Раньше Карты, Поиск и Алиса отвечали на запросы об организациях, во многом основываясь на данных от самих организаций. Это был нормальный компромисс, но всегда можно сделать лучше.
Теперь учитываются ещё и реальные отзывы людей. Тем самым запросы, по которым раньше выдача была менее релевантной, обрабатываются качественнее, и мы можем решить больше пользовательских задач. Давайте расскажу, как мы к этому шли, и покажу примеры.
Пара слов о геопоиске
Все запросы про адреса, местоположения объектов и организации в Яндекс Картах, Навигаторе и Поиске обрабатываются специальным внутренним компонентом — геопоиском. Геопоиск основан на базе организаций, которая читателям Хабра лучше всего знакома как Справочник. Владелец организации может указать в своей карточке информацию с помощью «рубрик» и «признаков».
И ещё не так давно поиск по организациям основывался исключительно на текстовом поиске по названию и фильтрации по рубрикам и признакам. Для этого в процессе поиска слова запроса сопоставляются с данными об организациях из Яндекс Бизнеса и обогащаются синонимами. Например, для запроса [кафе] выделяются рубрики «Кафе», «Ресторан», «Кофейня». Дальше геопоиск находит все организации с необходимыми характеристиками в нужной части карты. Чтобы облегчить пользователю задачу выбора, мы показываем ему только несколько десятков лучших организаций.
Чтобы из десятков тысяч отобранных на первой стадии заведений выбрать лучшие, мы используем библиотеку CatBoost. Модель работает на основе нескольких сотен самых разных признаков: рейтинга организации, расстояния до пользователя и так далее. Такой подход хорошо работает на простых запросах вроде [кафе] или [магазин продуктов], при этом большинство пользовательских запросов гораздо сложнее.
Рубрики и признаки — довольно сильное упрощение реального мира. Например, в запросе [уютное кафе] уютное — это признак? Не очень понятно, по какому критерию его нужно ставить. Такой признак очень сложно формализовать, и он будет иметь низкое качество.
К тому же текущие признаки оптимизированы для отображения в карточке организации, а не для поиска. Пользователи в поиске могут интерпретировать рубрику не так, как владелец организации, когда он её ставит. К примеру, популярная сеть закусочных отмечена как ресторан, имеется в виду «ресторан быстрого питания», а пользователь по запросу [ресторан] ожидает увидеть дорогие места с хорошим обслуживанием. В результате по сложным запросам мы можем не находить всех нужных организаций или в некоторых случаях показывать нерелевантные места — пользователю такие ошибки могут показаться глупыми.
Мы никогда не покроем всего многообразия запросов признаками и не сможем вручную поправить всевозможные расхождения. Но это и не нужно: наши пользователи уже описали в отзывах всевозможные аспекты, которые могут быть им интересны.
Мы хотим искать организации по смыслу. В качестве первого шага решили использовать отзывы на финальных стадиях поиска: когда мы выбираем, какие именно заведения из найденных стоит показать пользователю.
Нейросети для поиска организаций
Классический способ использовать неструктурированные тексты в машинном обучении — это нейросети. В Яндексе есть несколько стандартных архитектур, которые очень удобно использовать в поиске. Для начала мы попробовали применить DSSM. Это достаточно старая архитектура, её устройство подробно описано в постах про «Палех» и «Королёв».
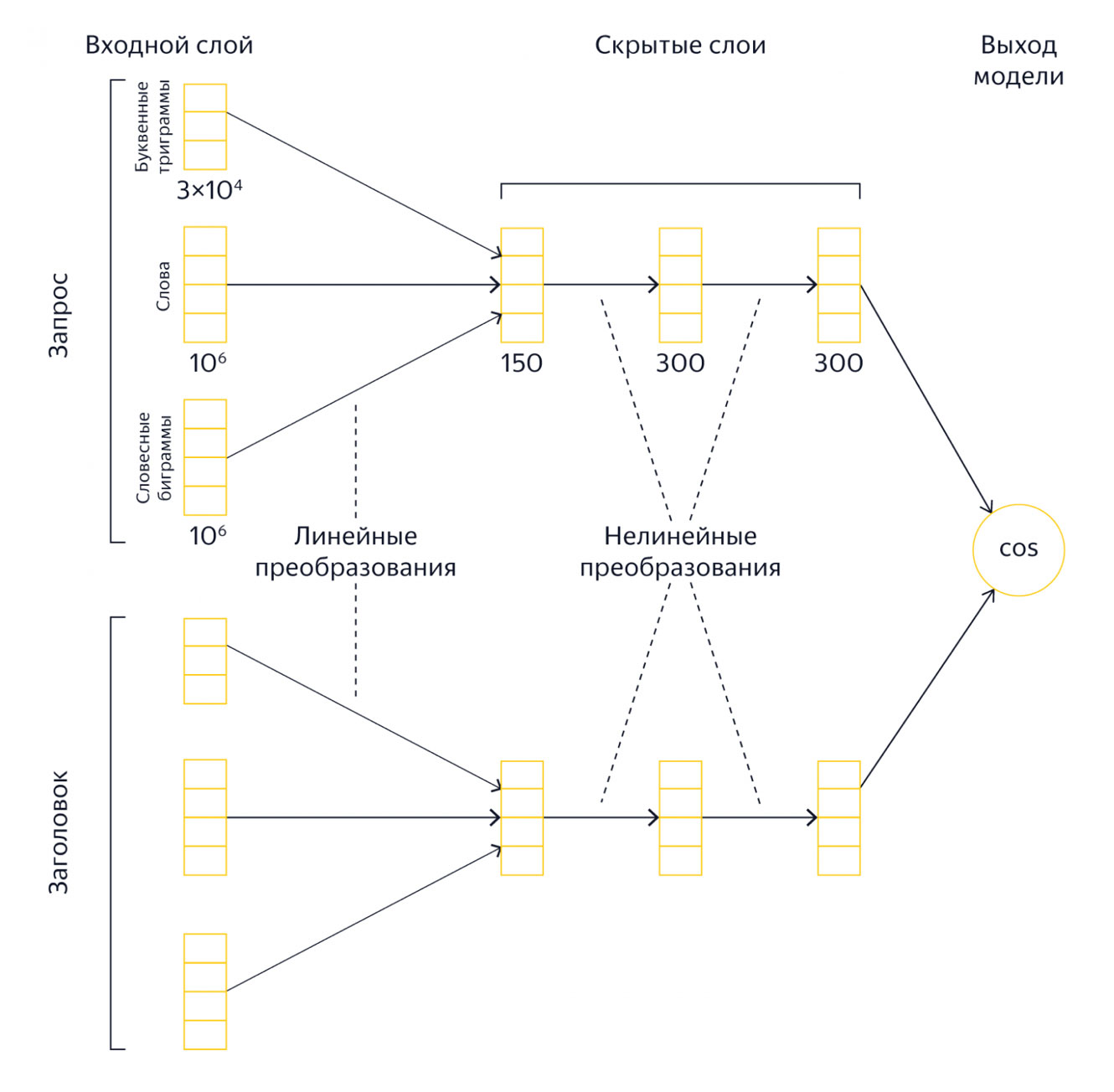
Если коротко, DSSM — сиамская сеть, в которой есть две независимые «башни»: одна, как правило, используется для представления запроса, другая — для представления документа. На вход башням подается «мешок слов», состоящий из слов запроса, словесных биграмм и буквенных триграмм. На выходе каждой башни получается слой эмбеддингов. Косинус вектора-эмбеддинга запроса и вектора-эмбеддинга документа — это и есть выход сети. По сравнению с современными большими нейросетями DSSM — более простая модель, её всё ещё можно применять на CPU за адекватное время, к тому же учить её гораздо быстрее, чем трансформеры. Именно поэтому мы начали с DSSM.
Какой же датасет подать на вход, чтобы сеть научилась «искать» по отзывам? Для обучения сетей настолько большого размера нужны миллионы примеров. В качестве источника данных такого объёма часто используют клики: в нашем случае мы могли бы по всем показам выдачи геопоиска пользователям собирать пары запрос-организация там, где пользователь кликнул на эту организацию. Но кликовый датасет обладает очевидным недостатком: данные в нём очень сильно смещены в наше текущее ранжирование. Если мы сейчас не очень хорошо умеем отвечать на запрос [уютное кафе], то способность предсказывать клики здесь не поможет.

Поэтому вместо кликов мы решили начать с редакторских подборок мест, размещённых в Яндекс Картах. Чтобы подготовить данные для обучения, мы сопоставили организации из подборок с запросами пользователей в веб-поиске Яндекса, по которым эта подборка показывалась хотя бы несколько раз. При этом в качестве данных про организацию использовали топ отзывов.
К сожалению, таким методом у нас получилось сгенерировать лишь несколько сотен тысяч обучающих примеров. Для качественного обучения DSSM этого недостаточно, архитектура требует на несколько порядков больше данных на входе.
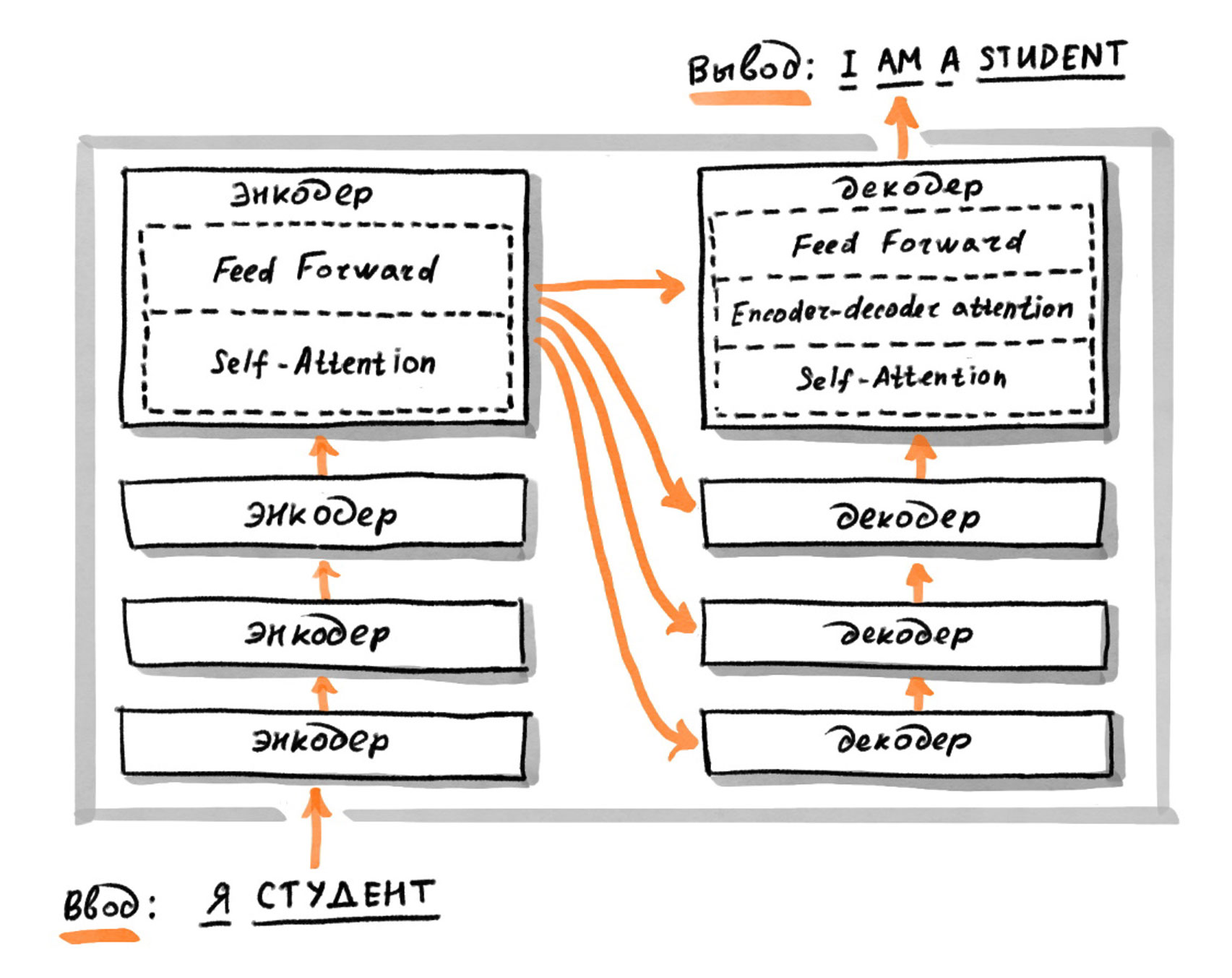
Тогда мы решили попробовать другой подход. В веб-поиске активно используются трансформеры на основе YATI, вот хабрапост про эту технологию. Для дообучения модели YATI достаточно всего нескольких тысяч примеров, это позволило бы нам обойти лимиты на обучение DSSM.
Мы взяли Large BERT, который был обучен по запросам пользователя в веб-поиск предсказывать, выбрал бы он этот документ в выдаче или нет. Такая модель уже достаточно хорошо умеет понимать тексты запросов. К тому же за счёт особенностей архитектуры она неплохо умеет работать с неизвестными словами. Это важное свойство модели, потому что в геозапросах пользователи часто используют названия населённых пунктов, мало встречающиеся в обычных текстах, к примеру, [почта в Урюпинске].
На нашем датасете подборок организаций мы дообучили Large BERT определять, входит ли организация в подборку по данному запросу. Для обучения к такой задаче нам нужны не только настоящие примеры из подборок («позитивы»), но и достаточно много примеров организаций, которые не входят в подборку («негативы»). При этом недостаточно взять в качестве негативов случайные организации, иначе сеть не сможет выучить тонкие различия между запросами.
Мы попробовали несколько вариантов генерации примеров организаций, не входящих в подборку. Например, брали близкие организации в той же рубрике или просто случайные организации в том же регионе. В результате каждый раз у нас неплохо получалось обучить сеть. На части пула, которую она не видела в обучении, мы оценили precision — долю верно классифицированных позитивных примеров из всех, и recall — долю верно найденных позитивных примеров среди всех позитивных примеров. Для обеих метрик значения получились более 95%, что достаточно хорошо.
Как понять, будет ли такой BERT помогать ранжированию? Для оценки качества поиска по смыслу мы скачиваем поисковую выдачу по определённому набору запросов и просим экспертов оценить, является ли каждая организация в выдаче релевантной данному запросу. То есть — помогает ли она пользователю решить свою задачу. Мы добавили BERT в качестве признака в ранжирующий CatBoost геопоиска. К сожалению, ни один вариант BERT в качестве фичи не показывал существенных улучшений релевантности нашей выдачи. Кажется, предсказание подборок — это всё-таки неподходящая задача, надо было использовать какие-то другие данные.

Тогда мы попробовали дообучить тот же Large BERT отличать релевантные документы от нерелевантных прямо по нашей экспертной разметке. На этот раз датасет получился совсем небольшой, у нас были опасения, что его не хватит для обучения такой модели. Но мы решили попробовать.
Чтобы не попасть в режим переобучения и сохранить способность наших офлайн-метрик качественно оценивать выдачу, для обучения сети мы брали оценки на «отложенном» множестве запросов — тех, которые не участвовали в оценке качества. Обучив BERT, мы снова оценили его в качестве фичи CatBoost’а. И на этот раз получилось хорошо! Фича с предсказанием BERT входила в топ-5 по feature importance и статистически значимо улучшала loss.
Но нельзя просто взять и внедрить трансформер в рантайм. На CPU такая модель будет применяться слишком долго. Запрос в поиск с включённым подсчётом фичи для лучших найденных документов стал обрабатываться за несколько минут! И даже на GPU применение модели такого размера очень сильно увеличило бы время ответа поиска. К тому же нам хотелось бы перенести как можно больше тяжёлых вычислений на этап подготовки данных. Этого можно достичь с помощью DSSM, предпосчитав удобное для сети представление организаций, а в рантайме обчитывать только запросы. Поэтому мы приступили к дистилляции BERT в DSSM.
Дистилляция — процесс, позволяющий получить более простую модель, которая решает задачу практически с тем же качеством, что и тяжёлая. Для этого на гигантском пуле простую модель-«пародию» обучают предсказывать результаты работы тяжёлой модели. Мы собрали все наши выдачи по всем запросам из логов за год, для каждой пары (запрос — организация) посчитали скор BERT’а — его оценку, насколько организация релевантна запросу. У нас получилось около 300 миллионов примеров в обучающем пуле. Мы подали на вход DSSM ровно те же данные, что использовались трансформером: запрос и топ отзывов про организацию, а в качестве таргета — скор Large BERT с предыдущего шага.
Модель-пародия оказывалась в топе по feature importance основного ранжирующего CatBoost’а, но loss уже не улучшался.
Небольшие изменения loss очень трудно интерпретировать, поэтому мы начали сравнивать вердикты BERT и DSSM на проблемных выдачах. Оказалось, что небольшое количество запросов типа [где поесть] и [кафе] занимают в обучающем пуле огромную долю. При этом на таких запросах наше ранжирование прекрасно справляется и без использования отзывов. А вот более сложных и проблемных запросов в пуле оказывалось гораздо меньше.
Мы подправили пул, устранив перекос в частотные запросы. В результате дистиллированный DSSM стал улучшать loss ранжирующей формулы.
При этом поначалу модель не оказывала существенного влияния на порядок в выдаче. Причина была в том, что для обучения нашего ранжирующего CatBoost’а используется комбинация сигналов разной степени сложности и чистоты. В итоге отзывы неплохо помогали на начальном этапе, но добиться большого улучшения было сложно. Тогда мы обратили внимание, что DSSM можно использовать и более просто — для фильтрации нерелевантных результатов из выдачи. С этим модель справлялась достаточно хорошо — ведь ровно на такой задаче дообучался исходный Large BERT. И вот в этой конфигурации наконец-то получилось увидеть улучшение в эксперименте и выкатить модель в продакшен.
Ниже пара примеров применения модели.
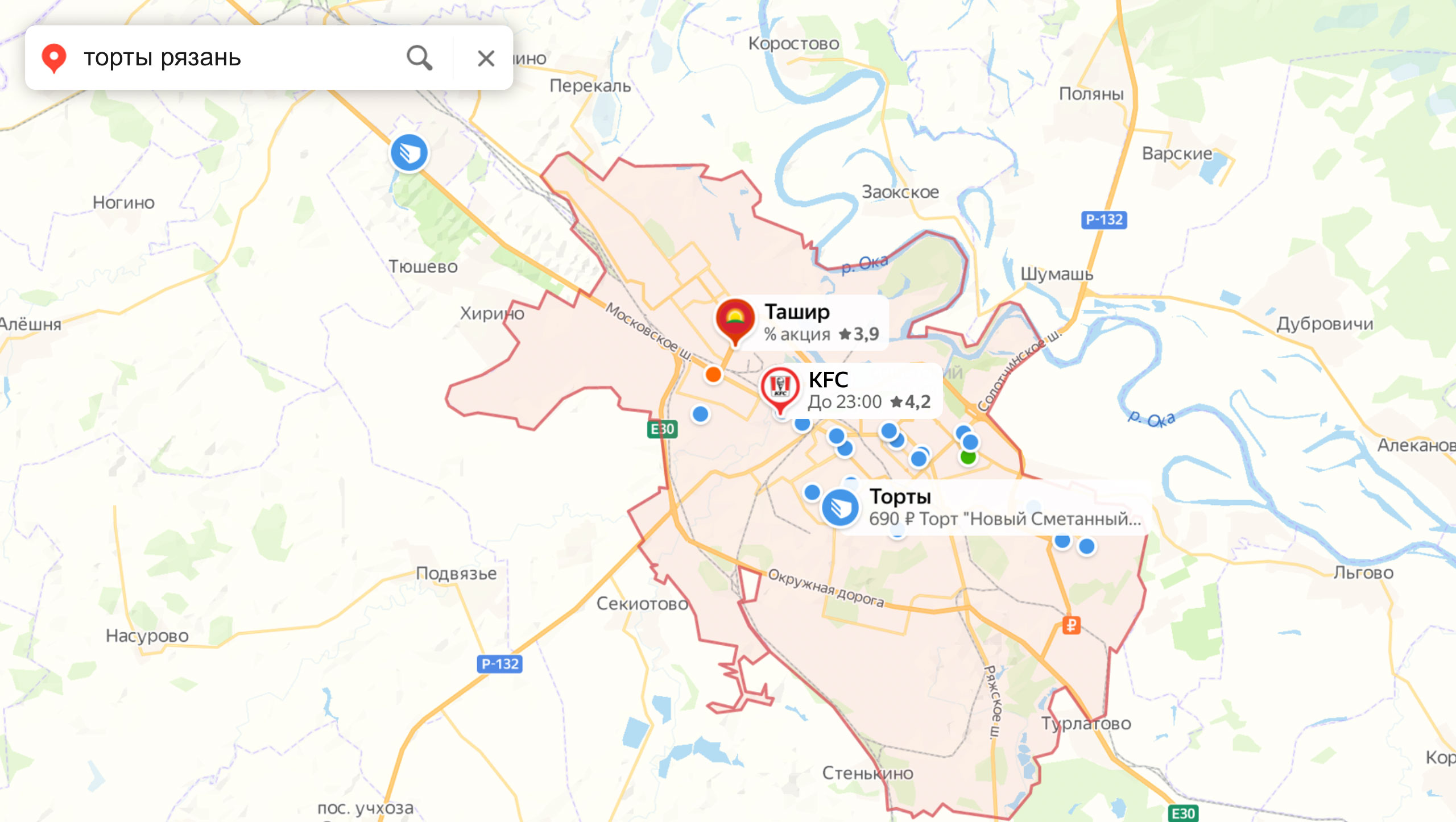
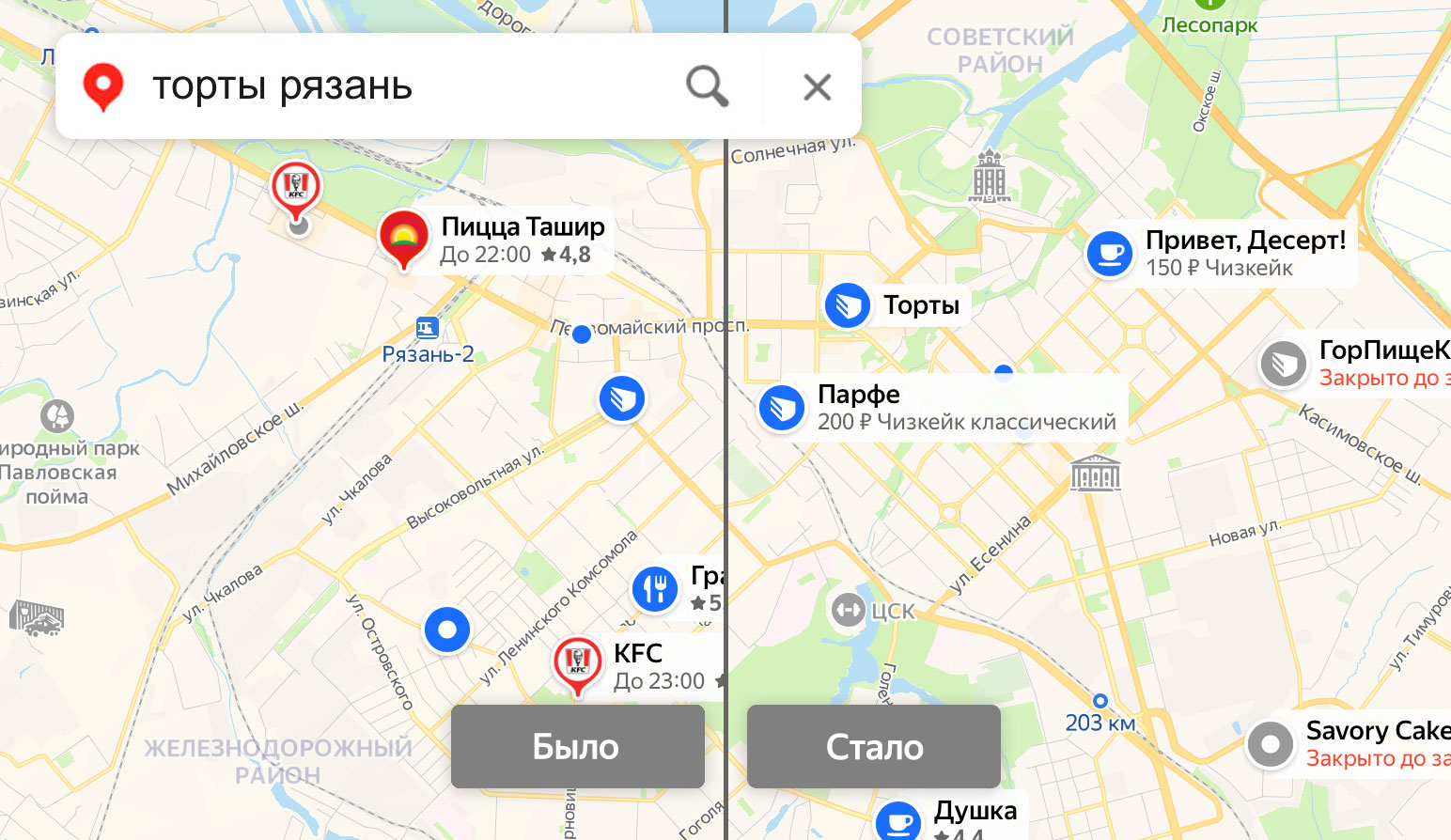
Скажем, раньше по запросу [торты Рязань] мы показывали сеть пиццерий «Ташир» и KFC. С помощью новой модели на базе отзывов нам удалось убрать нерелевантные результаты:


По запросу [кальянные в СПб] среди наших результатов был суши-бар «Токио Сити», а после внедрения модели в выдаче остались только кальян-бары.
Что в итоге?
У нас получилась модель, которая улучшает ранжирование геопоиска на основании отзывов пользователей Яндекс Карт. В дополнение к упрощённой модели признаков, проставляемых вручную владельцами или редакторами, мы можем использовать всё многообразие свойств организаций, добывая нужную нам информацию из текстов отзывов.
Мы попробовали множество разных вариантов обучения и применения модели. Изначально мы опасались, что небольшого количества экспертной разметки будет недостаточно для обучения, поэтому пробовали учить модели на данных из подборок организаций. К тому же нам хотелось получить более простую архитектуру, которую можно применять в рантайме. Но в итоге с помощью YATI и дистилляции в DSSM мы пришли к предсказанию экспертной разметки.
Текущая отзывная нейросеть, конечно, не идеальна. Например, из-за ограничений по длине текста обрабатывается только часть отзывов — а ведь про вкусный фалафель могут писать и не в самом первом из них. У нас на подходе новые модели, которые способны учитывать больше отзывов в Картах, а также включают в себя другие сигналы, полезные при определении релевантности документа. Важный итог: по офлайн-замерам релевантности дистиллированная модель на отзывах в одиночку дала такое же улучшение качества поиска, как все внедрения нашей команды за предыдущий квартал.
ссылка на оригинал статьи https://habr.com/ru/company/yandex/blog/671504/
Добавить комментарий