Еще весной 2021 года мы оценивали примерно половину трафика через наш рекламный продукт, как фрод. Для его фильтрации использовали сторонний инструмент, но сами были не в восторге от этого решения — мы вынуждены были платить за его использование, но не могли повлиять на происходившую под капотом “магию”.
Взяв дело в свои руки, мы разобрались в деталях и проработали собственную систему фильтров. После отключения партнеров, подавляющая часть трафика от которых принадлежала ботам, мы сократили долю входящего фрода до 10%. А с этой долей мы легко боремся ловушками в режиме реального времени.
Под катом не раскроем всех секретов, но расскажем о подходе.

В двух словах о решении
Ранее мы уже писали, что разрабатываем собственную биржу Ad Exchange, которая помогает перепродавать трафик. В составе продукта есть так называемый Campaign manager — инструмент, который помогает рекламодателям настраивать кампании, задавая бюджеты и трафик, который должен поступать на их сайт из нашей рекламной сети.
В Campaign manager мы работаем с push-рекламой — как с классическими push-уведомлениями, отображаемыми средствами операционной системы, так и с in-page push, которые появляются на странице в браузере в iframe. Пользователь просматривает рекламу, кликает, если она его заинтересовала, и попадает к нам на бекенд. Далее мы должны перенаправить его на сайт рекламодателя, но все не так просто.
Почему надо бороться с фродом?
В теории пользователю, запросившему рекламу, мы должны просто показать объявление (зарегистрировав клик через промежуточный редирект). Но на практике мы вынуждены оценивать качество трафика и отфильтровывать огромную долю фрода, чтобы деньги рекламодателей не уходили впустую.
С трафиком есть две большие проблемы, которые снижают конверсию рекламодателей (а значит и их мотивацию использовать наши инструменты):
-
Трафик от ботов, которые ничего никогда у рекламодателя не купят. Ботов мы условно делим на два типа:
-
автоматизированные скрипты, созданные средствами для тестирования в браузерах — phantomjs, selenium, puppeteer, playwright и другими. С их помощью браузер сам “нажимает” определенные кнопочки, эмулируя просмотр рекламы пользователем;
-
код JavaScript, встроенный в легитимную страницу, которую просматривает пользователь (код делает вид, что пользователь загрузил рекламу и кликнул по объявлению, перейдя на сайт рекламодателя).
-
-
Трафик не того ценового диапазона. Push-трафик стоит дорого, за него и платят рекламодатели. Но бывает, что определенный источник приводит к нам трафик с иного типа рекламы, чтобы взять больше денег с наших рекламодателей. Мы отфильтровываем таких паблишеров, защищая интересы рекламодателя, несмотря на то, что по такому каналу к нам могут приходить вполне легитимные пользователи. В конце концов, наш клиент должен получить то, за что платит.
По нашим оценкам на тот момент, когда мы занялись проблемой фрода, все эти запросы составляли примерно половину всего входящего трафика. В практическом смысле это означает низкую конверсию и огромную лишнюю нагрузку на наши сервера.
Изначально для быстрого выхода на рынок мы использовали стороннее средство фильтрации. Но для нас оно оказалось плохим выбором по нескольким причинам:
-
в процессе работы инструмент стучался на свои сервера,
-
была неясная магия под капотом,
-
это загрузка еще одной внешней зависимости,
-
инструмент вносил довольно много потерь трафика,
-
у него были ложноположительные срабатывания,
-
в ходе эксплуатации мы натыкались на ошибки, которые на некоторое время отключали нам фильтрацию.
А еще инструмент не учитывал специфику push-рекламы, не позволяя выявлять трафик не того ценового диапазона. Фактически, он давал оценку, является ли пользователь ботом, но на этом всё.
Пытаясь подобрать более удачную альтернативу, мы пробовали разные решения, но не нашли ни одного подходящего. В итоге нам пришлось погрузиться в тему самостоятельно.
Далее поговорим о том, как мы организовали фильтрацию.
Редиректы и промежуточные страницы
Оценку и фильтрацию фрода мы осуществляем с помощью промежуточной страницы, на которую попадает пользователь, запросивший рекламу.
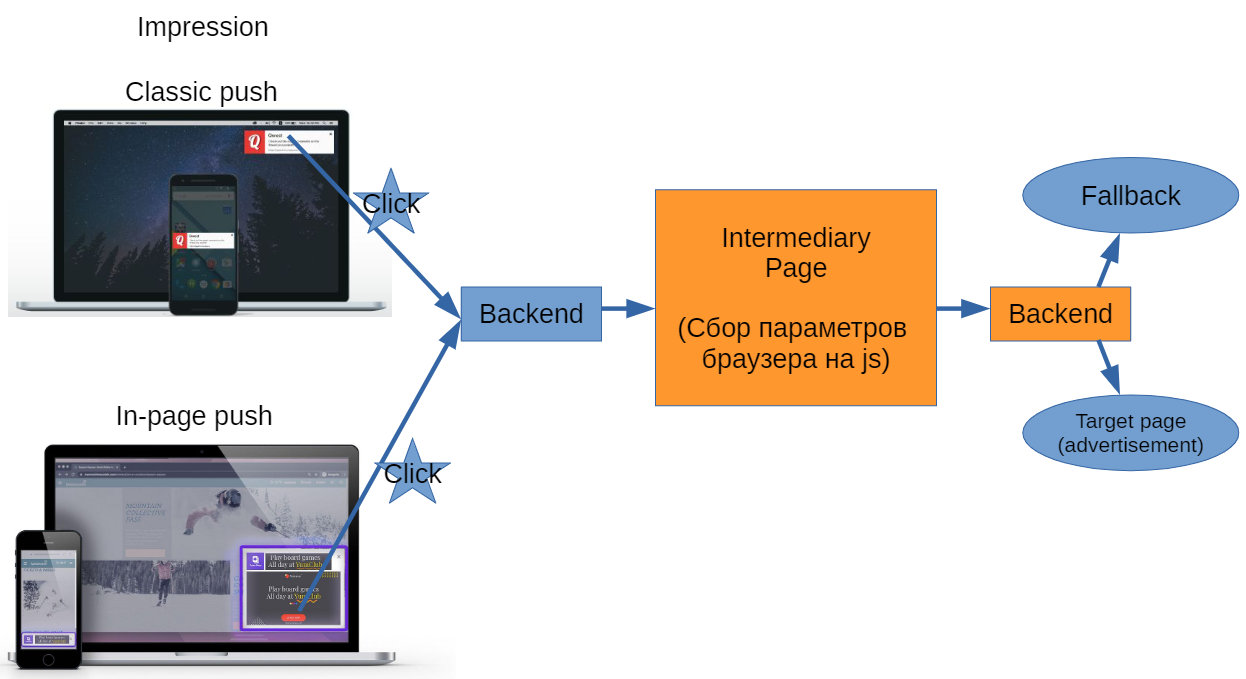
На этой странице мы собираем параметры браузера и прочие доступные данные — они отправляются на бекенд, где мы принимаем решение, показывать ли в ответ на этот запрос объявление нашего рекламодателя. Тем, кого отбросили, мы показываем заглушку, остальным — настоящее рекламное объявление. Рекламодатель же видит высокую конверсию и ценит инструмент за качественный трафик.
В ходе экспериментов мы реализовали несколько вариантов промежуточной страницы:
-
Minimal — страница, которая не собирает ничего и в обычном режиме не используется (т.е. на нее отправляется 0% кликов). Ее реализовали, чтобы понять как сам факт “лишнего” редиректа на промежуточную страницу влияет на процесс перехода пользователя на сайт рекламодателя. Выяснилось, каждый редирект отсеивает порядка 5-7% кликов. Увы, устанавливая фильтрацию, мы вынуждены с этим мириться.
-
Light — страница, которая используется большую часть времени (на нее отправляется 95% трафика). Этот вариант промежуточной страницы, который собирает только основные параметры, на ней мы теряем около 16% пользователей. Это чистые потери — те, кто не преодолевают эту страницу по неизвестным нам причинам. Это могут быть боты, которые не способны исполнять JavaScript, или люди с мобильными устройствами и плохим интернет-соединением, которые просто не дожидаются, пока промежуточная страница загрузится и отработает. Мы спокойно относимся к этим потерям, поскольку ни первые, ни вторые не принесут никакого профита рекламодателю. Как и во время редиректа, они просто не дождаться загрузки целевой страницы.
-
Normal — страница, на которой мы собираем порядка 140 различных параметров — кто и откуда пришел, с каким браузером, какую рекламу запросил и т.п. С помощью нее мы в реальном времени мониторим трафик от партнеров и выделяем фрод. Также на этой странице у нас раньше работала внешняя система определения фрода. С ее помощью мы проверяли некоторые свои гипотезы. Сбор такого количества параметров и работа сторонней системы с точки зрения потерь трафика не бесплатны, не преодолевают эту страницу порядка 32% пользователей.
В зависимости от задачи, мы перенаправляем трафик между промежуточными страницами. В обычном режиме используем Light. Надо провести эксперимент с новой ловушкой — подключаем Normal. А в каких-то исключительных ситуациях возвращаем Minimal.
Как осуществляется фильтрация
Входящий трафик мы фильтруем при помощи разработанных ловушек, оценивающих один или несколько собранных параметров. Для каждого из типов фрода мы постепенно развиваем свои ловушки — отслеживаем параметры, строим гипотезы, проверяем их на небольшой доле пользователей и внедряем, если проверка оказалась успешной — если фильтр по этому правилу действительно повышает качество трафика. Каждая ловушка позволяет отсечь определенную долю фрода, но ее работа “не бесплатна” с точки зрения производительности. Поэтому мы отдаем приоритет тем, у которых эффективность выше.
Раскрыть все ловушки — значит дать ботоводам в руки инструмент для обхода нашей системы антифрода. Но мы можем привести несколько примеров, по которым будет понятен подход.
Ловушка по времени (Low time to click)
Мы отслеживаем время, которое проходит между действиями пользователя с одним и тем же IP-адресом и UserAgent. Легальные пользователи не могут с пренебрежимо малой разницей во времени кликнуть на несколько рекламных объявлений или ткнуть на рекламу сразу же после загрузки иконки (время между загрузкой иконки и кликом не должно быть мало). Если ловушка “срабатывает” на определенной доле трафика от партнера, это повод обратить на него внимание.
Ловушка High CTR
CTR (click-through rate) — это известный параметр для анализа эффективности рекламных кампаний, равный отношению количества кликов к количеству показов. Как правило, он измеряется в процентах, отражая, какой процент показов рекламы обернулся кликами и переходом на сайт рекламодателя.
Мы измеряем это значение и сравниваем с ранее зафиксированными. Такая ловушка имеет смысл не для конкретного посетителя, а для источника трафика. Обычно CTR не велико, не более нескольких процентов. Слишком большое значение — признак фрода.
Ловушка по размеру окна
Логика подсказывает, что окно с документом у легального пользователя должно быть адекватных размеров. Мы отфильтровываем весь трафик, для которого window.innerWidth меньше 200, а window.innerHeight меньше 100. Это очень скромно даже для современных мобильных телефонов, в у ботов эти параметры обычно равны 0.
Любопытно, что мы натыкались и на ошибки этого правила — когда параметры равны 0, но пользователь приходит на сайт рекламодателя и совершает целевые действия. Позже мы нашли объяснение — появились боты нового поколения, которые периодически заходят на сайт рекламодателя, чтобы ML-инструменты их не засекли. Нам нужно их банить, но велика вероятность ложного срабатывания на легальных пользователях. Поэтому в нашей команде пока нет однозначного мнения на тему этого правила — мы продолжаем эксперименты.
Ловушка по наличию объекта
Большая часть пользователей приходит с браузера Chrome, поэтому мы можем себе позволить ставить браузер-специфичные ловушки. И этот пример — одна из них.
У легального пользователя в окне должен присутствовать объект window.chrome (т.е. он не должен быть undefined). При этом многие ботоводы скрывают браузер и зачем-то убирают этот объект. Так что мы фильтруем трафик, если в ответ на запрос этого объекта получаем undefined. Здесь ловушку упомянули для примера, поскольку сейчас она отключена (на Firefox она начала давать много ложных срабатываний).
Не все правила уходят в прод. К примеру, мы предполагали, что у легального пользователя User Agent у запроса, клика и иконки для картинки, которую ему в итоге показывают, должны совпадать. Установили такую ловушку, но получили слишком много ложных срабатываний. Оказалось, что многие партнёры при передаче строк User Agent через query-параметры запросов допускают разные вольности.
Контроль качества фильтрации
Мы довольно лояльно подходим к фильтрации — отсеиваем трафик, только если на 99% уверены, что это фрод. Выше мы уже упоминали, что перед внедрением очередной ловушки проверяем, насколько качественно она работает. Вот, как это происходит.
Самый простой подход — посмотреть в Clickhouse и оценить глазами параметры отфильтрованного трафика. В ручном режиме заметны различные отклонения трафика, которые дают идеи для новых ловушек.
А еще мы можем посмотреть на качество трафика со стороны рекламодателя — оценить конверсию, когда пользователь, переходит по рекламе и совершает некие действия на сайте. Когда целевое действие выполнено, рекламодатель сообщает нам об этом. Мы набрали уже достаточное количество данных и можем анализировать, какой трафик не приносит конверсии. Зачастую это свидетельствует о том, что трафик генерируют боты. И это помогает нам искать новые ловушки или проверять, насколько эффективно работают старые.
Мы можем анализировать не только запросы одного пользователя, но и весь трафик, приходящий от определенного партнера. И мы действительно сталкивались с тем, что от некоторых паблишеров поступает в основном фрод. Мы включаем такие сайты в черный список и разбираемся подробнее, что происходит.
Для анализа доли трафика, выделенной по определенным параметрам, мы используем CatBoost. Это довольно эффективный классификатор от Яндекса, который хорошо работает с категориальными признаками. Мы забрасываем в него данные трафика, а на выходе получаем список значимых параметров, на основе которых можно создавать новые правила. Ко всему прочему CatBoost умеет создавать матрицу значимости признаков, так что мы вытаскиваем из него много интересного (конкретно — какие именно свойства этой доли трафика выявляют в нем фрод).
А вот дальше автоматической работы нет — с партнерами вопросы решаются на уровне менеджмента. И у нас были прецеденты отключения партнеров, поставляющих много мусорного трафика, особенно вначале. После такой “чистки” списка партнеров доля фрода сократилась с 50% до 10%, которые мы отлавливаем правилами.
В последнее время мы параллельно пошли и по другому пути — начали смотреть на инструменты автоматизации, с помощью которых создаются боты. Например, анализируя исходный код продукта и его плагинов, нашли несколько маркеров в Puppeteer. Проблема в том, что недавно в инструменте был проведен полный рефакторинг и есть пул-реквесты, исправляющие найденные нами “дыры” в скриптах ботоводов. Теперь нам предстоит изучать новую версию системы, чтобы понять, как ее ловить. Точно также мы изучаем новые версии браузеров — в них появляются новые свойства, по которым можно делать выводы о качестве трафика.
В целом борьба с фродом оказалась интересной задачей, которая постоянно подкидывает новые вопросы.
P.S. Мы публикуем наши статьи на нескольких площадках Рунета. Подписывайтесь на нашу страницу в VK или на Telegram-канал, чтобы узнавать обо всех публикациях и других новостях компании Maxilect.
ссылка на оригинал статьи https://habr.com/ru/company/maxilect/blog/668562/
Добавить комментарий