Секунда теории
Гетероскедастичность – это ситуация, когда ошибка регрессии не удовлетворяет условию гомоскедастичности, т.е. дисперсия этой самой ошибки непостоянно. Это приводит при использовании метода наименьших квадратов к разным неприятным эффектам смещения значений оценок, что ставит под сомнение смысл всей проделанной на основании данного уравнения регрессии работы.
В странствиях по CRAN-у попался пакет skedastic, в котором реализованы 25 разных тестов гомоскедастичности – о нем и поговорим.
О тестах
Вдумчивый разбор математического основания всех реализованных тестов – это дело статьи в специализированном журнале, дело данной заметки – посмотреть, как они работают.
Возьмем из пакета UsingR данные о бриллиантах diamond и посмотрим уравнение регрессии (цена зависит от веса)
library(tidyverse) library(ggplot2) library(skedastic) library(AER) library(gvlma) library(UsingR) data(diamond) ggplot(data = diamond, aes(x=carat, y=price)) + geom_point() model_1 <- lm(price~carat, data=diamond) summary(model_1) gvlma(model_1) ggplot(data = diamond, aes(x=carat, y=model_1$residuals)) + geom_point() + ylab("Error of model")
На графике видна классическая линейная зависимость. Соответствующая модель значима и даже (по версии пакета gvlma) все условия Гаусса-Маркова выполняются
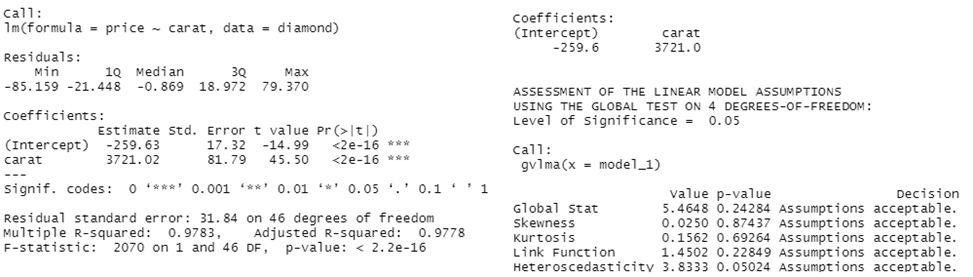
График ошибок говорит о том же самом:

Есть значительные основания полагать, что гетероскедастичности тут нет. Теперь посмотрим на результаты применения пакета skedastic (во всех тестах нулевая гипотеза: есть гомоскедастичность; при уровне значимости меньше заданного, допустим, 0.05, она будет отвергнута):

Собственно, тесты почти единодушны: 24 из 25 (кроме теста Хонды) указали, что нулевая гипотеза не может быть отвергнута, значит, можно смело говорить про гомоскедастичность.
Эксперимент
Самое интересное, правда, другое – вопрос о том, насколько эти тесты определяют гетероскедастичность, когда у нас она есть. Создадим искусственный датафрейм по формуле y = ax+b+e(1+s|x|) при разных значениях s. При s=0 у нас классическая гомоскедастичность (ошибки происходят из нормального распределения), при s=1 – классическая гетероскедастичность (когда дисперсия ошибок растет при увеличении х по модулю). Логично предположить, что нормальное поведение теста в этих случаях – обратная пропорциональность p-значения от значения s. Каждый тест проводился 100 раз на разных значениях a и b, его результаты потом усреднялись. Соответствующие графики представлены ниже:
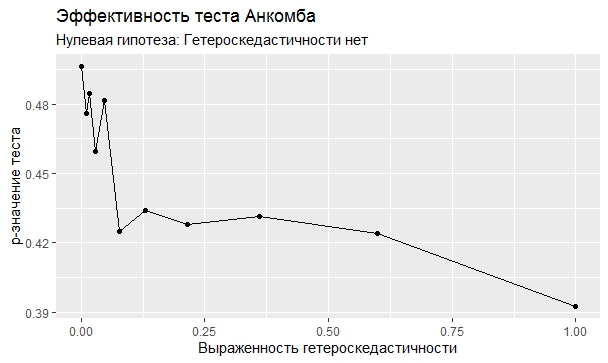
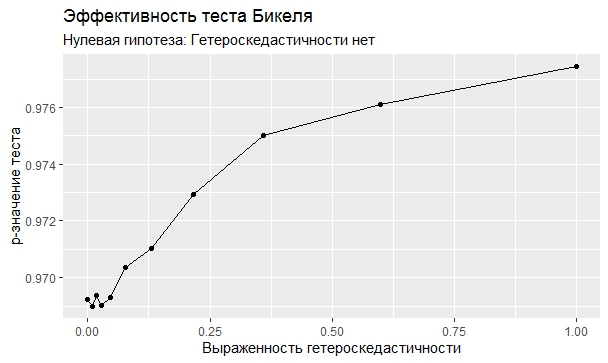
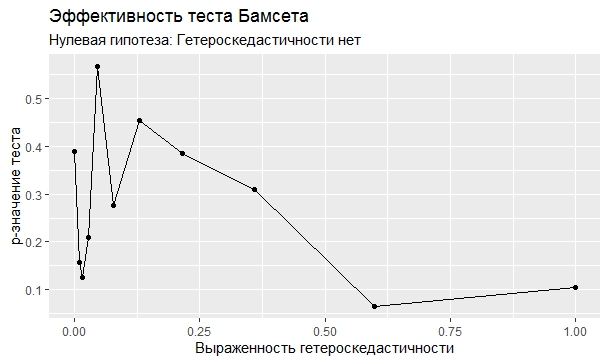

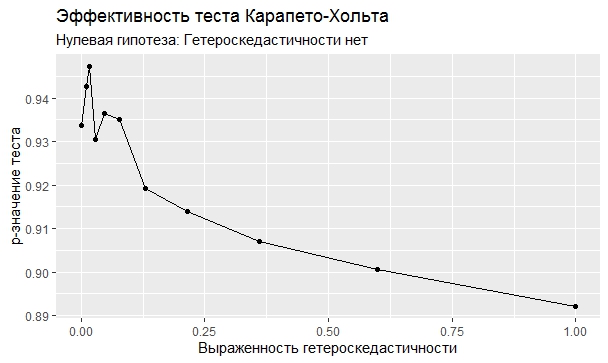
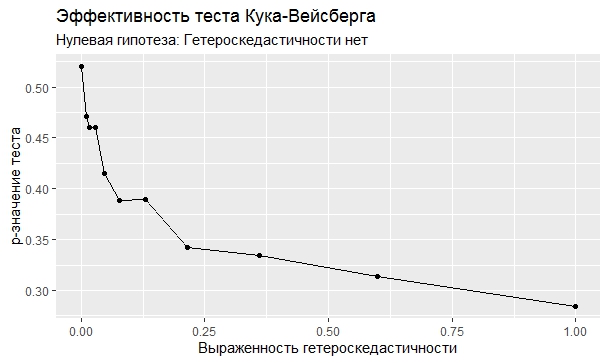
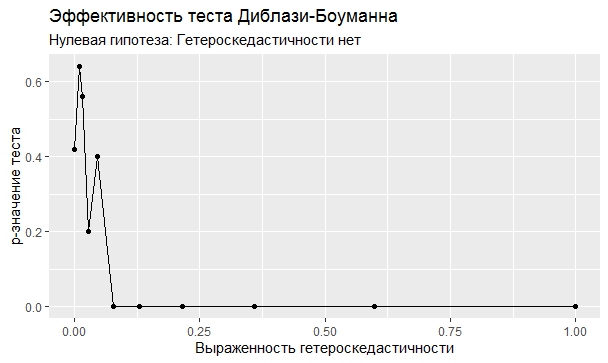
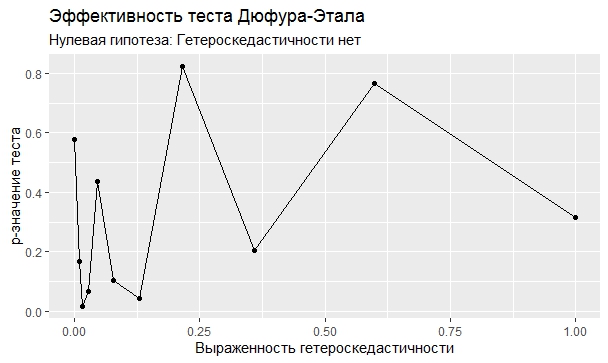
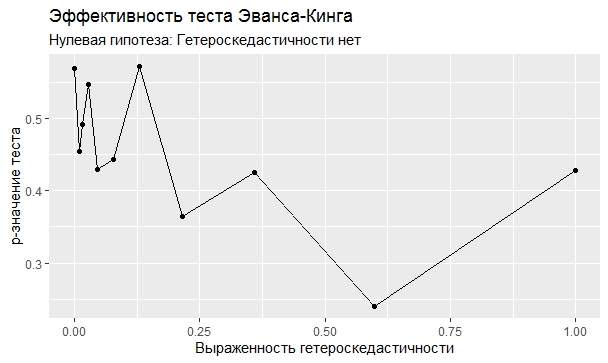
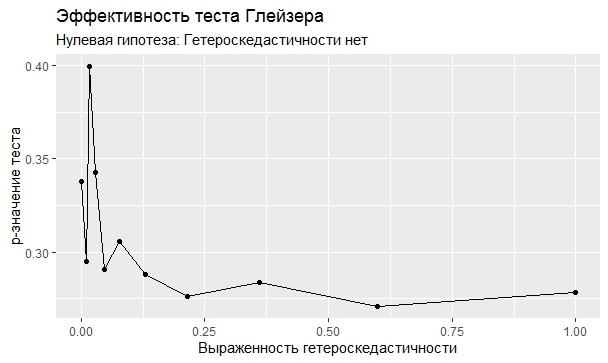
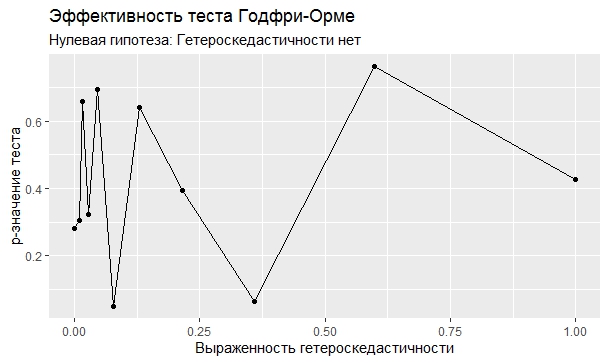
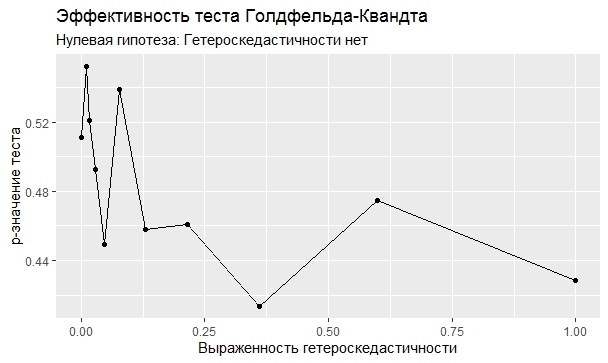
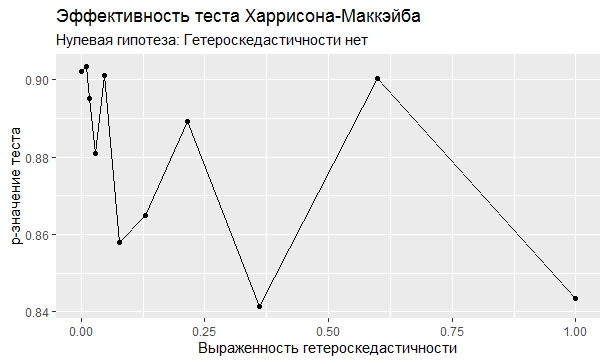
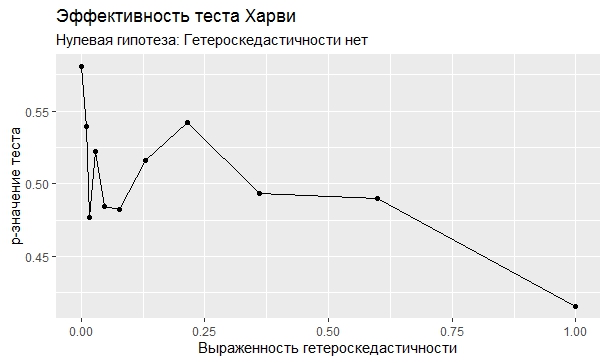
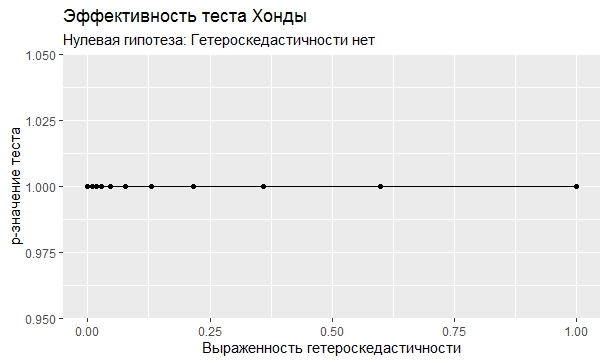
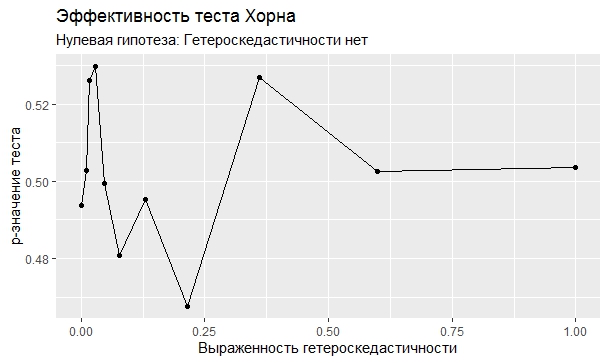
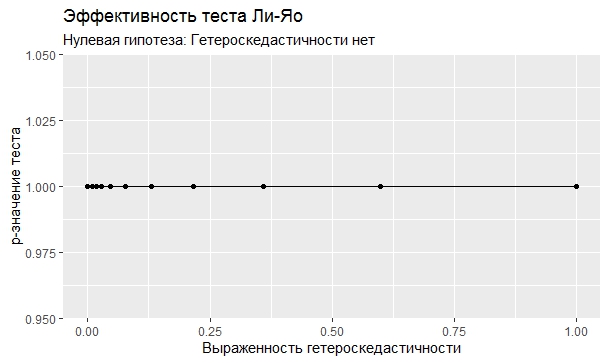
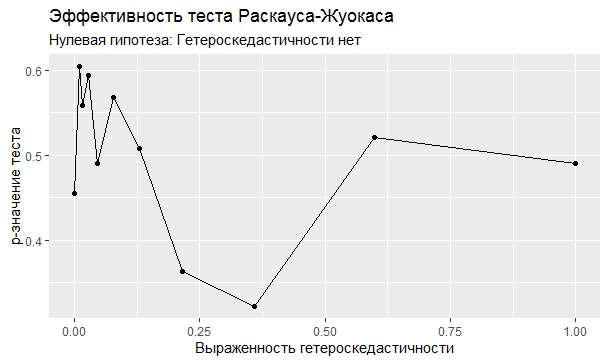
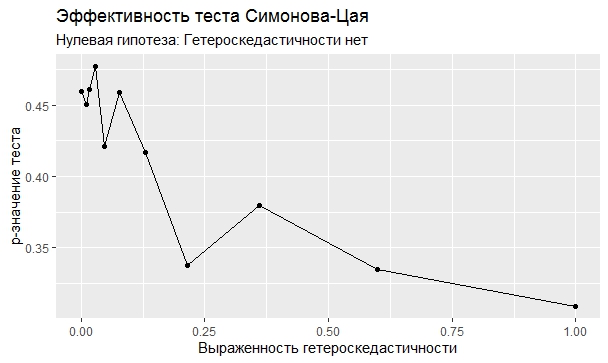
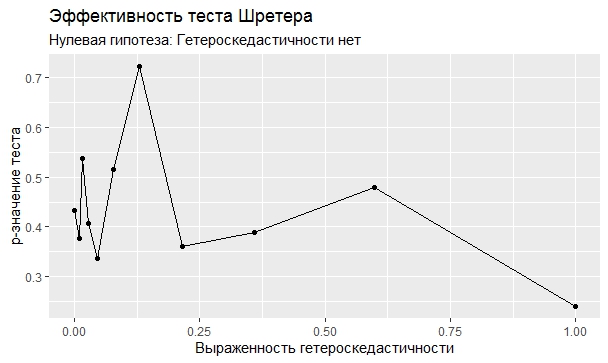
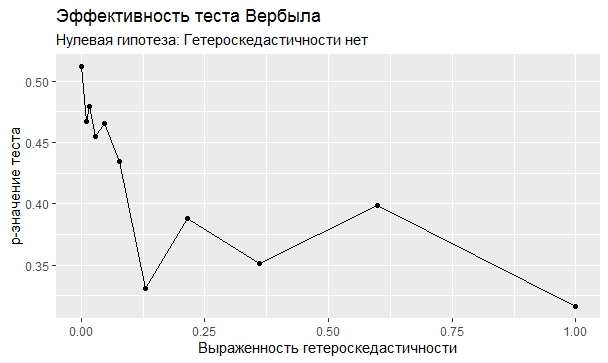
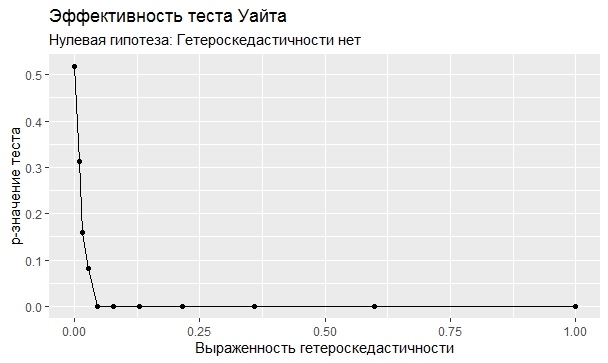
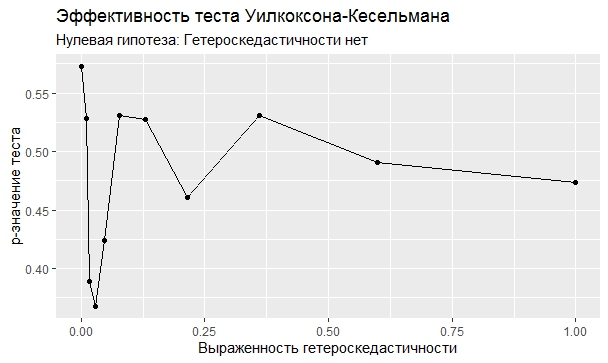
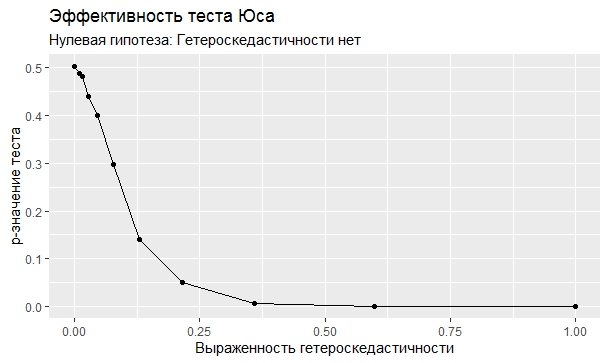
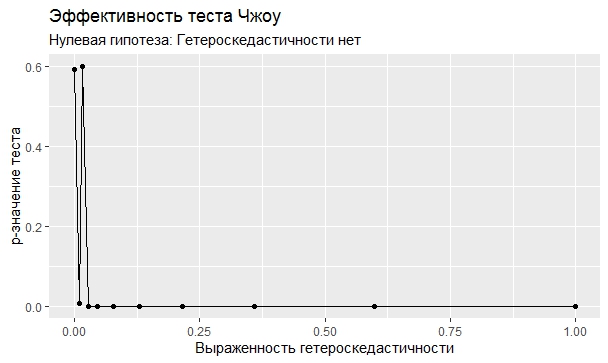
Собственно, тестов, определяющий данный вид гетероскедастичности, всего 4 (из 25): Диблази-Боуманна, Уайта, Юса и Чжоу. Это говорит о том, что даже если вам тесты показали, что у вас все хорошо, это не значит, что оно так и есть. И это также повод внимательно посмотреть и определить области эффективности этих тестов.
Все материалы, в т.ч. статьи авторов-изобретателей тестов, есть на https://github.com/acheremuhin/Heteroscedacity
ссылка на оригинал статьи https://habr.com/ru/post/678834/
Добавить комментарий