Следить за обновлениями блога можно в моём канале: Эргономичный код
Это второй пост в серии, посвящённый диаграмме эффектов:
-
«Спецификация» — назначение диаграммы, основные концептуальные элементы и их визуальное представление.
-
«Пример построения, проект True Story Project (TSP)» — процесс построения диаграммы эффектов реального проекта.
-
«Декомпозиция системы на модули на базе диаграммы эффектов» — рациональный подход к разбиению системы на модули с помощью диаграммы эффектов и его применение для декомпозиции проекта TSP.
-
«Перевод диаграммы в код» — процесс трансляции диаграммы в исходный код на примере проекта TSP.
Введение
Ведущие разработчики (ака техлиды, тимлиды, архитекторы) встречаются с целым рядом нетривиальных вопросов:
-
Как оценить трудоёмкость проекта?
-
Как обеспечить низкую сцепленность (читай: низкую стоимость) системы?
-
В каком порядке реализовывать части системы и как эффективно распараллелить работу?
-
И ключевой вопрос — а что вообще надо сделать-то?
Я для поиска ответов на эти вопросы использую диаграмму эффектов. Чтобы научить этому и свою команду, я поэтапно описал процесс создания диаграммы эффектов своего последнего коммерческого проекта.
Думаю, эта методика будет полезна не только моей команде, но и всем разработчикам, которые хотят научиться уверенно находить ответы на эти вопросы.
Диаграмма эффектов системы актуализации данных в Яндекс.Картах и 2Гис (True Story Project, TSP)
Я только что сделал небольшой проект по автоматизации обновления информации о компании в Яндекс.Картах и 2Гис. Это идеальный проект для иллюстрации диаграммы эффектов — он небольшой, но включает все основные типы событий и ресурсов (картинка кликабельна):

Все новые проекты я начинаю с диаграммы эффектов и этому есть ряд причин.
Самая главная: построив диаграмму эффектов, я получаю целостную картинку того, что необходимо сделать.
Затем, на этапе оценки, формула (<кол-во операций>+<кол-во ресурсов>) * 8 часов даёт хорошее первое приближение трудоёмкости работы, если все операции и ресурсы типовые. По этой формуле ожидаемая трудоёмкость реализации проекта TSP составляет 14 * 8 = 112 часов. А фактически весь проект я сделал за 130 часов, включая построение диаграммы эффектов и всевозможные административные издержки.
Глядя на диаграмму эффектов, я могу убедиться, что ничего забыл и понимаю, как реализовать каждую функцию системы. Это даёт мне высокую степень уверенности в точности оценки.
Далее, на этапе проектирования, я использую диаграмму эффектов для разбиения системы на модули с высокой связанностью и низкой сцепленностью.
Наконец, на этапе планирования работ полученные модули, а также явные и, что важнее, неявные связи между ними я использую для определения порядка выполнения и возможности распараллеливания работ.
Процесс построения диаграммы
Этот проект я сделал по «Time&Material», поэтому на самом деле в рамках реализации сделал не полную диаграмму, приведённую выше, а краткую с событиями — её построение я и опишу.
Итак, поехали. На старте у меня было ТЗ, которое можно ужать до следующих пунктов:
-
У заказчика есть проблема: ему необходимо держать информацию о его организациях в ряде геосервисов в актуальном состоянии.
-
На первом этапе необходимо актуализировать информацию в Яндекс.Картах и 2Гис.
-
Организаций у заказчика существенно больше тысячи и построение фида (жаргонное название списка организаций заказчика) требует существенного времени и ресурсов. Поэтому фид необходимо обновлять по расписанию.
-
Интеграция с Яндекс Картами заключается в том, что робот Яндекса приходит на специально выделенный URL и забирает оттуда фид в XML-формате.
-
Яндекс требует, чтобы фид всегда был доступен по заданному URL, поэтому необходимо обеспечить постоянное хранение последнего сгенерированного фида.
-
Интеграция с 2Гисом выполняется посредством отправки фида на Email, но уже в формате xlsx.
-
Список организаций необходимо получать из специального сервиса заказчика по REST API.
-
Ещё часть данных хранится во внутренней СУБД заказчика и извлекается с помощью JDBC и SQL-запроса, предоставленного заказчиком.
-
Наконец, фид может содержать ссылки на фотографии организаций, и управление этими фотографиями должен обеспечить разрабатываемый сервис. Доступ к этой функциональности должен быть обеспечен посредством REST API. Конкретное хранилище изображений можно выбрать на своё усмотрение.
Работу можно начать сразу с построения диаграммы эффектов, но я обычно в первом проходе составляю просто списки событий, операций и ресурсов, т.к. по мере вычитки ТЗ их состав наверняка будет меняться и уточняться. Кроме того, при первой вычитке ТЗ я обычно строю ER-диаграмму, но в данном случае модель данных примитивная я не буду усложнять пример её построением.
Поэтому давайте пройдёмся по «ТЗ» и сделаем на его основе три артефакта: список операций системы, список событий системы и список ресурсов.
Шаг №1: построить списки событий, операций и ресурсов
Я буду описывать процесс так, как будто в первый раз вычитываю ТЗ сверху вниз. Поэтому некоторые элементы сначала обозначу как непонятные, а потом уточню, дойдя до соответствующего пункта в ТЗ.
Пройдёмся по пунктам ТЗ.
|
У заказчика есть проблема: ему необходимо держать информацию о его организациях в ряде геосервисов в актуальном состоянии. |
Из этого пункта мы можем сделать предположение, что у нас будет ресурс «Коллекция организаций», но пока не понятно, как он будет реализован . Добавляем его в соответствующий список со знаком «?». |
|
На первом этапе необходимо актуализировать информацию в Яндекс.Картах и 2Гис. |
Пункт №2 говорит о том, что нам потребуются ещё 2 ресурса — «Интеграция с Яндекс.Картами» и «Интеграция с 2Гис» — также добавляем в список с «?». |
|
Организаций у заказчика существенно больше тысячи и построение фида требует существенного времени и ресурсов. Поэтому фид необходимо обновлять по расписанию. |
Этот пункт даёт нам событие «Scheduler: Истёк срок действия фида» и операцию «Обновить фид» — добавляем в списки событий и операций. Уже сейчас понятно, что эта операция будет связана со всеми известными на данный момент ресурсами — можно это как-то отметить в списке, но я на первом проходе не обозначаю связи, чтобы держать списки максимально простыми. |
|
Интеграция с Яндекс Картами заключается в том, что робот Яндекса приходит на специально выделенный URL и забирает оттуда фид в XML-формате. |
Пункт №4 проясняет интеграцию с Яндексом. На самом деле у нас pull-модель (Яндекс «вытягивает» фид из нашей системы), а не push-модель (когда мы «толкаем» фид в Яндекс). Это даёт нам новое событие и операцию — «HTTP: Запрос фида» и операцию «Выдать фид Яндекса». Тут мы должны задуматься, какой ресурс обеспечит реализацию операции — сейчас у нас такого нет, зато есть устаревший «Интеграция с Яндекс.Картами». Очевидно, нам нужен какой-то кэш, куда операция «Обновить фид» будет писать данные, а операция «Выдать фид Яндекса» будет их оттуда забирать — меняем название ресурса в списке на «Фид Яндекса». |
|
Яндекс требует, чтобы фид всегда был доступен по заданному URL, поэтому необходимо обеспечить постоянное хранение последнего сгенерированного фида. |
Пункт №5 дальше уточняет этот ресурс — это должен быть какой-то постоянный кэш, добавляем соответствующую пометку в список. |
|
Интеграция с 2Гисом выполняется посредством отправки фида на Email, но уже в формате xlsx. |
Этот пункт проясняет способ реализации интеграции с 2Гис — Email, уточняем его в списке. |
|
Список организаций необходимо получать из специального сервиса заказчика по REST API. |
Пункт №7 уточняет способ реализации ресурса «Коллекция организаций» — REST, уточняем его в списке. |
|
Ещё часть данных хранится во внутренней СУБД заказчика и извлекается с помощью JDBC и SQL-запроса, предоставленного заказчиком. |
Пункт №8 определяет ещё один ресурс операции «Обновить фид» — «JDBC: Дополнительная информация», добавляем его в список. |
|
Фид может содержать ссылки на фотографии организаций, и управление этими фотографиями должен обеспечить разрабатываемый сервис. Доступ к этой функциональности должен быть обеспечен посредством REST API. Конкретное хранилище изображений можно выбрать на своё усмотрение. |
Пункт №9 определяет новый ресурс «Изображения» и набор операций «Загрузить изображение», «Скачать изображение», «Выдать список изображений организации», «Удалить изображение», с набором соответствующих событий об обращениях к HTTP-эндпоинтам. |
В итоге у нас получились следующие списки.
События:
-
Scheduler: Истёк срок действия фида;
-
HTTP: Запрос фида;
-
HTTP: Запрос загрузки нового изображения;
-
HTTP: Запрос изображения;
-
HTTP: Запрос списка изображений организации;
-
HTTP: Запрос удаления изображения.
Операции:
-
Обновить фид;
-
Выдать фид Яндекса;
-
Загрузить изображение;
-
Скачать изображение;
-
Выдать список изображений организации;
-
Удалить изображение.
Ресурсы:
-
REST: Коллекция организаций;
-
Постоянный Кэш?: Фид Яндекса;
-
Email Server: Интеграция с 2Гис;
-
JDBC: дополнительная информация;
-
???: Изображения.
Теперь построим диаграмму эффектов, просто перенося в неё элементы списков, попутно отмечая связи между ними.
Шаг №2: нарисовать остальную сову (построить диаграмму эффектов)
Как именно переносить элементы из списков на диаграмму — сверху вниз, снизу вверх или в случайном порядке — не так важно. Я предпочитаю идти по событиям, раскрывая целиком все эффекты этого события.
Например, если начать с первого события «Истёк срок действия фида», то мы раскрутим сразу половину диаграммы — само событие «Истёк срок действия фида», операцию «Обновить фид», ресурсы «Коллекция организаций», «Дополнительная информация», «Изображения», «Фид Яндекса» и «Интеграция с 2Гис» Добавляем всё это на диаграмму, связываем операции с ресурсами соответствующими эффектами и получаем примерно такую картину:

После взгляда на эту диаграмму у меня загорается «алярма!» — две красные стрелки из одной операции часто свидетельствуют о нарушении одного из принципов проектирования:
-
низкой сцепленности, высокой связности;
-
единственности ответственности;
-
открытости/закрытости.
Это не всегда так, но в данном случае текущая версия диаграммы точно нарушает третий из них — добавление нового геосервиса потребует модификации существующего кода. А у нас в бэклоге, по секрету, болтается ещё потенциальная интеграция с Гуглом. Про сцепленность и единственность ответственности тоже можно порассуждать, но не буду, чтобы не размывать фокус поста.
Самым простым и универсальным способом расцепить эффекты записи является шина событий. В нашем случае она вполне подойдёт. Для того чтобы провести этот «рефакторинг» нам надо добавить новый ресурс «Тема (Topic) ‘Сгенерирован новый фид’» и соответствующее событие «Оповещение о генерации нового фида», которое будет обрабатываться новыми операциями «Обновить фид Яндекса» и «Отправить фид в 2Гис». Добавив всё это на диаграмму (про списки можно уже забыть), получаем новую версию:
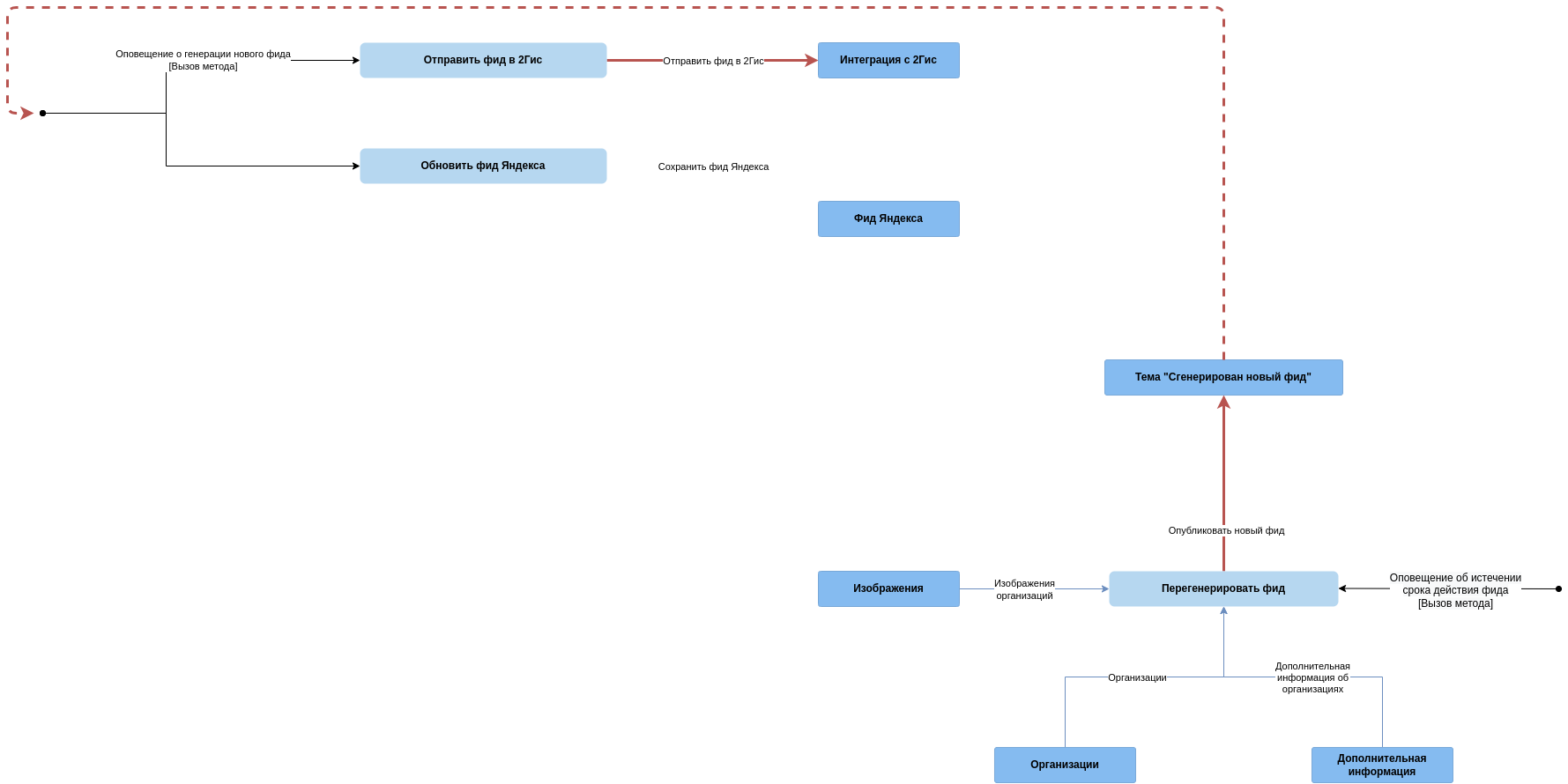
Теперь обновление фида открыто для расширения новыми интеграциями без изменения существующего кода.
Затем я обращаю внимание на то, что операция «Обновить фид» будет достаточно сложной, так как требует много ресурсов. Поэтому я задумываюсь о том, как она будет реализована — «я пробегусь по списку организаций, для каждой организации подтяну дополнительную информацию и изображения, данные свяжу через такие-то поля — все необходимые ресурсы есть, верхнеуровнево всё понятно», подумаю я.
Ещё я подумаю, что мне надо будет убедиться в том, что внешние ресурсы предоставляют мне нужное API. В частности, при выборе способа реализации ресурса «Изображения», который у меня пока под вопросом, мне надо будет убедиться, что выбранный способ обеспечит возможность хранения привязки файлов изображений к организациям. Но я это пока просто помечу в заметках по проекту и продолжу строить диаграмму эффектов.
На этом ветка обработки события «Истёк срок действия фида» у нас заканчивается и мы можем переходить к следующему событию — «Запрос фида». Для этого события уже всё готово — осталось только привязать его к ресурсу «Фид Яндекса» через операцию «Выдать фид Яндекса».
Далее мы аналогичным образом добавляем на диаграмму события и операции, связанные с изображениями.
Теперь по реализации осталось два вопроса: как реализовать ресурсы «фид Яндекса» и «Изображения»? Сами фотографии явно лучше хранить в хранилище BLOB-ов вроде Amazon S3. Там же можно хранить и фид Яндекса — у этого ресурса тривиальное API сохранения и получения файла по ключу, а размер файла исчисляется мегабайтами.
Но при ближайшем рассмотрении выясняется, что с фотографиями есть нюанс — помимо операций по ключу есть и поиск по организации. Теоретически это можно реализовать посредством bucket-ов или «папок» S3, но на мой вкус это решение уже начинает дурно пахнуть. А чуть позже, когда мы внимательнее изучим формат фида Яндекса, мы увидим, что у фотографий есть ещё и метаинформация в виде типа и тэгов — хранить это в S3 будет уже совсем плохой идеей. Значит нам нужна более продвинутая СУБД. У меня «продвинутой СУБД по умолчанию» является PostgreSQL.
PostgreSQL отлично справится с хранением привязки и метаинформации изображений, но он не предназначен для хранения сотен гигабайт самих изображений. Поэтому абстрактный ресурс «Изображения» будет состоять из двух технических частей — «Файлы» и «Метаинформация». Это нам создаст определённые проблемы с согласованностью данных (существование файла без метаинформации или наоборот). Однако, это будет не критично, если упорядочить операции добавления и удаления правильным образом — добавление файла, добавление меты, удаление меты, удаление файла. В этом случае проблема будет заключаться в том, что в случае ошибок, в S3 будут оставаться мусорные файлы, но если это вдруг действительно станет проблемой — можно будет достаточно безболезненно реализовать сборку этого мусора.
Все эти соображения в качестве примечания или описания ресурса стоит внести на диаграмму, если её целью является документирование реализации (т.е. планируются её долгий срок жизни или широкая аудитория). Я же эту диаграмму делаю для себя, чтобы спроектировать систему, оценить и спланировать работы. Поэтому не стану загромождать диаграмму этой информацией.
В итоге получаем финальную версию диаграммы эффектов проекта True Story в краткой нотации с событиями:

Заключение
Построение диаграммы эффектов уже дало нам много полезных штук:
-
Хорошее представление о том, что надо сделать — какие операции есть у системы и что они должны делать.
-
Список ключевых работ, которые необходимо выполнить для решения задачи — это можно взять за основу для оценки трудоёмкости работ.
-
Возможность увидеть часть реализации, в которой можно было легко ошибиться и избежать этой ошибки.
-
Интуитивно-понятную иллюстрацию для декомпозиции системы на модули — вы же тоже видите на диаграмме модули изображений, фида, интеграции с Яндексом и 2Гисом?
Но вернёмся к нашим изначальным вопросам:
-
Как оценить трудоёмкость задачи?
-
Как обеспечить низкую сцепленность системы?
-
В каком порядке реализовывать части системы и как эффективно распараллелить работу?
-
И ключевой вопрос — а что вообще надо сделать-то?
На последний вопрос мы получили исчерпывающий ответ.
Для ответа на первый вопрос у нас появились все входные данные и осталась только механическая работа по оценке простых и понятных блоков.
А вот ответов на второй и третий вопросы мы пока не получили. Для того чтобы их найти, нам необходимо декомпозировать систему на модули, о чём я напишу в следующем посте.
ссылка на оригинал статьи https://habr.com/ru/post/671226/
Добавить комментарий