
Можно ли ускорить обученную сверточную нейросеть? Можно ли заметно сократить ее веса, не снижая точности? Можно ли найти и «обезвредить» узкие места в модели, препятствующие достижению максимальной точности? Можно ли радикально изменить архитектуру готовой сетки, не прибегая к обучению с нуля?
А вот и посмотрим.
Сначала о производительности
Сверточные нейросети хороши всем, кроме объема вычислений. Можно представить такую сеть как стопку изображений со все меньшим числом пикселей, где значением одного пикселя самого верхнего слоя является тройка цветов RGB, преобразуемая от слоя к слою в вектор т.н. признаков все большей размерности. В конце остается самая маленькая матрица из самых длинных векторов. Которые чаще всего поэлементно усредняются к единственному выходному вектору, и затем уже следует одно-двухслойный перцептрон классификатора.

Чтобы получить значение одного выхода в одном пикселе слоя нужно скомбинировать вектора признаков всех соседних пикселей предыдущего слоя. Это десятки, сотни, а иногда и тысячи умножений и сложений. Учитываем количество выходов в пикселе, количество пикселей в слое, количество слоев, — и легко получаем по 100-200 миллионов операций даже на самых компактных моделях со скромными 2М весов (солидные содержат в 10-30 раз больше).
Предлагались разные варианты борьбы с этой проблемой, в том числе групповая свертка. Можно разбить признаки (каналы) слоя на несколько групп небольшой размерности, и провести автономную свертку внутри каждой группы, а затем как-нибудь скомбинировать или просто перемешать каналы между группами. (Так устроена, например, ShuffleNet). Но более успешной оказалась архитектура с группами размером в один единственный канал (т.н. depthwise separable convolution).
Одним из типичных представителей этого многочисленного семейства моделей является вариация MobileNet v3 от Google, состоящая из весьма однотипных строительных блоков. Не вдаваясь в детали, каждый блок можно упрощенно представить в виде набора следующих слоев:
1) слой расширения, увеличивающий входные каналы одного пикселя в несколько раз;
2) слой одноканальной свертки 3×3 или 5×5, передающий информацию между соседними пикселями раздельно для каждого из возросшего числа признаков;
3) слой сжатия, обратно уменьшающий каналы внутри пикселя до разумного минимума.
Как следует из названия, эта модель призвана обеспечить приемлемый баланс между точностью и объемом расчетов в средах с умеренными вычислительными возможностями. Но даже здесь, если присмотреться, основная нагрузка приходится на первый и последний слои блока (которые реализуются в виде свертки с ядром 1×1, т.е. простого перцептрона, миксирующего заданное число входов в необходимое количество выходов). Можно ли еще здесь как-нибудь сэкономить?
Осторожный оптимизм внушает такое свойство нейросетей как избыточность. Можно наугад обнулить десятки, сотни, или даже тысячи весов сколько-нибудь сложной сетки, и ничего заметного не произойдет. Так устроен один из эффективных методов повысить точность при обучении, — прореживание (dropout). Случайным образом временно отключаются 10-30% входов слоя, т.е. локально купируется избыточность, и точность предсказания ощутимо повышается, т.к. слой вынужден искать приемлемые варианты даже в условиях дефицита входящей информации.
Выборочное прореживание
Рассмотрим самый базовый перцептрон с несколькими входами и всего одним выходом. Когда требуется больше выходов, такие элементарные конструкции просто объединяются в стек. Функция активации нас не интересует, — часто она выделяется в отдельный слой, следующий после пакетной нормализации (BatсhNorm) выходов свертки.

C целью оптимизации можно попробовать отказаться от нескольких входов, которые имеют самое незначительное влияние на результат, т.е. с самыми маленькими по модулю весами  . Веса в слое могут отличаться на 2-3 порядка, — есть из чего выбрать. В терминах свертки это эквивалентно умножению входящего плотного тензора значений на разреженную матрицу весов.
. Веса в слое могут отличаться на 2-3 порядка, — есть из чего выбрать. В терминах свертки это эквивалентно умножению входящего плотного тензора значений на разреженную матрицу весов.
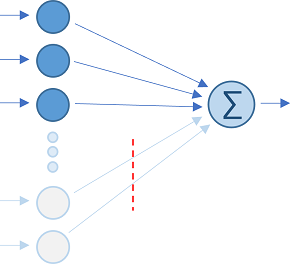
Итак, мы можем произвести осмысленное стационарное прореживание, связывающее с каждым выходом свой персональный набор входов, руководствуясь масштабом предварительно обученных весов. Есть еще варианты?
Пожалуй да. Вместо выставления за дверь неугодного канала, можно попробовать заменить его на константу, — матожидание данного входа. Произведение  пополнит смещение
пополнит смещение  а дальше мы получаем предыдущий вариант. Мы уже не просто отбросили вход, но сохранили часть информации о нем в выходе.
а дальше мы получаем предыдущий вариант. Мы уже не просто отбросили вход, но сохранили часть информации о нем в выходе.
Не останавливаемся на достигнутом! Пусть  , где
, где  — центрированная величина с единичным отклонением. Тогда вклад одного канала в
— центрированная величина с единичным отклонением. Тогда вклад одного канала в  можно записать как
можно записать как  Т.е., оставляя только матожидание входа, мы выбрасываем осцилляцию
Т.е., оставляя только матожидание входа, мы выбрасываем осцилляцию  что вносит среднюю ошибку порядка
что вносит среднюю ошибку порядка 
Очевидно, для минимизации такой ошибки мы должны выбрать кандидатов на удаление с самыми скромными  а не просто
а не просто 
Межканальная корреляция
Посмотрим, что будет, если не выбрасывать , а заменить на единичную осцилляцию другого канала. Если они заметно коррелируют, то результат может оказаться интересным. Как известно, дисперсия суммы
, а заменить на единичную осцилляцию другого канала. Если они заметно коррелируют, то результат может оказаться интересным. Как известно, дисперсия суммы

Если принять  то
то

где  — линейный коэффициент корреляции между исходными каналами
— линейный коэффициент корреляции между исходными каналами  и
и  Это парабола с минимумом при
Это парабола с минимумом при  Т.е. подстановка должна быть
Т.е. подстановка должна быть 
Тогда среднеквадратичное отклонение довеска  составит
составит

Т.к.

то очевидно, при замене теряется член  который имеет оценку
который имеет оценку

При этом меняется не только bias, но и вес канала-«спонсора»:

Стратегия выбора входов-аутсайдеров тоже меняется: подбираем каналы с минимальной 
Полная аппроксимация
Попробуем выразить суммарную осцилляцию второстепенных входов (хвост) через композицию остающихся основных каналов (ядро).
Условимся обозначать переменные ядра индексами i и j, а переменные хвоста – индексом k. Т.е.,

Представим

Наша цель, — подобрать  так, чтобы погрешность
так, чтобы погрешность была минимальной. Воспользуемся формулой
была минимальной. Воспользуемся формулой

Тогда, обозначив  получим
получим

Первые две пары слагаемых во второй строке — это дисперсии хвоста и его аппроксимации, а последняя сумма – ковариация между ними. Относительно каждого  снова имеем параболу с минимумом при
снова имеем параболу с минимумом при

(Здесь учтено, что слагаемые  в силу симметричности повторяются дважды). Т.е. мы получаем систему уравнений
в силу симметричности повторяются дважды). Т.е. мы получаем систему уравнений

Вычислим вектор коэффициентов аппроксимации  , где
, где  – обращенная матрица корреляции ядра, а
– обращенная матрица корреляции ядра, а  – прямоугольная матрица корреляций между ядром и хвостом с элементами
– прямоугольная матрица корреляций между ядром и хвостом с элементами  .
.
Итак, если ошибка приближения  достаточно мала, то
достаточно мала, то

Чтобы перейти к цивилизованной векторной записи, обозначим как  векторы значений, матожиданий и весов ядра,
векторы значений, матожиданий и весов ядра,  – вектор матожиданий хвоста. Затем вычислим вектор поправки
– вектор матожиданий хвоста. Затем вычислим вектор поправки

Тогда y легко записать через скалярные произведения

Или  , где
, где  , и
, и  .
.
Выбор каналов ядра и хвоста
Итак, зная матожидание, стандартные отклонения и коэффициенты корреляции входных каналов, можно вместо вычисления хвоста в каждом пикселе слоя заранее аппроксимировать хвост с помощью ядра. Достаточно лишь вычислить вектор поправки для модификации весов и смещения, и забыть о лишних каналах как о дурном сне.
К сожалению, «забыть» получится только в одном выходном канале. Разные выходы пиксела по-разному комбинируют одни и те же входы, поэтому входной канал в одном наборе выходов будет считаться хвостом, а в другом – ядром. Поэтому разделять каналы на ядро и хвост придется индивидуально для каждого выхода.
Очевидно, выбирать хвост нужно так, чтобы дисперсия ошибки аппроксимации была минимальной. Фактически, при вычислении вектора  из уравнения
из уравнения  ,
,

Как и положено корреляционным матрицам,  неотрицательно определенные, — не могут же дисперсии быть отрицательными (да и нулевыми – ну очень маловероятно).
неотрицательно определенные, — не могут же дисперсии быть отрицательными (да и нулевыми – ну очень маловероятно).
Чтобы не связываться с обращением очередного варианта матрицы  на каждом шаге поиска, можно для начала уменьшить дисперсию хвоста
на каждом шаге поиска, можно для начала уменьшить дисперсию хвоста  .
.
Эта задача сродни поиску подматрицы с минимальной площадью, правда речь не о непрерывных подмассивах, а о подпоследовательностях с произвольным набором индексов, — тоже удовольствие не из приятных.
На практике неплохо работает следующий алгоритм:
-
Начинаем с поиска минимального элемента
 это будет начальный хвост.
это будет начальный хвост. -
Добавляем к хвосту еще один канал ядра с минимальным увеличением
 . Для экономии расчетов храним промежуточные суммы элементов, чтобы вычислять только изменения
. Для экономии расчетов храним промежуточные суммы элементов, чтобы вычислять только изменения  при модификации ядра и хвоста.
при модификации ядра и хвоста. -
Далее в цикле стараемся улучшить результат, пробуя поочередно заменить каждый из каналов хвоста на свободные каналы ядра, сравнивая их потенциальные вклады в дисперсию.
-
Если уменьшить
 не получается, добавляем к хвосту еще один канал ядра с минимальным увеличением итоговой суммы.
не получается, добавляем к хвосту еще один канал ядра с минимальным увеличением итоговой суммы. -
Повторяем итерации, пока ошибка не приблизится к заданной границе (напр. определенный процент от общей дисперсии выхода).
-
Рассчитываем коэффициенты аппроксимации и вектор поправки.
Результат будет неидеальным, но довольно приличным. Более рационально, конечно, добавить в поиск расчет  напрямую учитывающий остальные корреляции. Разложение Холецкого нам в помощь, — для экономии времени стоит использовать один вариант ядра для опробования сразу серии правых частей.
напрямую учитывающий остальные корреляции. Разложение Холецкого нам в помощь, — для экономии времени стоит использовать один вариант ядра для опробования сразу серии правых частей.
Послойный коллапс модели
Как это все может выглядеть в практическом плане:
-
Берем готовую натренированную модель. Скорее всего это будет одна из предобученных стандартных моделей, которую мы довели до ума на своих данных.
-
Выбираем первый слой для аппроксимации, предварительно пропустив пару-тройку начальных блоков (которые также не рекомендуется и тренировать при трансфертном обучении)
-
Строим вспомогательную модель для расчета матожиданий, сигм и матрицы корреляций, — заменяем выбранный слой и все последующие на слой подсчета статистики.
-
Прогоняем обучающий набор изображений через вспомогательную модель. Если используется предобработка данных, то стоит усреднить параметры по нескольким эпохам (матожидания и сигмы более чувствительны к таким вещам, чем коэффициенты корреляции).
-
По полученным данным строим ядра, хвосты и вектора поправки. Модифицируем веса и bias слоя, веса хвостов обнуляем.
-
Запрещаем дальнейшее обучение весов подвергшегося коллапсу слоя. В них уже и так заложена масса дополнительной информации, позволяющая существенно сократить фактическую размерность свертки.
-
Проводим дообучение низлежащих слоев для адаптации модели к последствиям коллапса.
-
Поочередно повторяем экзекуцию с оставшимися слоями.
Скорость расчетов
Универсальные пакеты-монстры типа TensorFlow не предназначены для рекордов быстродействия, но обеспечивают более чем достаточный уровень производительности (если ваша производственная среда лопается от тензорных ядер и гигабайт быстрой видеопамяти).
Однако в реальной жизни зачастую приходится умерять аппетиты самым драматичным образом. Что ж, об этом и статья. Если вам настолько не повезло, что доступны только скалярные операции, и никаких векторных SIMD-излишеств, то вы безусловно получите пропорциональную пользу от нативной реализации произведения тензора значений на разреженную в пределах 50-70% матрицу весов.
С векторными расширениями типа AVX2 придется немного повозиться. Обычно выгоднее размещать в векторном сумматоре вычисляемый подвектор выходных признаков пикселя (что соответствует формату тензоров NHWC). Но в нашем случае нужно произвольно комбинировать данные из разных входных каналов. Операция собирания регистра из разных мест памяти очень медленная. Намного эффективнее читать данные плотными векторами.
Поэтому лучше перейти к формату NCHW с поканальным размещением данных. Тогда сумматор (как и регистры операндов) будет содержать соседние точки одного и того же канала.
Самое выгодное, если удастся объединить выходные каналы в небольшие группы с более-менее одинаковым набором каналов ядра. Тогда разместив в регистрах все сумматоры группы, можно в разы сократить повторное чтение входных данных, — один загруженный входной вектор будет участвовать в изменении сразу всех выходов группы.
В любом случае, даже не прибегая к рассматриваемой здесь оптимизации, грамотная нативная реализация стандартной модели, например, на «офисном» C# с помощью указателей, Intrinsics, и продуманной буферизации даст вам как минимум двух-трех кратное ускорение на CPU с AVX2 (точнее, FMA3) относительно сборки TensorFlow под ту же архитектуру.
Спектральное прореживание
Первое, что вы заметите, если действительно попробуете аппроксимировать по описанному алгоритму свою излюбленную модель, — что при подборе порога аппроксимации (и тем самым, процента сокращенных весов) разные слои будут вести себя по-разному. Одни могут позволить себе сокращение аж до 70%, и при этом умудрятся даже немного повысить точность модели. Другие будут «упираться до последнего». (В среднем 40-50% бонус очень даже возможен!)
Очевидно, — с помощью прореживания аппроксимацией мы получаем механизм выявления узких и избыточных мест модели. И то и другое одинаково негативно влияет на точность предсказания. Узкие места – это к архитекторам, а вот избыточность, — можно ли ее уменьшить напрямую, не затевая весь этот балаган с арифметическим приближением?
Так вот же она, — наша прелесть, — матрица корреляции каналов, «сфотографированная» между соседними слоями. Методом главных компонент легко оценить «выхлоп» предыдущего слоя на предмет действительно независимой информации.
Итак, поехали! Вычисляем матрицу ковариации  на стыке между блоками, нормировать ее до матрицы корреляции не нужно. Она симметричная и неотрицательно определенная. Делаем спектральное разложение
на стыке между блоками, нормировать ее до матрицы корреляции не нужно. Она симметричная и неотрицательно определенная. Делаем спектральное разложение

Изучаем отсортированный по убыванию спектр неотрицательных собственных значений. Многочисленная мелочь в конце рейтинга, — явный признак избыточности. По сути, просто препятствующий выделению важных признаков спектральный шум. И напротив, если большинство  существенно, скорее всего перед нами бутылочное горлышко.
существенно, скорее всего перед нами бутылочное горлышко.
Решаем, какой долей общей дисперсии  (т.е. суммы собственных значений) хотим пожертвовать (процента 3 для начала будет в самый раз). Отбраковываем
(т.е. суммы собственных значений) хотим пожертвовать (процента 3 для начала будет в самый раз). Отбраковываем  в конце списка. Отбрасываем соответствующие им столбцы (собственные вектора) в матрице
в конце списка. Отбрасываем соответствующие им столбцы (собственные вектора) в матрице  и получаем прямоугольную матрицу прореживания
и получаем прямоугольную матрицу прореживания  .
.
Тогда можно вставить до или после свертки слой  и посмотреть на результат, предварительно адаптировав последующую часть модели. (Чтобы не искажались матожидания, можно добавить смещение
и посмотреть на результат, предварительно адаптировав последующую часть модели. (Чтобы не искажались матожидания, можно добавить смещение  .) Слой спектрального прореживания готов.
.) Слой спектрального прореживания готов.
Фактически, он включает в себя понижение размерности данных. Чтобы этим воспользоваться и для улучшения производительности, можно попробовать уменьшить размерность стыка между блоками, раздельно перемножив  и
и  на матрицы весов предыдущего и следующего сверточных слоев.
на матрицы весов предыдущего и следующего сверточных слоев.
К сожалению, это не всегда возможно. Если предыдущий блок заканчивается функцией активации или слоем суммирования, можно только модифицировать веса в начальной свертке следующего блока  (Только не стоит забывать, что веса в TensorFlow и других пакетах обычно хранятся транспонированными).
(Только не стоит забывать, что веса в TensorFlow и других пакетах обычно хранятся транспонированными).
Небольшие дополнительные хлопоты потребуются, если предыдущий блок заканчивается на BatchNorm. В этом случае от него надо просто избавиться, модифицировав bias предыдущей свертки, и умножив столбцы ее матрицы весов на соответствующие масштабирующие множители.
Не стоит ждать от спектрального прореживания крупного ускорения расчетов, а вот на предмет точности стоит и поэкспериментировать. Обычно Dropout и BacthNorm плохо уживаются друг с другом, — случайное отключение входов при классическом прореживании это гарантированные скачки стандартного отклонения и матожидания на выходе свертки. Их последующая нормировка по пакетам только добавит хаоса.
При спектральном коллапсе у нас этой проблемы уже не будет, т.к. прореживание стационарно и разнесено с обучением во времени.
Имитация
Хватит полумер, пришло время эпической прорывной медитации на дао избыточности.
Смотрим на последний слой блока, отвечающий за уменьшение каналов в 2-6 раз. Смотрим на спектр матрицы корреляции или ковариации. Смотрим, сколько мусора можно вычистить из матриц весов с помощью аппроксимации, — как на входе блока, так и на выходе. Смотрим и думаем.
А вот бы уменьшить не индивидуальные веса внутри слоя, но масштаб расширения числа каналов в середине блока? Это бы гарантированно убавило число весов и объем расчетов, без всяких архитектурных ухищрений с разреженными матрицами.
Ой, это же топорное вмешательство в отличную структуру модели, оптимизированную, между прочим, на огромных датасетах. Уменьшить размерность блока легко, но результат будет закономерно плачевным. Расплачиваться придется падением точности предсказания при последующем неизбежном обучении как нового блока, так и всех тех, что «ниже по течению».
Стоп. Почему неизбежном? А давайте локально аппроксимируем уже имеющийся обученный блок сверточных слоев другим блоком, только попроще! Имитируем функцию исходного блока с помощью нейросетевой регрессии, и затем подсунем для адаптации остальных слоев модели готовый облегченный муляж.
Сначала построим модель для имитации: оставляем предыдущие блоки как есть, затем в параллель ставим блок-прототип и блок меньшей размерности для приближения соседа, получающие на вход одинаковые данные. Затем вычисляем разность значений выходных каналов-побратимов. В идеале разница должна быть нулем. Добавляем предпочитаемую функцию потерь, — MSE, MAE или Huber, и проводим обучение на исходных данных, никак не затрагивая модель-прототип. Тренируются только веса в муляжике! Бинго!
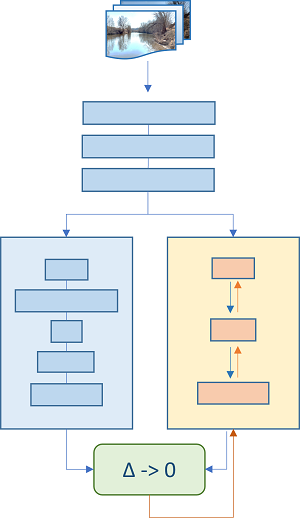
Итак, мы подменили исходный сложный блок упрощенной имитацией. Т.е. аппроксимировали его передаточную функцию другой нейросетью, — чем собственно нейросети и славятся. (Вероятно, инженеры назвали бы такой трюк суррогатным моделированием.)
У наших блоков совершенно разные задачи на момент их обучения: оригинал пыхтит над выделением признаков и получает через back propagation градиентные пинки от низлежащих «товарищей» за откровенную лажу в классификации. Имитатору на эти муки наплевать, — он только притворяется готовым результатом длительных мучений прототипа. На все готовенькое, так сказать. Пусть неидеально, пусть и с погрешностью эмулируя оригинал, но несравненно лучше такого же блока, обученного в каноническом deep learning. Который о выстраданных возможностях продвинутого прототипа – ни сном, ни духом.
Ну а дальше, понятное дело, снова каскадный коллапс, но уже не послойный, а поблочный: имитировали очередной блок, дали модели привыкнуть к изменениям, дообучив последующие слои, затем приступаем к следующему блоку. И никто не мешает сначала «подсушить» избыточный блок спектральным прореживанием или аппроксимацией, а затем уже его имитировать.
В итоге наша модель «схлапывается» не хуже нейтронной звезды, — коллапсирующие слои ужимаются, поглощают массу ценной вспомогательной информации, но расплачиваются за это необратимым отказом от дальнейшего обучения. Так что исходный прототип ни в коем случае не выбрасываем!
А вот если мы хотим не только упрощать, но и поблочно усложнять модель в «узком» месте, то «необратимого отказа от дальнейшего обучения» не потребуется. Напротив, предварительно обучив более «упитанный» блок на прототипе, и затем разрешив тренировку его весов, мы получим отличное приближение для быстрого дообучения модифицированной модели уже традиционным способом.
Вообще говоря, имитация допускает самые разные схемы обучения. Например, на каждом этапе можно сравнивать суррогат только с оригиналом, не беря в качестве прототипа следующий блок после коллапса. Это будет экивалентно пошаговому удлинению ветвей исходной модели и имитации в приведенной выше схеме. Можно переключаться между прототипом после коллапса и исходной моделью в зависимости от того, какой вариант точнее. Можно варьировать на разных этапах число обучаемых слоев в правой цепочке, и т.д., и т.п.
О чем все это было
Заходим на посадку. Пока вокруг на все лады склоняют «deep learning, deep learning», мы с вами попробовали сосредоточиться на «simple prediction», рассмотрев аппроксимацию, спектральное прореживание и имитацию. На первый взгляд это выглядит чем-то осмысленным, — разделить модель для обучения и модель для предсказания. Несомненно, у них разные задачи, но почему бы тогда и не разная архитектура? Построить вторую из первой можно описанными выше методами.
Причем архитектура может быть действительно разной, — вплоть до квантования отдельных слоев под целочисленную арифметику int8/int16. Послойный/поблочный коллапс и имитация подходят для этого как нельзя лучше. Вполне реально построить модель с целыми весами и значениями признаков, даже не покидая любимого фреймворка и уютного fp32.
(Здесь возможна следующая схема имитационного обучения: блок имитации можно составить из целочисленного слоя, полученного квантованием очередного слоя-прототипа, слоя возврата к плавающей арифметике и нескольких последующих слоев оригинала, демпфирующих ошибки квантования. На каждом шаге эта конструкция смещается вниз на один слой по прототипу.)
В любом случае, взять мощную точную модель для прототипа, и коллапсировать ее в быструю имитацию для продакшена, — довольно любопытная перспектива, не так ли. По крайней мере на задачах классификации с десятками классов и небольшим обучающим датасетом, если исходная структура модели заточена под тысячи классов и миллион картинок. Если трансфертное обучение адаптирует к вашим данным только веса модели, то здесь адаптируется и ее архитектура.
Возможно, имитационное обучение составит полезное дополнение к глубокому. Хотя не будем спешить с окончательными выводами. Практическая проверка большинства утверждений данной статьи пока еще слишком скромная. Но даже если эти соображения в итоге окажутся не самыми адекватными, всегда полезно взглянуть на проблему под другим углом.
Всего доброго
Ссылки
-
. Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. https://arxiv.org/abs/1707.01083
-
François Chollet. Xception: Deep Learning with Depthwise Separable Convolutions. https://arxiv.org/abs/1610.02357
-
Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam. Searching for MobileNetV3. https://arxiv.org/abs/1905.02244
-
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, Ruslan Salakhutdinov. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. https://jmlr.org/papers/v15/srivastava14a.html
-
Sergey Ioffe, Christian Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. https://arxiv.org/abs/1502.03167
ссылка на оригинал статьи https://habr.com/ru/post/671778/
Добавить комментарий