Уже традиционно в рамках PHDays мы организовали AI CTF — соревнование в формате capture the flag, затрагивающее риски безопасности систем ИИ. Что было интересного в этом году, расскажем ниже в посте.
Но сейчас немного истории:
AI CTF 2019: habr.com/ru/company/pt/blog/454206/
AI CTF 2021: habr.com/ru/company/pt/blog/560474/
Разбор заданий
Как и в прошлом году, задания оценивались динамически: чем больше решивших задание, тем меньше становилась его стоимость. Изначально все задания стоили 200, по мере решения их участниками их стоимость уменьшалась до минимальных 50.
Начнем с самых популярных и перейдем к самым сложным. В конце поста расскажем об итогах.
StegoRegression
Это задание оказалось самым популярным и решаемым. Практически все участники, кто пытался его решить, поняли, что нужно делать 🙂
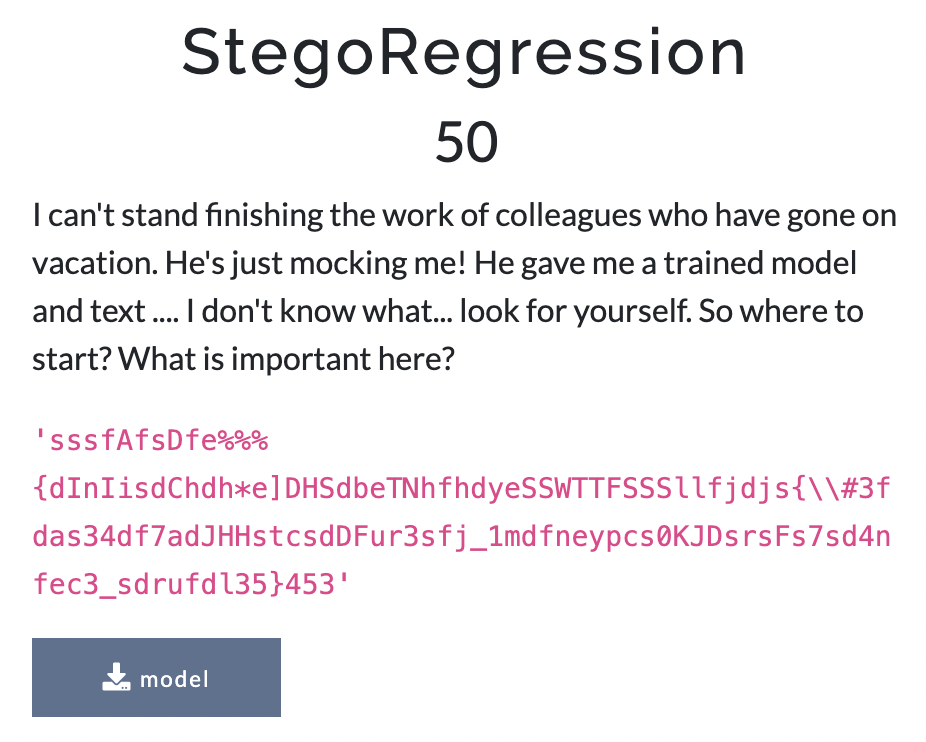
Участникам был дан непонятный текст и файл модели… А категория задания была задана как stego.
Стеганография — способ передачи или хранения информации с учетом сохранения в тайне самого факта такой передачи. Сообщение нешифрованное, но просто где-то тут есть флаг.
Но раз дана модель, то можно ее загрузить и посмотреть, что там лежит.
Конечно, было несложно догадаться (или явно посмотреть), что это был файл, сериализованный с помощью pickle. Далее несложно загрузить в память.
Начав смотреть информацию о модели, можно было бы понять, что это линейная регрессия. В ней столько же коэффициентов, сколько и в сообщении, которое мы выдали.
Какая первая мысль у датасаентиста? Количество входов в модели совпадает с количеством текста, который дали… Но те, кто пытался просто прогнать текст через модель, во-первых, не понимали, как сделать корректно, ведь не дано никакого способа преобразования букв в цифры. А во-вторых, они и не получили бы ничего разумного.
Но если посмотреть на эти самые коэффициенты, которые представляют из себя 0 и 1, и вспомнить, что L1-регуляризация говорит о важных коэффициентах, то можно сопоставить и в итоге получить флаг из наиболее важных символов, которые изначально были даны.

Достаточно было сопоставить текст с 1 и получить флаг.
Это самый решаемый таск, поэтому есть уверенность, что все, кто хотел, справились быстро и на отлично!
NFT_RARITY

Следующим по популярности оказалось задание, связанное с NFT. Никакой крипты под этим всем не было, хотелось просто воспроизвести механику.
Сервис представлял собой арт-галерею уникальных изображений. Участникам для решения необходимо было было загрузить еще одно уникальное изображение, не похожее ни на одно из уже представленных в сервисе, и тогда они получили бы флаг. Внутри был кластеризатор, который говорил, как далеко присланное изображение от уже имеющихся. Так как изображений в сервисе уже было много, то подразумевалось, что прислать уникальное было не так просто…

Мы сознательно оставили в вебе багу, которая давала возможность скачать архив с изображениями, представленными в галерее. Мы беспокоились, чтобы участникам не требовалось много считать и чтобы предоставленный объем данных казался адекватным для кластеризации локально.
Но как обычно бывает, что-то идет не по плану. И по факту большинству участников удавалось загрузить рандомное изображение и получить флаг.
Вот какие интересные изображения нам прислали — и они прошли:

Face_Auth
Задача простая — get the flag авторизоваться. С одной стороны, задача жизненная: вот вы нашли в интернете какой-то сервис аутентификации. Не очень понятно, кто там зарегистрирован и что вы из этого можете получить, но пройти, залогиниться интересно.

Задание было отмечено как web, и обычно опытным участникам CTF становится достаточно очевидным, что нужно его посмотреть, чтобы понять, куда двигаться дальше. Что делают опытные участники? Открывают в браузере инструменты разработчика и смотрят клиентский код.
В клиентском коде можно было заметить закомменченную подсказку — API-метод create_backup.
Пройдя по адресу, получаем исходные данные основных модулей и файл data.pt c векторами, представляющими из себя сохраненные признаки лиц, которые были зарегистрированы в сервисе. В модуле fake_face.py находилась подсказка о том, как генерировать синтетические лица, но без необходимых оптимизаторов.
В модуле ml.py можно было понять, какую нейронную сеть использовали для вычленения лицевых признаков и как хранятся и создаются векторные представления лиц.
Мы использовали Inception Resnet (V1) обученную vggface2 датасете.
Из модуля app.py можно было узнать, как устроена обработка и валидация фотографий. И становится понятным, что для получения флага нужно написать генератор лиц и минимизировать расстояние до референсных векторов, запомненных моделью.
Мы подразумевали, что надо так решать… Но опять же, участники делали по-разному. Кто-то действительно генерировал, а кто-то брал большие датасеты и просто перебирал в ожидании, что какое-то лицо окажется похожим.
Вот с такими лицами участники обходили сервис.

How much?
Изначально участникам дана модель классификации. Нужно загрузить предварительно обученную сеть из вспомогательного файла model_ex.pkl. Этот файл содержит нейронную сеть, которая классифицирует объекты недвижимости по категориям: эконом, бюджет, комфорт.

model = pickle.load(open('model_ex.pkl', 'rb')) pred = model.predict(home) pred array([[0., 0., 1.], [0., 0., 1.], [0., 0., 1.], [0., 0., 1.], [0., 0., 1.], [0., 0., 1.], [0., 0., 1.], [0., 0., 1.], [0., 0., 1.], [0., 0., 1.]], dtype=float32)Нужно получить из нее регрессионный ответ, определить стоимость 10 домов из файла objects.csv.
Участнику нужно было немного подправить модель. Но как?
Если посмотреть структуру модели, то можно было увидеть что-то вроде:
Model: "sequential_3" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= sequential (Sequential) (None, 1) 3093 dense_5 (Dense) (None, 3) 6 ================================================================= Total params: 3,099 Trainable params: 6 Non-trainable params: 3,093Что интересного или необычного?
Здесь видно, что внутри есть необучаемые параметры (Non-trainable params). Что? зачем?
То есть есть какой-то слой, который заморожен.
Чтобы получить регрессионные ответы, достаточно отрезать последний слой:
model_new = Sequential() for layer in model.layers[:-1]: model_new.add(layer) Предсказать стоимость объектов:
pred = model_new.predict(home) pred array([[2024.5602], [2247.2188], [1895.7915], [2074.5354], [1924.3127], [2183.7146], [2042.5957], [1918.0402], [1728.2181], [2904.476 ]], dtype=float32)Далее вычислить целые части значений стоимости домов, вставить их последовательно в уравнения и перенести неизвестные в флаг.
LoveShakespeareTooMuch
Задание было отмечено как crypto. Был расчет на то, что участники догадаются, какой алгоритм шифрования используется и как получать получать ключи из текста после него.
Участникам был дан архив с нужными для решения файлами. Он состоял из:

-
модели нейронной сети для посимвольной генерации текстов (веса + токенайзер);
-
кода для загрузки модели и генерации;
-
Jupyter Notebook для наглядности, как генерировать тексты;
-
файлик .py с функцией преобразования флага в leet кодировку.
Пример текста, который генерировала модель:
S’zo ‘mazue
Sq’rq rqu .u’d rqu .u rqu .u’krp oa zar t’cd rqu iqakmo pakd tadf za rqu x’i t’cd ircmm ou’o
Siazzur hymcc
Srqak scju rqu xcrq rqu ou’d .u’krp iq’fu
Skzoud rqucd rqu f’p rqu mc-u rqu rqczu upui cz rqu ruurqud tdaf maju rqu iq’mm f’ou rqu xcmm fu fp
S’chrt iq’-uigu’du ci zar ou’o
S’zo zar iq’fuo oa rqak iqu oarq iq’fu
S’zo iuu ouhuduo rqu xadrq xcrq ircmm oudhu xqchq rqu xcrq duhucju
S’zo maju ci qci rqu ircmm .uczs .u’krp zux xcrq xqudu rqu majuvi fadu rqp mu’d ra rqu iqax ra hqudu
S’chrt iq’-uigu’du ci zar ou’o
Модель была посимвольная, и потратив некоторое время на изучение, можно было понять, что здесь используется шифр простой замены.
Чтобы решение задания было понятнее, предлагается описание, как мы его готовили. Вот некоторые шаги:
-
Взяли английские тексты со стихами Шекспира.
-
Сделали небольшой препроцессинг: привели к нижнему регистру, почти полностью удалили пунктуацию и лишние разделители и т. д.
-
Между строк стихов в случайные места подмешали текст с флагом.
-
Зашифровали все тексты с помощью шифра простой замены.
-
Выучили на всех текстах символьную языковую модель LSTM (то есть такую модель, которая предсказывала по левому контексту следующий символ из алфавита).
Теперь если ее использовать в авторегрессионном режиме (выход из модели опять подавать на вход, пока не будет предсказан токен конца стиха), то она будет генерировать зашифрованные тексты в стиле Шекспира вперемешку с зашифрованным флагом.
Решение подразумевалось следующее:
1. Запускаем код в Jupyter Notebook, генерируем много текста. Можно заметить, что есть часть, которая много раз повторяется (это и был флаг).
2. Далее по шифртексту требовалось взломать шифр простой замены. На этом сильно останавливаться не будем, отметим лишь факт, что такой шифртекст сохраняет распределение частот n-грамм с точностью до замен букв и по этой информации восстанавливается ключ.
3. Расшифровываем стих, который встречается чаще всего; либо можно было расшифровать все сгенерированные тексты и увидеть часто встречающийся стих.
4. Но флаг был в обычном написании, а в системе принимался флаг в leet-кодировке. Для конверта в leet была заготовлена функция, которую можно было найти в архиве с файлами, выданными в самом начале. Подставляем полученный текст флага в функцию и получаем его в leet-кодировке. Отправляем.
Авторское решение можно изучить тут: gist.github.com/kadetfrolov/b0a977e80333912711d1602603262310
RNN gen
В этом задании участникам был дан зашифрованный файл с флагом с известным заголовком (ogg) и исходный код алгоритма шифрования.
При чем же тут ИИ?
Алгоритм шифрования в данном случае — это генератор псевдослучайной последовательности, основанный на RNN.

Но на самом деле все сильно проще. RNN по сути — это модель, которая использует два матричных умножения, прибавления двух векторов смещений и функции активации (в нашем случае RELU), но в данном задании оба вектора смещения были нулевыми, значения, которые подавались в RNN были неотрицательными, если точнее — бинарные 0 или 1, то есть функция активации не играла роли.
А если посмотреть на веса RNN и код генератора, то можно понять, какой криптографический примитив используется, — это регистр сдвига с линейной обратной связью. Подробнее схема:

-
R1 и R2 — регистры сдвига с линейной обратной связью размера 16 бит каждый
-
x_i и y_i — состояния регистров
-
g_i — бит псевдослучайной последовательности
-
ot_k — байт открытого текста
-
ct_k — байт зашифрованного текста
i и k — это моменты времени, они разные всмысле того, что на каждый байт открытого текста генерируется 8 бит псевдослучайной последовательности(логично).
И сложение (+) на схеме — это сумма по модулю 2, а вычитание (-) по модулю 256 согласно соотношению.
ct_k = (G_k — ot_k) mod 256, где G_k — это 8 бит псевдослучайной последовательности. Такой пример используется для инвалютивного применения алгоритма (шифрование работает так же, как и расшифрование).
Ключевыми параметрами здесь являются начальные заполнения регистров x_0 и y_0.
Если подбирать их грубой силой, то потребуется перебрать (2^32 состояний) * (32 бита для выработки начального отрезка последовательности), то есть итого 2^37. Используя одно ядро и Python, это можно вычислить более чем за два месяца, но конкурс шел всего два дня, так что грубой силой тут перебирать не представлялось возможным.
Алгоритм проектировался специально слабым. Нестойким он был к методу согласования.
Итого, если реализовать его, то трудоемкость снижается до (2^16 + 2^16 состояний) * (32 бита для выработки начального отрезка последовательности), то есть 2^22 — это примерно в 30 000 раз быстрее, чем грубой силой. Также для реализации метода требуется память для хранения 2^16 пар состояний регистра и 32-х битных отрезков последовательности.
Правильно расшифрованный файл должен быть воспроизводимым, и в нем голосом произносится содержание флага.
Для полного разбора метода предлагается код решения gist.github.com/kadetfrolov/57b1bc41d7869aa977c76960c129704d
loast_all_code

Это задание оказалось самым сложным для участников. Его решил только один человек.
Участникам был дан докер-образ, в котором лежал Jupyter Notebook с текстом “# I have lost all my data(.”

Но если посмотреть на формат Jupyter Notebook, который сохраняет не только ячейки, но и историю изменений, то всегда можно заметить рядом хранящуюся базу данных, к которой при некорректной конфигурации сервиса, к которому есть внешний доступ, может получить доступ в целом любой желающий.
Файл .ipython/profile_default/history.sqlite содержал множество всякого кода с GitHub, в который подмешан код с ключом.

Для того чтобы флаг нельзя было найти с помощью метода пристального взгляда, ячейки с кодом флага мы обфусцировали с помощью pyarmor (github.com/dashingsoft/pyarmor).
Вариантов кода с ключом много (1501), но только один в формате leet, что и есть формат флага, который нужно было найти.
Как решать?
У участников была возможность достать всю историю выполнения ячеек Jupyter Notebook. Более 100К примеров.
Далее, когда датасаентист видит много данных, что он делает?
Конечно, кластеризует!
Кластеризовать можно было с помощью, например, tfidf+dbscan, но это не принципиально.

Распределение числа примеров по кластерам такое:

А дальше можно посмотреть, что там внутри каждого кластера, которых было адекватное количество. Например:

А для самого большого и не мусорного кластера содержимое такое:

Все 1501 пример с обфусцированным флагом попадали в один кластер при несложной настройке.
Далее нужно было декодировать pyarmor. И получить такое содержимое ячеек:

Можно было провалидировать ключи по leet или просто глазами увидеть паттерн. И вот флаг найден!
Итоги
Соревнование длилось 28 часов, 18–19 мая.
У нас было 44 участника, которые сдали хотя бы один флаг. Все задания были решены, но никто не решил все.
Участники в этом году проявляли большую сфокусированность на техниках машинного обучения, чем на классических CTF-заданиях, которые были в прошлых годах. И мы правда старались задания сделать еще более близкими к области DS.
Победитель, занявший первое место, решил почти все задания и занял свою позицию еще вечером первого дня, находясь на площадке конференции. Тяжелые условия — интересные доклады и активности вокруг — обычно отвлекают участников, поэтому победа вызывает огромное уважение!
1 место — mr.goose
2 место — someone12469
3 место — anodev
Победителей мы наградили подарками: за I место— Nintendo Switch
За II место — набор Lego
И за III место — квадрокоптер
Традиционно надеемся, что соревнование помогло DS, ML и в конце концов AI специалистам всё больше погружаться в вопросы безопасности, а специалистам по безопасности — знакомиться с миром ИИ.
До новых встреч!
ссылка на оригинал статьи https://habr.com/ru/company/pt/blog/671554/
Добавить комментарий