Автор статьи: Виктория Ляликова
Нормальный закон распределения или закон Гаусса играет важную роль в статистике и занимает особое положение среди других законов. Вспомним как выглядит нормальное распределение

где a -математическое ожидание,  — среднее квадратическое отклонение.
— среднее квадратическое отклонение.
Тестирование данных на нормальность является достаточно частым этапом первичного анализа данных, так как большое количество статистических методов использует тот факт, что данные распределены нормально. Если выборка не подчиняется нормальному закону, тогда предположении о параметрических статистических тестах нарушаются, и должны использоваться непараметрические методы статистики
Нормальное распределение естественным образом возникает практически везде, где речь идет об измерении с ошибками. Например, координаты точки попадания снаряда, рост, вес человека имеют нормальный закон распределения. Более того, центральная предельная теорема вообще утверждает, что сумма большого числа слагаемых сходится к нормальной случайной величине, не зависимо от того, какое было исходное распределение у выборки. Таким образом, данная теорема устанавливает условия, при которых возникает нормальное распределение и нарушение которых ведет к распределению, отличному от нормального.
Можно выделить следующие этапы проверки выборочных значений на нормальность
-
Подсчет основных характеристик выборки. Выборочное среднее, медиана, коэффициенты асимметрии и эксцесса.
-
Графический. К этому методу относится построение гистограммы и график квантиль-квантиль или кратко QQ
-
Статистические методы. Данные методы вычисляют статистику по данным и определяют, какая вероятность того, что данные получены из нормального распределения
При нормальном распределении, которое симметрично, значения медианы и выборочного среднего будут одинаковы, значения эксцесса равно 3, а асимметрии равно нулю. Однако ситуация, когда все указанные выборочные характеристики равны именно таким значениям, практически не встречается. Поэтому после этапа подсчета выборочных характеристик можно переходить к графическому представлению выборочных данных.
Гистограмма позволяет представить выборочные данные в графическом виде – в виде столбчатой диаграммы, где данные делятся на заранее определенное количество групп. Вид гистограммы дает наглядное представление функции плотности вероятности некоторой случайной величины, построенной по выборке.
График QQ (квантиль-квантиль) является графиком вероятностей, который представляет собой графический метод сравнения двух распределений путем построения их квантилей. QQ график сравнивает наборы данных теоретических и выборочных (эмпирических) распределений. Если два сравниваемых распределения подобны, тогда точки на графике QQ будут приблизительно лежать на линии y=x. Основным шагом в построении графика QQ является расчет или оценка квантилей.
Существует множество статистических тестов, которые можно использовать для проверки выборочных значений на нормальность. Каждый тест использует разные предположения и рассматривает разные аспекты данных.
Чтобы применять статистические критерии сформулируем задачу. Выдвигаются две гипотезы H0 и H1, которые утверждают
H0 — Выборка подчиняется нормальному закону распределения
H1 — Выборка не подчиняется нормальному распределению
Установи уровень значимости \alpha=0,05.
Теперь задача состоит в том, чтобы на основании какого-то критерия отвергнуть или принять основную нулевую гипотезу при уровне значимости
Критерий Шапиро-Уилка
Критерий Шапиро-Уилка основан на отношении оптимальной линейной несмещенной оценки дисперсии к ее обычной оценке методом максимального правдоподобия. Статистика критерия имеет вид

Числитель является квадратом оценки среднеквадратического отклонения Ллойда. Коэффициенты  и критические
и критические  значения статистики являются табулированными значениями. Если
значения статистики являются табулированными значениями. Если  , то нулевая гипотеза нормальности распределения отклоняется на уровне значимости
, то нулевая гипотеза нормальности распределения отклоняется на уровне значимости  .
.
В Python функция  содержится в библиотеке scipy.stats и возвращает как статистику, рассчитанную тестом, так и значение p. В Python можно использовать выборку до 5000 элементов. Интерпретация вывода осуществляется следующим образом
содержится в библиотеке scipy.stats и возвращает как статистику, рассчитанную тестом, так и значение p. В Python можно использовать выборку до 5000 элементов. Интерпретация вывода осуществляется следующим образом
Если значение  , тогда принимается гипотеза H1, т.е. что выборка не подчиняется нормальному закону.
, тогда принимается гипотеза H1, т.е. что выборка не подчиняется нормальному закону.
Критерий Д’Агостино
В данном критерии в качестве статистики для проверки нормальности распределения используется отношение оценки Даутона для стандартного отклонения к выборочному стандартному отклонению, оцененному методом максимального правдоподобия

В качестве статистики критерия Д’Агостино используется величина

значение которой рассчитывается на основе центральной предельной теоремы, которая утверждает, что при 
![\lim\limits_{x \to \infty}P\bigg(\frac{D-M[D]}{\sqrt{D[D]}}{<x}\bigg)=\Phi(x)](https://habrastorage.org/getpro/habr/upload_files/942/0a9/b3a/9420a9b3a29c728265cf3734143c97bd.svg)
где стандартная нормальная случайная величина.
стандартная нормальная случайная величина.

Критические значения являются табулированными значениями. Гипотеза нормальности принимается, если значение статистики лежит в интервале критических значений. Данный критерий показывает хорошую мощность против большого спектра альтернатив, по мощности немного уступая критерию Шапиро-Уилка.
В Python функция normaltest() также содержится в библиотеке scipy.stats и возвращает статистику теста и значение p. Интерпретация результата аналогична результатам в критерии Шапиро-Уилка.
Критерий согласия — Пирсона
— Пирсона
Данный критерий является одним из наиболее распространенных критериев проверки гипотез о виде закона распределения и позволяет проверить значимость расхождения эмпирических (наблюдаемых) и теоретических (ожидаемых) частот. Таким образом, данный критерий позволяет проверить гипотезу о принадлежности наблюдаемой выборки некоторому теоретическому закону. Можно сказать, что критерий является универсальным, так как позволяет проверить принадлежность выборочных значений практическому любому закону распределения.
Для решения задачи используется статистика  — Пирсона
— Пирсона

где — эмпирические частоты (подсчитывается число элементов выборки, попавших в интервал),
— эмпирические частоты (подсчитывается число элементов выборки, попавших в интервал),  — теоретические частоты. Подсчитывается критическое значение
— теоретические частоты. Подсчитывается критическое значение  . Если
. Если  , отклоняется гипотеза о принадлежности выборки нормальному распределению и принимается, если
, отклоняется гипотеза о принадлежности выборки нормальному распределению и принимается, если  .
.
Теперь перейдем к практической части. Для демонстрации функций будем использовать Dataset, взятый с сайта kaggle.com по прогнозированию инсульта по 11 клиническим характеристикам.
Загружаем необходимые библиотеки
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import numpy as npЗагружаем датасет
data_healthcares = pd.read_csv('E:/vika/healthcare-dataset-stroke-data.csv')
Набор состоит из 5110 строк и 12 столбцов.
Посмотрим на основные характеристики, каждого признака.data_healthcares.describe()

Из данных характеристик можно увидеть, что есть пропущенные значения в показателях индекс массы тела. Посчитаем количество пропущенных значений.

Если бы нам необходимо было делать модель для прогноза, то пропущенные значения bmi являются достаточно большой проблемой, в которой возникает вопрос как их восстановить. Поэтому будем предполагать, что значения столбца bmi (индекс массы тела) подчиняются нормальному закону распределения (предварительно был построен график распределения, поэтому сделано такое предположение). Но так как, на данный момент, у нас нет необходимости в построении модели для прогноза, то удалим все пропущенные значения
new_data=data_healthcares.dropna()
Теперь можем приступать к проверке выборочных значений показателя bmi на нормальность. Вычислим основные выборочные характеристики
|
Выборочная характеристика |
Код в python |
Значение характеристики |
|
Выборочное среднее |
new_data.bmi.mean() |
28,89 |
|
Выборочная медиана |
new_data.bmi.median() |
28,1 |
|
Выборочная мода |
new_data.bmi.mode() |
28,7 |
|
Выборочное среднеквадратическое отклонение |
new_data.bmi.std() |
7.854066729680458 |
|
Выборочный коэффициент асиметрии |
new_data.bmi.skew() |
1.0553402052962928 |
|
Выборочный эксцесс |
new_data.bmi.kurtosis() |
3.362659165623678 |
После вычислений основных характеристик мы видим, что выборочное среднее и медиана можно сказать принимают одинаковые значения и коэффициент эксцесса равен 3. Но, к сожалению коэффициент асимметрии равен 1, что вводить нас в некоторое замешательство, т.е. мы уже можем предположить, что значения bmi не подчиняются нормальному закону. Продолжим исследования, перейдем к построению графиков.
Строим гистограмму
fig = plt.figure fig,ax= plt.subplots(figsize=(7,7)) sns.distplot(new_data.bmi,color='red',label='bmi',ax=ax) plt.show()
Гистограмма достаточно хорошо напоминает нормальное распределение, кроме конечно, небольшого выброса справа, но смотрим дальше. Тут скорее, можно предположить, что значения bmi подчиняются распределению  .
.
Строим QQ график. В python есть отличная функция qqplot(), содержащаяся в библиотеке statsmodel, которая позволяет строить как раз такие графики.
from statsmodels.graphics.gofplots import qqplot from matplotlib import pyplot qqplot(new_data.bmi, line=’s’) Pyplot.show
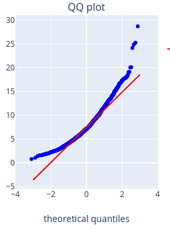
Что имеем из графика QQ? Наши выборочные значений имеют хвосты слева и справа, и также в правом верхнем углу значения становятся разреженными.
На основе данных графика можно сделать вывод, что значения bmi не подчиняются нормальному закону распределения. Рядом приведен пример QQ графика распределения хи-квадрат с 8 степенями свободы из выборки в 1000 значений.
Для примера построим график QQ для выборки из нормального распределения с такими же показателями стандартного отклонения и среднего, как у bmi.
std=new_data.bmi.std() # вычисляем отклонение mean=new_data.bmi.mean() #вычисляем среднее Z=np.random.randn(4909)*std+mean # моделируем нормальное распределение qqplot(Z,line='s') # строим график pyplot.show()
Продолжим исследования. Перейдем к статистическим критериям. Будем использовать критерий Шапиро-Уилка и Д’Агостино, чтобы окончательно принять или опровергнуть предположение о нормальном распределении. Для использования критериев подключим библиотеки
from scipy.stats import shapiro from scipy.stats import normaltest shapiro(new_data.bmi) ShapiroResult(statistic=0.9535483717918396, pvalue=6.623218133972133e-37) Normaltest(new_data.bmi) NormaltestResult(statistic=1021.1795052962864, pvalue=1.793444363882936e-222)После применения двух тестов мы имеем, что значение p-value намного меньше заданного критического значения \alpha , значит выборочные значения не принадлежат нормальному закону.
Конечно, мы рассмотрели не все тесты на нормальности, которые существуют. Какие можно дать рекомендации по проверке выборочных значений на нормальность. Лучше использовать все возможные варианты, если они уместны.
На этом все. Еще хочу порекомендовать бесплатный вебинар, который 15 июня пройдет на платформе OTUS в рамках запуска курса Математика для Data Science. На вебинаре расскажут про несколько часто используемых подходов в анализе данных, а также разберут, какие математические идеи работают у них под капотом и почему эти подходы вообще работают так, как нам нужно. Регистрация на вебинар доступна по этой ссылке.
ссылка на оригинал статьи https://habr.com/ru/company/otus/blog/671322/
Добавить комментарий