
Обучать ли модель ML повторно? Многие отвечают на этот вопрос интуитивно или действуют по взятой из ниоткуда схеме: по ночам, раз в месяц, «когда пользователи начинают жаловаться». Команда VK Cloud Solutions перевела статью о том, когда на самом деле стоит переобучать и на что опираться при принятии этого решения.
Примечание редакции: В оригинале статьи используют слово retrain. Мы перевели его как «переобучение», хотя обычно в русскоязычной среде этим термином описывают ситуации, когда модель излишне подгоняется на обучающих данных. В этой статье под переобучением имеют в виду именно повторное обучение модели с нуля.
Главный вопрос: зачем переобучать
Почему мы вообще говорим о переобучении моделей? Ведь мы вложили много сил в их создание.
Всё потому, что ML-модели устаревают. Даже если ничего кардинально нового не происходит, постепенно накапливаются мелкие изменения. Могут возникать два явления — дрейф данных (Data Drift) или дрейф концепций (Concept Drift), либо оба вместе.
Чтобы модели оставались актуальными, их нужно заново обучать паттернам. Они нуждаются в свежих данных, которые лучше отражают реальность. Это и есть «повторное обучение» — мы добавляем новые данные к старому ML-пайплайну и повторно его запускаем.
Скорость устаревания модели зависит от сферы деятельности.

Например, производственные процессы меняются относительно медленно, и модель прогнозирования качества может продержаться целый год. Или до первого внешнего изменения, например появления нового поставщика сырья.
Потребительский спрос больше подвержен колебаниям. Каждую неделю происходят изменения, которые стоит учитывать.
Это не универсальные сроки. Попадаются и производственные модели, которые нужно обновлять после каждой партии, и до скучного стабильные продажи.
В таких сферах, как детекция антифрода, надо помнить о враге по ту сторону баррикад. Он может быстро подстраиваться под ситуацию, изобретать новые типы мошенничества — и, как следствие, новые концепции для нашей модели.
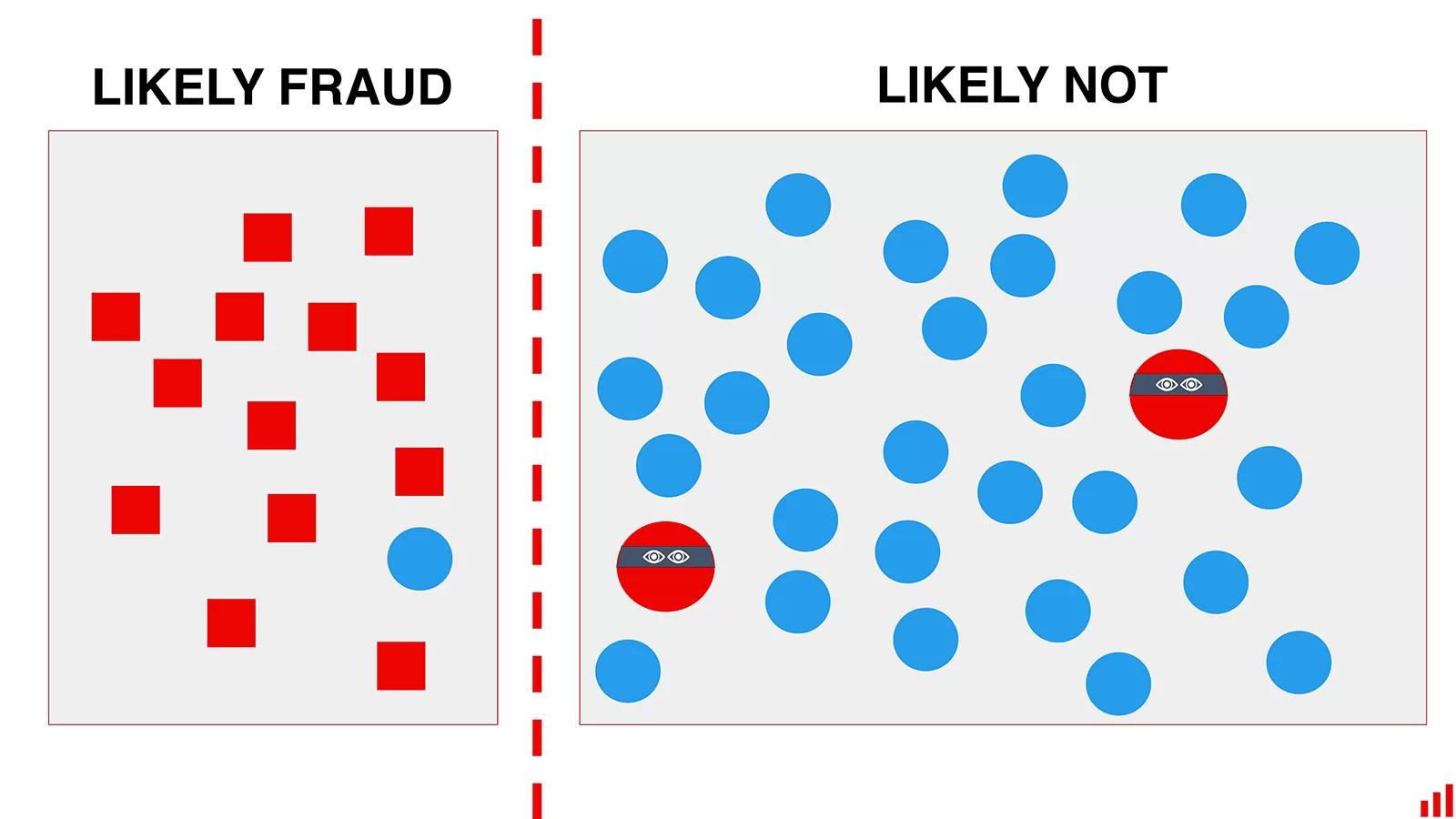
Если модель не менять, со временем мошенники к ней адаптируются
Возьмем, к примеру, SEO. Нечестные сеошники всегда пытаются переиграть систему. И повторное обучение модели убьет двух зайцев: поддержит качество ранжирования и помешает мошенникам. Переобучать стоит, даже если ранжирование не изменится: главное — усложнить адаптацию, изменив правила работы системы.
В системах, работающих с данными в реальном времени, большое значение приобретает свежий фидбек.
Здесь для примера возьмём рекомендацию музыкальных треков. Если пользователю разонравились несколько песен, служба рекомендаций должна отреагировать на эти действия за несколько секунд.
Это не значит, что модель утратила актуальность. Не всегда нужно переобучать ее полностью, но важно учесть изменившиеся вкусы пользователя. Например, мы можем скорректировать вес пользовательских предпочтений — снизить важность одних и повысить других. С точки зрения вычислительных ресурсов такие корректировки можно делать на лету.
Это всего лишь несколько примеров. У разных моделей разные потребности в поддержке — от небольшой калибровки до полного offline-обновления. А иногда нужно и то, и другое. Некоторые модели дрейфуют быстро, другие не слишком. Можно запускать ML-пайплайны раз в день или раз в месяц.
Невозможно составить универсальный график для моделей всех типов и сфер применения. Но когда речь идет о «старении» обычной модели, к вопросу можно подойти системно. Опишем такой подход — его можно применять для простых моделей и использовать как вдохновение для более сложных.
Часть 1. Заранее определяем стратегию повторного обучения
Как часто нужно повторно обучать модели? Как обычно, ответ нужно искать в данных. Определиться с графиком помогут несколько проверок. Можно выполнить все или некоторые — в зависимости от важности модели.
Проверка №1. Сколько данных нужно модели?

Да, это кривая обучения. Наша задача — понять, сколько данных требуется для модели: много или мало. То есть определить, завершено ли текущее обучение, прежде чем переходить к переобучению.
У такой проверки есть приятные побочные эффекты. После нее иногда удается сократить объем данных для обучения и понять, насколько важный сигнал содержит каждая порция данных.
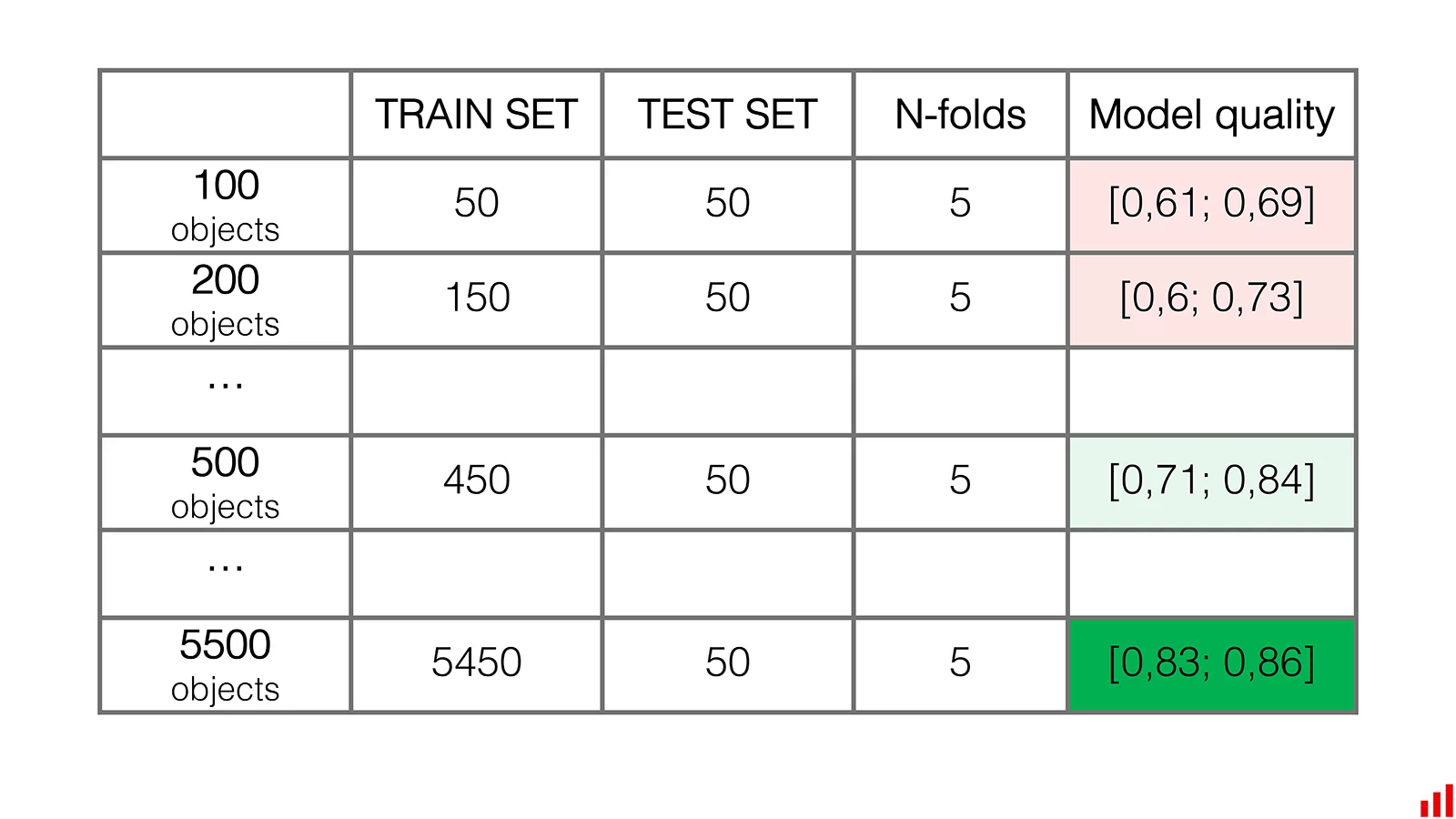
С чего начать? Если у вас есть данные для обучения за продолжительный период, можно проверить, действительно ли все они нужны.
Допустим, у нас есть данные за пять лет. Можно проверить, будет ли модель, обученная на всем дата-сете, лучше модели, обученной только на данных за последние периоды. Может, для тех же результатов хватит данных за пару лет?

В этом примере можно отбросить 40% наиболее старых данных
Если вы имеете дело с данными временных рядов и известными сезонными паттернами, может понадобиться подготовить кастомизированный тест-сет. Когда данных слишком много, эта грубая проверка помогает сократить размер тренировочного сета.
А можно вместо этого сразу перейти к детальному тестированию. Это имеет смысл, когда очевидно, что данных не слишком много. Или когда они непоследовательны: например, это просто группа маркированных объектов, таких как изображения или текст.
Такая проверка похожа на определение количества тренировочных циклов в градиентных методах. Или на выбор количества деревьев в ансамбле во время валидации модели — например, в алгоритме случайного леса.
Подсказка: чтобы определить оптимальное количество, нужно оценить альтернативы. Берем минимальное и максимальное количество деревьев. Задаем шаг. Потом проверяем качество модели для всех вариантов. И не забываем о кросс-валидации.
Далее рисуем, как качество модели зависит от количества деревьев. В какой-то момент мы выходим на плато: добавление деревьев не приводит к улучшению метрик.
Можно перенять этот подход, чтобы проверять, повышается ли качество модели при добавлении данных.
В этом случае временного измерения нет. Каждое наблюдение в нашем тренировочном дата-сете рассматриваем как отдельную запись. Одно размеченное изображение, одна заявка на кредит, одна пользовательская сессия и так далее.
Далее:
- Берем данные, имеющиеся для обучения.
- Выбираем тестовый дата-сет.
- Выбираем начальный размер тренировочного дата-сета — это может быть и половина данных, и всего 10%.
- Задаем шаг — объем добавляемых данных для обучения.
- Начинаем обучать модель с разными размерами тренировочного дата-сета.
Мы можем использовать метод random split и выполнить перекрестный контроль с изменяющимся размером данных для обучения. Смысл в том, чтобы оценить влияние объема данных на метрики модели.
В какой-то момент мы выйдем на плато — на этом можно остановиться. Увеличение объема данных уже не улучшит результаты.

Можно проанализировать результат и решить, какая выборка данных для обучения будет оптимальной. Если она меньше, чем весь доступный тренировочный дата-сет, отбросьте «лишнее». Тогда обучение будет «весить» меньше.
Но может оказаться, что мы не достигли пика, то есть нашей модели для повышения качества нужно еще больше данных:
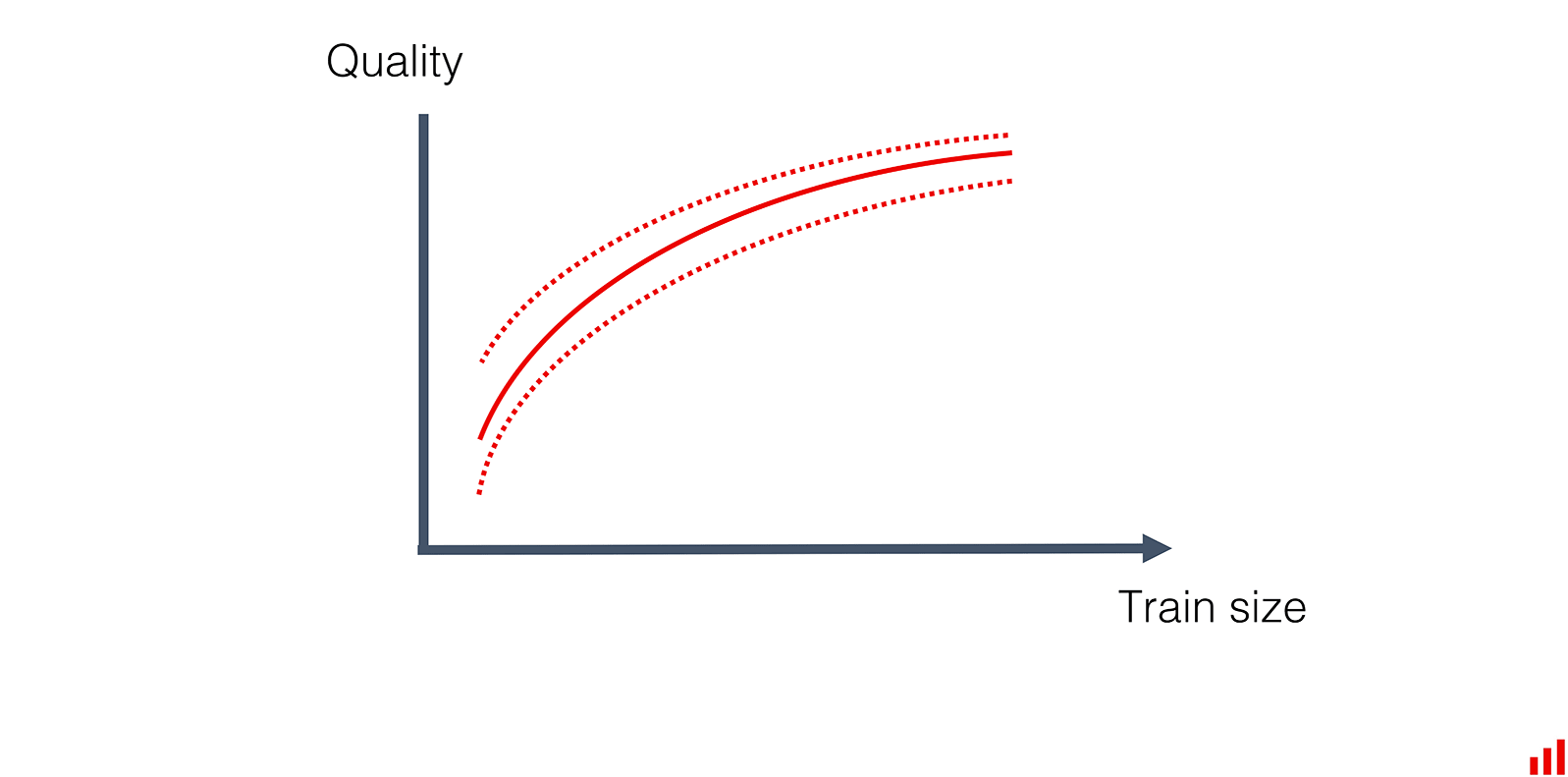
Значит, проверять скорость устаревания модели рано — мы все еще на этапе улучшения. Если с точки зрения бизнеса имеет смысл улучшать модель, над этим надо работать. Может, есть возможность получить больше размеченных данных? Либо придется постоянно улучшать модель и часто ее переобучать, пока мы не достигнем пика метрик.
Экстраполируя результаты, можно грубо оценить, сколько наблюдений нам нужно для достижения искомого качества. Пример для кейса классификации изображений можно посмотреть в Руководстве Keras.
В качестве побочного эффекта мы получаем представление о масштабе. Как быстро меняется качество модели? За 10 наблюдений или за 100? Сколько времени понадобится, чтобы получить эти данные? Дни или месяцы? Анализ старения и повторного обучения модели поможет нам выбрать «подходящий» шаг.
Эта проверка сама по себе не говорит, как часто переобучать модель, потому что не все данные одинаково полезны. Более «ценные» порции данных могут приходиться на выходные. Когда мы перемешиваем данные, мы нивелируем важность этого фактора. Поэтому нужны и другие проверки.
Проверка №2. Быстро ли снизится качество в продакшен-условиях?
Вот еще один полезный эвристический подход. Допустим, есть средняя ожидаемая скорость дрейфа. Возможно, с этой скоростью меняются вкусы пользователя или изнашивается оборудование. Можно:
- Присмотреться к этим данным и оценить их.
- Натренировать модель на более старых данных и последовательно применять ее к последующим периодам.
- Рассчитать, насколько хорошо наша модель работает по мере устаревания. Наша цель — определить, в какой момент метрики модели заметно падают.
Такая однократная оценка уже может снизить неопределенность. Мы приблизительно оценим скорость, с которой устаревает наша модель: за неделю, месяц или гораздо дольше.
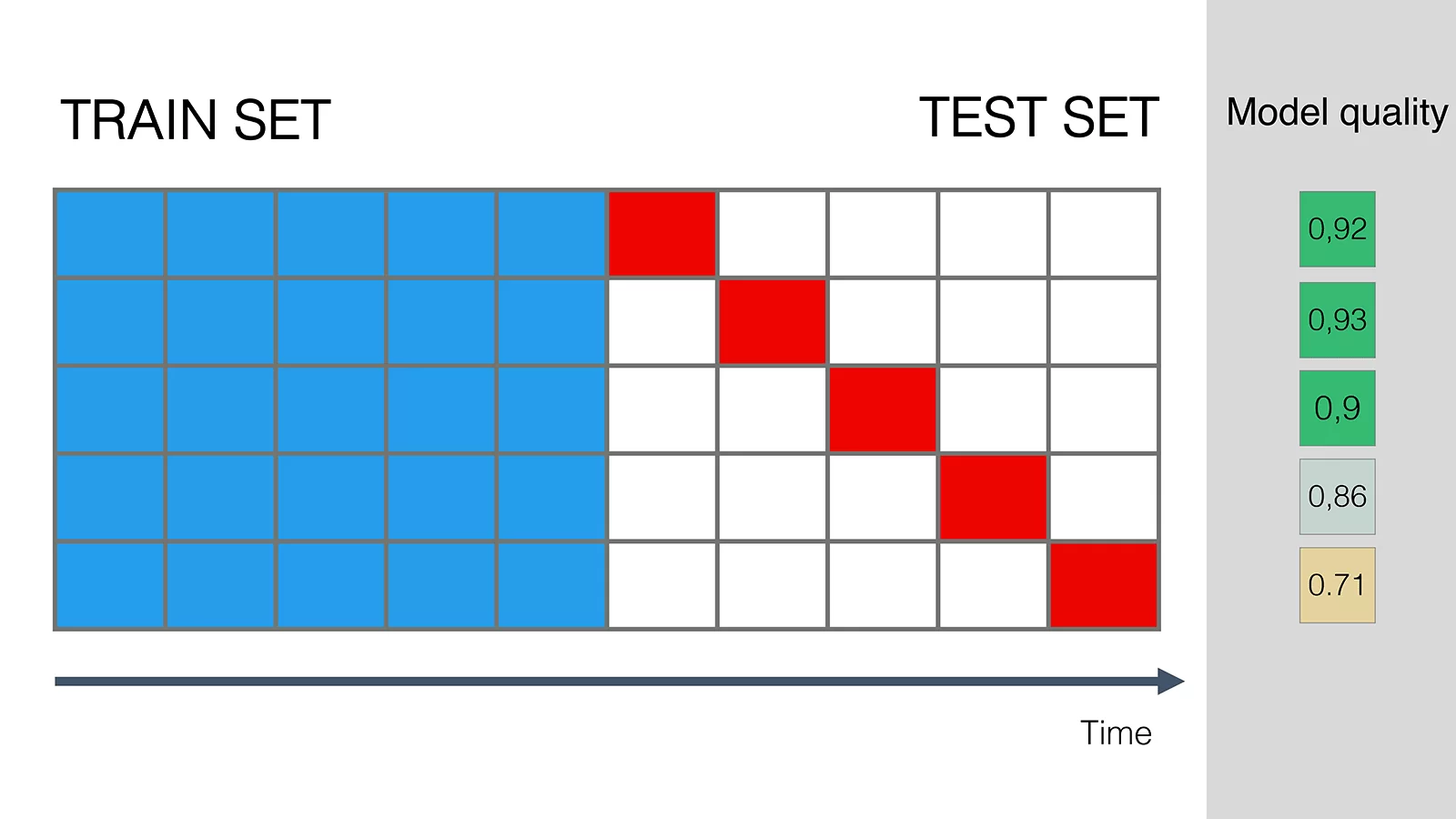
В этом примере мы наблюдаем снижение метрик только через три интервала
Если у нас достаточно данных, повторяем проверку несколько раз, сдвигая исходный набор данных для обучения. После этого можно усреднить результаты с учетом исключений из правил, если они будут.
Так мы получим более точную оценку:

На протяжении работы подход к обучению модели не должен меняться. В противном случае параметры повлияют на устаревание сильнее, чем изменения среды.
Предупреждение: если у вас есть критическое подмножество данных, стоит проверять по ним качество модели как отдельную метрику.
Результаты теста могут быть разными. Иногда выясняется, что модель очень стабильная: даже спустя 6 месяцев она работает как новая. А иногда оказывается, что модель устаревает в два счета. Если с этим трудно справиться, может быть, стоит пересмотреть подход к обучению.
Рекомендации:
- Сделайте модель чуть «тяжелее», зато стабильнее. Например, добавьте больше источников данных или усложните инжиниринг фичей. Такой подход может в моменте дать метрики поменьше, но в долгосрочной перспективе модель будет более стабильной.
- Сделайте модель динамичнее. Обучайте ее на данных за короткий период, но калибруйте чаще, например каждый час. Или присмотритесь к активному обучению.
- По отдельности подойдите к сложностям модели. Вероятно, она быстро деградирует только на отдельных сегментах. Можно избирательно применять модель, исключая их (см. руководство, где мы объясняем эту мысль!), и использовать некоторые методы не из области машинного обучения. А может, вернуться к старым добрым правилам или Human-in-the-loop?
Если результат проверки вас устраивает, запишите число. Ожидаемая скорость устаревания — ключевая переменная в нашем уравнении повторного обучения.
Всегда ли нужно оценивать прошлый дрейф? На самом деле нет. Мо
жно обойтись без этого, если исходить из идеи о постепенной скорости изменений в мире.
Некоторые проблемы динамичны по своей природе
Если вы создаете модель компьютерного зрения для обнаружения дорожных знаков, вам нужно высматривать низкочастотные темные изображения с помехами, но сами знаки преимущественно не меняются.
Это часто справедливо и для текстовых моделей, в которых нужен анализ тональности высказываний или извлечения объектов. Обновления нужны, но обычно не по графику. Имеет смысл искать сегменты с низкими метриками и отслеживать изменения, а не проверять скорость устаревания.
В других случаях модели обычно динамичнее. К ним относятся, например, клиентское поведение, паттерны мобильности населения или проблемы временных рядов вроде потребления электричества. Здесь стоит опираться на определенные темпы изменений или отслеживать прошлый дрейф, чтобы оценить темпы деградации модели.
Эти данные часто имеют временные метки. Чтобы выполнить вычисления, нетрудно заскочить в «машину времени».
Проверка №3. Как часто поступают новые данные?
Мы примерно представляем потребности в повторном обучении. Но можем ли мы его выполнить?
Чтобы запустить пайплайн повторного обучения, нам нужно иметь новые размеченные данные. Это не проблема, если фидбек поступает быстро. Но если есть задержки, приходится ждать или привлекать экспертов по маркировке.
Нужно разобраться, что происходит раньше: появление новых данных или устаревание модели. Это вопрос из области бизнес-процессов: насколько быстро генерируются данные и когда они попадают в ваше хранилище.
Предположим, мы выяснили, что исторически наши модели продаж устаревают каждые две недели. Но новые данные о фактических розничных продажах собирают только раз в месяц. Эта периодичность ограничивает наши возможности повторного обучения.
Вот способы это компенсировать:
- Каскад моделей. Может, какие-то данные появляются раньше? Например, из некоторых точек продаж информация поступает до конца месяца. Тогда можно создать несколько моделей с разными графиками обновления.
- Ансамбль моделей. Можно объединить модели разных типов, чтобы эффективнее бороться с их устареванием. Например, используйте в качестве бейзлайна статистику продаж и бизнес-правила, а потом добавьте машинное обучение, чтобы скорректировать прогнозы. Приблизительные правила могут дать неплохие результаты к концу периода, что сохранит метрики на приемлемом уровне.
- Перестройка модели для увеличения ее стабильности. Можно пожертвовать качеством на тестовом дата-сете в обмен на медленные темпы устаревания.
- Корректировка ожиданий. Насколько важна эта модель? Может, нужно принять реальность и жить в ней? Только не забудьте огласить вновь принятые метрики качества.

Мы можем попасть в одну из двух ситуаций:
- Пытаемся выжать качество моделей из имеющихся данных. Модель деградирует быстрее, чем поступают новые данные. Значит, нам придется переобучать модель каждый раз, когда поступает достаточно большая порция данных.
- У нас есть очередь из новых данных. Мы быстро получаем новые данные, но «старая» модель еще отлично работает. Тогда нужно решить, переобучать ее чаще или реже.
Проверка №4. Как часто надо переобучать модель?

Потребность в этой проверке возникает, если мы можем выбирать график. Давайте рассмотрим конкретный пример:
- У нас достаточно хорошая модель. Нет необходимости все время ее обновлять, чтобы она работала немного лучше.
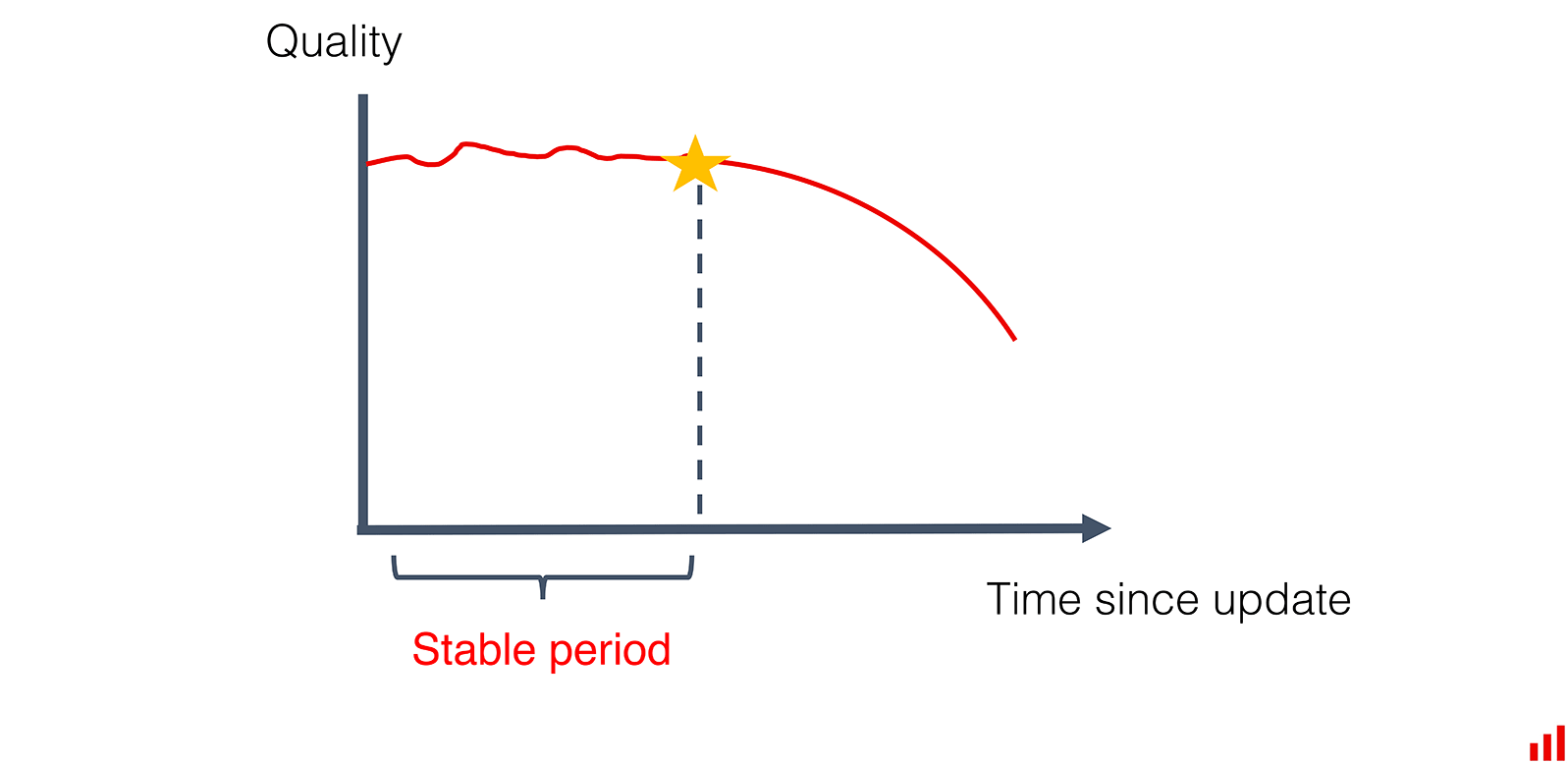
- Обычно метрики начинают снижаться примерно через 60 дней.
- Новые размеченные данные поступают в конце каждой недели.
Так когда нам ее переобучать: раз в неделю, в месяц, в 60 дней?
Можно выбрать периодичность наугад. У избыточного обучения есть свои недостатки, но модель не должна стать хуже. А можем действовать аналитически.
Вернемся к ранее выбранному подходу. Выберем тестовый набор из диапазона до точки устаревания. И начнем эксперимент в период со стабильными метриками качества модели.
Будем добавлять данные небольшими приращениями — неделя за неделей. Наша задача — определить, когда качество на тестовом дата-сете начнет улучшаться.

Из этого эксперимента, возможно, станет ясно, что добавление данных небольшими бакетами не всегда влияет на результат.
Например, если переобучать модель данными, которые поступают каждый день, это не влияет на тестовые метрики. Чтобы увидеть результаты, нужно подождать пару недель И нет смысла переобучать модель чаще.
Причина в «полезности данных». Возможно, это сезонные паттерны или критическая масса редких событий, которые накапливаются с течением времени. Чтобы зафиксировать изменения, модели требуется больше данных.
Реалистичный выбор окна для повторного обучения может оказаться меньше, чем кажется на первый взгляд.

Чтобы определиться с выбором, можно посмотреть, сколько улучшений приносит каждый бакет. В другой части уравнения — расходы и трудозатраты на частое переобучение. Можно повторить проверку несколько раз, чтобы выяснить, когда в среднем наступает заметное улучшение качества. Или просто выбрать число в этом узком промежутке.
Чем плохо частое повторное обучение? Кто-то скажет: «Хуже от него не будет». И действительно, разве плохо переобучать модель чаще, чем необходимо?
На самом деле плохо: сложность и затраты возрастают, а надежность снижается. «Работает — не трогай» — справедливый принцип и для машинного обучения.
 Обновление не каждой модели сродни запуску ракеты, но это все-таки не бесплатное удовольствие
Обновление не каждой модели сродни запуску ракеты, но это все-таки не бесплатное удовольствие
У каждого обновления есть цена. В первую очередь это прямые расходы на вычислительные операции и иногда на разметку данных. А еще трудозатраты команды.
Да, обновления можно запускать автоматически. Но если в новой модели на этапе валидации возникнет сбой из-за проблем с данными или их незначительного устаревания, всей команде придется устранять неисправность. И все потеряют время зря — ведь переобучать модель не было нужды.
При этом в работу будут вовлечены не только дата-сайентисты — понадобятся и другие специалисты, что сильно повысит организационные расходы и затраты на compliance cost.
Еще если нам только предстоит создать пайплайны повторного обучения, придется решать, насколько сложная система нужна.
Если мы переобучаем модели раз в квартал, хватит простой сервисной архитектуры. Если же обновления требуются каждый день, имеет смысл сразу инвестировать в набор инструментов посложнее. А для этого нужно четко представлять ожидаемое повышение качества.
Конечно, если у вас уже есть современная MLOps-платформа, расходы на вычислительные операции несущественны, а сценарий использования не критичен, от этих вопросов можно отмахнуться. В противном случае точный подход к эксплуатации модели однозначно со временем окупится!
Проверка №5. Надо ли отказываться от старых данных?
Допустим, мы определили разумный график повторного обучения модели. Как именно его выполнять? Взять новые данные, а старые выкинуть? Нужно ли сохранять «остатки»?
Это тоже можно продумать. Возьмем модель с такими характеристиками:
- мы использовали для обучения шесть бакетов данных;
- модель хорошо работает на протяжении следующих трех;
- потом во время четвертого качество падает;
- мы решили проводить переобучение после каждых двух новых бакетов данных.

Зафиксируем план повторного обучения. Это два бакета. Мы знаем, что они привносят необходимое нам повышение качества!
Потом можно поэкспериментировать с исключением старых данных бакет за бакетом. Наша задача — оценить влияние этих «старых» данных на метрики.
Это напоминает первую проверку, когда мы обдумывали, надо ли исключать старые данные при первоначальном обучении. Но теперь мы используем определенный тестовый дата-сет, устаревание которого известно. И с более точным шагом — отбрасываем данные за месяцы, а не за годы.
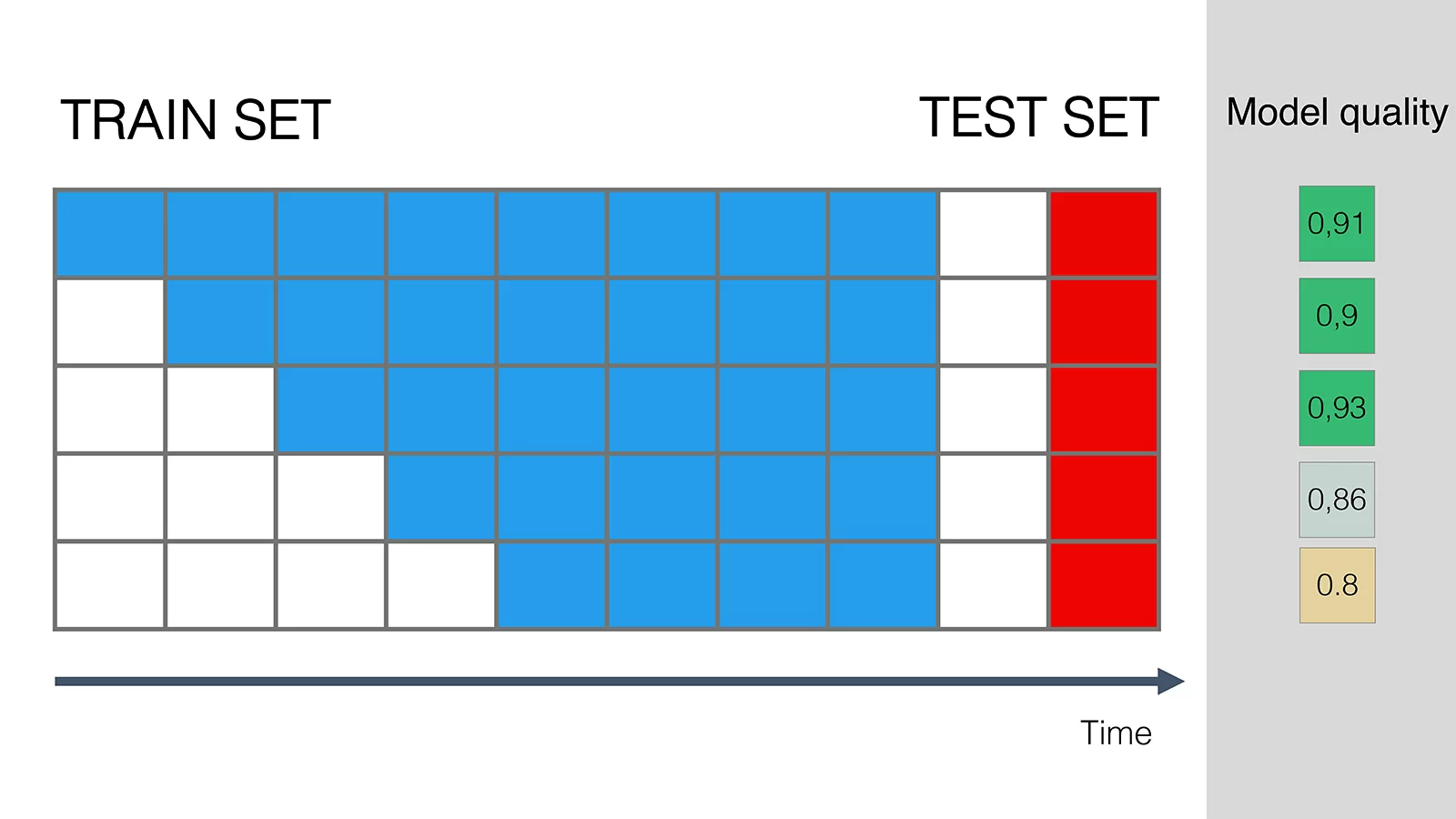
В итоге может получиться следующее:
- Из-за отбрасывания данных модель работает хуже. Тогда эти данные нужны.
- Отбрасывание старых данных не влияет на качество. «Хозяйке на заметку»: можно сделать обновления модели более легковесными. Например, исключать бакет старых данных всякий раз, как добавляем новый.
- Отбрасывание старых данных повышает качество. Бывает, что наша модель забывает устаревшие паттерны и становится более релевантной. Это хорошая новость: мы работаем в быстро меняющемся мире и нам не нужна слишком «консервативная» модель.
Могут быть и более сложные сочетания:
- Сохраняем данные для слабо представленных типов точек и небольших классов. Если отбросить данные за прошлые периоды, это может непропорционально повлиять на метрики для менее распространенных классов. Такое стоит контролировать. Можно избавляться от старых данных избирательно: удалять то, что обновляется часто, и не трогать то, что меняется редко.
- Присваиваем больший вес новым данным. Если из-за старых данных модель работает хуже, можно снизить важность старых данных, но не убирать их из модели полностью. Или даже задать разную скорость для разных классов.
Нужны ли вообще такие сложности? Зависит от обстоятельств. Планировать повторное обучение точно нужно. Но вот какую степень точности заложить? Тут нужно смотреть на сценарий использования.
Некоторые модели сами по себе легковесны, им нужно немного данных, а рисков на проде у них минимум. Здесь можно не углубляться в детали — хватит одной-двух проверок работоспособности.
Другие модели критически важные, для работы с ними нужные обширные руководства и подробный план по поддержке. Тут стоит изучить поведение модели максимально тщательно.
Идеального рецепта нет. Как и всегда, лучшая приправа для аналитики — здравый смысл и обоснованные допущения!
Часть 2. Мониторинг метрик модели в действии
В первой части мы изучали прошлое. Теперь модель готова, и пора отправляться в путь. Расписание обновлений нам пригодится, но это не панацея. Во время работы модели многое может измениться.
Понять, пора ли обновлять продакшен-модель, поможет мониторинг. Нам нужно оценить метрики на реальных данных и сравнить с эталонными показателями. Обычно это данные для обучения или за какой-то прошедший период. Так мы узнаем, надо ли вмешаться раньше, чем мы планировали. Или, наоборот, перенести обновление на более позднее время.
Проверка №1. Мониторинг изменений метрик

Если реальное положение дел быстро проясняется, можно вычислить фактические метрики. Например, среднюю ошибку для регрессионной модели или Precision модели вероятностной классификации. В идеале стоит добавить бизнес-метрики, чтобы напрямую отслеживать влияние модели на эти показатели. Если у вас есть конкретные важные сегменты, обратите на них внимание.
Можно настроить дашборды и пороги для мониторинга, чтобы получать уведомления при снижении качества модели. Или настроить триггеры, автоматически запускающие повторное обучение.
Дашборд Evidently: мониторинг ошибок для модели прогнозирования спроса
Часто выставление порогов полностью зависит от сценариев использования. Иногда даже небольшое ухудшение приводит к большим потерям для бизнеса. Вы в буквальном смысле слова знаете, во сколько вам обходится каждый процент точности. В других случаях колебания не так важны.
Стоит настроить эти пороги во время первой оценки метрик. Какое снижение считать действительно серьезным? Зная бизнес-кейс, вы можете определить, что заслуживает внимания, и посчитать трудозатраты на повторное обучение.
На этом этапе можно также повторить некоторые проверки из первой части, но с новыми данными. Всегда есть шанс, что данные offline-обучения не в полной мере отражали реальную ситуацию. Можно проверить, насколько ваша оценка устаревания модели соответствует реальному положению дел.
Если вы используете для оценки «эталонный дата-сет», возможно, стоит пересмотреть и обновить его. Реальные данные могут привнести новые граничные случаи или сегменты, с которыми ваша модель должна хорошо справляться.
Проверка №2. Мониторинг смещений данных
Если реальное положение дел не сразу бросается в глаза, есть риск застрять, дожидаясь новых значений или меток. Когда это происходит, мы остаемся только с данными. В таком случае стоит воспринимать дрейф данных и дрейф предсказаний как возможность оценить вероятное устаревание модели.

Зная форму входящих данных и ответ модели на них, мы можем оценить, насколько они отличаются от тренировочного дата-сета.
Представьте, что вы запускаете модель каждый месяц, чтобы выбрать подходящее маркетинговое предложение для клиентов и передать его в команду колл-центра. Для начала можно проверить входящие данные для статистического дрейфа. Если распределения входящих данных остаются стабильными, модель справится с задачей. Обновлять не нужно, все в порядке.

Дэшборд Evidently: распределения признаков без дрейфа
Если дрейф обнаружен, это раннее предупреждение. У вас есть возможность решить, какие меры принять. Например, задать другой порог принятия решения в вероятностной классификации или исключить некоторые сегменты. А если вы можете получить новые размеченные данные и переобучить, пора приступать.
Дрейф ключевых фичей часто предшествует видимому устареванию модели. Соответствующий пример мы привели в этом руководстве. Ключевые признаки сместились за пару недель до того, как метрики модели стали снижаться.
Поэтому имеет смысл следить за дрейфом данных, даже если новая разметка подтягивается часто. Для критически важных моделей это сигнал, на который стоит обратить внимание.
Часть 3. Повторное обучение vs обновления
Мы готовы к устареванию модели, правильно определили график повторного обучения и настроили оповещения, чтобы не пропустить изменения в реальном времени. Что делать теперь?
Важно, чтобы ваша модель работала и в нее поступали новые данные. Мы исходим из этого, когда проверяем оптимальные периоды между обучениями. Исключите старые данные, добавьте новые и повторите тот же пайплайн обучения. Это разумная реакция на любое снижение метрик. Но такой подход работает не всегда.

Если мы сталкиваемся со значительным дрейфом, возможно, модель придется переделать. Представьте, что произошло важное внешнее изменение, например мы столкнулись с совершенно новым сегментом клиентов.
Может, нужно отладить параметры модели или изменить ее архитектуру? Пересмотреть пре- или постобработку? Изменить вес данных, чтобы последняя выборка стала наиболее важной? Построить ансамбль, учитывающий новые сегменты?
Здесь мы движемся от науки к искусству. Решение зависит от сценария использования, серьезности изменений и здравого смысла дата-сайентиста.
Есть и оборотная сторона медали: возможно, нам удастся усовершенствовать модель. Можно начать с модели попроще, постепенно собирать данные и в итоге построить систему со сложными паттернами. Или добавить новые признаки из других источников?
Но учтите, что у новой модели может быть другой профиль устаревания! Чтобы к этому подготовиться, нужно:
- Не забывать о варианте с обновлением. Если рассматривать только упрощенное повторное переобучение, можно упустить из виду другие способы поддержания работоспособности модели. Имеет смысл запланировать регулярные проверки имеющихся моделей для оценки потенциала их усовершенствования.
- Выстроить порядок анализа модели. Четче представлять, как работает ваша модель и почему. Это не просто отдельная метрика вроде ROC AUC. Можно искать сегменты с низкими значениями метрик, изменения в данных, корреляции признаков, паттерны в ошибках модели и многое другое.

Чтобы все это выяснить, можно добавить больше представлений в дашборды для мониторинга. Или тщательно проанализировать батчи во время запланированной проверки модели. Если вы хорошо представляете себе контекст, это помогает действовать увереннее и выбирать правильные приоритеты при проведении экспериментов.
Создать каналы коммуникации. Данные не всегда меняются «сами по себе». Скажем, бизнес-специалисты в вашей компании планируют обновление процесса, в котором задействована ваша модель. В идеале вы не должны узнать о новой линейке продуктов по внезапному дрейфу данных во время мониторинга. Вам должны сообщить об этом заранее, чтобы вы подготовили модель к «холодному» запуску.
Обновления и повторное обучение модели могут зависеть от разных внешних триггеров: бизнес-решений, прямых запросов, изменений в процессе хранения данных. Должен быть способ все это оптимизировать.

Выводы
Так когда же переобучать модель? Чтобы ответить на этот вопрос для конкретного сценария использования, нужно учесть несколько моментов.
1. Запланируйте регулярное повторное обучение вместо графика, составленного наобум. Для этого определите, с какой периодичностью повторное обучение необходимо и возможно, и выберите для него оптимальную частоту.
2. Отслеживайте фактические метрики. Следите за продакшен-моделью — так вы вовремя обнаружите устаревание или будете знать, что у вас все под контролем.
3. Анализируйте. Повторное обучение не единственный вариант. На основе детальных сведений о метриках моделей вы сможете решать, как именно реагировать на изменения.
Команда VK Cloud Solutions развивает собственные ML-решения. Будем признательны, если вы их протестируете и дадите обратную связь. Для тестирования пользователям при регистрации начисляем 3000 бонусных рублей.
Читать по теме:
ссылка на оригинал статьи https://habr.com/ru/company/vk/blog/671224/
Добавить комментарий