Это история о том, как я писал код на Python 3, который собирает и систематизирует данные по избирательным комиссиям в моём родном городе Санкт-Петербурге. Ну, и про то, что я там накопал в извлечённых данных.
Интродукция
С 2018 года я работаю в разных качествах в избирательных комиссиях от одной из наблюдательский организация Санкт-Петербурга. Вношу свой посильный вклад в построение гражданского общества, так скажем. И да, может с учётом контекста сегодняшнего времени, не очень я вовремя с этой статьёй, ну а что поделать.
Интерес к тому, чтобы систематизировать данные по избирательным комиссиям появился у меня в тот момент, когда я участвовал в выборах 2021 года в качестве ЧПРГ ТИК№31. Учиться программировать я стал относительно недавно, 2 месяца в относительно ленивом темпе (на момент начала июня 2022).
3 июня я приступил к работе и начал осуществлять свою давнюю задумку.
S’il vous plait — хронология.
Глава 1. Сбор данных
Сайт, с которого я собирал данные выглядит так.
Слева структура комиссий в открывающихся списках. Честно говоря, я пока что понятия не имею, как устроена веб-страница на практике, но заметил, что если открывать разные комиссии, то сайт остаётся один и тот же, меняется только длинный номер в конце адреса. Я попробовал понять, есть ли какая-нибудь связь между номером комиссии и её номером в адресной строке, но быстро понял, что никакой генеральной закономерности там нет, хоть фрагментами и можно так подумать.
Переписывать ссылки вручную — дело долгое и неблагодарное, поэтому полез в веб-инспектор сафари. Полу-наугад стал там искать, где есть ссылки, на которые ведут номера комиссий. Сначала копался в ресурсах и увидел, что если раскрыть список — появляется файл st-petersburg, в котором перечислены несколько айдишников. Уже неплохо, но всё ещё многовато действий.

Продолжил поиски и во вкладке Аудит нашёл то, что искал, как на ладони (Result Data -> data-domAttributes. Для того, чтобы там появилось всё, что мне надо, пришлось вручную пооткрывать все списки, но это не заняло много времени.

Экспорт был в файл с расширением json. Я что-то об этом слышал, поэтому решил не разбираться (может быть слишком долго), а просто скопировал из окошка строки с айдишниками в обычный текстовый файл.
Также с сайта втупую выделил и скопировал список комиссий в текстовый файл, они там в таком же порядке, как и их айди на картинке, поэтому можно будет составить словарь или типа того.
Глава 2. Очистка данных
Эффективнее было бы очистить числа от html-мусора в любом текстовом редакторе, но это неспортивно, я ж в конце концов программировать учусь, а не текстовым редактором пользоваться.
Немного освежил память, как там обращаться к файлам и написал незамысловатый код для очистки:
out_string_indexes = '' file_name = 'Indexes List.txt' with open(file_name, mode='r') as file: for line in file: if '<' in line: #это чтоб отфильтровать нужные строки, они # там странновато скопировались out_string_indexes += line.split('id=')[1].split('"')[1] out_string_indexes += '\n' file_name = 'indexes_processed.txt' with open(file_name, mode='w') as file: file.write(out_string_indexes) Затем проверил, ничего ли не потерялось:
file_name = 'indexes_processed.txt' with open(file_name, mode='r') as file: i = 0 for line in file: i += 1 print('There are {} indexes'.format(i)) file_name = 'commissions_list.txt' with open(file_name, mode='r') as file: i = 0 for line in file: i += 1 print('There are {} commissions in the list’.format(i))Всё оказалось хорошо, выдало по 2017 и тех и других.
Нашёл в интернете вот это, для тех, что проникся дзеном пайтона
sum(1 for line in open('file', ‘r’))Но я ещё не проникся настолько, побаиваюсь вообще таких функций. Мне лучше для начала понятно и надёжно (как Tegridy farms(r))
Глава 3. Общение с вебсайтом
С такой проблемой я ещё не сталкивался, поэтому стал читать, как вообще обратиться к вебсайту. Спустя пару минут выяснил, что с помощью urllib.request. Открыл, сразу же столкнулся с такой проблемой:
urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:997)>
Догадался скопировать ошибку в гугл и быстро нашёл, что нужно в папке пайтона тыкнуть на установку сертификата. Попробовал подсоединиться снова, получил вот это:
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 403: Forbidden
Упс, кажется, мне тут не рады. А ещё похоже, что он меня по айпи забанил, потому что и через браузер перестал входить, а через терминал пингуется нормально. (апд: потом разбанил через сутки)
Ничего страшного, раздал интернет с телефона. Там, если я что-то в чём-то понимаю, айпи присваивается динамически при подключении, и такая блокировка не сработает, если переподключаться. В интернете я быстро вычитал, что к запросу надо добавить хедер, типа имитировать, что я с браузера захожу.
Если что, у меня ОЧЕНЬ поверхностные знания обо всём этом.
from urllib.request import Request, urlopen req = Request('http://www.st-petersburg.vybory.izbirkom.ru/region/st-petersburg?action=ik&vrn=27820001006425', headers={'User-Agent': 'Mozilla/5.0'}) webpage = urlopen(req).read() result = webpage.decode('utf-8', 'ignore') print(result)На этот раз получилось, но получилось всё ещё не то. Если я правильно понял, то страница-то загрузилась, но не выполнился скрипт, который подгружает на страницу все нужные мне данные.
Разумеется, я не единственный, кто с этой проблемой столкнулся, поэтому вновь углубился в чтение. За это время моим любимым сайтом стал Stack Overflow.
Собственно, загрузив нужный модуль requests_html, которых там почему-то сразу загрузилась целая гирлянда, я написал это, и оно наконец сработало! Лёд тронулся, господа присяжные.
from requests_html import HTMLSession session = HTMLSession() url = 'http://www.st-petersburg.vybory.izbirkom.ru/region/st-petersburg?action=ik&vrn=4784001269007' r = session.get(url, headers={'User-Agent': 'Mozilla/5.0'}) r.html.render result = r.text.encode('utf-8') result = result.decode('utf-8') print(result)Кодировать и раскодировать пришлось по той причине, что вместо кириллицы он выдавал ерунду, а как ещё декодировать эту хрень — я не догадался, так что прошу прощения, если говнокод. Тем не менее, результата я достиг.

Дело осталось за малым: нужно теперь вытащить оттуда саму табличку и написать программу, которая прогонит этот алгоритм через все 2017 комиссий. Предварительно придумав, каким образом эти данные структурировать, чтобы потом можно было по ним всё что нужно искать.
Кстати, я тут подумал, может повытаскивать у них адреса и разметить на карте

Глава 4. Построение программы
Сначала я писал команды в императивном стиле, чтобы понять, что мне именно нужно и как этого достичь, затем уже распихал всё это по функциям и слепил из них мастер-функцию.
Если кратко описать, то отрезал страницу по начало таблицы, удалил все <штуки>, некоторые заменив на разделители, затем командой split сделал из получившейся строки массив, из которого дальше сделал двумерный массив. Приблизительно так:
def text_cleanup(txt=text): # Обрезаю таблицу start = txt.index('ФИО') #начало таблицы txt = txt[start::] start = txt.find('1') #начало первой нужной строки таблицы txt = txt[start - 4::] end = txt.index('</table') #конец таблицы txt = txt[:end:] #Удаляю следы html txt = txt.replace('</tr>', '') txt = txt.replace('<tr>', '...') #строки txt = txt.replace('<td>', ',,,') #столбцы txt = txt.replace('</td>', '') txt = txt.replace('<nobr>', '') txt = txt.replace('</nobr>', '') txt = txt.replace('<br>', '') txt = txt.replace('</br>', '') txt = txt.replace('\r', '') txt = txt.replace('\t', '') txt = txt.replace('\n', '') return txtДальше так
txt = text_cleanup() result = txt.split(‘…’) #разбиваю текст по строкам for i in range(len(result)): #разбиваю каждую строку на элементы result[i] = result[i].split(',,,') return result
И лёгким движением руки таблица с сайта превращается… превращается таблица с сайта… в двумерный массив.
Дальше я создал функцию, которая берёт веб-страницу через session.get и render, как я писал выше, прогоняет полученное через функцию очистки, записывает в текстовый файл или эксель, и всё это в цикле, который из списка подгружает айдишники, которые до этого были в него записаны из файла ещё одной функцией. Как писать в эксель — это я прочитал статью про модуль pyopenxl, мне очень понравилась там функция append, которую я и использовал в своей программе.
Короче, сущностно происходит следующее:
-
Из файлов выгружается в двумерный список названия комиссий и их айди
-
Циклом по очереди из этого списка читаются айди
-
Добавляются к постоянной части адреса, загружается код страницы
-
Очищается от мусора и преобразуется в двумерный список
-
Построчно вместе с номером комиссии записывается в файл
Код получился здоровый, поэтому публиковать не буду, основные его элементы и логику я в принципе описал. Итого 2 минуты код отработал как часы и на выходе получилась здоровенная таблица!


Тут я ненадолго остановлюсь и опишу свои ощущения:
Я хоть и продвинутый, но обычный юзер, поэтому когда вся эта штука сработала — я ощутил себя каким-то, блин, Нео. Вообще то, что я написал программу, которая сама в интернете ковыряется — это крайне странно. Ни разу не выходил в интернет не через браузер. Вот уж был действительно hello world!
И это пока что первая программа, которая выполняет что-то не абстрактное, а вполне конкретное. Собственно, испытываю гордость за себя:)
Глава 5. Анализ
В принципе, всю аналитику можно было бы сделать в экселе, но это неспортивно, я же программировать учусь. Какую-то сложную аналитику я производить не буду, меня интересуют довольно простые вещи. Гипотеза в том, что представителей крупных партий кроме Единой России непропорционально мало среди руководства комиссий, а может и в принципе среди всех членов комиссий.
Чтобы мой дорогой читатель не подумал, что я сразу выдумал всю программу, сначала я написал код несколько меня интересующих случаев, но потом решил, что нужно более универсальное и гибкое решение.
Написал сначала функцию analysis(*args), которая делает вот что:
-
создаёт пустой словарь
-
считывает из текстового файла строку
-
ищет в ней слова из *args
-
если находит, проверяет, есть ли в словаре название партии
-
если есть — делает +=1, если нет — добавляет со значением 1
-
выдаёт в итоге общее количество найденных строк и словарь, в котором напротив названия партии указано количество человек
Так это выглядело на выходе, если не фильтровать (только без процентов сначала):

Фильтр работал нормально, но с таким результатом сделать что-то сложно. У меня возникли идеи: надо сделать отдельную функцию фильтр с аргументом, переключающим режимы И / ИЛИ, а также создать список основных партий и сверять с ним, потому что читать данный результат трудно. Можно ещё отметить, что Единая Россия внимательнее всех относится к тому, чтобы написать именно конкретное отделение своей партии.
В итоге следующая версия выглядела так:
parties_list — это список более крупных партий, который я выделил
def filter_keywords(line='', und=False, *args): """Returns True if arguments are in line. Basically, und is and: If und=True -> every argument must be in line, If und=False -> at least one argument must be in line""" if und: for word in args: if word.lower() not in line.lower(): return False return True else: for word in args: if word.lower() in line.lower(): return True return False def analysis(unite_minors=True, und=False, *args): """Returns vocabulary with parties and a number of members in it and overall quantity of members. unite_minors collects every minor party/association to keyword 'Остальные'. und is about filtering style 'and' or 'or', und is and in a nutshell. args is keywords for filtering""" result = {'Остальные': 0} counter = 0 with open('master_table.txt', mode='r') as file: for line in file: if filter_keywords(line, und, *args): party = line.split(' : ')[6] if not unite_minors: #если не объединять партии, не входящие в список if party in result: result[party] += 1 else: result[party] = 1 counter += 1 else: #если объединять партии, не входящие в список for major_party in parties_list: if filter_keywords(line, False, major_party): if major_party in result: result[major_party] += 1 else: result[major_party] = 1 counter += 1 break else: #если за цикл не нашлось совпадений counter += 1 result['Остальные'] += 1 # сортировка словаря, скопировал из интернета дзен-функцию # на этот раз было лень писать самому result = dict(sorted(result.items(), key=lambda item: item[1], reverse=True)) return result, counter Я решил отправить в return помимо словаря сколько всего строчек обработано. Для учёта и чтоб сразу проценты можно было высчитывать, хотя не знаю, насколько это целесообразно. Но если что — легко переделывается.

Так гораздо лучше, но спустя некоторое количество запросов я понял, что такая функция не позволяет мне узнать, например, кто выдвинул Председателя, Зама и Секретаря только в Территориальных комиссиях. Поэтому решил сделать новую, которая будет фильтровать отдельно по уровню комиссий и должностям. Она стала концептуально проще и принимает строки с ключевыми словами через пробел.
def filter_or(line, *args): for word in args: if word.lower() in line.lower(): return True return False def analysis2(level='', position='', unite_minors=True): """Returns vocabulary with parties and a number of members in it and overall quantity of members. unite_minors collects every minor party/association to keyword 'Остальные'. level is keywords for level filter, type with spaces between keywords! position is keywords for position filter, type with spaces between keywords!""" result = {'Остальные': 0} counter = 0 level = level.split(' ') position = position.split(' ') with open('master_table.txt', mode='r') as file: for line in file: t_party = line.split(' : ')[6] t_position = line.split(' : ')[5] t_level = line.split(' : ')[0] if filter_or(t_level, *level) and filter_or(t_position, *position): if not unite_minors: if t_party in result: result[t_party] += 1 else: result[t_party] = 1 counter += 1 else: for major_party in parties_list: if filter_or(t_party, major_party): if major_party in result: result[major_party] += 1 else: result[major_party] = 1 counter += 1 break else: counter += 1 result['Остальные'] += 1 result = dict(sorted(result.items(), key=lambda item: item[1], reverse=True)) return result, counterНа этот раз я получил весь функционал, который хотел. И да, немного кода, который всё это выводит на консоль. А затем ещё и в графики вместе с модулем matplotlib.pyplot, о котором я только что прочитал.
voc, quantity = analysis2(level='спбик тик уик', position='председатель зам секретарь член', unite_minors=True) print('****Всего {}****\n'.format(quantity)) for item in voc: print('{} or {}% : {}'.format(voc[item], round(voc[item] / quantity * 100, 1), item)) values, keys = list(voc.values()), list(voc.keys()) plt.pie(values, labels=keys, autopct='%.1f%%') #так неочевидно процент выводится plt.title('Винни-Пух и все, все, все') plt.show()Глава 6. То, ради чего это всё задумывалось
Тут будут таблички и графики с минимальными комментариями.
Если есть желание понять субъект анализа, типа как эти все комиссии устроены и кто в них что делает, то лучше об этом почитать подробнее в любом разделе «Обучение» наблюдательский организаций или даже официальных порталов. А я опишу кратко:
УИК — участковая избирательная комиссия, обеспечивает выборы на местах непосредственно. Принимает всё что нужно для работы от ТИК, отчитывается туда же.
ТИК — территориальная избирательная комиссия, выполняет административно-хозяйственные функции, то есть, грубо говоря, материальная база и вопросы формирования, назначения/освобождения членов нижестоящих комиссий (разумеется через заявления).
Комиссия — коллегиальный орган, право голоса имеют все, вопросы решаются через голосование большинством. Кворум для открытия заседания в общем случае — больше половины.
Председатель — по сути спикер комиссии, должностное лицо
Секретарь — думаю, более-менее и так понятно
Поскольку у комиссий разного уровня сильно разные функции, то и обобщать их особого смысла я не вижу.
Для начала посмотрим, что мы имеем по Участковым избирательным комиссиям:
УИК, все


По месту работы — это по сути работники бюджетных организаций. По месту жительства в большинстве случаев тоже, ну или близкие к. Возможно среди них есть и просто активные жители, но очень сомневаюсь, что таких там хоть сколько-то много. Думаю, где-то описаны схемы набора таковых, да и догадаться несложно
Остальные — это представители многочисленных организаций, о которых в основном никто никогда и не слышал. Обычно около-административные. (Личная оценка)
Как видно, средняя комиссия наполовину состоит из этих трёх категорий, а партии распределены более-менее ровно с предпочтением к самым крупным.
Теперь посмотрим, а что там в руководстве УИКов.
УИК, Руководство (Председатель, Зам.Председателя и Секретарь)


Ой, а что это у нас тут случилось? Я думаю, что комментарии тут излишни, а изменения очевидны. Ради интереса можно посмотреть, кто такие эти трудовые партии, союзы труда и партия «За женщин России». У-ух!
Теперь посмотрим, что там по Территориальным комиссиям.
ТИК, Все члены


Да тут прям почти полноценный плюрализм, мамочки родные!
А теперь руководство ТИК:
Руководство ТИК

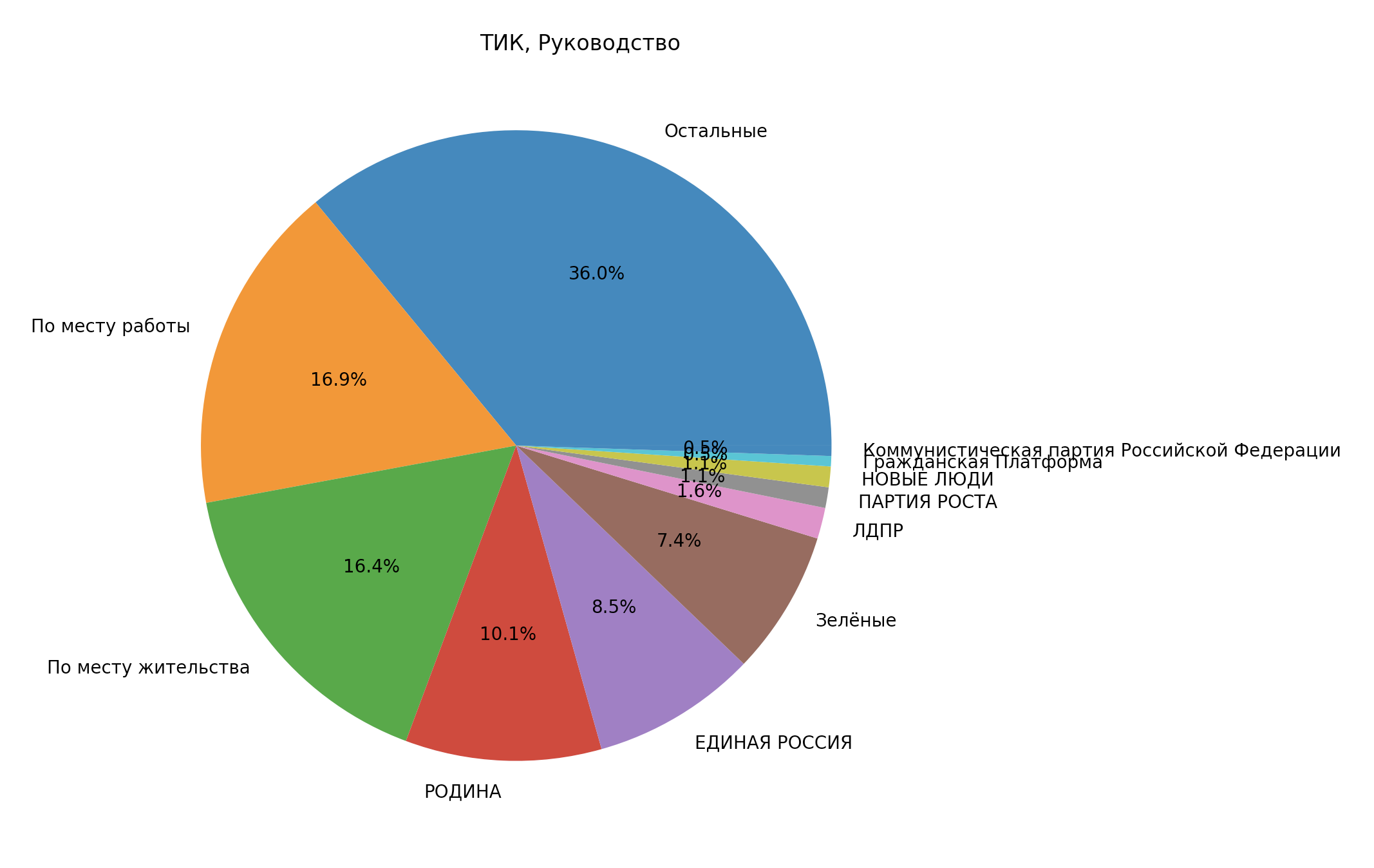
…Ну, что тут сказать можно, картинка достаточно красноречива
Очень большой сегмент “Остальные”, я бы посмотрел подробнее, кто у нас там.
voc, quantity = analysis2(level='тик', position='председатель зам секретарь', unite_minors=False) print('****Всего {}****\n'.format(quantity)) for item in voc: print('{} or {}% : {}'.format(voc[item], round(voc[item] / quantity * 100, 1), item))32 or 16.9% : собрание избирателей по месту работы
31 or 16.4% : собрание избирателей по месту жительства
29 or 15.3% : территориальная избирательная комиссия предыдущего состава
16 or 8.5% : Региональное отделение ВСЕРОССИЙСКОЙ ПОЛИТИЧЕСКОЙ ПАРТИИ «РОДИНА» в городе Санкт-Петербурге
16 or 8.5% : Санкт-Петербургское региональное отделение Всероссийской политической партии «ЕДИНАЯ РОССИЯ»
12 or 6.3% : представительный орган муниципального образования
11 or 5.8% : Региональное отделение в Санкт-Петербурге Политической партии «Российская экологическая партия «Зелёные»
6 or 3.2% : Санкт-Петербургское региональное отделение политической партии «ПАТРИОТЫ РОССИИ»
4 or 2.1% : Политическая партия «ПАТРИОТЫ РОССИИ»
3 or 1.6% : Региональная общественная организация поддержки и развития молодежного творчества «Гаудеамус»
3 or 1.6% : Санкт-Петербургское региональное отделение Политической партии ЛДПР — Либерально-демократической партии России
3 or 1.6% : ВСЕРОССИЙСКАЯ ПОЛИТИЧЕСКАЯ ПАРТИЯ «РОДИНА»
3 or 1.6% : Политическая партия «Российская экологическая партия «Зелёные«
2 or 1.1% : Межрегиональная общественная организация «Ассоциация ветеранов, инвалидов и пенсионеров»
2 or 1.1% : Региональное отделение в Санкт-Петербурге Всероссийской политической партии «ПАРТИЯ РОСТА»
2 or 1.1% : Региональная общественная организация поддержки и развития молодежного творчества «Гуадеамус»
2 or 1.1% : Региональное отделение в Санкт-Петербурге политической партии «НОВЫЕ ЛЮДИ»
1 or 0.5% : Межрегиональная общественная организация «Центр содействия реализации социальных инициатив «Живой Питер»
1 or 0.5% : Региональное отделение в городе Санкт-Петербурге Политической партии «Гражданская Платформа»
1 or 0.5% : Политическая партия «Российская экологическая партия «Зеленые«
1 or 0.5% : Санкт-Петербургская региональная общественная организация содействия детям сиротам «Радуга»
1 or 0.5% : САНКТ-ПЕТЕРБУРГСКОЕ ГОРОДСКОЕ ОТДЕЛЕНИЕ политической партии «КОММУНИСТИЧЕСКАЯ ПАРТИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ»
1 or 0.5% : Санкт-Петербургская Региональная Общественная Организация инвалидов «Радонежец»
1 or 0.5% : Местное отделение Санкт-Петербургской общественной организации ветеранов (пенсионеров, инвалидов) войны, труда, Вооруженных сил и правоохранительных органов «Кировское» на территории муниципального округа «Дачное»
1 or 0.5% : Региональная общественная организация инвалидов «Радонежец»
1 or 0.5% : Санкт-Петербургская Общественная Организация в поддержку молодежи «МИР МОЛОДЕЖИ»
1 or 0.5% : Санкт-Петербургская общественная организация «Жители блокадного Ленинграда»
1 or 0.5% : Политическая партия СОЦИАЛЬНОЙ ЗАЩИТЫ
1 or 0.5% : Санкт-Петербургская ассоциация общественных объединений родителей детей-инвалидов “ГАООРДИ»
Я подчеркнул тех, что вошёл как “Остальные”. И ещё заметил, что партия Зелёные вошла тоже туда, потому что для компьютера Е и Ë — разные символы. Надо будет учесть этот момент, хоть он принципиально ни на что и не влияет.
Конечно, я подтолкнул к мысли о том, что не так с этой системой. На самом деле не я, а данные, я их лишь обнажил.
Заключение
Мне очень понравилось, что спустя уже небольшое время я смог применить на практике то, чему научился. Я очень рад, если было хоть немного интересно это занудство читать, если статья открыла какое-то новое виденье, вдохновила, или повлияла ещё каким-то образом.
Открыт для любых дискуссий, пожеланий, советов, критики или чего там ещё.
ссылка на оригинал статьи https://habr.com/ru/post/671832/
Добавить комментарий