
Привет,
Это статья нашего бывшего коллеги, Андрея Лукьяненко, который работал над проектом по созданию медицинского чат-бота. Андрей покинул нашу компанию по собственному желанию (и с большим сожалением для нас), но несмотря на это, мы решили опубликовать его материал. Мы уверены, что эта статья будет полезна всем, кто работает над созданием специализированных чат-ботов.
Итак, передаем слово Андрею Лукьяненко, бывшему техлиду MTS AI.
В последние годы рынок телемедицины (дистанционных медицинских услуг) и в целом медтеха активно растет, и пандемия коронавируса только ускорила его развитие. Такие технологии востребованы, потому что они относительно дешевы, доступны вне зависимости от места проживания пациента и дают возможность самостоятельно выбирать врачей.
Однако в работе над этими технологиями есть множество проблем, например, медленная адаптация законодательства, сложности получения, обработки и хранения конфиденциальных данных. Сейчас в России врачи не имеют права ставить диагноз без очной встречи с пациентами. При этом, согласно приказу Минцифры, к 2030 году половина медицинских консультаций должна проходить онлайн.
В медтехе очень популярны онлайн-консультации. Они могут проходить как с участием врача, так и без. Естественно, серьёзные вопросы должен решать доктор, но тем не менее остается огромное количество простых задач, с которыми может справиться искусственный интеллект. В России уже реализованы подобные решения: боты записывают пациентов на приём, проводят опросы перед приемом, распознают диалог врача и пациента, а затем конвертируют аудиозапись в текст.
В MTS AI мы разрабатывали своего медицинского чат-бота около двух лет и… у нас это не получилось. Идея была простой: перед первым приёмом пациент общается с чат-ботом, тот проводит первичный опрос. На выходе получаем анамнез для врача, а для пациента — информацию о том, к какому специалисту ему стоит обратиться. Польза для доктора заключается в том, что ему не надо задавать одни и те же вопросы каждому пациенту, достаточно лишь верифицировать анамнез и предполагаемый диагноз. Благодаря этому, время первичного приёма сокращается и ускоряется поток пациентов. К тому же пациент не всегда знает, к какому врачу ему обратиться, и чат-бот поможет ему сориентироваться. Конечно, было бы лучше, чтобы чат-бот показывал потенциальный диагноз, но это рискованно и может нарушать нормы законодательства, поэтому мы решили ограничиваться рекомендациями.
Проект оказался весьма сложным, его потенциальная прибыльность была неясна, и поэтому его остановили в конце 2020 года. Но в ходе работы над ним мы научились многому, и хотели бы этим поделиться.
Я был техлидом NLP-части проекта около года, и именно об ней я буду рассказывать.
В этой статье я опишу работу над проектом в целом, далее затрону тему сбора и разметки данных. Как известно, от их качества успех проекта зависит напрямую. Именно поэтому очень важно хорошо организовать не только сбор и разметку данных, но и проверку этой разметки. После этого мы рассмотрим, какие модели машинного обучения были использованы— это ведь самое интересное, правда? Затем я расскажу, что из опробованного нами не сработало. А в конце объясню, какую пользу мы смогли извлечь из проекта, несмотря на то, что он не удался.
Высокоуровневое техническое описание
Хороший чат-бот — это большая разработка, и наш проект не был исключением: в работе над ним участвовали DS-ы в направлениях NLP и рекомендательных систем, программисты, менеджеры и другие специалисты.
Для начала рассмотрим, как должен был функционировать разрабатываемый нами чат-бот. Я нарисовал упрощённую схему.

Как уже говорилось выше, проект выполняет две задачи: составление анамнеза и предсказание диагноза (даже если мы не будем его показывать пациенту). Чтобы предварительно установить диагноз, нам нужно детальное описание состояния человека. Например, если он жалуется на «боль в горле», «сухой кашель» и сообщает ещё несколько других специфических симптомов, мы можем сказать, что у него скорее всего «острый фарингит». Но вытаскивать такие симптомы из текста целиком очень сложно или невозможно, опрашивать людей о наличии всех этих симптомов слишком долго, им надоест отвечать. Мы решили парсить тексты на отдельные сущности, а потом объединять их в такие комплексные симптомы.
По итогу, наша команда пришла к следующей схеме. Мы решили, что пациенты будут писать в чат-бот неструктурированный текст, а нам предстоит извлекать из него информацию и приводить её в структурированный вид. Для этого обычно используется slot filling.
У нас был конфигурационный файл со списками сущностей и связями между ними. Мы выделили две группы: сами сущности и их атрибуты. Например, сущностью может быть «боль», «насморк» или «отек». Атрибуты могут показывать, при каких условиях возникает боль (условие), где она ощущается (локализация), когда происходит (время суток) и т. д. И было указано, какие атрибуты могут быть у сущностей. Зачем это нужно? Дело в том, что не все комбинации имеют смысл (например, не нужно описывать, что насморк ощущается в носу — в другом месте его бывает), а некоторые комбинации не важны для диагноза.
Кроме того, для большинства атрибутов у нас были классы. Например, болеть может рука, нога, левое подреберье, ухо и ещё много чего. Симптомы могут возникать при сидении, наклонах, дыхании и т. д. Кроме того, люди могут использовать уменьшительно-ласкательные суффиксы, сленг и прочие альтернативные написания. Все это вызывает необходимость строить модели классификации для предсказания конкретных классов.
Разберём пример:
Пациент пишет нам жалобу, например: «Я упал с лестницы, теперь у меня сильно болит нога и рука, а ещё по утрам отекает щека». Примечание: здесь и далее жалобы выдуманы.

Вначале мы извлекаем сущности с помощью моделей NER. Список сущностей длинный, поэтому используются разные подходы — от простого парсинга на правилах и регулярных выражениях до нейронок.
Дальше мы используем модель Relation Extraction, чтобы найти связанные между собой сущности. Нам надо понять, что отёк возникает именно по утрам, и что болит только нога и рука. Для этого подаем все пары сущностей и атрибутов, дополнительные фичи в модель и делаем предсказания. Помимо этого, мы настраиваем фильтрацию, чтобы отбросить невозможные пары.
Следующий шаг — разделение атрибутов на классы (описанные выше). Это простая модель классификации для каждого термина.
Но и это ещё не все: в жалобе может быть что-то типа «у меня болит нога, а рука не болит». В таком случае нам надо распарсить отрицание и правильно присвоить его.
Это все был первый, но самый насыщенный шаг. Дальше мы анализируем slot filling. Например, мы не знаем, при каком условии у пациента болит рука (или она болит всегда), и поэтому должны спросить его об этом.
Мы генерим вопросы на основе заранее написанных шаблонов и опрашиваем человека по всем пунктам. Пациент может выбрать один из предложенных вариантов или написать ответ в свободном стиле.
Такой опрос продолжается, пока все слоты для выявленных сущностей не будут заполнены (или помечены как отсутствующие/неизвестные). Далее мы пытаемся предсказать диагноз и формулируем новые вопросы для его уточнения. Это делалось с использованием рекомендательных систем, но поскольку я этим не занимался, углубляться в детали не будут.
Когда достигается критерий сходимости, опрос заканчивается, и мы выдаём анамнез и предварительный диагноз.
Данные — наше всё
С данными в нашем проекте было сложно. В целом на русском текстов меньше, чем на английском. Но это полбеды. Нам нужны были данные в медицинском домене. Таких датасетов для русского языка практически нет. Мы смогли спарсить несколько миллионов текстов из открытых источников (например, форумов), но оставался ряд проблем. В том числе:
-
стиль и содержание текстов с форумов сильно отличаются от того, что люди будут писать в чат-бот;
-
данные не были размечены;
-
нет никаких претренированных моделей NLP на русскоязычных медицинских текстах. Самое близкое — либо англоязычный BioBERT, либо какой-нибудь русскоязычный BERT. Но в первом случае не подходит язык, а во втором — домен;
Таким образом, нам нужно было:
-
самостоятельно делать разметку;
-
учитывать различия в домене между текстами, которые у нас есть, и теми, которые будут в реальности;
-
тренировать модели с нуля или делать свой претрейн;
Разметка данных проходила в несколько этапов:
В самом начале мы её делали либо своими руками, либо с использованием простых парсеров на правилах и regex (я присоединился к проекту как раз на этом этапе). Когда я пробовал натренировать модель NER на такой разметке, результаты получились ожидаемые — модель часто ошибалась, и при этом во многих случаях давала правильные предсказания на семплах с ошибочной разметкой.
Через какое-то время мы решили, что лучше сделать настоящую разметку. Если бы нам нужно было разметить что-то простое (например, названия локаций или имена людей), то можно было не париться над составлением задания на разметку, поскольку любой человек сразу поймёт, что надо размечать. Но нам надо было размечать медицинские сущности, поэтому первым шагом стало составление подробных инструкций.
Это оказалось гораздо сложнее, чем мы ожидали изначально. Мы пробовали разные подходы для покрытия большинства случаев: например, размечали тексты по отдельности, а потом собирались вместе, чтобы обсудить спорные моменты. В результате инструкции по разметке были составлены примерно таким образом:

Я уже писал выше, что мы знали о разнице между нашими текстами и теми текстами, которые могли приходить к нам в проде. Но к этому времени у нас уже была рабочая версия чат-бота (но практически без ML-части), поэтому мы могли посмотреть в логи и узнать, что же пишут люди. Результаты были прямо сказать удручающие: иногда люди описывали свои болезни очень кратко, в одном-двух словах; иногда они перечисляли чуть ли не все имеющиеся у них болячки, а не только то, что их беспокоит прямо сейчас; наконец, во многих сообщениях не было ничего о проблемах со здоровьем — люди писали, что у них все хорошо, шутили (например, жаловались, что у них «душа болит») или просто писали чушь.
Исходя из всего этого, мы решили делать следующее:
-
для разметки и тренировки моделей брать короткие фразы (до 50 слов);
-
добавлять достаточное количество текстов без сущностей/классов, чтобы уменьшить долю false positives;
-
добавлять аугментации;
Время шло, разметка копилась, но нам быстро стало понятно, что её качество оставляет желать лучшего. Дело в том, что практически отсутствовал контроль за разметкой: каждый текст размечал один человек, качество разметки особо и не проверялось. Но я не мог просто сказать «давайте делать лучше», надо было продемонстрировать наличие проблем и предложить способы их решения.
На тот момент у нас набралось примерно 15 тысяч размеченных текстов. Среди них я обнаружил около 3 тысяч дубликатов — одинаковых или почти одинаковых текстов, которые размечались несколько раз, потому что тогда мы не делали предварительную проверку на отсутствие дубликатов. Анализ этой разметки выявил множество проблем:
-
разные люди в одних и тех же текстах размечали NER по-своему: кто-то отмечал предлоги, кто-то нет; кто-то отмечал «дополнительные» слова, кто-то нет, и так далее;
-
иногда в тексте одна и та же сущность встречается несколько раз. Кто-то из разметчиков фиксировал все такие сущности, кто-то только первую;
-
наконец, случалось и так, что в тексте один разметчик размечал только одну сущность, а другой — только другую.
Этой аналитики было достаточно, чтобы изменить процесс разметки. В результате нескольких итераций мы пришли к единообразию:
-
вначале мы собирали данные для разметки. Изначально это делали просто поиском по ключевым словам, но позже реализовали некий упрощённый вариант active learning: собирается очень маленький датасет, тренируется модель, дальше мы делаем предсказания, считаем энтропию и берём тексты с максимальной энтропией для разметки. Причём это использовалось не напрямую, а объединялось с рядом других критериев в snorkel. Это работало весьма хорошо;
-
эти тексты передавались разметчикам вместе с подготовленной нами инструкцией. Они размечали данные в настроенном doccano. Над каждым текстом работали 5 человек;
-
был специальный чатик в телеграме, где разметчики могли задавать вопросы «контролёрам» (людям, которые лучше разбираются, как правильно делать разметку) для уточнения спорных моментов. Это давало очень большой прирост качества разметки. Как-то раз ради эксперимента попробовали отменить этот этап, и в результате эта итерация оказалась значительно хуже, чем обычно;
-
какое-то время полученную разметку предварительно проверяли валидаторы. Они случайным образом брали 10% размеченных текстов и проверяли качество; если оно было выше 90%, то разметку передавали нам, если нет — данные отправлялись на переразметку;
-
размеченные тексты прогонялись через написанный нами постпроцессинг — он исправлял множество косяков, которые проще было делать автоматически, чем заставлять людей следить за ними. Он удалял лишние предлоги и пробелы, мусорные слова и многое другое. Этот скрипт итеративно улучшался по мере того, как мы обнаруживали новые мелкие расхождения в разметке. Это тоже давало значительное увеличение качества;
-
далее мы запускали написанный скрипт для анализа качества разметки. Он показывал множество информации: доля текстов с полным и частичным совпадением разметки, отмеченные куски текста (для задачи NER), примеры текстов с расхождением и с совпадением разметки. Кстати говоря, было действительно полезно рассматривать примеры текстов с одинаковой разметкой, потому что случалось, что все разметчики делали одну и ту же ошибку. Это было сигналом того, что надо обновлять инструкцию для них. То же самое относится к текстам, где ни один разметчик ничего не отметил;
-
если доля текстов с полным совпадением разметки была выше 90%, мы принимали разметку, если же нет, то тексты отправлялись на переразметку;

У нас возникали идеи по ускорению разметки, но обычно это был трейдофф между временем разметчиков, временем data scienctist-ов и качеством моделей. Рассмотрим некоторые предложения.
Одна из идей была следующей: допустим, в рамках текущей итерации было размечено 1000 текстов. Анализ разметки показал, что лишь у 70% текстов было полное совпадение кросс-разметки.Мы предложили в таких случаях отправлять на переразметку не все 1000 текстов, а только 300, по которым было расхождение. Такой подход, конечно, значительно ускорял разметку, но ценой небольшого ухудшения качества, потому что в 700 текстах с совпадением разметки точно будут тексты, где все разметчики ошиблись. И тогда либо ml-щики должны просматривать все тексты и проверять их на ошибки, либо мы принимаем ухудшение качества моделей из-за ухудшения разметки.
Ещё одна из идей: у нас есть много сущностей (больше 50), для тренировки моделей было бы хорошо, чтобы в каждом тексте размечались все сущности, в таком случае можно будет натренировать одну модель сразу на все сущности. К сожалению, это не представлялось возможным. Во-первых, это временные затраты: какие-то сущности встречаются часто (больше половины случаев), какие-то — редко (меньше 10 или даже 5 процентов). Если просить людей размечать все сущности во всех текстах, в большинстве случаев они ничего не разметят. И, что важнее, если вы попросите кого-то разметить в тексте 50 сущностей, то он забудет про многие из них.
В результате долгое время мы просто давали разметчикам тексты и просили в них разметить одну сущность. В дальнейшем мы пробовали отдавать те же тексты на разметку других сущностей или просить размечать в текстах до пяти конкретных сущностей.
И даже всего этого часто не хватало. Например, в какой-то момент мы обнаружили, что во фразе «у меня болит рука» модель NER на локализации не находила слово «рука». Оказалось, что из четырёх тысяч размеченных на тот момент текстах, лишь в одном попалось это слово.
Кроме того, в текстах очень часто встречались сложные случаи, в которых было легко ошибиться. Покажу пример: «мучаюсь очень сильными головными болями, иногда даже темнеет в глазах от боли». Слово «болями» является сущностью «боль». А вот слово «боли» в конце не является сущностью «боль» — это скорее условие при котором темнеет в глазах.
Подробнее про машинное обучение
Процессинг текста
Процессинг текста доставил нам мучений и головной боли.
Выше я уже описывал постпроцессинг стандартизации разметки данных. Похожий постпроцессинг у нас использовался и после моделей извлечения сущностей. Кроме того, у нас была собственная расшифровка аббревиатур, постпроцессинг предсказаний на основе бизнес-правил и многое другое.
Отдельного внимания заслуживает токенизация текста. Есть множество методов токенизации, и сложно сказать, какой из них является лучшим. Изначально у нас использовался токенизатор из spacy (поскольку spacy очень активно использовался в проекте), и переход на другие токенизаторы означал бы переписывание многих кусков проекта, так что мы его не заменяли. Но нередко возникала необходимость допиливать его вручную, чтобы он не ломался на наших текстах. Пример такого кода:
from spacy.tokenizer import Tokenizer from spacy.util import compile_infix_regex, compile_suffix_regex, compile_prefix_regex def custom_tokenizer(nlp): """Creates custom tokenizer for spacy""" suf = list(nlp.Defaults.suffixes) # Default suffixes # Удаление suffixes , чтобы spacy не разбивал слитно написанные слова # по типу '140мм рт ст' del suf[75] suffixes = compile_suffix_regex(tuple(suf)) # remove № inf = list(nlp.Defaults.infixes) inf[2] = inf[2].replace('\\u2116', '') infix_re = compile_infix_regex(inf) pre = list(nlp.Defaults.prefixes) pre[-1] = pre[-1].replace('\\u2116', '') pre_compiled = compile_prefix_regex(pre) return Tokenizer(nlp.vocab, prefix_search=pre_compiled.search, suffix_search=suffixes.search, infix_finditer=infix_re.finditer, token_match=nlp.tokenizer.token_match, rules=nlp.Defaults.tokenizer_exceptions)Эмбеддинги
В NLP одним из залогов успеха является использование хороших претренированных моделей или хотя бы претренированных эмбеддингов.
Как я уже писал выше, претренированных NLP-моделей на русских медицинских текстах нет, поэтому нам надо было искать другие подходы.
Для начала я просто взял публичные эмбеддинги fasttext, претренированные на Википедии. Они сработали неплохо, но хотелось чего-то получше. Тогда я взял все имеющиеся у нас тексты на медицинскую тематику и стал тренировать на них эмбеддинги — word2vec, glove и fasttext. Эмбеддинги fasttext оказались самыми лучшими (что неудивительно), выбор гиперпараметров тоже сыграл важную роль.

В этой табличке можно увидеть результаты тренировки модели классификации диагнозов на разных эмбеддингах. Это был эксперимент по прямому предсказанию диагнозов на полном тексте жалобы. Такой подход мы не стали использовать, но тем не менее видно, что подбор гиперпараметров эмбеддингов может значительно увеличить качество моделей.
Модели NER
Извлечение сущностей начиналось с простого: вначале мы использовали парсеры с регекспом для поиска ключевых слов. Хочу отметить, что этот подход продолжал использоваться для простых сущностей до самого конца, у нас были такие сущности, которые легко вытаскивались по ключевым словам, а значит не было необходимости тратить ресурсы на их разметку.
Следующим шагом было использование моделей NER из spacy. То есть мы либо тренировали модели с нуля, либо использовали spacy_ru. На тот момент тренировать модели было удобнее с помощью самостоятельно написанных питоновских скриптов, но в новых версиях гораздо проще делать это просто в командной строке. Мы пробовали комбинировать тренируемые модели spacy с EntityRuler — то есть по факту возможность добавления правил или просто поиска по ключевым словам, но особой пользы это не дало.
Когда у нас накопилось побольше разметки, мы стали переходить на нейронки. BiLSTM на векторах fasttext работала отлично. Мы пробовали экспериментировать с архитектурой, например добавлять attention, но однозначного улучшения не было. В итоге мы просто тюнили архитектуры и гиперпараметры модели под разные сущности.

Классификация
С классификацией все было прямолинейно: на вход моделям приходили очень короткие тексты — то, что вытащили модели NER. Тренировать на этом какие-то сложные модели было бессмысленно, поэтому мы просто использовали старый, проверенный подход — векторизацию с помощью tf-idf на буквосочетаниях (char-gram-ы) и на словосочетаниях (word-gram-ы) и логистическую регрессию для предсказания.
Для этого было удобно использовать Pipeline из sklearn, и все выглядело примерно так:
combined_features = FeatureUnion([('tfidf', TfidfVectorizer(ngram_range=(1, 3))), ('tfidf_char', TfidfVectorizer(ngram_range=(1, 3), analyzer='char'))]) pipeline = Pipeline([('features', combined_features), ('clf', LogisticRegression(class_weight='balanced', solver='lbfgs', n_jobs=10, multi_class='auto'))])Relation extraction
Поиск взаимосвязей между сущностями был довольно сложной задачей. Иногда взаимосвязанные сущности находились рядом друг с другом в тексте, иногда они были далеко; иногда в текстах были взаимосвязи один к одному, иногда — многие ко многим; кроме того, не все комбинации связей были возможны. Все это создавало сложности для тренировки моделей, потому что невнимательно собранный датасет легко приводил к оверфиттингу и множеству false positives. Мы пробовали много моделей, например, начинали просто с извлечения эмбеддингов ELMo и MLP поверх них, но такой подход работал медленно и не особо качественно.
Спустя множество итераций мы пришли к такому подходу: берем предложение и извлеченные из него сущности, векторизируем, для каждой пары сущностей и атрибутов извлекаем дополнительные признаки и используем вот в такой архитектуре:
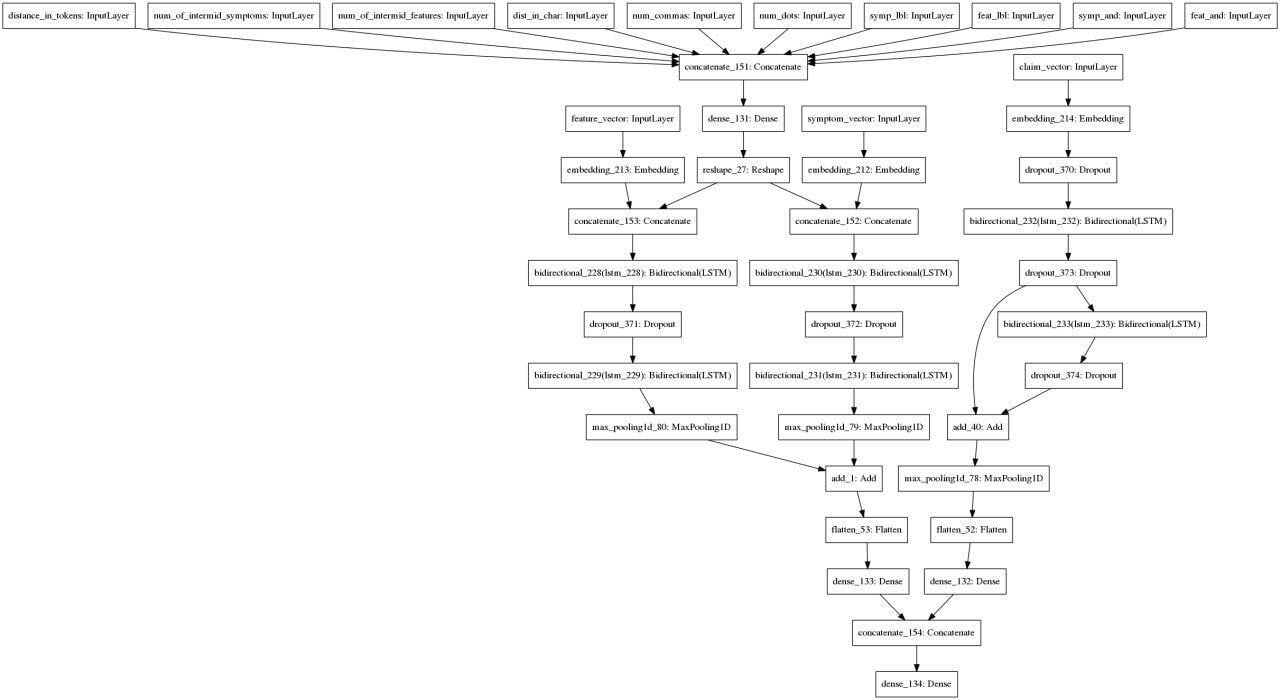
Augmentation
Аугментации сыграли довольно большую роль в улучшении качества наших моделей. Дело в том, что разметки всегда было недостаточно, и это стало одной из основных наших проблем. Например, в сущности локализация (напомню, это место, где есть проблема — нога, рука и так далее) было больше 150 классов — это значит, что и модели NER должны ловить такие слова, и моделям классификации нужно корректно определять их классы, и моделям relation extraction следует правильно находить связи с такими словами. В других сущностях было значительно меньше классов, но все равно возникали подобные сложности. Если размечать тексты случайным образом, то велика вероятность, что многие классы/слова не встретятся. А искать все классы вручную — сложно. Попытка же вручную собирать тексты со всеми парами слов для моделей relation extraction вообще обречена на провал.
На помощь нам пришли аугментации, причем скорее аугментации на правилах, чем какие-то умные варианты. Один из стандартных подходов к аугментации текстов — замена слов синонимами или словами с близкими эмбеддингами. К сожалению, в нашем случае это не работало.
Допустим есть фраза, «у меня болит рука». Если мы просто попробуем взять синоним или слово с близким эмбеддингом к слову «боль», то мы можем получать что-то подходящее, например «болезненность», а можем получить, например «резь», «дискомфорт», «ломота» — а это уже другие сущности. Кроме того, подобные замены будут ломать орфографию.

Один из сработавших подходов:
-
берем исходное предложение, например, опять же, «у меня боль в руке» и генерим новые предложения, просто заменяя «руке» на другие локализации. При этом надо не забывать использовать правильные склонения;
-
дальше мы можем менять слова в сущности «боль» и получать что-то типа «у меня болезненность в руке», » у меня болит рука» — и опять же надо следить за формами слов;
-
кроме того, мы можем добавлять атрибуты и получать «у меня сильная боль в руке», «у меня боль в руке по утрам» и многое другое. Важно изменять и саму разметку;
-
наконец, мы можем заменять сущность «боль» на что-то другое и получать «у меня ломота в руке», «у меня отек руки», и тоже изменять разметку;
Причём такой подход можно использовать как с датасетами для NER, так и с датасетами на классификацию и relation extraction.
Всё это звучит слишком хорошо — будто разметка особо и не нужна. И действительно, это оказалось слишком хорошо, чтобы быть правдой. При таком подходе появились две проблемы: мы не знали все возможные варианты слов, и модели слишком быстро учили паттерны. В результате мы получали дикий оверфит и множество false positive.
Для исправления ситуации пришлось сильнее рандомизировать аугментации, добавлять в сгенеренные фразы побольше мусорных слов (не сущностей) и следить, чтобы в тренировочном датасете значительная часть текстов была реальной, а не сгенерированной. Такой подход оказался рабочим.
Дополнительные технические детали
Опишу ещё ряд технических моментов, которые мне показались достаточно интересными.
У нас было довольно много легаси, большую часть мы оставляли, что-то переписывали из необходимости, что-то для удобства. Например, разные модели классификации/NER были написаны в отдельных скриптах, потом импортировались в другой скрипт и там использовались. Это работало неплохо, но при добавлении/изменении моделей приходилось бы менять импорты и делать другие изменения в коде, что не всегда хорошо. Я переписал это, в результате настройки моделей и пути к классам хранились в yaml-конфиге. Благодаря этому, если мы тренировали новую версию модели или добавляли новую, не надо было изменять основной код, достаточно было изменить конфиг и, при необходимости, добавить скрипт с кодом новой модели.
Мы настроили базовый ci/cd, хотя скорее это проверки стиля.
В какой-то момент мы решили, что нам нужно иметь какие-то более или менее чёткие критерии того, стоит ли выкатывать новую версию модели или нет. Для этого мы (ml-щики) самостоятельно собирали и размечали свой тестовый датасет для проверки качества моделей. В нём были тексты с полной разметкой на сущности, классы, связи между сущностями. Из-за трудоёмкости такой разметки, в нём было всего несколько сотен примеров. Когда у нас появлялась новая версия модели, мы запускали её по этому датасету и смотрели, насколько изменилось качество, обращая внимание и на false positives, и на false negatives. Новая модель принималась, только если она улучшала все метрики. Заодно благодаря этому мы могли отчитываться перед менеджерами о прогрессе в улучшении моделей.
Одной из проблем проекта стало то, что у нас было очень много моделей: нам приходилось извлекать 50+ сущностей, находить связи между ними, классифицировать и так далее. В результате получался большой совокупный вес моделей и медленная скорость работы проекта. Например, в какой-то момент мы просто не смогли его запустить на маленьком сервере, поскольку там не хватало оперативной памяти. Скорость работы была тоже важна: пользователю надо отвечать очень быстро. Эти сложности решали комплексом мер: просто оптимизацией кода (в легаси-коде нередко одна и та же модель инициализировалась много раз или использовалась неэффективно), использованием моделей на правилах, где это возможно, тренировкой одной модели на много сущностей, если это позволяла разметка. Это также означало, что мы не могли просто взять и запихнуть в проект с десяток бертов это вышло бы за все возможные лимиты.
Какие идеи не сработали
У нас было много идей, которые либо не сработали, либо их просто не получилось попробовать по ряду причин. Перечислю некоторые из них.
Мы очень хотели натренировать одну модель на все сущности. А в идеале — сделать сложную архитектуру, и тренировать модель одновременно на NER и Relation extraction (а если возможно, то ещё и на классификацию). Это упиралось в наличие разметки, но у нас не было возможности разметить достаточно большой датасет на все сущности. Впрочем, нам удалось попробовать потренировать SpERT, но результат получился недостаточно хорошим, чтобы внедрять его в проект.
Мы пробовали использовать лемматизацию, но в итоге отказались от этой идеи. Тестировали разные инструменты: spacy, pymorphy2, natasha, rnnmorph и другие, pymorphy2 был самым быстрым и качественным на наших данных. Но использование лемматизации практически не улучшило качество наших моделей. Кроме того, многие медицинские термины обычно не обрабатывались лемматизаторами. Наконец, использование лемматизаторов заметно замедляло скорость отклика системы, поэтому мы решили, что нет смысла использовать их.
Была идея попробовать использовать спеллчекеры, поскольку много людей пишет с ошибками. Наша команда тестировала Jamspell и pyenchant, но, увы, они часто портили тексты и заметно замедляли работу проекта.
Ещё мы пробовали конвертировать натренированные модели в другие форматы для ускорения инференса, но оказалось, что слой CRF не конвертируется в onnx, а если тренировать модели NER без него, то качество значительно падает.
Почему же у нас не получилось
Как уже было сказано в самом начале поста, проект был остановлен. Это решение приняли по независящим от нас причинам. Отчасти это произошло, потому что проект работал недостаточно хорошо. И здесь есть две группы причин: технические и организационные. Впрочем, часто они были взаимосвязаны.
Технические проблемы
-
Я много писал про работу с данными, и повторюсь снова: их разметка была сложной и занимала много времени. Для улучшения качества моделей и покрытия разных случаев стоило бы потратить на разметку гораздо больше времени и сил;
-
Мы не могли продуктивно использовать данные логов чат-бота, поскольку их было очень мало. Стоило бы сделать одно из двух: либо более активное использование чат-бота и анализ логов, либо направить развитие проекта на те направления, по которым поступало основное большинство жалоб;
Организационные проблемы
-
Большую часть времени у нас либо не было роадмапа, либо он был очень верхнеуровневым. Из-за этого было не слишком понятно, что надо делать для успеха проекта;
-
В связи с этим время от времени появлялись новые идеи от продакт-менеджеров, приводящие к изменениям функционала, к изменениям списка извлекаемых сущностей и классов, к изменениям логики работы. Нередко идеи были не продуманы, и нам приходилось самостоятельно доводить их до ума;
-
Более того, у нас не было четких milestone и критериев качества работы моделей. Мы тратили много времени и сил на улучшение наших моделей, но у нас не было понимания того, какое качество моделей является достаточным для приёмки. Мы даже самостоятельно собирали тестовый датасет для проверки качества наших моделей;
-
Кроме того, у нас не было каких-либо метрик для оценки качества диалога в целом. То есть мы могли измерить качество моделей обычными метриками машинного обучения, но мы никак не оценивали хорошо ли работает наша диалоговая система в целом или нет;
-
У нас не было тестирования. Проект был весьма сложным, помимо NLP-части, была большая часть отвечающая за сам опрос, была внушительная backend-составляющая — об этом можно рассказывать ещё долго. Время от времени мы находили какие-то баги и исправляли их, но было бы гораздо лучше, если бы имелась команда QA. Справедливости ради, вряд ли можно было просить QA тестировать работу проекта с медицинской точки зрения, ибо для этого требовались бы доменные знания, но и помимо этого было много вещей, которые можно было бы тестировать;
Где-то в конце проекта нам огласили три бизнес-метрики:
-
человек согласился с рекомендацией чат-бота;
-
согласился и записался на приём;
-
согласился, записался и пришёл на приём.
Проблема заключалась в том, что мы можем повлиять только на первую метрику, вторая и третья метрика никак не зависела от качества работы чат-бота.
В итоге мы видим, что проект получился очень сложным, при этом не было чёткого понимания того, насколько хорошо он будет работать в реальных условиях и сколько денег будет приносить. В результате, его заморозили решением свыше в конце 2020 года.
Была ли польза?
Ну а что в итоге? Казалось бы, все зря: было потрачено много ресурсов, а проект остановили. Тем не менее на вопрос: была ли какая-либо польза от него, я ответил бы да. И вот почему:
-
Мы опробовали много подходов к active learning и анализу качества разметки, некоторые из этих подходов использовались в дальнейших проектах;
-
Мы наработали опыт в построении различных моделей для работы с текстами — NER, классификация, relation extraction. Это также использовалось в дальнейшем;
-
При тренировке моделей мы разработали два пайплайна на pytorch lightning — эти пайплайны могут быть вновь использованы в дальнейшем;
-
Проект заморожен, но может быть возобновлён в будущем.
Вот и вся история этого проекта. Надеюсь, что это было интересно и полезно. 🙂
ссылка на оригинал статьи https://habr.com/ru/company/mts_ai/blog/670144/
Добавить комментарий