
Серверные вычислительные ресурсы распределяются между большинством сервисов Яндекса централизованно. Тем самым все команды — и существующие давно, и собранные вокруг небольших экспериментов — получают мощности, которые им необходимы, чтобы сервис бесперебойно и быстро работал у всех пользователей. Однако этим распределением нужно управлять.
Меня зовут Сергей Фомин, я разработчик Yandex Planner. Мой пост будет посвящён тому, как мы эффективно решаем задачу планирования вычислительных мощностей.
Сначала я расскажу, что такое Yandex Planner и почему мы решили писать своё решение. После этого мы поговорим про то, в чём заключается задача планирования, почему она не такая простая, как может показаться на первый взгляд. И в качестве одного из способов решения задачи мы рассмотрим дефрагментацию ресурсов. Поехали.
Что такое Planner
Yandex Planner (YP) — система, которая управляет вычислительными ресурсами кластера. В её обязанности входит:
- Иметь представление о том, какие вычислительные ресурсы у нас имеются. Но этого мало.
- Управлять этими ресурсами — раздавать их конечным пользователям. Под пользователями здесь и дальше я буду иметь в виду разработчиков, которые заказывают вычислительные мощности под свои сервисы. Они должны уметь приходить в систему и делать заказы.
- Предоставлять отдельный API, чтобы компоненты системы тоже взаимодействовать с YP.
Yandex Planner существует уже около четырёх лет и управляет более чем 75-ю процентами вычислительных мощностей в компании — включая ресурсы наших суперкомпьютеров. То есть, скорее всего, подавляющее большинство ресурсов сервиса Яндекса, которым вы пользуетесь, управляются именно YP.
В абсолютных числах YP управляет более чем 50-ю тысячами хостов и более чем двумя миллионами вычислительных ядер. Номинальная утилизация вычислительных ресурсов, которую мы достигаем, в пике составляет 97%. И это, как мы с вами увидим, не так уж мало.
Сравнение с k8s
Проще всего прочувствовать, что такое YP, если сравнить его архитектуру с архитектурой его прямого конкурента в мире опенсорса — Kubernetes. Вот очень высокоуровневая архитектура одного кластера Kubernetes:

В кластере есть компоненты, которые называются мастерными. Туда входят API-серверы, через которые и пользователи, и разные компоненты Kubernetes взаимодействуют с системой. В мастерные компоненты также входит планировщик, который расселяет заказы конечных пользователей на конкретные физические хосты. К мастерным компонентам относят и какое-то количество контроллеров, которые управляют объектами Kubernetes.
На железных машинах в кластере Kubernetes присутствуют специальные агенты, которые называются Kubelet, их задача — управлять ресурсами одного конкретного хоста, запускать на нем контейнеры конечных пользователей.
Самая интересная для нас часть будет в том, что в качестве storage Kubernetes использует etcd.
Чем YP похож на Kubernetes и чем от него отличается?

Архитектура кластера Яндекса
Общего, на первый взгляд, очень много. Тоже есть некоторое количество мастерных компонент: API серверы, планировщик, какое-то количество контроллеров, которые управляют объектами в YP. На хосте тоже присутствует агент, который управляет ресурсами хоста. У нас, конечно, свой агент, но он существовал задолго до YP. Мы его, можно сказать, подобрали в свою архитектуру.
Интересная часть — в левом нижнем углу. В качестве storage YP использует YT, а основная часть информации YP хранится в динамических таблицах. Это горизонтально масштабируемые key-value storages. Кроме того, некоторое количество информации хранится в Cypress — реплицированном хранилище мета-информации.
Если отойти на шаг назад, то можно увидеть следующую картину:
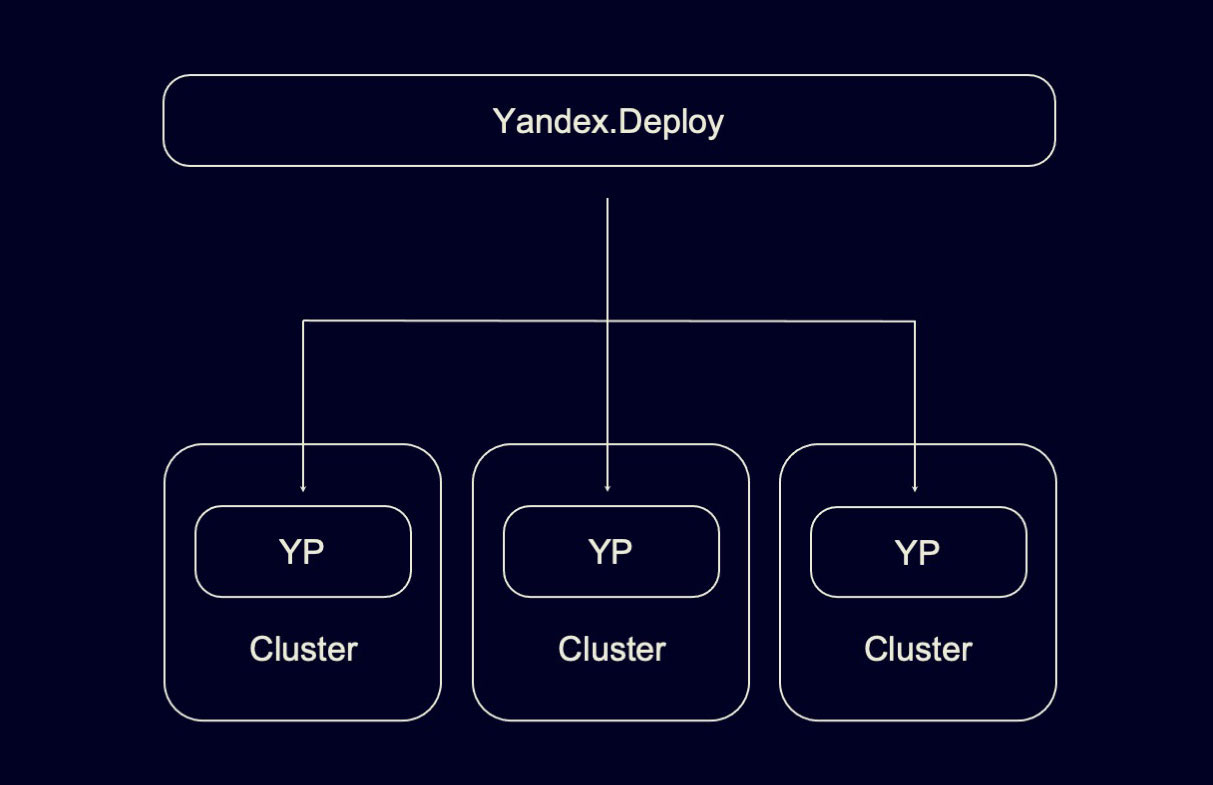
У Яндекса несколько дата-центров, в каждом из которых существует своя независимая инсталляция YP, которая управляет вычислительными ресурсами только этого ДЦ.
Но вы как конечный пользователь, конечно, не хотите создавать сервис в нескольких инсталляциях YP. Вы хотите прийти в центральную точку и создать сервис в ней, а дальше она расскажет всем инсталляциям YP, где и сколько есть инстансов, в которых живет сервис.
В архитектуре нашего внутреннего облака такой точкой входа в систему для конечных пользователей является Yandex Deploy. В этом смысле YP — полноправная инфраструктурная компонента: как правило, конечные пользователи взаимодействуют не с YP напрямую, а с Deploy или с некоторыми другими системами.
Давайте вернемся к вопросу, почему мы решили делать YP, а не воспользовались Kubernetes.
- Главная причина в масштабируемости. По данным на официальном сайте, Kubernetes поддерживает до пяти тысяч хостов на один кластер. Для большинства пользователей Kubernetes этого более чем достаточно. Но у Яндекса абсолютно другие масштабы, поэтому мы были вынуждены разрабатывать YP таким образом, чтобы он мог поддерживать десятки тысяч машин на один кластер. Самая большая инсталляция, которая у нас сейчас есть, составляет чуть более 30 тысяч хостов на один кластер.
Казалось бы, зачем иметь кластеры большего размера? Можно просто создать много кластеров размером поменьше. Но если бы у нас было много кластеров размером поменьше, мы бы не смогли эффективно решать задачу получения высокой утилизации вычислительных ресурсов. Потому что когда у вас, к примеру, один кластер на 30 тысяч машин, вам намного проще перераспределять внутри него вычислительные ресурсы.
Вы можете часть сервисов передвинуть на хосты, которые сейчас не используются, но где-то этому сервису нужны. Если бы у вас было, например, шесть независимых инсталляций Kubernetes по пять тысяч хостов на кластер, такая задача была бы намного более проблематичной.
- Если у вас много маленьких кластеров, вам нужен планировщик второго уровня, который будет по этому большому количеству кластеров размещать сервисы. Если же у вас маленькое количество кластеров, которые сами по себе большие, вам достаточно того планировщика, который внутри кластера присутствует.
- И не последнюю роль сыграло то, что у Яндекса накопилась большая экспертиза в эксплуатации YT как хранилища. Думаю, ни для кого не секрет, что большинство проблем, которые возникают с высоконагруженными системами, возникают именно на уровне storage. Намного приятнее, когда разработчики этого storage, которые непосредственно пишут для него функциональность, находятся в 15 метрах от вас и их можно подонимать вопросами, почему что-то начинает тормозить. С нагруженными системами такое нередко происходит.
Я надеюсь, что убедил вас, что мы не просто так взяли и написали что-то свое, что у нас были для этого причины. Давайте теперь поймем, как мы достигаем высокой утилизации вычислительных ресурсов. Для этого нам придется сначала погрузиться в то, в чем заключается задача планирования этих ресурсов.
Планирование ресурсов
Знакомьтесь, наш типичный подопечный — самый простой сервер:

У сервера есть какое-то количество ресурсов, которыми конечный пользователь хочет воспользоваться, вычислительных ядер, памяти. И, как минимум, ещё есть storage. Он интересен тем, что бывает разный: в виде твердотельных накопителей (более дорогих и с более высокой пропускной способностью) или жёстких дисков (дешёвых, с невысокой пропускной способностью).
Конечный пользователь, как правило, хочет иметь возможность заказать конкретный класс storage: либо твердотельные накопители, либо HDD. И в рамках этого заказа сказать, сколько ему потребуется места на накопителе и сколько потребуется пропускной полосы.
Мы конечному пользователю даём возможность задавать все эти параметры с высокой гранулярностью, заказывать ядра с точностью до одной десятой ядра, заказывать память и storage с точностью до байта, а пропускную способность storage — с точностью до одного байта в секунду. То есть задача планирования приобретает многомерный вид. Кто же будет потреблять все эти ресурсы, которые у железного хоста есть?
Ни для кого не секрет, что в облаке главным потребителем ресурсов являются контейнеры. Они интересны тем, что, как правило, конечный пользователь не хочет заселить один контейнер на хост. Он хочет заселить некоторую пачку контейнеров.

Предположим, у конечного пользователя есть веб-сервис. Тогда в эту стопочку контейнеров может входить как контейнер, в котором находится код веб-сервиса, так и некоторые служебные контейнеры. Например, пользователь наверняка хочет собирать логи сервиса, чтобы их агрегировать и проводить по ним аналитику. Этим часто занимается отдельный контейнер. И наверняка у пользователя есть необходимость в аутентификации. Обычно задачами аутентификации тоже занимается отдельный контейнер. Такая стопочка контейнеров, которую пользователь обязательно хочет поселить на один хост, и в терминологии Kubernetes, и в YP называется подом.
Но пользователь, думая о деплое своих компонентов, как правило, хочет деплоить конкретные поды не по отдельности, а группами, компонентами деплоя. Такая компонента называется Pod Set. Это просто объединение подов в некоторую более высокоуровневую сущность.

Вооружившись этим пониманием, давайте попробуем решить конкретную задачу планирования. Например, у нас есть 16 хостов. Надо же с чего-то начинать? Мы не сразу перейдем к десяти тысячам. Каждый хост находится в стойке. У нас будет две стойки по восемь хостов.

Есть сервис, у сервиса — какое-то количество компонент деплоя. Если это простой сервис, то у него точно есть фронтенд, бэкенд и фоновые процессы. Возможно, бэкенд не один, но ограничимся простым случаем. Каждая из этих компонент деплоя представлена отдельным Pod Set. В рамках каждого Pod Set, как мы уже поняли, находится какое-то количество подов. Поды — единица планирования для планировщика: они обладают заказом, и планировщик должен удовлетворить заказы этих подов. Как он мог бы их удовлетворить? Давайте попробуем решить задачу конкретно для этих 16 машин и девяти подов.
Если у каждой машины 64 ядра, то решение могло бы выглядеть просто: селить сервисы на хосты максимально равномерно.

У нас было девять подов и 16 машин. Каждому поду мы выделили целую машину, и даже ещё остались пустые хосты. Идея проста, но может возникнуть проблема. Что если в следующий момент времени — через час, день или даже через неделю — приходит сервис, который хочет заселить два пода размерном в 60 ядер. При этом он обязательно хочет, чтобы поды были в разных стойках, это довольно стандартное требование от пользователей (часто они хотят иметь гарантии на отказоустойчивость). И такой заказ представляет при текущем расселении проблему, потому что у нас просто нет таких двух хостов, что каждый находится в отдельной стойке и на каждом есть 60 свободных ядер.
Наверное, решение, которое мы приняли на прошлом шаге, было плохим. Давайте попробуем другой подход. Он мог бы выглядеть так:

Давайте селить поды максимально плотно. Мы взяли те же самые девять подов и расселили их всего лишь в три хоста. Оставшиеся 13 хостов у нас остались пустыми. Но и это тоже может быть проблемой: в следующий момент времени приходит пользователь и создает 15 подов, каждый из которых заказывает восемь ядер. И мы опять такой заказ удовлетворить не можем: на кластере просто нет 15 хостов с восемью свободными ядрами. У нас только 13 таких хостов.
Какие выводы можно сделать? К сожалению, любое решение о расселении подов, которые вы примете прямо сейчас, в будущем может оказаться максимально плохим, потому что вы не знаете будущего. Следовательно, в текущей модели в том виде, в котором вы ее сформулировали, задача оптимального планирования не решается, и нам придется с этим что-то сделать.
Действительно ли проблема большая?
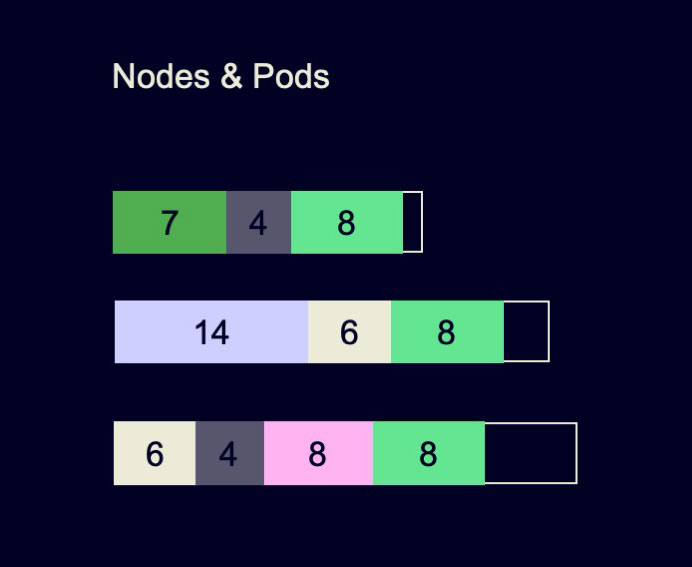 Оптимально расселить поды на хосты мы, кажется, не можем. Но если мы закроем глаза и притворимся, что проблемы нет, то, может быть, в итоге получим не очень плохую утилизацию вычислительных ресурсов?
Оптимально расселить поды на хосты мы, кажется, не можем. Но если мы закроем глаза и притворимся, что проблемы нет, то, может быть, в итоге получим не очень плохую утилизацию вычислительных ресурсов?
Проверим такую гипотезу. Для этого проведём базовый эксперимент. Возьмём текущий кластер с тем количеством подов и хостов, которые под этим подом лежат. И будем делать следующее: создадим один под понятного размера в восемь ядер и 32 гигабайта памяти, поселим его на кластер и будем повторять эту операцию, пока не придём к неудаче. Однажды мы такой под уже не сможем заселить.
В этом примере мы смогли заселить целых три светло-зеленых пода и на этом остановились. То, что осталось, — недоутилизированные ресурсы, которые уменьшают нашу утилизацию.
Когда мы провели эксперимент на реальном кластере, то утилизация CPU, которой можно достичь, составила 90,4%. Много это или мало? Давайте попробуем понять.
Один сервер стоит порядка десяти тысяч долларов. Это значит, что на каждые десять тысяч машин, если вы откуда-то достанете один процент утилизации, или, наоборот, по каким-то причинам потеряете его, этот один процент эквивалентен одному миллиону долларов.
На наших масштабах машин десятки тысяч — как минимум, 50 тысяч. Если мы сможем получить 95% утилизации вместо 90%, это будет эквивалентно как минимум 25 миллионам долларов. За них, кажется, можно побороться. Бороться мы будем с помощью подхода, который заключается в дефрагментации вычислительных ресурсов.
Дефрагментация ресурсов
В чём была проблема, которая мешала нам достигать высокой утилизации? Мы не можем предсказывать будущее. Можем принять решение сейчас локально, но не знаем, с каким заказом пользователи придут к нам через какое-то время. У нас было несколько вариантов решения этой проблемы. Сначала мы честно пошли на hh.ru и искали там предсказателей. Но оказалось, что всех предсказателей, очевидно, уже взяли в Яндекс Браузер.

Это реальный скриншот с hh.ru. Почему-то Яндекс Браузеру нужны предсказатели. Так что этот план провалился. Но мы не отчаялись.
Если в текущей модели задачу оптимального планирования решать нельзя, давайте эту модель расширим. И расширим мы её, добавив операцию eviction, по-русски «выселение». Это просьба к поду уехать с хоста. Eviction проходит в два этапа. Сначала мы запрашиваем eviction через API, а потом внешняя система подтверждает eviction или отменяет его. Этап подтверждения необходим, потому что YP сам по себе не знает, в каком состоянии находятся поды, с которыми он работает.
Мы, конечно, очень не хотим выселить виртуальную машину разработчика, у которого не закоммичены изменения. Он нам спасибо не скажет. Информация о том, в каком состоянии находятся поды и можно ли их выселить, находится в более высокоуровневых системах, например в Yandex Deploy.
Обычно выселение происходит за десятки минут. Как правило, меньше, чем за полчаса. Если мы говорим про тяжёлые виртуальные машины разработчиков, то выселение может сходиться и за часы, но такие поды мы обычно стараемся не трогать. Сервисы, у которых небольшой стейт или вообще нет стейта, обычно могут освободить хост за 10-20, иногда 30 минут. Вооружившись этой операцией, давайте попробуем предложить какой-нибудь план, как нам всё-таки достигнуть высокой утилизации.
Реактивная дефрагментация
 Предложенный план называется «реактивная дефрагментация», потому что пока на кластере всё хорошо, он ничего не делает.
Предложенный план называется «реактивная дефрагментация», потому что пока на кластере всё хорошо, он ничего не делает.
Что значит «всё хорошо»? Если на кластере нет подов, которые мы сейчас не можем заселить, значит, можно предположить, что проблемы нет. Но рано или поздно такой под появится и нам придётся его спасать. Если в маленьком кластере из трёх машин на каждой из них находится два пода, на 32 и восемь ядер, а суммарно на машине 64 ядра, то ещё 24 свободны.
Когда мы смотрим на такой кластер, неочевидно, есть ли проблема. Но она становится очевидной, если в следующий момент пользователь придёт и создаст под на 40 ядер заказа. На нашем кластере присутствует 40 свободных ядер, но мы не можем найти их для этого пода. Значит, нам нужно что-то придумать.
Конкретно в этом случае мы могли бы рассмотреть такой план: взять центральный под на восемь ядер и переселить его на первый хост. Потом светло-зеленый под на 32 переселить на освободившиеся ядра второго хоста. Под на 40 ядер мы тогда сможем переселить на нижний хост. Здесь возникает другая проблема: как мы будем такие планы составлять? Задача, как мы уже поняли, многомерная, сложная.
Решение ILP
На наше счастье, есть математическая постановка, которая называется задачей о целочисленном линейном программировании, integer linear programming. И мы можем сформулировать задачу планирования как задачу о целочисленном линейном программировании. Нам здесь помогает то, что мы максимизируем линейную целевую функцию:


То есть мы максимизируем количество заселённых на хост подов.
Рассмотрим матрицу, каждой строчке которой соответствует какой-то под, каждому столбцу — какой-то хост, а на пересечении строчки и столбца находится бинарная переменная, равная нулю, если данный под на данный хост не заселён, и единице, если заселён. Мы просто максимизируем сумму элементов такой матрицы, количество заселённых подов. Но я немножко обманываю, когда говорю это. Нам, конечно, нужны ещё какие-то ограничения, иначе матрица, состоящая из единиц, отлично максимизирует весь наш целевой функционал.
Ограничения, которые в нашем случае накладываются, к счастью, тоже линейные. Например, простое и понятное ограничение: никакой под не может быть заселён больше чем на один хост. Оно формулируется как набор линейных неравенств на каждый под:

Другое естественное ограничение — мы не можем раздать больше CPU хоста, чем у него есть. Такое ограничение тоже формулируется как набор линейных неравенств:

Здесь Rpod — число заказанных CPU подом pod, а Cnode — число CPU у ноды node. Есть ещё несколько линейных неравенств: как минимум, ограничения на память и другие ресурсы, на то, какие поды с какими мы можем селить на один хост или в одну стойку. Но все эти ограничения укладываются в линейную модель.
Мы сформулировали задачу о целочисленном линейном программировании, но теперь нам надо её решить. Плохие новости: решение целочисленных линейных программ — NP-полная задача. Вы не можете просто взять максимально большую целочисленную линейную программу и решить её оптимально за разумное время.
Хорошие новости тоже есть. Целочисленные линейные программы — практически значимый класс задач, которые людям решать приходилось и приходится. Человечеству известны подходы, способные решать небольшие целочисленные линейные программы. Мы, например, используем wrapper над солверами, который называется Google OR-Tools, с солвером CBC. Он неплохо решает задачи размером 15–20 нод или 100–150 подов. «Неплохо» значит, что где-нибудь за полминуты он справляется и даёт оптимальное решение.
Но мы до этого говорили про десятки тысяч машин, а сейчас вдруг говорим про 15–20 хостов. Отсюда следует, что эти хосты нужно ещё уметь выбирать. Но про это можно написать целую отдельную статью. Вот мой доклад — более технический и длинный. В нём я рассказал больше интересных деталей, кому интересно, посмотрите.
Плюсы у предложенного реактивного подхода многообещающие:
- В первую очередь, мы можем исправлять ошибки, которые допустили в прошлом. Вчера мы как-то расселили по хостам поды, которые у нас были. Если нам сегодня это решение уже не кажется таким хорошим, мы можем эти вчерашние поды выселить, заселить их на новые места, таким образом исправить свою ошибку и в итоге увеличить утилизацию железа.
- Ещё один большой плюс: приносимую пользу реактивной дефрагментации легко пронаблюдать. У вас был кластер, на нём было десять незаселённых подов, которые никак не могли заселиться. Пришёл реактивный дефрагментатор, кого-то куда-то подвигал, и эти десять подов заселились. Это откровенная, ничем не прикрытая польза, которая видна невооруженным взглядом.
Минусы тоже есть:
- По построению реактивная дефрагментация не может предотвратить наступление проблемы, потому что пока мы проблему не заметили, то ничего не делаем.
- А проблема, которую мы замечаем, — это что поды не селятся. Когда мы её заметим, то есть когда она наступит, нам может потребоваться масса переселений, чтобы поды конечного пользователя нашли себе хосты. В терминах пользователей это значит, что понадобится много времени: каждое переселение потенциально занимает десятки минут. Пользователи могут быть недовольны, что мы долго не можем их заселить.
Если бы реактивный дефрагтментатор был супергероем…

В параллельной вселенной, где инфраструктурные компоненты превращаются в супергероев, реактивный дефрагментатор был бы тем, кто большую часть времени ничего не делает, но в слабо предсказуемые моменты превращается в чудовище, которое начинает наносить непоправимое добро налево и направо.
Отталкиваясь от плюсов и минусов реактивной дефрагментации, сформулируем другой принцип.
Проактивная дефрагментация
Можем сделать интересное наблюдение: целочисленное линейное программирование способно решить любую задачу, которую мы в состоянии сформулировать как линейную целевую функцию. Мы до этого просто максимизировали количество заселённых подов. Но мы можем максимизировать нечто другое, лишь бы оно было линейным. Например — количество эталонных подов, которые потенциально могут быть заселены на наш кластер.
В том числе мы можем взять за эталон простой под из восьми ядер, 32 гигабайт памяти, 300 гигабайт жесткого диска и говорить: это наш золотой под. И максимизировать именно количество заселяемых подов такого вида. Можно даже пойти немножко дальше и зафиксировать несколько разновидностей эталонных подов, даже присвоить им веса, сказать, что такие поды нам нравятся больше, а такие — меньше. И максимизировать взвешенную сумму подов, которые потенциально могут заселиться на кластер.
Из абсолютно другой оперы — можно минимизировать количество подов, принадлежащих одному сервису и при этом находящихся в одной стойке. Таким образом мы улучшим отказоустойчивость сервисов, заселённых на нашем кластере.
Плюсы такого подхода зеркально отражают недостатки предыдущего:
- Проактивный дефрагментатор наносит пользу, даже если на кластере вроде бы всё хорошо и все поды заселились. Потенциально это значит: если мы хорошо сформулировали целевую функцию, проблема может и не наступить.
- Но если она наступит, то, скорее всего, количество переселений, которое нам придётся сделать, будет меньше, чем если бы мы вообще ничего не делали. Конечным пользователям придется меньше ждать момента, когда они смогут заселить свои поды.
Минус, кажется, один, но довольно существенный:
- Очень непросто убедить себя, что проактивный дефрагментатор действительно наносит пользу. Вы смотрите на свой кластер, в нём вроде бы всё хорошо, а проактивный дефрагментатор всё равно что-то куда-то выселяет. И вы не можете понять, а действительно ли он делает это, принося пользу, или ему просто так захотелось и он зазря эвакуирует сервисы, хотя мог бы этого не делать.
Если бы проактивный дефрагтментатор был супергероем…

В той же параллельной вселенной, где инфраструктурные сервисы становятся супергероями, проактивный дефрагментатор был бы тем, кто принимает странные и плохо объяснимые в моменте решения, но они имеют далеко идущие последствия.
Итог
Что мы сделали, вооружившись всем тем, о чём я рассказал? Мы разработали сочетание реактивной и проактивной дефрагментации и внедрили его на всех продакшен-кластерах Яндекса, на десятках тысяч машин.
Эффективность дефрагментации мы показали как в экспериментах, так и на реальных кластерах. По нашим метрикам мы получили, что дефрагментация поднимает потенциальную утилизацию кластера на 5-7 процентов на реальном кластере. Это эквивалентно экономии в десятки миллионов долларов.
Напомню ссылку, по которой доступен мой более развернутый, более технический доклад про дефрагментацию.
ссылка на оригинал статьи https://habr.com/ru/company/yandex/blog/564510/
Добавить комментарий