Привет, Хабр! Это вторая статья цикла, о процессе собеседования Golang разработчика. Первую часть вы можете почитать по ссылочке ниже. Как я писал в предыдущем посте, проходя интервью на позицию Golang разработчика, мне удалось собрать пул вопросов, которыми я хотел бы поделиться с вами. Надеюсь эта информация будет полезна и послужит чек листом при подготовке к интервью.
-
Собеседование Golang разработчика (теоретические вопросы), Часть I
-
Собеседование Golang разработчика (теоретические вопросы), Часть II. Что там с конкурентностью?
Оглавление
Темы вопросов, рассмотренные в предыдущей части
В предыдущей части мы рассмотрели вопросы по следующим темам:
-
ООП в Golang;
-
Области видимости в Golang;
-
Операторы в Golang;
-
Strings в Golang;
-
Int в Golang;
-
Const в Golang;
-
Array и slice в Golang;
-
Map в Golang;
-
Интерфейсы в Golang;
-
Инструкция defer.
Конкурентность в Golang
Зачастую начальным вопросом к раскрытию темы конкурентности в Golang является вопрос на общее понимание асинхронности «Что такое асинхронность?»
Ответ
Вычисления в системе могут идти двумя способами:
-
синхронно — это когда код выполняется последовательно;
-
асинхронно — это когда операцию мы можем выполнять не дожидаясь результата на месте. Обычно подразумевается, что операция может быть выполнена кем-то на стороне.
«Что такое параллельность?»
Ответ
Вычисления будут являться параллельным только в том случае, если они выполняются одновременно. Как пример можно привести процесс ремонта в доме. У нас есть несколько мастеров-универсалов, каждый из которых выполняет работы на своем объекте под ключ. При этом производительность мастеров не зависит друг от друга, так как их работа не пересекается.
«Что такое конкурентность?»
Ответ
Конкурентность обеспечивает выполнение нескольких задач посредством переключения контекста. Конкурентные вычисления реализуются на одном ядре системы. Как пример приведем тот же процесс ремонта, но с другими вводными условиями. Теперь мы имеем один объект, на который привлекаем специалистов разного профиля: по демонтажным работам, электрике, подготовке стен и полов, отделке. При этом у нас часто возникают ситуации, когда хозяин уже в процессе подготовки стен, решает, что вот эта стена ему все же не нужна, и на сцену опять выходят демонтажники. Такой процесс организации работ можно назвать конкурентным, так как наши мастера уступают место друг другу, одновременно клеить обои и ломать стены они не могут.
Важным, более общим вопросом, является «Что такое thread?»
Ответ
Thread — это реализация виртуальных эмуляций физического процессора. Вычисления на разных thread условно можно назвать параллельными.
«Что такое goroutine?»
Ответ
Горутина — реализация в Go корутины, блоков кода, которые работают асинхронно. Она объявляется через оператор go перед функцией, вычисления которой необходимо сделать асинхронными. На многоядерной архитектуре выполнение горутин можно осуществлять на разных ядрах процессора. Это сделает эти вычисления параллельными и может сильно ускорить вычисления.
«Какие основные отличия горутины от thread?»
Ответ
Таблица различий
|
Gorutine |
Thread |
|
Управляются рантаймом языка |
Управляются процессорным ядром |
|
Более высокоуровневая абстракция, поэтому не зависит от системы |
Зависит от системы |
|
Более легковесны |
Требуют большего количества ресурсов |
|
Асинхронно вытесняющий планировщик |
Вытесняющий планировщик |
|
Имеет стэк, который может расти |
Фиксированный стэк |
«Каков минимальный и максимальный вес горутин?»
Ответ
На этот вопрос, ожидается ответ, не сколько весят все вместе взятые поля в структуре g объекта горутины. Интервьюера интересуют минимальный и максимальный размер стэка горутины. Минимальный (начальный) размер стэка составляет 2 КБ. Максимальный размер стэка горутины зависит от архитектуры системы и равен 1 ГБ для 64-разрядной архитектуры, 250 МБ для 32-разрядной архитектуры.
// The minimum size of stack used by Go code _StackMin = 2048// Max stack size is 1 GB on 64-bit, 250 MB on 32-bit. // Using decimal instead of binary GB and MB because // they look nicer in the stack overflow failure message. if sys.PtrSize == 8 { maxstacksize = 1000000000 } else { maxstacksize = 250000000 }«Что будет если размер горутины превысил допустимый максимум?»
Ответ
Если размер стэка горутины превышен (к примеру запустили бесконечную рекурсию), то приложение упадет с fatal error.
runtime: goroutine stack exceeds 1000000000-byte limit fatal error: stack overflow«Какое максимальное количество горутин может быть запущено в системе?»
Ответ
Количество горутин ограничено только оперативной памятью системы.
«Что такое планировщик go?»
Ответ
Управление горутинами осуществляет Go планировщик. Про тонкости работы планировщика можно рассказывать бесконечно долго, поэтому сосредоточимся на основных моментах. Планировщик go оперирует 3-мя основными сущностями (важно понимать, что все это структуры, не пытайтесь переложить их на физическое восприятие):
-
M— машина, поток операционной системы, которым она управляет; -
P— контекст планирования, необходимый для возможности переброски очередей планирования между потоками (M); -
G— горутина, прежде всего там содержатся: стек, указатель команд, канал для планирования горутин.

При запуске программы на каждое виртуальное ядро процессора создается структура P, к которой привязывается отдельный поток M. Каждому P присваивается локальная очередь выполнения LRQ (есть еще глобальная очередь выполнения GRQ, этот вопрос я советую изучить самостоятельно). LRQ управляет горутинами в контексте P, переключением контекста M.
«В равной ли степени горутины делят между собой процессорное время?»
Ответ
Существует 2 типа многозадачности:
-
кооперативная — передачей управления процессы занимаются самостоятельно;
-
вытесняющая многозадачность — планировщик дает отработать процессам равное время, после чего перещелкивает контекст.
С версии Go 1.14 планировщик с кооперативного стал асинхронно вытесняющим. Сделано это было по причине долго отрабатывающих горутин, надолго занимающих процессорное время и не дающих доступа до него другим горутинам. Теперь когда горутина отрабатывает больше 10 м/с Go будет пытаться переключить контекст для выполнения следующей горутины. Казалось бы вот он ответ. Но не все так просто… Части кооперативного поведения до сих пор присутствуют, к примеру перед вытеснением горутины необходимо выполнить проверку куска кода на атомарность, с точки зрения garbage collector. Операция вытеснения может настичь горутину в любом месте, в зависимости от состояния данных, сборщик мусора может отработать совсем не так как ожидалось. Так как Go живой язык, в который постоянно вносятся изменения, реализация и тонкости в разных версиях могут отличаться. Настоятельно советую обновлять свои знания по этой теме по мере релизов Go.
«Какие есть способы остановить все горутины в приложении?»
Ответ
Если размышлять глобально, то таких способа 3:
-
завершение
mainфункции иmainгорутины; -
прослушивание всеми горутинами
channel, при закрытииchannelотправляется значение по умолчанию всем слушателям, при получении сигнала все горутины делаютreturn; -
завязать все горутины на переданный в них
context.
«Как вручную задать количество процессоров P для приложения?»
Ответ
Это позволяет сделать runtime.GOMAXPROCS(). Важно понимать, что при выставлении количества логических процессоров больше, чем есть у вас в системе, вы рискуете получить определенные проблемы с производительностью. Чтобы избежать этого можно задать runtime.GOMAXPROCS(runtime.NumCPU()), runtime.NumCPU() — количество логических процессоров.
«Как принудительно переключить контекст?»
Ответ
Переключение контекста вручную осуществляется с помощью функции runtime.Goshed().
«Как наладить связь между горутинами?»
Ответ
Горутины общаются друг с другом посредством перегонки необходимых данных по channel. Именно о каналах идет речь знаменитом девизе Go: «Не общайтесь, делясь памятью; делитесь памятью, общаясь».
«Какие есть примитивы синхронизации?»
Ответ
В используемые примитивы синхронизации можно записать:
-
wait group; -
mutex; -
atomic; -
sync map; -
channel.
«Что такое wait group?»
Ответ
sync.WaitGroup — это реализация счетчика, который можно инкрементировать и декрементировать, и самое главное остановить выполнение куска кода до того момента, пока значение счетчика не будет равно 0.
func main() { wg := sync.WaitGroup{} wg.Add(1) go gorutinePrint(&wg) wg.Wait() fmt.Println("hello from main") } func gorutinePrint(wg *sync.WaitGroup) { // без использования WaitGroup нет гарантий, что будет выведено fmt.Println("hello from goroutine") wg.Done() }Вывод
hello from goroutine hello from main«Для чего используются mutex и какие бывают?»
Ответ
Прежде чем ответить на этот вопрос, давайте немного поговорим о гонке данных. Гонка данных — это процесс, который возникает в Go приложении при условии:
-
что 2 и более горутины используют одни и те же данные;
-
1 и более горутина используют данные на запись. В этом случае мы получаем ситуацию, когда наши данные могут стать неконсистентными. Во избежание этого необходимо определить правила, ограничивающие одновременную работу с данными. Для этих целей и были введены
mutex. Их существует 2 вида: -
sync.Mutex— блокирует кусок кода как на запись, так и на чтение; -
sync.RWMutex— позволяет блокировать кусок кода только на запись.
// SafeCounter is safe to use concurrently. type SafeCounter struct { mu sync.Mutex v map[string]int } // Inc increments the counter for the given key. func (c *SafeCounter) Inc(key string) { c.mu.Lock() // Lock so only one goroutine at a time can access the map c.v. c.v[key]++ c.mu.Unlock() } // Value returns the current value of the counter for the given key. func (c *SafeCounter) Value(key string) int { c.mu.Lock() // Lock so only one goroutine at a time can access the map c.v. defer c.mu.Unlock() return c.v[key] } func main() { c := SafeCounter{v: make(map[string]int)} for i := 0; i < 1000; i++ { go c.Inc("somekey") } time.Sleep(time.Second) fmt.Println(c.Value("somekey")) }Вывод
1000«Для чего используется atomic?»
Ответ
atomic — предоставляет набор атомарных функций, реализованных на аппаратном уровне. Это позволяет избегать гонки данных без блокировок. Вместе с этим, с помощью atomic в отличие от mutex можно делать только простые вещи, к примеру инкрементировать различные счетчики. Немного пояснений про атомарность: функция будет атомарной, если она завершается в один шаг по отношению ко всем другим потокам, которые имеют доступ к обрабатываемой памяти.
func main() { var ( counter uint64 wg sync.WaitGroup ) for i := 0; i < 10; i++ { wg.Add(1) go func() { for c := 0; c < 1000; c++ { atomic.AddUint64(&counter, 1) } wg.Done() }() } wg.Wait() fmt.Println("counter:", counter) }Вывод
counter: 10000«Для чего используется sync map?»
Ответ
Простой ответ на этот вопрос: достаточно частый кейс использования в Go mutex, который защищает данные в map. sync.Map можно рассматривать как map+RWMutex обертку. Но на деле этот ответ не совсем правильный, так как sync.Map решает одну довольно конкретную проблему cache contention. Что же это такое? При использовании sync.RWMutex в случае блокировки на чтение каждая горутина должна обновить поле readerCount, что происходит атомарно. Довольно обще процесс выглядит так:
-
ядро процессора обновляет счетчик;
-
ядро процессора сбрасывает кэш для этого адреса для всех других ядер;
-
ядро процессора объявляет, что только оно знает действующее значение для обрабатываемого адреса;
-
следующее ядро процессора вычитывает значение из кэша предыдущего;
-
процесс повторяется. Так вот, когда несколько ядер хотят обновить
readerCount, образуется очередь. И операция, которую мы считали константной, становится линейной относительно количества ядер. Именно решая эту проблему и ввелиsync.Map.sync.Mapрекомендуется применять именно на многопроцессорных системах.
// Lock locks rw for writing. // If the lock is already locked for reading or writing, // Lock blocks until the lock is available. func (rw *RWMutex) Lock() { if race.Enabled { _ = rw.w.state race.Disable() } // First, resolve competition with other writers. rw.w.Lock() // Announce to readers there is a pending writer. r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders // Wait for active readers. if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 { runtime_SemacquireMutex(&rw.writerSem, false, 0) } if race.Enabled { race.Enable() race.Acquire(unsafe.Pointer(&rw.readerSem)) race.Acquire(unsafe.Pointer(&rw.writerSem)) } }«Что такое graceful shutdown?»
Ответ
У каждого сервера есть потребность в его отключении, обычно это происходит при получении сигнала от ОС. И хорошо бы делать это отключение корректно, останавливая поэтапно все службы. Согласитесь никто из нас не выключает телевизор ударом табурета по корпусу. Так же и с сервером, для корректного отключения которого есть общие подходы. К примеру:
-
создать канал, прослушивающий системные сигналы на выход;
-
прослушивать этот канал;
-
при получении сигнала поэтапно выходить из горутин;
-
остановить сервер.
interrupter := make(chan os.Signal, 1) signal.Notify(interrupter, os.Interrupt) for range interrupter { appCtx.Done() break }Каналы в Golang
«Что такое channel?»
Ответ
channel — это абстракция Go, которая помогает горутинам общаться друг с другом, передавая по channel значения. Канал можно представить как трубу, в которую одни горутины кладут данные, а другие их вычитывают. Под капотом channel представляет из себя 3 структуры (hchan, sudog, waitq). Наиболее интересной для нас является hchan, основные поля которой:
-
qcount— количество элементов в буфере; -
dataqsiz— размерность буфера; -
buf— указатель на буфер для элементов канала; -
elemsize— размер элемента в канале; -
closed— флаг, указывающий, закрыт канал или нет (1/0 соответственно); -
elemtype— тип элемента; -
recvq— указатель на связанный список горутин, ожидающих чтения из канала; -
sendq— указатель на связанный список горутин, ожидающих запись в канал; -
lock— мьютекс для безопасного доступа к каналу. Когда мы создаем канал, мы присваеваемhchanelemtypeиelemsizeи аллоцируем структуруhchanвHeap.
type hchan struct { qcount uint // total data in the queue dataqsiz uint // size of the circular queue buf unsafe.Pointer // points to an array of dataqsiz elements elemsize uint16 closed uint32 elemtype *_type // element type sendx uint // send index recvx uint // receive index recvq waitq // list of recv waiters sendq waitq // list of send waiters // lock protects all fields in hchan, as well as several // fields in sudogs blocked on this channel. // // Do not change another G's status while holding this lock // (in particular, do not ready a G), as this can deadlock // with stack shrinking. lock mutex }«Что такое буферизированный и небуферизированный channel?»
Ответ
channel делятся на два типа по наличию/отсутствию буфера. Соответственно в первом случае поле dataqsiz будет равно размеру переданного буфера (3), а поле buf будет ссылкой на этот буфер. Во втором случае поле dataqsiz будет равно 0, а поле buf будет nil. Отсюда возникает различное поведение этих типов channel при операциях с ними. Об этом мы поговорим ниже.
chanBuf := make(chan bool, 3) chanIsNotBuf := make(chan bool)«Какие действия можно произвести с каналом?»
Ответ
С channel можно сделать 4 действия:
-
создать канал;
-
записать что-то в канал;
-
что-то вычитать из канала;
-
закрыть канал.
myChan := make(chan int) myChan <- 1 <- myChan close(myChan)«Что будет если писать/читать в nil channel?»
Ответ
Как мы смотрели ранее, канал — это структура, которую надо инициализировать. Если же мы этого не сделали и пишем в nil канал, то произойдет fatal error, так как в исходниках Go идет проверка на nil. Точно такое же поведение будет при чтении из nil канала.
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool { if c == nil { if !block { return false } gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2) throw("unreachable") } ... }func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) { // raceenabled: don't need to check ep, as it is always on the stack // or is new memory allocated by reflect. if debugChan { print("chanrecv: chan=", c, "\n") } if c == nil { if !block { return } gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2) throw("unreachable") } ... }«Что будет если писать/читать в/из закрытый channel?»
Ответ
Запись в закрытый канал приведет к панике. Опять же из-за проверки флага в исходниках. При чтении из закрытого канала мы получим совсем другое поведение — значение из буфера, если оно есть, или дефолтное значение типа данных канала если буфер канала пуст. Более подробно это поведение можно посмотреть в функции chanrecv рантайма Go.
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool { ... if c.closed != 0 { unlock(&c.lock) panic(plainError("send on closed channel")) } ... }«Что будет если писать/читать в/из буферизированный channel?»
Ответ
Запись в буферизированный канал не является блокирующей операцией до тех пор, пока не заполнится буфер канала. После операция вызовет блокировку. Чтение из буферизированного канала не является блокирующим, если буфер канала не пуст. При пустом буфере канала чтение из него вызовет блокировку. Важный момент, что чтение из буферизированного канала — жадная операция. Если начался процесс чтения данных из канала, то данные будут читаться без блокировки до момента опустошения буфера.
func printNum(c chan int) { for i := 0; i <= 3; i++ { num := <-c fmt.Println(num) } } func main() { // без блокировок fmt.Println("start") defer fmt.Println("stop") c := make(chan int, 3) go printNum(c) c <- 1 c <- 2 c <- 3 }Вывод
start stopfunc printNum(c chan int) { for i := 0; i <= 3; i++ { num := <-c fmt.Println(num) } } func main() { // с блокировкой fmt.Println("start") defer fmt.Println("stop") c := make(chan int, 3) go printNum(c) c <- 1 c <- 2 c <- 3 c <- 4 // блокировка c <- 5 }Вывод
start 1 2 3 4 stop«Что будет если писать/читать в/из небуферизированный channel?»
Ответ
Небуферизированный канал — это тот же буферизированный канал, но с nil буфером. Соответственно принцип его работы будет таким же. Чтение из пустого и запись в непустой небуферизированный канал являются блокирующими операциями.
«Как закрыть channel? Что с ним происходит?»
Ответ
Для закрытия канала предусмотрена функция close. Если упрощенно (опускаем блокировки), то при закрытии канала происходят следующие действия:
-
проверка, что канал инициализирован и не является
nil(panic— если это не так); -
проверка, что канал не закрыт (
panic— если это не так); -
поле
closedhchanвыставляется в1(true); -
отправка всем ожидающим чтения default value типа данных в канале;
-
ожидающие записи получают
panic. Интересный момент, что так как закрытие канала не блокирует чтение канала, то данные из буфера канала можно вычитать и после его закрытия.
func closechan(c *hchan) { if c == nil { panic(plainError("close of nil channel")) } lock(&c.lock) if c.closed != 0 { unlock(&c.lock) panic(plainError("close of closed channel")) } ... c.closed = 1 var glist gList // release all readers for { sg := c.recvq.dequeue() if sg == nil { break } if sg.elem != nil { typedmemclr(c.elemtype, sg.elem) sg.elem = nil } ... gp := sg.g gp.param = unsafe.Pointer(sg) sg.success = false if raceenabled { raceacquireg(gp, c.raceaddr()) } glist.push(gp) } // release all writers (they will panic) for { sg := c.sendq.dequeue() if sg == nil { break } sg.elem = nil if sg.releasetime != 0 { sg.releasetime = cputicks() } gp := sg.g gp.param = unsafe.Pointer(sg) sg.success = false if raceenabled { raceacquireg(gp, c.raceaddr()) } glist.push(gp) } ... }«Какие есть инструкции для чтения из channel?»
Ответ
Из канала можно читать значения:
-
присваивая их в переменную;
-
прослушивая канал с помощью инструкции
for range; -
прослушивая канал с помощью инструкции
select case. Также следует обратить внимание, что чтение из закрытого канала отдает дефолтное значение типа данных канала. Поэтому существует возможность проверить, что при чтении получено значение из буфера. Для этого используется синтаксис со второй (bool) переменнойval, ok := <- myChan.
func main() { queue := make(chan string, 2) queue <- "one" elem := <-queue fmt.Println(elem) }Вывод
onefunc main() { queue := make(chan string, 2) queue <- "one" queue <- "two" close(queue) for elem := range queue { fmt.Println(elem) } }Вывод
one twofunc main() { ch1 := make(chan string) ch2 := make(chan string) go func() { ch1 <- "one" }() go func() { ch2 <- "two" }() for i := 0; i < 2; i++ { select { case msg1 := <-ch1: fmt.Println("chan1: ", msg1) case msg2 := <-ch2: fmt.Println("chan2: ", msg2) } } }Вывод
chan2: two chan1: one«Как сделать select неблокирующим?»
Ответ
Инструкция select в предыдущем примере является блокирующей, так как на каждый виток цикла будет происходить ожидание одного из case. Но есть возможность задать поведение для select по умолчанию, то есть для случаев, когда не выполняются case. Для этого необходимо добавить инструкцию default. Таким образом, когда не срабатывает ни один из case будет срабатывать кусок кода под инструкцией default.
«Какой порядок исполнения операций case в select?»
Ответ
Первым выполнится тот case в select, который будет готов. При одновременной отправке данных в каналы, прослушиваемые в select порядок операций не гарантирован.
Контексты в Golang
«Что такое context?»
Ответ
По сути context — это некий сборник метаданных, который можно привязать к какому-нибудь процессу. К примеру для HTTP вызова можно объявить context, записать туда куки и иную информацию о пользователе. По окончанию вызова context можно отменить.
«Для чего применяется context?»
Ответ
У context два основных применения:
-
для отмены выполнения либо по таймауту, либо по дедлайну. Тот же пример с HTTP запросами;
-
для передачи параметров. Правда злоупотребление этим плохо сказывается на явности кодовой базы. Обязательные параметры передавать через
contextвсе же не стоит.
«Чем отличается context.Background от context.TODO?»
Ответ
И context.Background() и context.TODO() это одно и то же. Разница лишь в том, что context.TODO() выставляется в местах, где пока нет понимания, что необходимо использовать context.Background() и возможно его надо заменить на дочерний контекст.
«Как передавать значения и вычитывать их из context?»
Ответ
В пакете context существует функция context.WithValue(parent Context, key, val interface{}) Context, которая от родительского контекста создает производный и добавляет в него по key значение. Извлекая значение из context необходимо помнить, что на выход получаем интерфейс, который необходимо правильно скастить.
func main() { type favContextKey string f := func(ctx context.Context, k favContextKey) { if v := ctx.Value(k); v != nil { fmt.Println("found value:", v) return } fmt.Println("key not found:", k) } k := favContextKey("language") ctx := context.WithValue(context.Background(), k, "Go") f(ctx, k) f(ctx, favContextKey("color")) }Вывод
found value: Go key not found: color«Каковы отличия context.WithCancel, context.WithDeadline, context.WithTimeout?»
Ответ
-
context.WithCancel(parent Context) (ctx Context, cancel CancelFunc)создает контекст производный от родительского, также возвращает функцию отмены, с помощью которой этот контекст можно закрыть. Общепринятой практикой является работать с функцией отмены там, где она получена, не передавая ее глубже. -
context.WithDeadline(parent Context, d time.Time) (ctx Context, cancel CancelFunc)создает контекст производный от родительского, также возвращает функцию отмены, с помощью которой этот контекст можно закрыть. Контекст автоматически отменится в переданное, как входной параметр функции, время. -
context.WithTimeout(parent Context, timeout time.Duration) (ctx Context, cancel CancelFunc)создает контекст производный от родительского, также возвращает функцию отмены, с помощью которой этот контекст можно закрыть. Контекст автоматически отменится через интервал времени, переданный, как входной параметр функции.
«Как обрабатывать отмену context?»
Ответ
Отмену контекста можно обрабатывать через канал <-context.Done(), который уведомляет об отмене контекста.
func main() { ctx, cancelFunc := context.WithCancel(context.Background()) numChan := make(chan int) go work(ctx, numChan) go func() { for i := 0; i < 5; i++ { numChan <- i } }() cancelFunc() time.Sleep(1 * time.Second) } func work(ctx context.Context, numChan chan int) { for { select { case <-ctx.Done(): fmt.Println("stop") return case num := <-numChan: fmt.Println(num) } } }Вывод (может отличаться по количеству num)
0 stopПамять в Golang
«Как реализовано хранилище памяти в Go?»
Ответ
Хранилища памяти в Go реализованы с помощью двух подходов:
-
хранение в
stack; -
хранение в
heap.stackв основном используется для хранения локальных переменных, аргументов функции. Из плюсов —stackдостаточно легко очищается. Из минусов — при аллокациях наstackсуществуют копии одних и тех же значений, которые надо хранить и обрабатывать.heapв основном используется для хранения глобальный переменных и ссылочных типов. Из плюсов — при аллокациях наheapсуществует всегда одно уникальное значение, которое надо хранить и обрабатывать. Из минусов —heapтяжело очищается, так как приходится запускать сборщик мусора, который имеет много накладных расходов и останавливает приложение.
«Что обозначает * и &?»
Ответ
& — это адрес блока памяти. То есть &myVar — это адрес того места в памяти, где хранятся данные переменной myVar. Тогда как * можно использовать в двух вариантах:
-
чтобы объявить тип-указатель
var pointVar *int. В данном случае указатель наint; -
чтобы получить значение по адресу
*pointVar. Обратный предыдущему процесс, и здесь мы получим значение по адресуpointVar.
func main() { myVar := "something" var pointVar = &myVar fmt.Println(myVar) fmt.Println(&myVar) fmt.Println(pointVar) fmt.Println(*pointVar) }Вывод
something 0xc000096230 0xc000096230 something«Как происходит передача параметров в функцию?»
Ответ
Параметры в Go всегда передаются по значению. Это значит, что всякий раз, когда мы передаем аргумент в функцию, функция получает копию первоначального значения. Чтобы работать именно с той же самой переменной, не копируя ее, необходимо использовать адрес этой переменной. При этом сам указатель будет скопирован.
func main() { str := "someString" fmt.Println("first val:", str) dontCahngeStr(str) fmt.Println("after dontCahngeStr val:", str) fmt.Println("val addr in main:", &str) cahngeStr(&str) fmt.Println("after cahngeStr val:", str) fmt.Println("val addr in main:", &str) } func dontCahngeStr(str string) { str = "nextStr" } func cahngeStr(str *string) { fmt.Println("addr addr in cahngeStr:", &str) *str = "nextStr" }Вывод
first val: someString after dontCahngeStr val: someString val addr in main: 0xc000010070 addr addr in cahngeStr: 0xc00000e030 after cahngeStr val: nextStr val addr in main: 0xc000010070«Есть ли особенности поведения при передаче map и slice в функцию?»
Ответ
Передача slice и map может заставить усомниться в том, что они передаются в функцию по значению. Однако здесь так же происходит копирование. Структуры slice и map копируются, однако в самих структурах содержатся ссылки на области памяти, благодаря которым создается эффект передачи по ссылке.
func main() { slice := []int{1, 2, 3, 4, 5} fmt.Println(slice) fmt.Printf("%p\n", &slice) changeZeroElem(slice) fmt.Println(slice) } func changeZeroElem(slice []int) { fmt.Printf("%p\n", &slice) slice[0] = 99 }Вывод
[1 2 3 4 5] 0xc0000ac018 0xc0000ac048 [99 2 3 4 5]func main() { store := map[string]int{"first": 1, "second": 2} fmt.Println(store) fmt.Printf("%p\n", &store) changeMapElem(store) fmt.Println(store) } func changeMapElem(store map[string]int) { fmt.Printf("%p\n", &store) store["first"] = 99 }Вывод
map[first:1 second:2] 0xc0000b2018 0xc0000b2028 map[first:99 second:2]«Как функции делятся памятью?»
Ответ
В начале следует сказать про фрейм. Фрейм можно представить как отдельное пространство памяти для конкретной функции. Функция может работать с памятью в своем фрейме, однако не может работать с памятью фреймов других функций. Когда из одной функции мы вызываем другую функцию, происходит переход фреймов. Чтобы использовать какие-то данные предыдущего фрейма в следующем их можно передать по значению. Если необходимо работать не с копией, а именно переменной другого фрейма, необходимо использовать переменные-указатели, которые обеспечивают доступ до переменных других фреймов.
«Можно ли явно аллоцировать переменную в стэке или куче?»
Ответ
Способа явно сказать компилятору Go, где аллоцировать переменную, в куче или в стеке не существует. Но это можно сделать косвенно — стилем написания кода. Решающую роль здесь играет, то, как значение будет использоваться в программе.
Сборщик мусора в Golang
«Что такое сборщик мусора и по какому алгоритму он реализован в Go?»
Ответ
Любую аллоцированную память необходимо очищать после окончания ее использования. В некоторых языках программирования разработчик сам должен управлять этим процессом. В Go неиспользуемые объекты находит и удаляет сборщик мусора. Сборщик мусора — устроен по алгоритму Mark and Sweep (реализация может поменяться, необходимо просматривать изменения).
«Расскажите про алгоритм mark and sweep»
Ответ
Алгоритм Mark and Sweep состоит из двух частей:
-
Markразметка; -
Sweepочистка памяти. Сама стадияMarkреализована с помощью 3 цветного алгоритма. Для наглядности представим, что все наши данные лежат в виде графа, все узлы графа помечаем белым цветом. Алгоритм:
-
идет сканирование объектов первого уровня доступа, тех которые хранятся либо глобально, либо в стэке потока;
-
объекты первого уровня помечаются серым цветом;
-
в каждом сером объекте ищутся ссылки на области памяти;
-
объекты по ссылкам помечаются серым;
-
сам родительский элемент помечается черным;
-
процесс повторяется, пока не останется серых объектов (белые объекты будем удалять на следующем шаге).
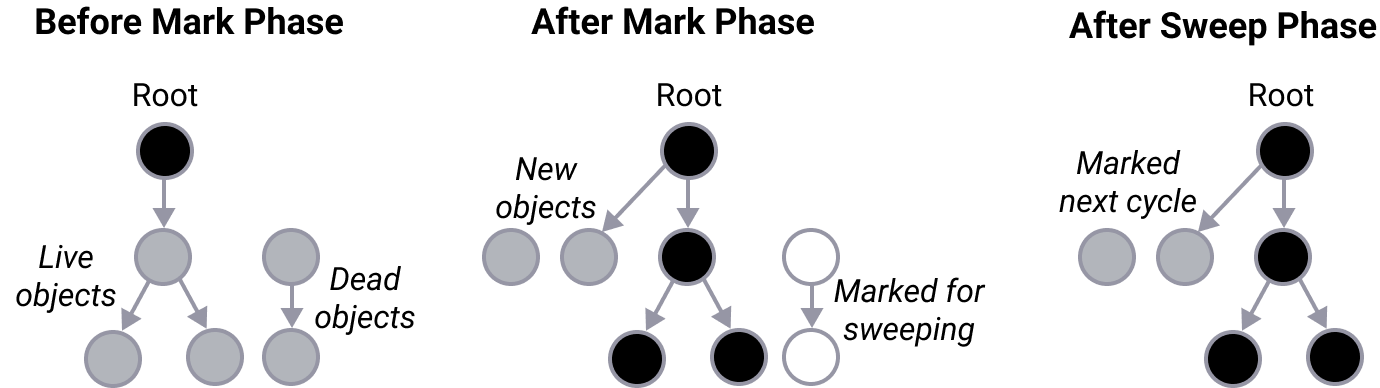
Прежде чем переходить к самому алгоритму необходимо разобрать два понятия stop the world и write barrier.
write barrier — в рамках этой статьи мы будем рассматривать его как некий черный ящик. Основная его цель — контролировать, чтобы сборщик мусора правильно выстраивал и обрабатывал «граф» данных, так как объекты могут перемещаться и иже.
Упрощенный алгоритм сборщика мусора (на момент работы программы, то есть сборщик мусора уже отработал один или больше циклов):
-
завершение цикла очистки
Sweep, на этом этапе вызываетсяstop the world, ожидается пока все горутины достигнут точки безопасности, завершается очистка ресурсов; -
начало цикла
Mark, на этом этапе включаетсяwrite barrier,start the world, сканируются глобальные переменные, выполняется трехцветный алгоритм; -
завершение цикла
Mark, на этом этапе вызываетсяstop the world, после выполнения задач очищаются кэши, завершается разметка; -
начало цикла очистки
Sweep, на этом этапе выключаетсяwrite barrier,start the world, дальнейшая очистка ресурсов происходит в фоне.
«Когда запускается сборщик мусора?»
Ответ
По умолчанию сборщик мусора запускается в тот момент, когда heap увеличился вдвое. Этот параметр также можно настроить с помощью переменной среды окружения GOGC. Вручную сборщик мусора можно запустить с помощью runtime.GC().
«Каковы ресурсы, которые потребляет сборщик мусора?»
Ответ
Сборщик мусора потребляет до 25% CPU для фазы Mark. Помимо этого за цикл работы сборщика мусора два раза происходит остановка приложения (вызов stop the world).
Заключение
Далеко не все аспекты, которые можно спросить на собеседовании удалось осветить в формате статьи. Также Go развивающийся язык и определенная информация может устаревать от версии к версии. По этим причинам, при подготовке в интервью, призываю вас не останавливаться только на изложенных здесь вопросах и ответах, изучайте свой инструмент, это окупится!
Буду признателен любым конструктивным замечаниям. Спасибо!
Спасибо за конструктивные замечания к статье как до, так и после ее выкладки: @user862, @JimTheBeam.
ссылка на оригинал статьи https://habr.com/ru/post/670974/
Добавить комментарий