Как-то раз мне захотелось сделать для курса на платформе Эквио полный конспект всех текстовых материалов, чтобы удобно их перечитывать на досуге, так и родилась мысль, которая вылилась в небольшой инструмент для сбора данных, их обработки и создания pdf-файлов по материалам курса.

Все началось с того, что в компании, где я сейчас работаю, была запущена программа обучения для руководителей на платформе Эквио.
Википедия говорит нам, что «Эквио — мобильная платформа, единое цифровое пространство для обучения, управления и мотивации персонала. Позволяет создавать обучающие курсы, проводить онлайн-презентации, организовывать обучение сотрудников.»
Программа представляет из себя набор модулей, состоящих из видео, статей, тестов и практических заданий. В общем, добротный курс с полезными материалами. И случается, что порой хочется вернуться к какому-то материалу и перечитать его или найти нужный отрывок, который «кажется, где-то там был…». И все бы ничего, но находить нужный контент на платформе совсем непросто.
Сначала мне как пользователю доступен верхний уровень, который говорит, что у меня есть модуль, который включает в себя N программ обучения, внутри которых есть секции (которые изначально все свернуты), и только развернув каждую, я могу посмотреть, какие там материалы были и уже далее открыть контент конкретного материала. Поиска по содержимому тоже не завезли.

К тому же материалы курса доступны только на самой платформе и чем-то полезным непросто поделиться с коллегой, который курс не проходил.
И для сравнения мне в голову пришел другой пример. Однажды довелось мне проходить курс на Coursera, так вот там у каждого модуля, кроме видео-обучалок и прочего давали в дополнительных материалах скачать информативную PDF-ку, где уже текстом было описано содержимое модуля. Эдакие методички, как в университете были, может этим меня формат и подкупает. Так к этим файлам я неоднократно возвращался, и зачастую это было удобно и полезно.

Так, обуздав свои порочные желания, попробуем понять, чего же мы хотим:
-
Быстро находить нужное место в материалах по содержанию или по ключевым словам, если мы их запомнили
-
Иметь у себя материалы-методички, чтобы не лазить каждый раз на сайт и не зависеть от доступности курса на платформе или самой платформы
-
Делиться нужным разделом с коллегой, которого курс обошел стороной
Сложив два плюс два, мне показалось, что организовать подобное и здесь будет хорошей идей. В голове нарисовалась схема, где я соберу текстовые материалы с сервиса, сформирую на их основе опрятные файлы с оглавлением, а их уже затем переведу в PDF.
Идем на разведку
Подумано — сделано. Сначала нужно было понять, как мы сами эти материалы сможем получить. Скрестив пальцы и понадеясь, что мне не придется все же заниматься веб-скраппингом, я вооружился старым-добрым Charles и пошел смотреть, а как у Эквио вообще ходят данные.
Сперва самое интересное: как отдается на фронт текст материалов?
Обратим внимание, что материалы у нас бывают разные. И для наших целей нас интересуют сейчас только «лонгриды».
Изначально ожидал, что в лучшем случае текстовый контент я найду в JSON виде строки с куском HTML внутри или просто в виде строк с сырым текстом, однако результат порадовал еще больше: с бэкэнда отдается статья, в markdown-разметке.
{ "success": { "page": { "uuid": "fc3f7d5a-254f-4bbb-a999-5b8da9ca9a17", "longread_id": 12345, "order": 1, "updated_at": 1635758515, "title": "Введение в блок", "body": "%текст статьи, написанный на markdown%", "images": [] } } }Такой поворот событий воодушевляет: значит, получить контент без приключений мы все же сможем, к тому же уже с готовым оформлением (приятный бонус). Markdown мы легко сможем сконвертировать в HTML, который затем уже переведем в PDF.
Однако, чтобы получить такой ответ, нам необходимо в запросе отправить параметры «longread» и «page«, о которых мы пока не имеем представления. Поэтому разберемся с остальными запросами и раскрутим цепочку до конца.
Пройдемся по порядку и изобразим схему, как клиент (браузер) взаимодействует с серверной частью.
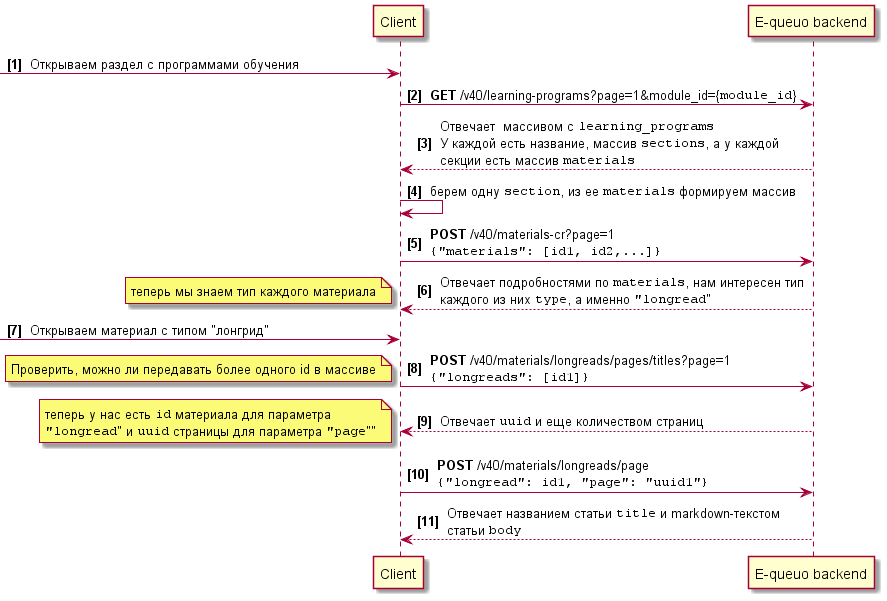
Далее для интересующихся описан более подробно разбор взаимодействия.
Сначала мы открываем список всем программ обучения и уходит запрос GET /v40/learning-programs?page=1&module_id={module_id}
Сервер нам отвечает массивом с «learning_programs«. У каждой программы есть название, массив «sections«, а у каждой секции есть массив «materials«.
// ответ сокращен для компактности, часть параметров исключена { "success": { "learning_programs": [ { "id": 12345, "name": "1.1 Вводное занятие", "order": 38, "sections": [ { "id": 12345, "name": "Введение в блок", "order": 50861, "materials": [ { "id": 12345, "name": "1.1 Введение в блок", "is_required": 1, "order": 1 } ] } ] } ], "meta": { "pagination": { "current_page": 1, "pages_count": 1, "per_page": 20, "total_count": 14 } } } }Далее отправляется запрос POST /v40/materials-cr?page=1, в теле мы передаем массив «materials«, содержащий id материалов, массив сформирован из материалов одной секции.
{ "materials": [12345, 12345, 12345, 12345] }В ответе получаем детальную информацию по каждому из переданных materials, из полезного здесь мы можем получить тип каждого материала, который нам пригодится далее.
{ "success": { "materials": [ { "id": 12345, "name": "1.1 Введение в блок", "image": { // параметры исключены для компактности тела ответа }, "type": "longread", // тот самый тип, который нам интересен "is_rating": 0, "updated_at": 1637272596, "allow_skip_pages": 0 } ], "meta": { "pagination": { "current_page": 1, "pages_count": 1, "per_page": 20, "total_count": 15 } } } }Затем для лонгрида отправляется POST /v40/materials/longreads/pages/titles?page=1. В теле содержится массив из одного элемента с id материала-лонгрида.
{ "longreads": [12345] }Мы с вами внимательные и здесь замечаем, что, поскольку мы открываем конкретный материал, то в запросе передается всего один элемент массива, однако в предыдущем запросе мы видели такой же принцип и можем предположить, что запрашивать лонгриды можно не по одному, а сразу пачкой. К проверке этого предположения вернемся далее.
Ответ здесь сообщает UUID страницы лонгрида, который также нужен, чтобы получить искомый текст.
{ "success": { "page_titles": [ { "uuid": "ccbcd472-9c45-45df-862b-0358c04901f0", "longread_id": 12345, "order": 1, "updated_at": 1635758515, "title": "Введение в блок" } ], "meta": { "pagination": { "current_page": 1, "pages_count": 1, "per_page": 300, "total_count": 1 } } } }И после этого уже идет запрос POST /v40/materials/longreads/page. В теле передается id лонгрида и UUID его страницы.
{ "longread": 12345, "page": "ccbcd472-9c45-45df-862b-0358c04901f0" }В ответе и получаем нужный нам текст. Дело раскрыто, пора переходить к следующему шагу.
Реализация
Выделим основные шаги, которые намечаются к разработке:

В качестве ЯП выбрал Python, просто потому что интересно наработать практику на нем, объем данных в моем случае небольшой, записывать полученные сырые данные никуда не будем, чтобы не усложнять реализацию, а будем держать их в памяти.
Преобразуем диаграмму последовательности, которую мы составили ранее, в более подходящую для нас:
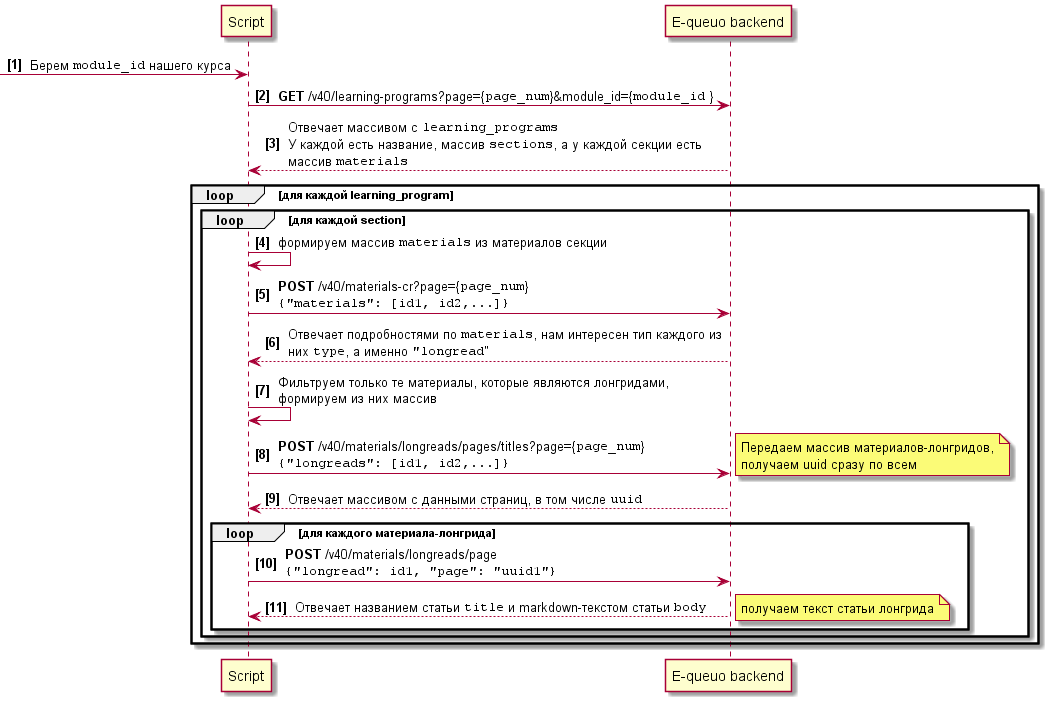
Для улучшения процесса проверили догадку, которая появилась ранее: передали несколько id в массиве «longreads» и получили UUID сразу по всем. Это позволило не отправлять запрос для получения данных по каждому лонгриду, как это делает клиентская часть, а получать данные сразу для нужного количества.
Начнем с авторизации, на ней было принято волевое решение сэкономить и не писать ее вовсе. Повлиял на это также нюанс, что платформа допускает только один активный сеанс авторизации, и при новой завершает прочие сеансы.
Опять смотрим запросы к серверу и видим, что используется Bearer-токен в заголовке Authorization, значит будем использовать его. Сформируем общие заголовки для всех запросов и, чтобы наши запросы были больше похожи на настоящие и не светили в логах каким-нибудь «python-requests/2.26.0«, добавим еще случайный User agent.
Далее нам нужно получить данные программ обучения. Используя схему, описанную выше, получим структуру каждой программы и сложим данные в словарь вида
{ 1234: { # ключ-id программы обучения "name": "2.1 Эмоциональное лидерство", "order": 39, "sections": [ { "id": 12345, "materials": [ {"id": 12345, "name": "1.1 Введение в тему модуля", "order": 1}, { "id": 12345, "name": "1.2 Введение в тему занятия " "“Эмоциональное лидерство”", "order": 2, }, ], "name": "Лидерство — это ответственность", "order": 52013, }, ], }, }Кроме названий и id, полезным оказалось использование order из тела ответа, на основе этого ключа сделаем далее сортировку, чтобы материалы были в том же порядке, что и на платформе.
Затем для каждой программы определим типы материалов, для материалов с типом «лонгрид» получим UUID страниц и сложим это в массив, по которому далее будем получать тексты
[ {"id": 12345, "uuid": "0542f71f-83c4-4572-b37d-74d948c8c03a"}, {"id": 12346, "uuid": "1a7bc1bd-b7e9-487d-968c-87a4f2dfe86c"}, ]И полученные тексты соберем их в отдельном массиве со структурой
[ {"id": 12345, "content": "%markdown-текст%"}, {"id": 12346, "content": "%markdown-текст%"}, ]Далее отфильтруем материалы в общем словаре с программами обучения на основе массива с лонгридами, чтобы оставить только материалы-лонгриды.
Теперь сделаем общие markdown-файлы с контентом. Программы обучения с платформы являются верхним уровнем в структуре (не включая сам курс). Поэтому будем делать файл для каждой программы обучения. Тексты отдельных лонгридов у нас уже есть, теперь их нужно собрать вместе. Для этого просто сконкатенируем их, добавляя перед каждым лонгридом его название в виде markdown-заголовка 1 уровня.
program_content_md += f'# {heading}\n\n\n{text}\n'Однако, поскольку в статьях уже были свои заголовки, я столкнулся с тем, что на 1 уровне были и добавляемые заголовки лонгридов, и уже имеющиеся заголовки статей. Помимо неудобств в оформлении, это помешает нам дальше при формировании оглавления. Соответственно появилась необходимость «сдвинуть» все исходные заголовки на уровень вниз, чтобы на 1 уровне оставались только те, которые мы добавляем сами. Поискав существующие наработки на эту тему, я нашел только расширение для VS Code, в исходниках которого ничего элегантного тоже не было. Поэтому я реализовал свой небольшой велосипед для смещения заголовков:
def shift_headings(md, level=1): shift = '#'*level replaced = re.sub(r'^(#+)', r'\1'+shift, md, flags=re.MULTILINE) return replacedТак получаем markdown-файл:

Дальше нужно сделать оглавление и сконвертировать markdown в HTML. К этому моменту у меня были в голове мысли, как я смогу сделать оглавление: я хотел использовать якорные ссылки markdown на заголовки, однако предвидел проблемы с тем, как это будет переводиться в HTML. Но дело обернулось еще лучше.
Для конвертации я решил использовать популярную библиотеку markdown и в процессе изучения документации обнаружил, что в ней уже реализована возможность сбора оглавления на основе заголовков из markdown-документа. Для этого в ней есть расширение TOC.
Для использования в самом документе необходимо разместить строку-маркер (по умолчанию «[TOC]») в том месте, куда необходимо вставить оглавление, и указать соответствующий аргумент при конвертации. Оглавление будем строить по заголовкам только первого уровня, здесь как раз и пригодилось смещение исходных заголовков на уровень вниз.
html = markdown.markdown(program_content_md, extensions=[ TocExtension(title='Оглавление', toc_depth='1')])Получаем наш конспект уже в формате HTML, а также имеем кликабельное оглавление:

Теперь нужно создать PDF-файл. Для конвертации HTML в PDF использовал библиотеку pdfkit, она работает с утилитой wkhtmltopdf.
Причешем внешний вид выходного файла, используя аргумент options:
options = { 'encoding': 'UTF-8', 'footer-right': '[page]/[topage]', # номера страниц в футере 'footer-font-size': '10', 'footer-center': programs[program_id]["name"], # название программы обучения в футере 'footer-spacing': '5', # отступ от текста для футера 'footer-font-name': 'Roboto', 'margin-top': '16mm', 'margin-bottom': '20mm', 'margin-right': '20mm', 'margin-left': '20mm', 'user-style-sheet': 'pdf.css', # css-файл, который будет использован при конвертации 'disable-smart-shrinking': None, # необходимо, чтобы вручную задать постоянное отношение px/dpi через zoom 'zoom': 0.6112 # вычислил опытым путем для документов, чтобы масштаб везде был одинаковый и подходящий } Path("output/pdf").mkdir(parents=True, exist_ok=True) pdfkit.from_file( f'output/html/{file_name}.htm', f'output/pdf/{file_name}.pdf', options=options)Здесь столкнулся с загвоздкой в виде того, что у wkhtmltopdf по умолчанию включена «автоподстройка» контента под страницу, что с одной стороны дает из коробки правильный масштаб, но с другой на некоторых файлах может привести к неконтролируемому его изменению. Поэтому пришлось поиграться с параметрами и сделать костыль в виде отключения этой опции и вычисления значения для zoom, чтобы результат по крайней мере был предсказуемым.
И поиграемся со шрифтами добавим немного оформления в CSS (размеры текста указаны с учетом выставленного ранее масштаба):
.toc { page-break-after: always !important; } * { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Open Sans', 'Helvetica Neue', sans-serif; } body :not(h1):not(h2):not(h3):not(h4):not(h5):not(h6) { font-size: 24px; } h1 { font-size: 48px; page-break-before: always !important; } h2 { font-size: 36px; } h3 { font-size: 30px; } h4, h5, h6 { font-size: 24px; } .toctitle { font-size: 48px; font-weight: bold; } Получаем на выходе вот такую красоту:


И так создаем конспекты для всех программ обучения

Время выполнения на 19 программах обучения — в среднем 150-170 секунд из-за генерации PDF. Небыстро, но и задачи оптимизации и ускорения мы перед собой не ставили.
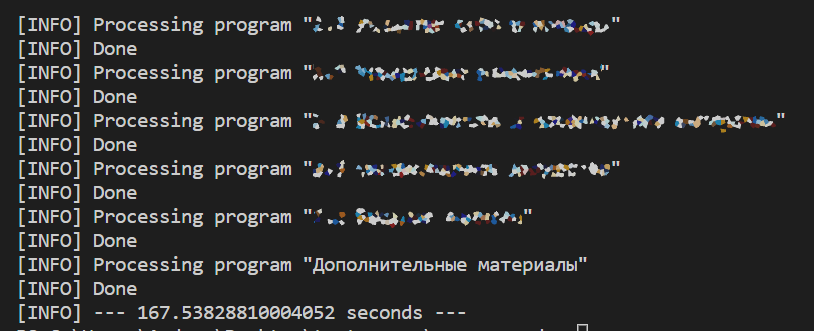
Курс еще в процессе и программы обучения доступны на платформе не все, но при добавлении или изменении материалов теперь можно быстро получить актуальную версию конспекта.
Исходники на Github: https://github.com/anador/e-queo-pdf
ссылка на оригинал статьи https://habr.com/ru/post/664898/
Добавить комментарий