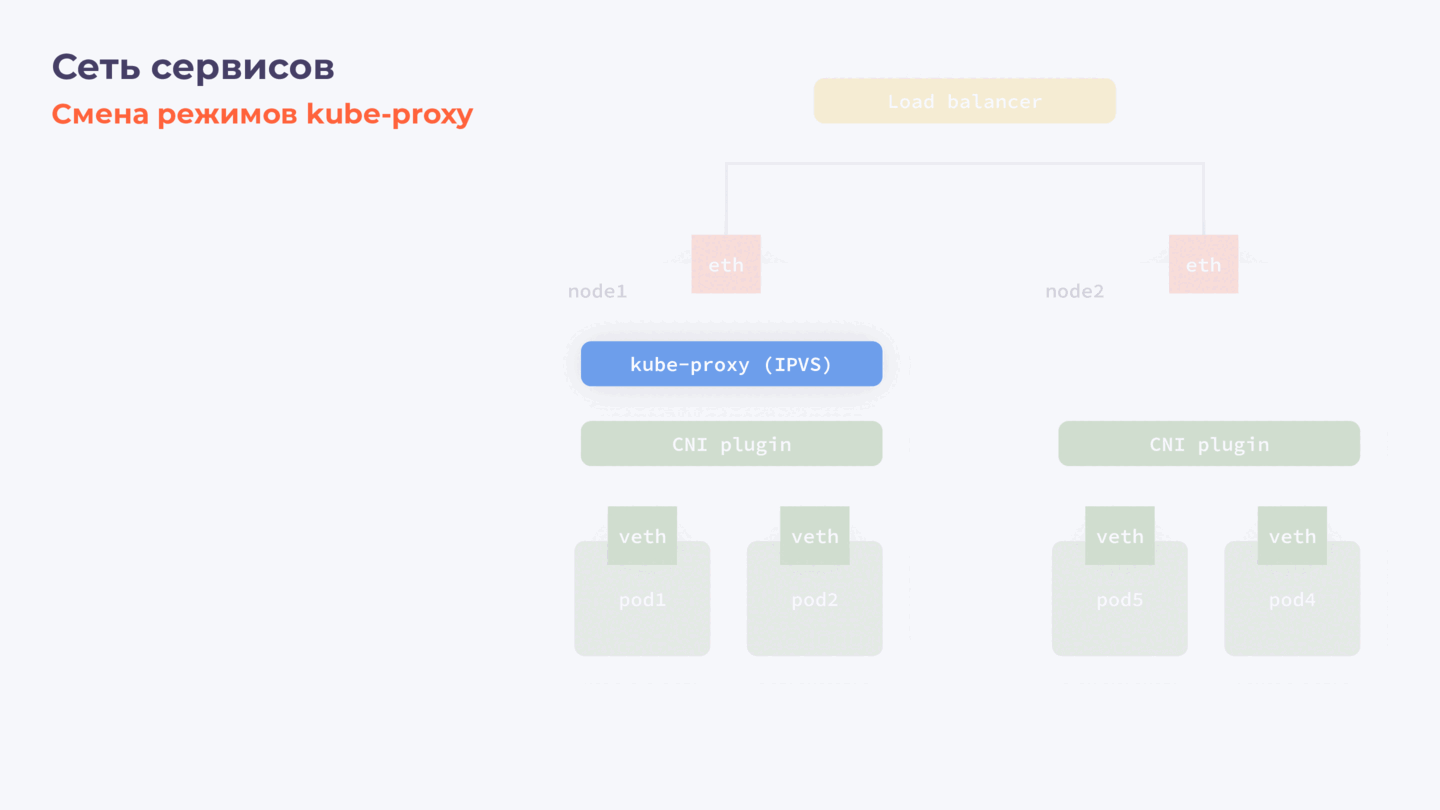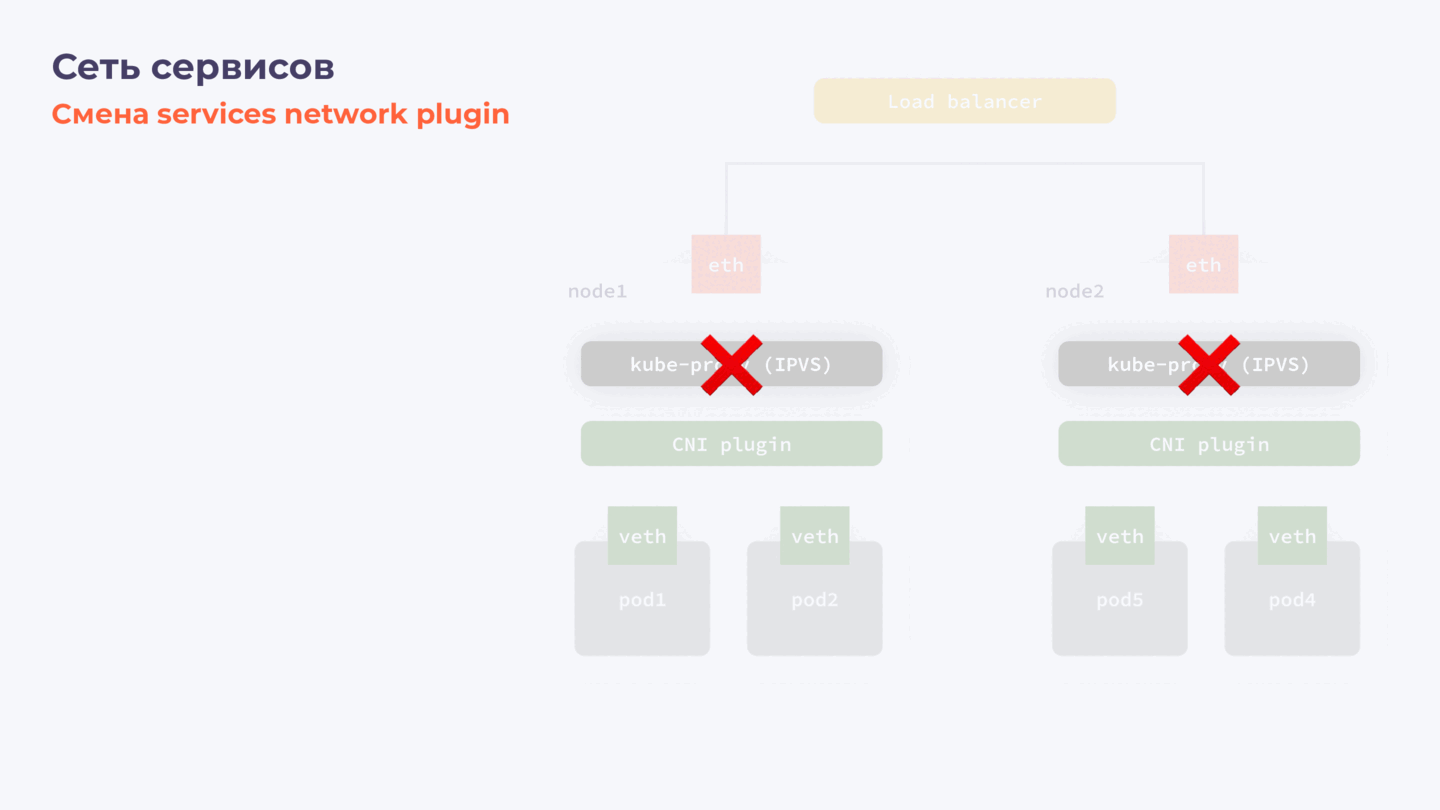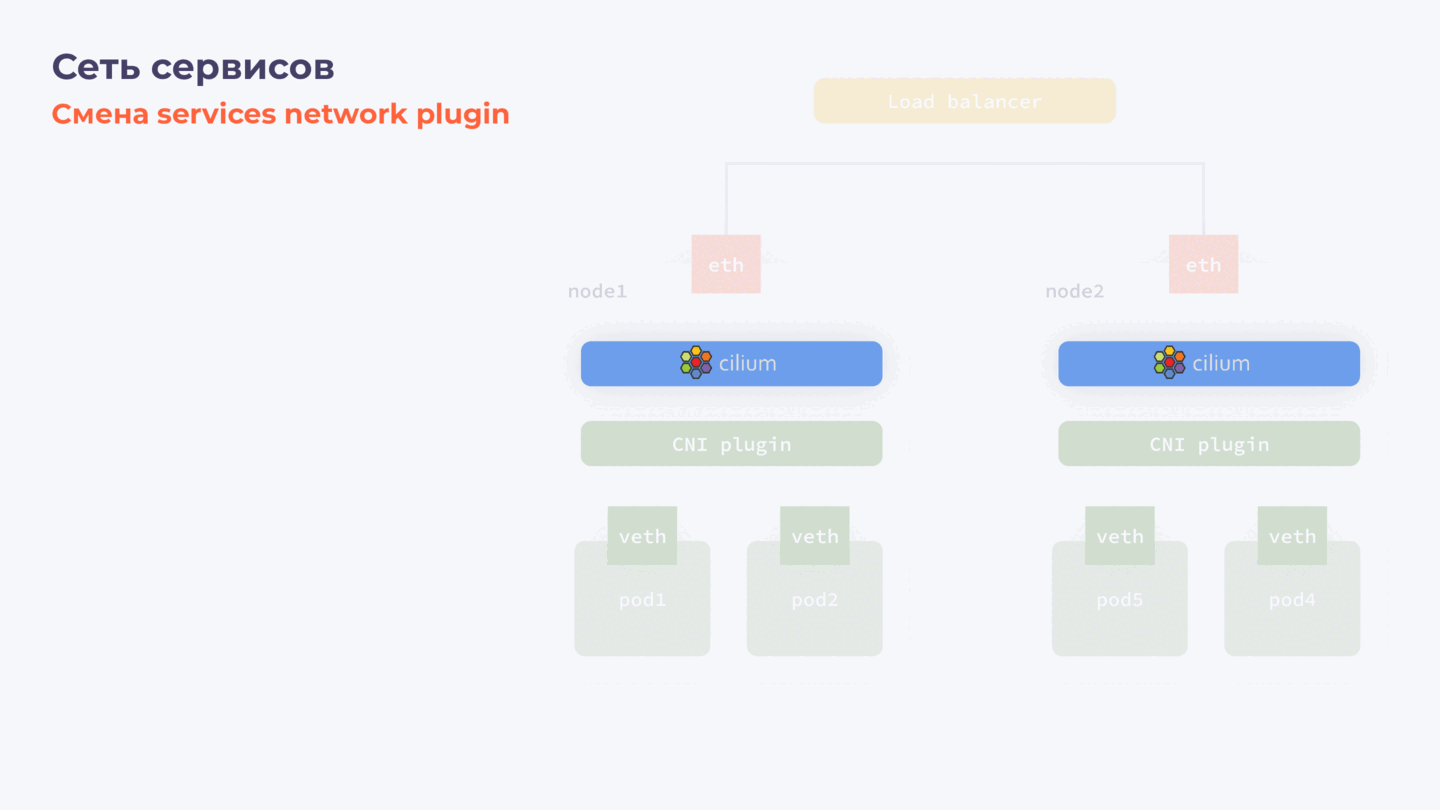
Этапы замены Services Plugin
Чтобы все работало корректно, после замены достаточно зайти и почистить старые правила. Для этого потребуется запустить бинарник kube-proxy со следующим флагом:
$ kube-proxy --cleanupХранение данных в Kubernetes
Сейчас у Kubernetes есть несколько встроенных (in-tree) storage-плагинов и много внешних. Для стандартизации взаимодействия с ними придумали спецификацию CSI (Container Storage Interface). На данный момент это самый полный и самый функциональный интерфейс для взаимодействия с внешними хранилищами. Кроме того, все внутренние плагины сейчас переписывают под CSI.
Также в Kubernetes есть две схемы провижининга физических томов:
- статический провижининг томов, когда администратор вручную создает тома, затем описывает их как PhysicalVolume в Kubernetes;
- динамический провижининг томов, когда драйвер автоматически создает и удаляет тома сразу после того, как пользователь создал PhysicalVolumeClaim.
Работа CSI-драйверов как комплексных решений построена на принципе динамического провижининга томов, то есть создания в режиме реального времени тома запрашиваемого размера. Этим занимается отдельный CSI-контроллер.
Если посмотреть на процедуру со стороны пользователя, то в схеме участвует четыре ресурса:
- StorageClass описывает параметры доступа к хранилищу и общие параметры создаваемых томов (например, файловая система, количество реплик и т. п.);
- Persistent Volume Claim (PVC) — запрос на хранение, который создает пользователь каждый раз, когда ему требуется выделить место для хранения данных;
- Persistent Volumes (PV) описывает непосредственно созданный физический том в хранилище;
- Pod, использующий том.
Важно заметить, что PV и PVC создаются несвязанными и в зависимости от схемы провижининга могут появляться раньше или позже друг друга. Тем не менее, когда Kubernetes находит PVC и подходящий PV для него, он выполняет операцию bound — связывает их друг с другом.
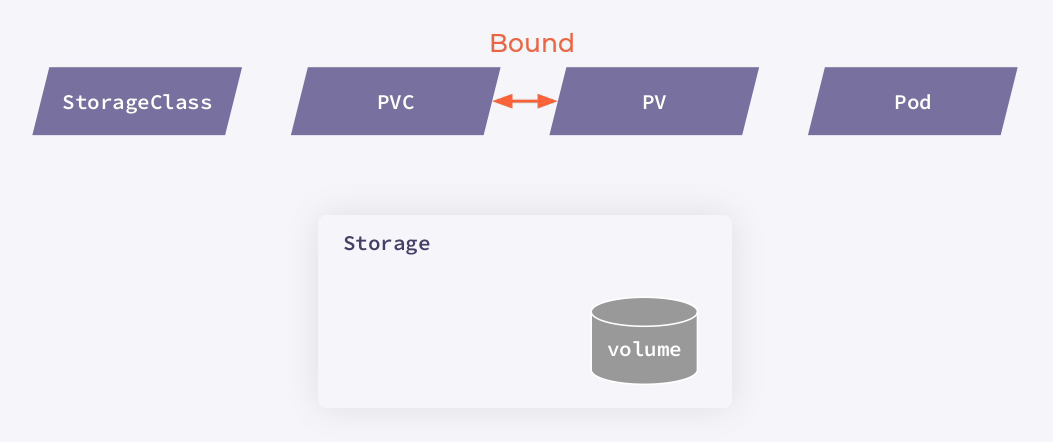
Взгляд со стороны пользователя
Давайте разберем всю ту магию, которая происходит при динамическом провижининге томов, — как создаются и удаляются тома с помощью CSI-драйвера.
Представим, что у нас есть нода с запущенным kubelet и отдельное хранилище, параметры которого описаны в StorageClass. При установке драйвера создается ресурс CSIDriver. Он уведомляет Kubernetes о возможности использования драйвера.
На ноде также запускается под csi-node, содержащий два контейнера: node-driver-registar и csi-driver. Node-driver-registar для каждой ноды создает еще один ресурс CSInode — с полем nodeID. Информацию для него он запрашивает через бинарник csi-driver, который предоставляет вендор хранилища.

Инициализация CSI-драйвера в кластере
Помимо этого, в кластере также запущен отдельный под csi-controller со своими контроллерами: external-provisioner, external-attacher, external-resizer, external-snaphotter и csi-driver (тот же самый бинарник, который предоставляет вендор хранилища).
Провижининг и подключение томов выполняются в несколько этапов:
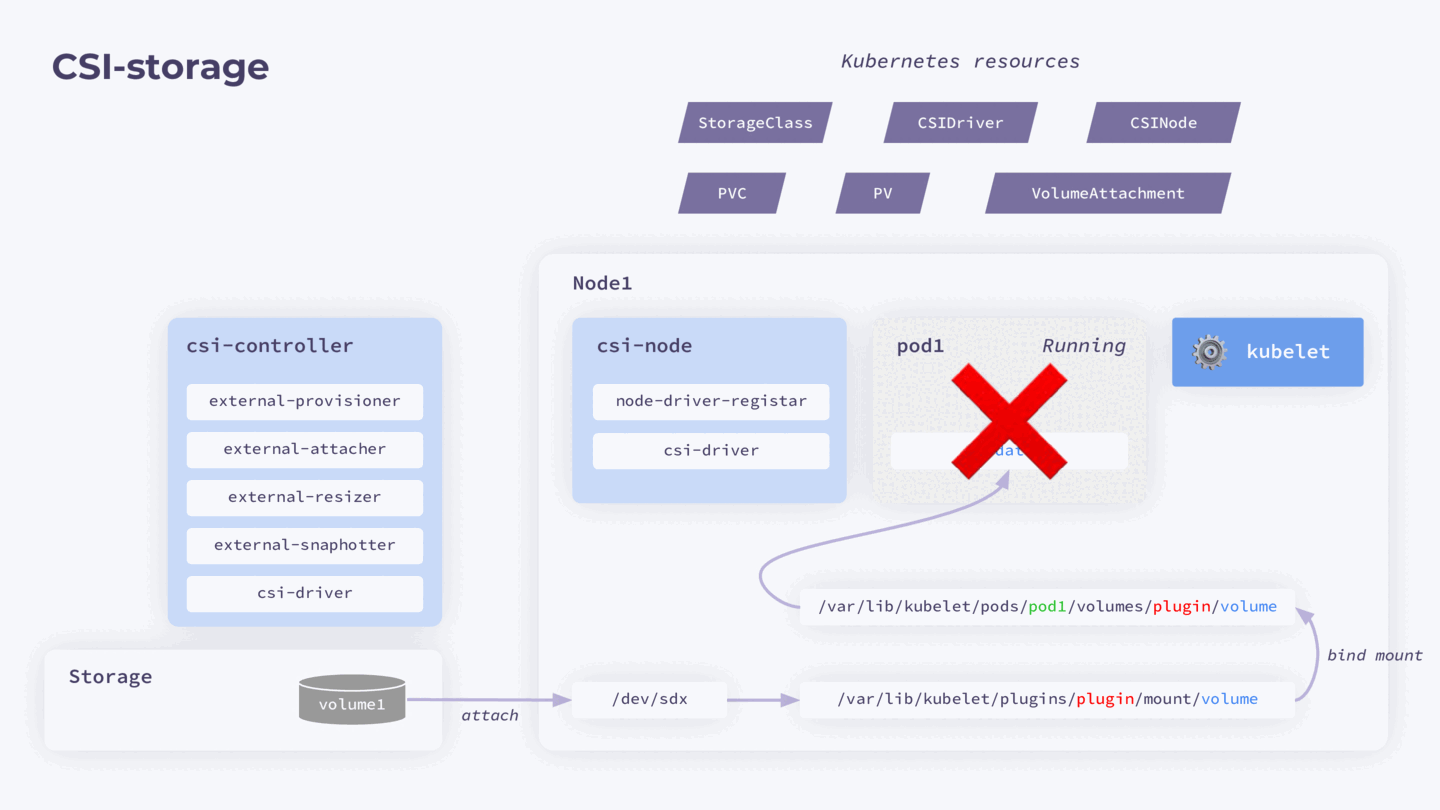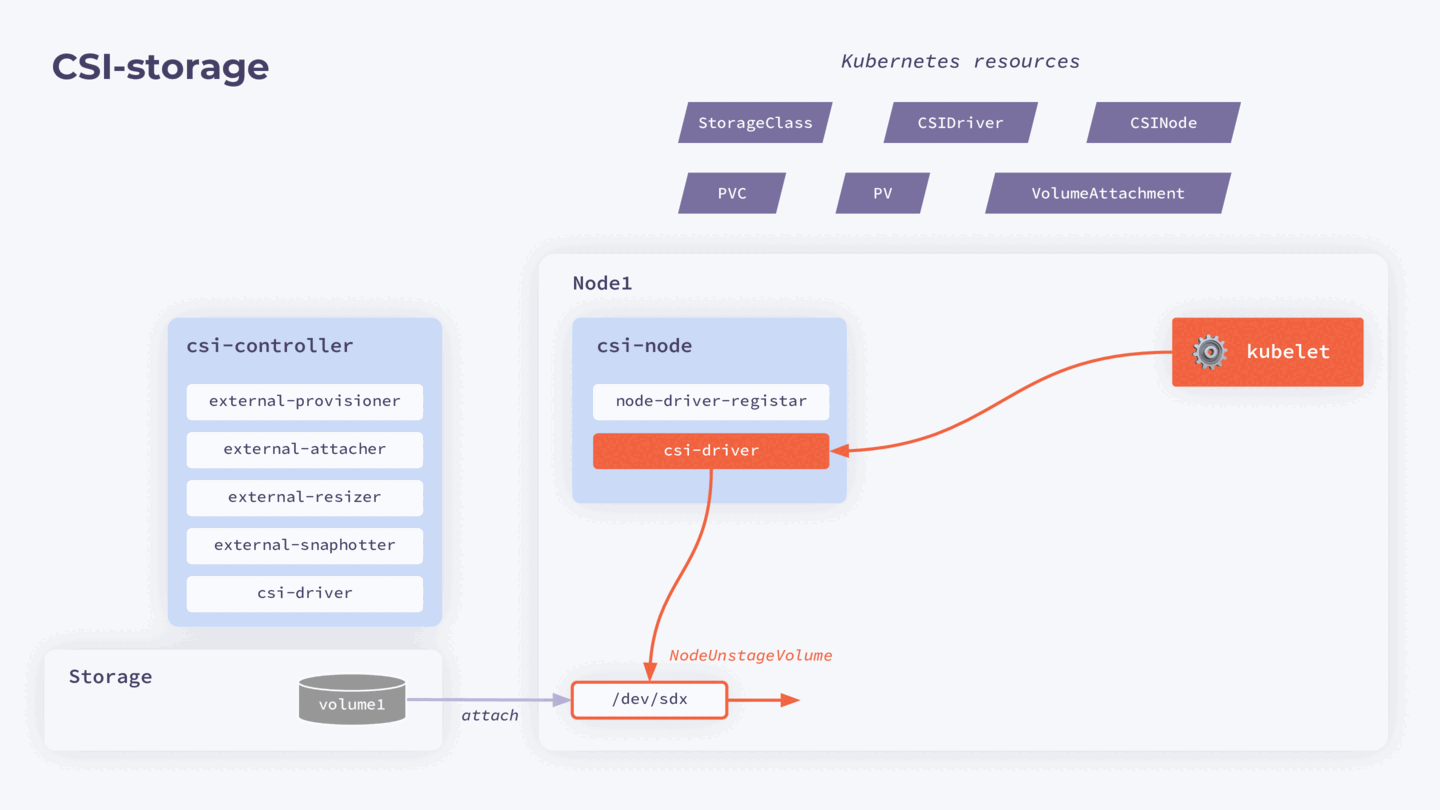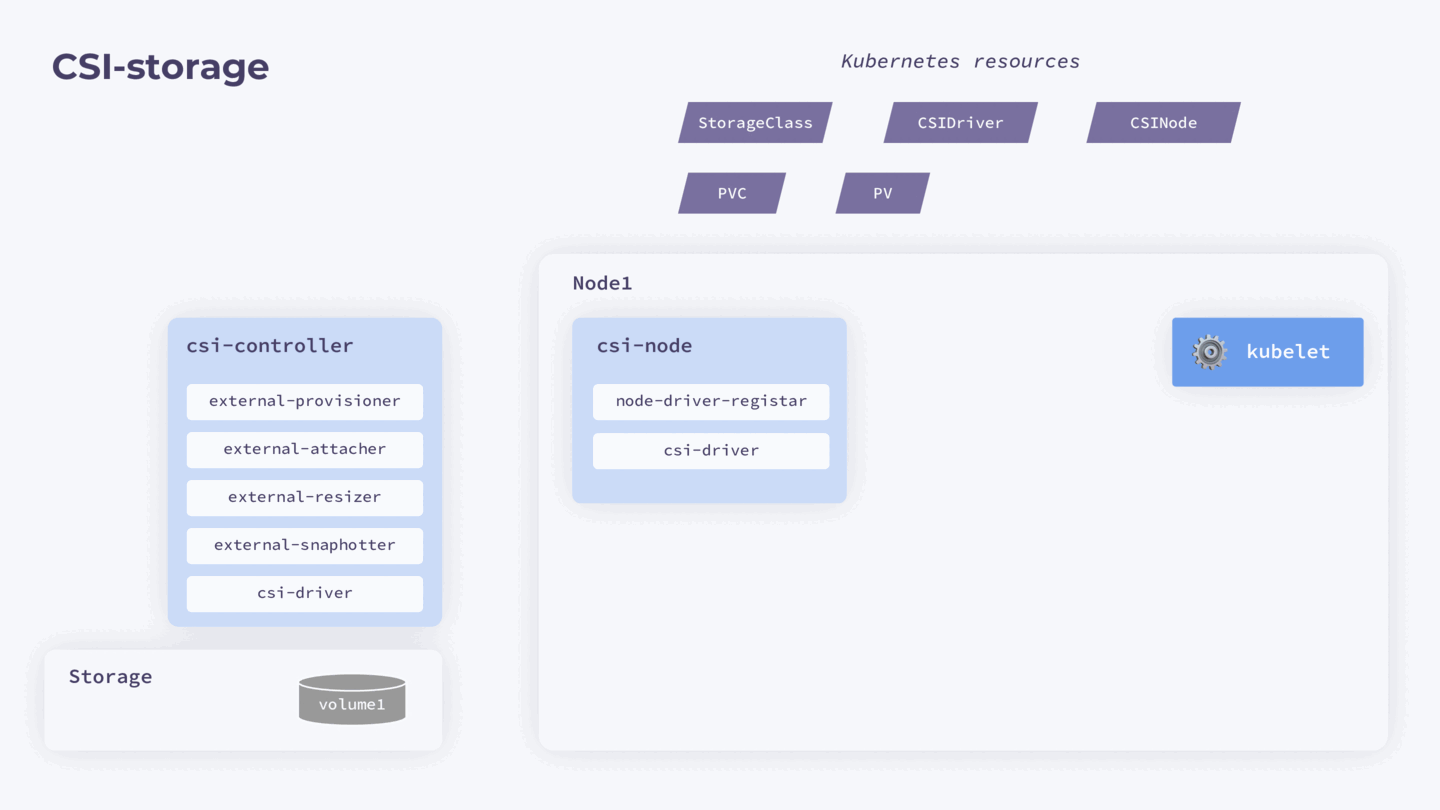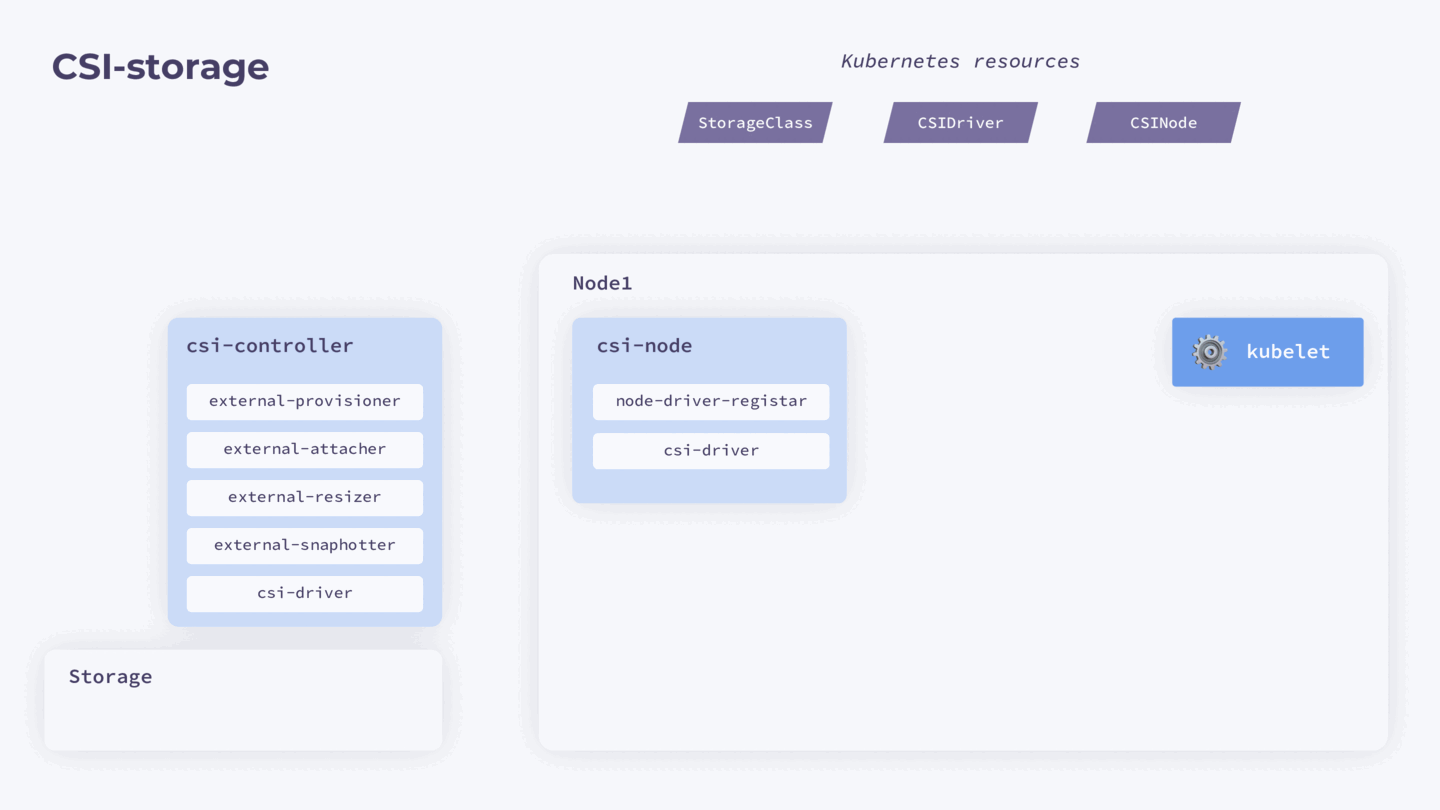
- После создания PVC прилетает в reconciliation loop к external-provisioner.
- External-provisioner через csi-driver обращается к хранилищу и создает том.
- После создания тома external-provisioner создает в кластере ресурс PV.
- PV и PVC объединяются с помощью Kubernetes (операция bound).
- После запуска пода на ноде kubelet добавляет в Kubernetes отдельный ресурс — VolumeAttachment.
- VolumeAttachment прилетает в reconciliation loop к external-attacher, который через csi-driver отдает команду хранилищу, чтобы оно экспортировало этот том на ноду.
- kubelet через csi-driver запускает операцию монтирования тома в директорию
/var/lib/kubelet/plugins/plugin/mount/volume. Она общая и нужна, чтобы тома могли использоваться сразу несколькими подами в пределах одной ноды, даже если они ReadWriteOnce. - kubelet через csi-driver монтирует созданный том в директорию нужного пода. После этого под может его использовать.
При запуске процедуры detach и удаления тома описанные действия выполняются в обратном порядке.

Как обновить тома, созданные таким образом
Ресурсы Kubernetes PV и PVC в большинстве случаев иммутабельны, то есть добавить или изменить многие поля в уже созданных ресурсах практически невозможно. Но на практике подобное изменение может понадобиться.
Например, я сталкивался с необходимостью миграции с использования in-tree-плагинов и FlexVolume на CSI, а также с изменениями спецификации драйвера вендором. Чтобы не пришлось перезапускать контейнеры и пересоздавать тома, нашел более простой путь — пересоздать PV и PVC сразу с нужными параметрами.
Это можно сделать следующим образом:
1. Для начала нам потребуется остановить CSI-controller, отвечающий за провижининг и удаление томов. Это позволит свободно работать с любыми ресурсами, не опасаясь, что они будут удалены физически.
2. Сохранить локально, а затем удалить PV и PVC-ресурсы из Kubernetes. При удалении потребуется вручную удалить поле finalizer. Если этого не сделать, Kubernetes будет ждать, пока не появится контроллер и не отработает операцию удаления PV.
3. Локально из PV нужно также удалить информацию о связи каждого PV с конкретным PVC — uid и, возможно, другую информацию из поля ClaimRef. Это нужно, поскольку при пересоздании ресурсов меняется ID, и Kubernetes выполняет bound повторно.

Спецификация PV и фрагменты, которые нужно удалить вручную
4. Из PVC потребуется удалить специальные аннотации, которые указывают на то, что провижининг и bound для этого PVC уже выполнены

Спецификация PVC и фрагменты, которые нужно удалить вручную
5. Загрузить новые PV и PVC в кластер с новыми параметрами. Подождать, пока Kubernetes выполнит bound.
6. Включить csi-controller, который просто продолжит работать с новыми ресурсами как с нативными.
Этот трюк не сработает, если поменяется имя драйвера, поскольку оно определяет директорию драйвера на ноде, и в этом случае потребуются дополнительные действия на ноде, чтобы отмаунтить его от старой директории и примонтировать на новое место. Возможно, обычного mount --move olddir newdir в вашем случае будет достаточно.
Среда исполнения контейнеров в Kubernetes (CRI)
Теперь немного поговорим про среду исполнения контейнеров. Если раньше это был только Docker, то сегодня их существует гораздо больше. К тому же от Docker решено избавиться, и в последних версиях Kubernetes он уже не поддерживается.
Проблема Docker очевидна: он представляет собой отдельную систему оркестрации контейнеров, в которой, помимо функции запуска контейнеров, есть собственная реализация сети, service discovery и физические тома, тогда как Kubernetes использует из этого только возможность запуска контейнеров.
Для коммуникации с Docker в kubelet встроена специальная прослойка — dockershim. Отдельная проблема заключается в том, что Docker имеет нестабильный API, который может изменяться при обновлении. Таким образом, приходится привязываться к конкретным версиям Docker, чтобы быть уверенным, что все работает как надо.

Схема запуска контейнера с использованием Docker
Впоследствии Docker разделили на несколько независимых частей, среди которых есть и containerd — часть, которая отвечает за запуск контейнеров. Кроме того, в нем уже реализовали CRI-интерфейс, с которым kubelet может общаться напрямую без всяких дополнительных прослоек. И теперь процедура запуска контейнеров стала намного проще и стабильнее.

Схема запуска контейнера при использовании containerid
Как заменить Docker на containerd?
Все на самом деле просто:
1. Нам нужно указать бинарнику kubelet, чтобы он ходил в сокет, расположенный не в dockershim, а напрямую в containerd, который уже есть на ноде (Docker тоже использует containerd как среду для запуска контейнеров).

2. То же самое нам потребуется сделать и с crictl — управляющей утилитой, которая пришла на замену команде docker. Для этого изменим его конфиг:

3. Теперь перезапустим сервисы containerd и kubelet:
$ systemctl restart containerd kubeletПосле этого в объекте ноды мы можем наблюдать, как изменился наш container-runtime.

При замене CRI поды не пересоздаются, однако это действие перезапустит все контейнеры внутри них. Но поскольку сложная логика с монтированием физических томов и выделением поду IP-адреса не будет выполняться заново, то даунтайм будет минимальным.
Опыт миграции control-plane Kubernetes
Зная особенности процессов, подобным образом можно мигрировать не только отдельные компоненты, но и целиком control-plane.
У меня был опыт распила большого (~800 нод) кластера на несколько маленьких. Причина такого решения в следующем.
Как мы знаем, Kubernetes — это single-tenant-приложение, а значит, он архитектурно не приспособлен для использования несколькими командами разработки. Это создает определенные риски: при любом сбое в control-plane весь кластер может стать недоступным для работающих с ним команд.
Управлять доступом в такой конфигурации тоже сложно. Гораздо лучше, когда у вас есть отдельный кластер на каждую команду разработки. К сожалению, опыт приходит с годами, и со временем приходится выполнять работу над ошибками.
Чтобы избавиться от подобных проблем, мы решили мигрировать отдельные части кластера в отдельные control-plane. В нашем случае ноды в кластере закреплены за конкретными командами, поэтому процесс отделения выглядел следующим образом:
- Запустить новый control-plane без нод.
- На нем развернуть backup работающего кластера, то есть создать его полную копию.
- Из нового кластера удалить все ресурсы, которые не будут относиться к нодам, вводимым на следующем шаге.
- Обновить IP в configmap для kube-proxy.
- Нужные ноды вывести из исходного кластера и присоединить к новому.
- В исходном кластере удалить ресурсы перенесенного кластера.
Что важно, при таком способе миграции существующие поды продолжают работать без даунтайма.
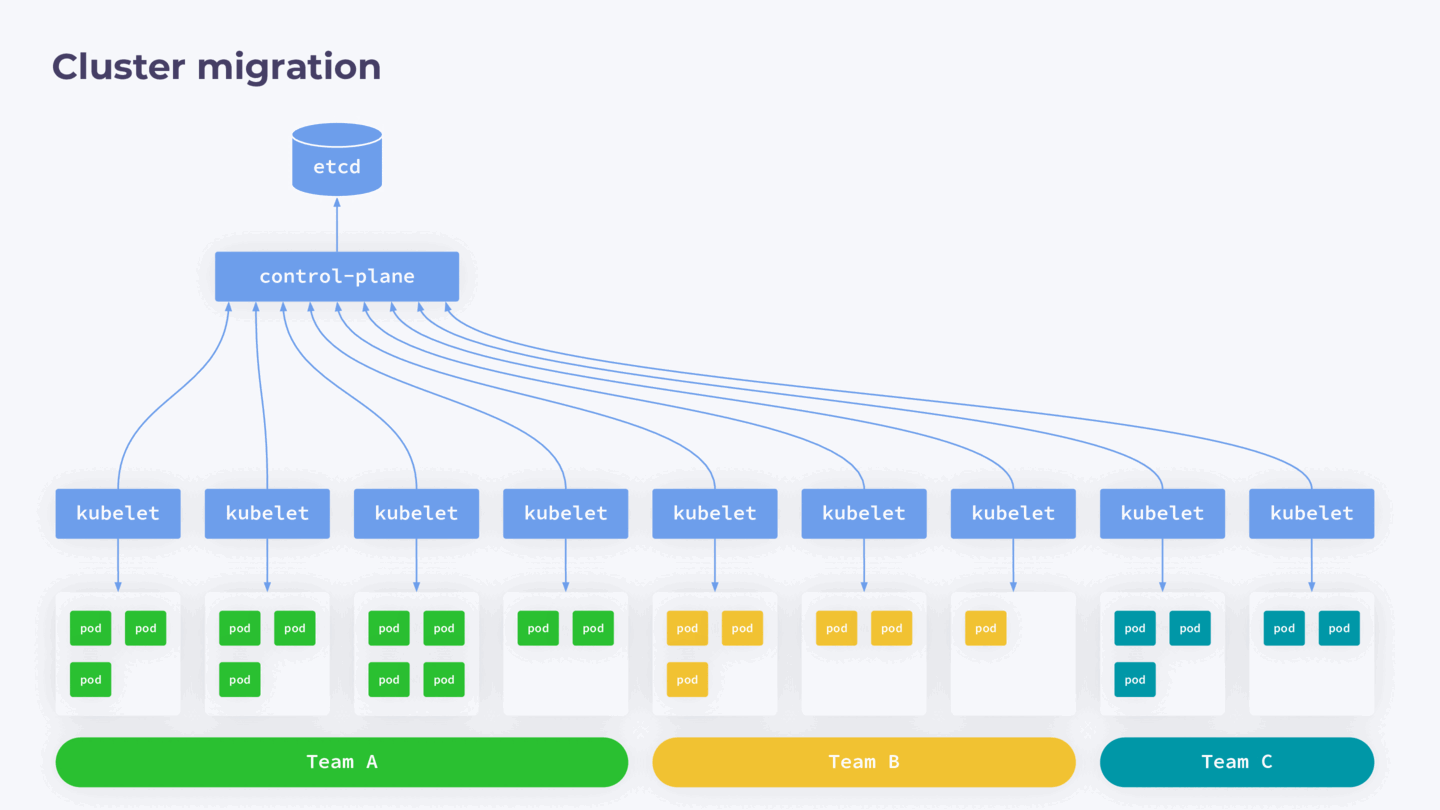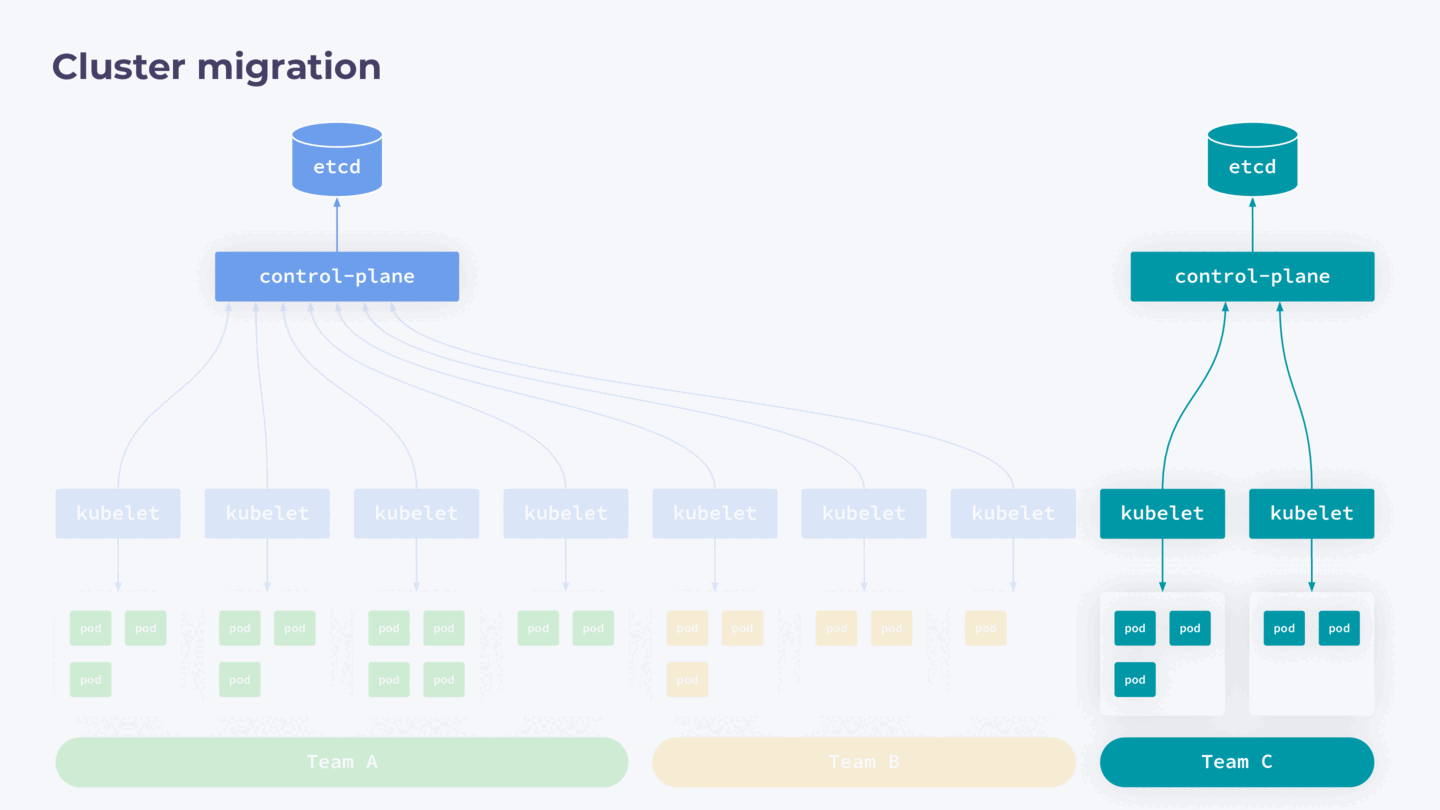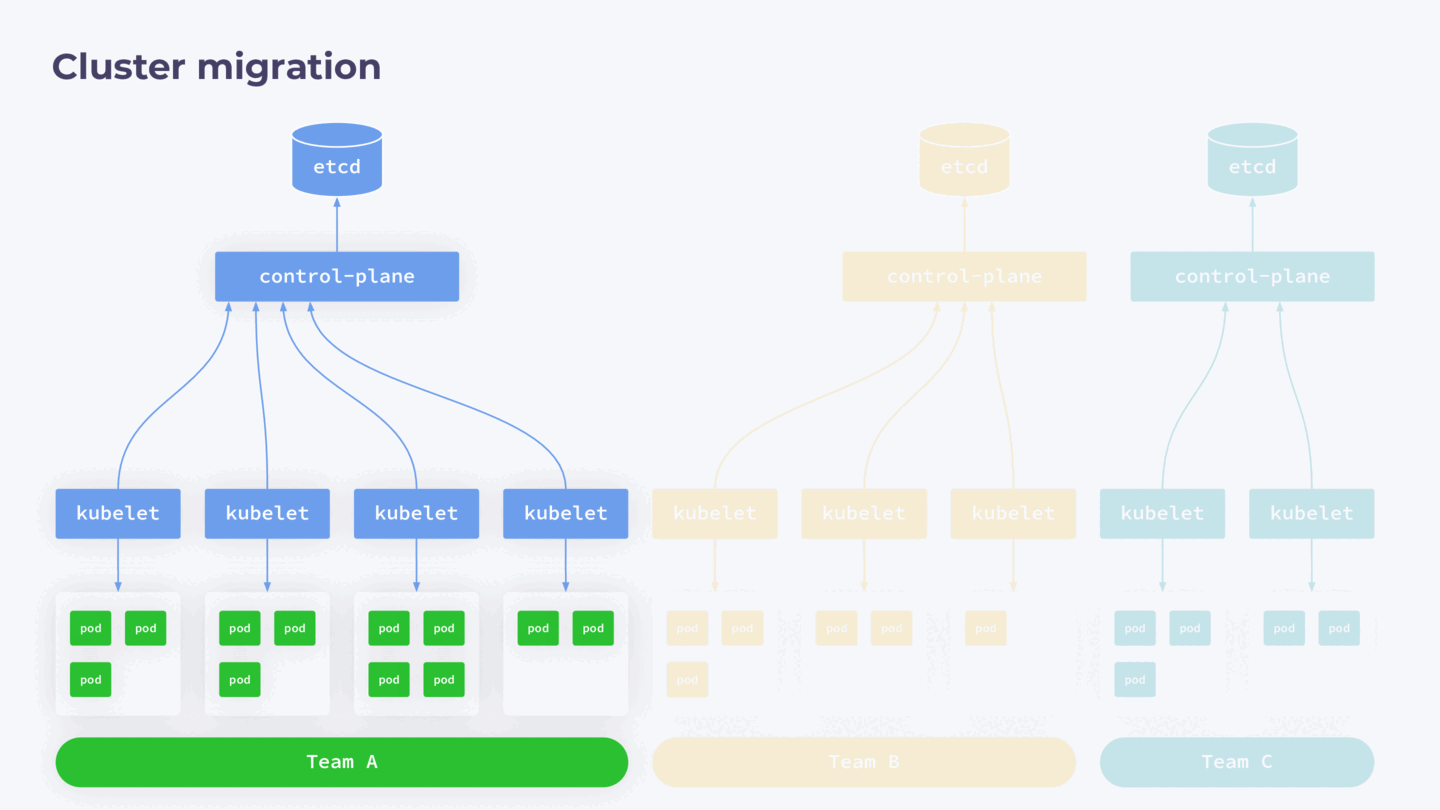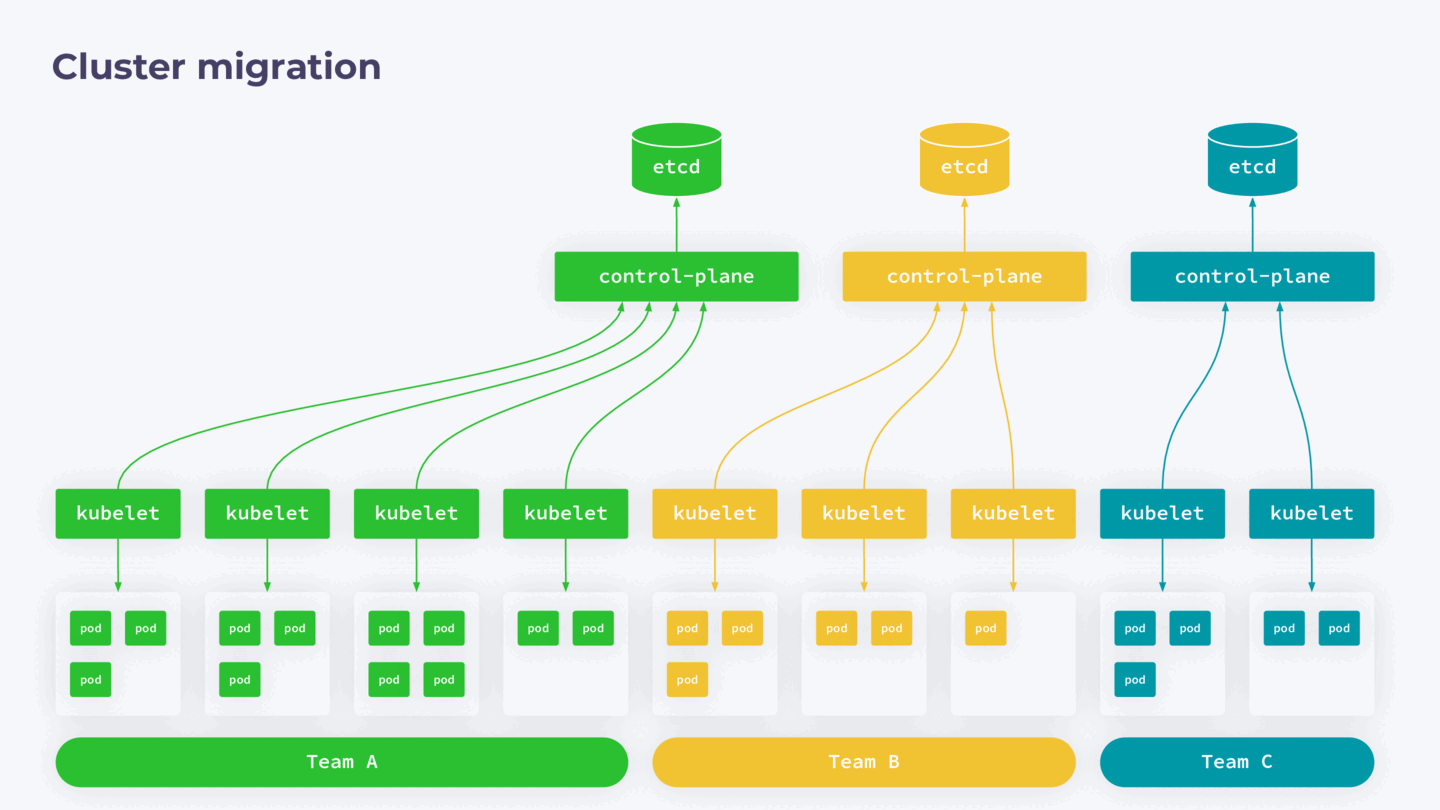
Схема полного перераспределения кластера
Вместо заключения
Ограничения в Kubernetes существуют не просто так. Но, зная особенности работы всех ресурсов и связанных с ними контроллеров, такие запреты можно обойти.
В этой статье я постарался собрать наиболее специфические и интересные случаи, с которыми мне довелось столкнуться на практике, попутно объясняя принципы работы CNI-, CSI- и CRI-интерфейсов.
Не стоит забывать, что основной сценарий применения Kubernetes сегодня остается прежним — для запуска stateless-приложений. В этом случае переезд было бы целесообразнее проводить с помощью поднятия нового кластера и постепенного переноса ресурсов в него. В моем случае был кластер, у которого 80% нагрузки — stateful, и такой вариант был для меня недоступным.
ссылка на оригинал статьи https://habr.com/ru/company/vk/blog/653035/
Добавить комментарий