
Привет, Хабр! Мы – команда информационной безопасности Почты Mail.ru. Уже много лет мы постоянно совершенствуем текущие и внедряем новые механизмы безопасности и технологии беспарольного входа, которые направлены на защиту аккаунтов пользователей. Но пока пароль остается основным методом аутентификации для большинства пользователей и является самым ненадежным методом аутентификации, потому что природа не одарила человеческий мозг хорошим генератором псевдослучайных чисел и идеальной памятью. Согласно многочисленным исследованиям, пользователи предпочитают использовать простые, предсказуемые, не уникальные пароли.
Чтобы побороть проблему скомпрометированных паролей, мы на протяжении нескольких лет собирали публичные утечки на просторах интернета и проверяли их через внутренний компонент, который представлял из себя самописный сервис для брутфорса. Данное решение позволяло нам успешно оберегать пользователей от злоумышленников, однако с каждым месяцем это становилось все сложнее. Пришло время рассказать, как нам все-таки удалось сделать этот процесс более управляемым.
Слепой «офлайн»-брутфорс, как оказалось впоследствии, был совершенно не масштабируемым решением: он стал узким местом так как мы находили утечек на порядок больше, чем успевали проверять.
Это усугубилось переходом на схему «тяжелого» хеширования. Такое хеширование защищает от офлайнового перебора пароля, даже если хеши окажутся в руках злоумышленника и делает невозможным использование для «офлайн»-брутфорса GPU, ASIC’ов и даже ботнетов. Однако по этой же причине скорость нашего брутфорса замедлилась на порядки, что стало временным блокером для окончательного перехода на новую схему. О внедрении «тяжелого» алгоритма хеширования мы расскажем в одной из следующих статей. Сам процесс проверок при этом тяжело поддавался автоматизации и был полон рутинной ручной работы. Также была вероятность совершить ошибку и, аки Танос, сделать щелчок бесконечности (именно в честь этого персонажа старый сервис и был назван). Но во всём этом было место и положительным моментам, один из которых заключается в том, что за эти годы мы успели накопить статистику, которой готовы поделиться.
Если утечка из зарубежного сервиса:
-
Пересечение (пользователь не наш, но у нас есть такой же логин, то есть username без @domain) с нашими учётками достаточно велико — 35 %.
-
В этом пересечении вероятность совпадения пароля учётки из другого сервиса с паролем от учётки в нашем сервисе 0,17 % (выглядит немного, но в абсолютных числах утечка 1 000 000 пар логинов с паролями потенциально может привести к несанкционированному доступу к учетным записям 595 пользователей).
-
Если сделать несколько дополнительных проверок, слегка «мутировав» пароль, как это делает средний пользователь (qwerty -> qwerty1 -> qwerty2 -> Qwerty2), думая что он самый неуловимый Джо на всём Диком Западе, то вероятность совпадения пароля из учётки возрастает чуть более чем в полтора раза, до 0,36 % (утечка 1 000 000 пар логинов с паролями приведёт к несанкционированному доступу к учетным записям 1260 пользователей). Брутфорсеры тоже так делают.
Если утечка из российского сервиса:
-
Пересечение (пользователь не наш, но у нас есть такой же логин, то есть username без @domain) с нашими учётками выше, чем в утечках из зарубежных сервисов — 65 %.
-
В этом пересечении вероятность совпадения пароля учётки из другого сервиса с паролем от учётки в нашем сервисе составляет 6,5 %.
-
С простой мутацией вероятность совпадения пароля из учётки возрастает также чуть более чем в полтора раза, до 10 %.
Предположим, что, на момент начала работ в известных утечках можно было найти 50 000 000 000 пар юзернейм + пароль (99 % относится к зарубежным сервисам, 1 % к российским), проверив которые мы потенциально подберём пароль к 178 200 000 + 50 000 000 = 228 200 000 аккаунтам.
На самом деле, картина чуть менее печальна. На практике среди уникальных пар есть похожие аккаунты и пароли одного и того же пользователя. Но даже если считать по максимальным значениям, то примерно 85 % из сбрутфорсенных аккаунтов уже заблокированы в рамках разработанных ранее процессов предотвращения взлома, 10 % неактивные и лишь около 5 % активные. То есть итоговые числа будут такие:
-
193 970 000 будут заблокированы в рамках разработанных ранее процессов предотвращения взлома.
-
22 820 000 будут неактивны, но потенциально уязвимы.
-
11 410 000 будут активные потенциально уязвимые пользователи.
Имеющиеся механизмы антибрутфорса защищают даже пользователей с потенциально скомпрометированными паролями, и, по крайней мере, не дают быстро проверить скомпрометированные эккаунты. Однако, если пароль пользователя утек и это единственный фактор, защищающий его учётную запись, с высокой вероятностью рано или поздно он будет взломан.
В итоге мы поняли, что для повышения уровня безопасности пользователей Почты необходим новый сервис, который поможет предотвратить потенциальный несанкционированный доступ к десяткам миллионов аккаунтов, и он должен:
-
Считать хеш от того пароля, с которым пользователь (или атакующий) пытается аутентифицироваться, и сравнивать его с хешами паролей, которые найдены в утечке, а не наоборот.
-
Быть быстрым и удобным.
-
Минимизировать ручной труд.
-
Увеличивать показатели эффективности:
-
проверять пароли на скомпрометированность не только у аккаунтов, что доступны к регистрации в наших публичных доменах, а вообще во всех;
-
иметь более качественный мутатор, который покроет большинство техник модификации паролей.
-
-
Собирать статистику работы в реальном времени.
-
Позволять быстро приостановить «прокрутку фарша».
-
Являться единым хранилищем хешей всех «непристойных» паролей, которые пользователям более нельзя использовать в своих учетных записях:
-
слабых (qwerty, p@ssword);
-
присутствующих в утечках;
-
использовавшихся пользователем ранее, с которым в учетной записи была замечена зловредная активность (явный взлом, рассылка спама).
-
-
Легко масштабироваться и быть легко переносимым, чтобы иметь возможность внедрить решение, разработанное командой Почты в других сервисах экосистемы VK или использовать его, например, совместно с passfilt.dll для проверки доменных учеток.
Базовая концепция решения
Новый сервис получил название Taneleer, по имени «Коллекционера» из вселенной Marvel. Для уменьшения TTM путём параллельной разработки тремя независимыми командами, и повышения устойчивости и быстродействия была выбрана концепция с двумя хранилищами:
-
«холодное» — для хранения содержимого исходных списков утёкших пар логин-пароль;
-
«горячее» — для проверки статуса «непристойности» пары логин-пароль в момент аутентификации пользователя.
Концептуально схема работы может быть представлена схемой:

Реализация
Холодное хранилище
Холодное хранилище решает несколько задач:
-
загрузка списков с парами логин-пароль.
-
администрирование загруженных списков.
-
поиск по загруженным спискам для расследования инцидентов.
Аналитик взаимодействует с холодным хранилищем через веб-интерфейс построенный на Django и Bootstrap:
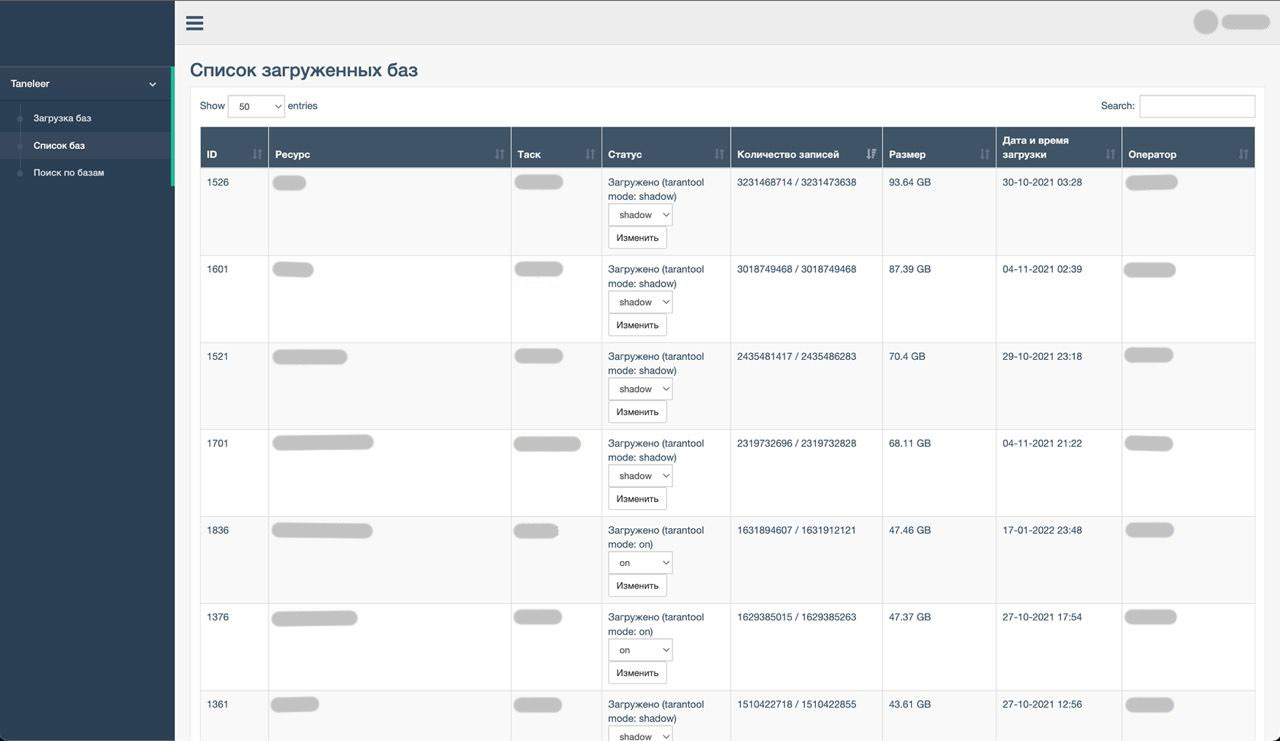
Аналитик передает файл на загрузку, сервер загружает его на диск и асинхронно обрабатывает. В процессе обработки серверный воркер выполняет базовые проверки (строка не содержит не-ASCII и непечатаемые символы, соответствует нужному формату и нормализует входящие данные, отсекая в логине всё, что после @). Валидные записи загружаются в базы холодного и горячего хранилищ, а список невалидных строк возвращается аналитику для просмотра. Поскольку обработка асинхронная, воркер может повторять попытки загрузки в базу до победного, аналитику не нужно прикладывать никаких дополнительных усилий для обработки временных ошибок, достаточно наблюдать за индикатором прогресса.
В интерфейсе аналитику доступна различная статистика по загруженным спискам: размер в байтах, количество валидных и невалидных строк, время и дата загрузки и прочая информация. Помимо статистики, интерфейс позволяет управлять «режимом работы» (on, off, shadow) каждого списка отдельно. “On” означает, что если пользователь попытается аутентифицироваться с паролем, который есть в таком списке, то ему будет отказано в доступе. В режиме “shadow” в доступе не отказывается, но можно по графикам наблюдать, какой поток отказов способна сгененировать эта утечка, если бы она была включена.
В качестве базы данных для холодного хранилища мы используем Scylla — производительное и отказоустойчивое хранилище модели DynamoDB, клон Cassandra на C++. У нас стоят узлы в нескольких ЦОДах, так что хранилище устойчиво к уходу одного ЦОДа. Модель данных Scylla отлично подходит для нашей задачи. Нам нужно уметь выполнять много записей и делать точечные выборки по логину. Вот как выглядит схема данных холодного хранилища:
CREATE TABLE IF NOT EXISTS taneleer.login_password_pairs ( login text, password text, db_id int, PRIMARY KEY (login, db_id, password) ) WITH CLUSTERING ORDER BY (db_id DESC, password ASC) AND bloom_filter_fp_chance = 0.001 AND compaction = {'class': 'SizeTieredCompactionStrategy'} AND compression = { 'sstable_compression': 'DeflateCompressor', 'chunk_length_in_kb': 64 };Scylla позволяет писать в произвольный узел, в случае возникновения конфликтов применяется алгоритм Last Write Wins: остается та строчка, у которой таймстемп создания записи больше. Этот алгоритм подходит не во всех задачах, но мы никогда не меняем старые данные, а лишь записываем новые, поэтому в штатной ситуации конфликтов у нас не должно быть в принципе. Единственный случай, когда у нас возникает конфликт, это когда воркер производит повторную попытку записи в Scylla, и в этом случае LWW нам на руку: он автоматически устраняет дубликаты.
В качестве эксперимента мы сравнивали производительность Scylla и MySQL для этой задачи. На одном и том же железе Scylla выдавала пропускную способность в 10 раз выше: в нашем случае 50K RPS, и это не предел. Это неудивительно, ведь Scylla оперирует данными не так гибко как MySQL, но для нашей задачи этого достаточно.
Горячее хранилище
Для горячего хранилища традиционно выбрали Tarantool — помимо очевидных требований, вроде шардирования и репликации данных между несколькими экземплярами горячего хранилища, требовалось реализовать часть бизнес логики именно в самом хранилище. К примеру, загрузка новых данных в горячее хранилище, а также поиск скомпрометированных логинов и паролей среди имеющихся записей требует определённых дополнительных действий и проверок, чтобы избежать дублирования информации и прочих ошибок.
Так как Tarantool является платформой in-memory вычислений, реализация необходимых частей бизнес-логики непосредственно в Tarantool’ах позволила уменьшить затраты на сетевые вызовы и, следовательно, время ответа сервиса. Плюсом к этому идет возможность реализовать сборку и отправку всей интересующей нас статистики непосредственно хранилищем — начиная с количественных характеристик хранимых данных и количества запросов до потребляемых каждым из шардов ресурсов. Это позволяет не только в реальном времени следить за состоянием хранилища, но и, в случае необходимости, отслеживать аномалии в его работе и их причины.
Остановимся на структуре горячего хранилища подробнее. Виды скомпрометированности представлены тремя различными space’ами в Tarantool’е:
-
weak_paswords — хеши слабых паролей (qwerty, p@ssword), заполняется единожды словарём слабых паролей;
-
bonds — пары логин-хеш, присутствующие в утечках, заполняется вручную посредством публичных данных об утечках;
-
predicted — пары логин-хеш, которые использовались пользователем ранее и с которыми в учётной записи была замечена зловредная активность (явный взлом, рассылка спама), заполняется автоматически в момент аутентификации пользователя.
bonds помимо логина и хеша пароля хранит принадлежность каждой пары к тому или иному списку. Это позволяет управлять работой сервиса в целом — при появлении новой публичной информации об утечке:
-
данные загружаются в холодное хранилище;
-
валидная часть данных нормализуется, хешируется и переносится в горячее хранилище;
-
новый список находится в состоянии “off” — данные из него не считаются компрометирующими пользователей;
-
после окончания загрузки список переводится в режим “shadow” — так мы можем оценить, сколько пользователей скомпрометировано в новой утечке, не осуществляя действий по ограничению доступа к учётной записи;
-
в ручном режиме список переводится в режим “on” — данные из такого списка считаются скомпрометированными.
Переход из режима “shadow” в “on” выполняется по определённому регламенту, однако может быть выполнен незамедлительно, если, например, количество запросов со скомпрометированными паролями аномально возрастает в ходе работы, что будет свидетельствовать о том, что данные из утечки начали использоваться злоумышленниками для получения доступа к учётным записям в нашем сервисе.
Итоговая схема данных в Tarantool получилась следующая:
local TNL_BOND_PASSWORD_HASH = 1 local TNL_BOND_USERNAME = 2 local s = box.schema.create_space('tnl_bonds', {if_not_exists = true}) s:create_index('password_hash__username', { type = 'tree', parts = {TNL_BOND_PASSWORD_HASH, 'string', TNL_BOND_USERNAME, 'string'}, if_not_exists = true, }) local TNL_WP_PASSWORD_HASH = 1 s = box.schema.create_space('tnl_weak_passwords', {if_not_exists = true}) s:create_index('password_hash', { type = 'tree', parts = {TNL_WP_PASSWORD_HASH, 'string'}, if_not_exists = true, }) local TNL_PREDICTED_PASSWORD_HASH = 1 local TNL_PREDICTED_USERNAME = 2 local s = box.schema.create_space('tnl_predicted', {if_not_exists = true}) s:create_index('password_hash__username', { type = 'tree', parts = {TNL_PREDICTED_PASSWORD_HASH, 'string', TNL_PREDICTED_USERNAME, 'string'}, if_not_exists = true, })Сервис проверки на скомпрометированность
В настоящий момент аутентификация реализована на языке C, однако новый сервис решено было писать на Go — язык изначально заточен под многопоточные backend-приложения и высокую нагрузку, что идеально нам подходит. Также есть готовые интеграции для всего стека технологий, которые нам требуются.
В качестве протокола для общения между C и Go был выбран gRPC — в сравнении с классическим REST API этот протокол передаёт данные более оптимальным образом, что особенно важно, раз мы предполагаем высокую нагрузку и хотим выжать максимум производительности из существующих решений. Кроме того, это позволяет жёстко задавать API для сервисов с помощью .proto-файлов. Генератор соответствующих обвязок кода реализован под большинство популярных языков программирования, включая Go и C — отлично, это то, что нам нужно.
Ниже приведен API в формате protobuf, который используется в gRPC, рассмотрим его подробнее:
-
параметры в запросе:
-
Username— логин пользователя; -
Password— пароль, с которым авторизуется пользователь.
-
-
параметры в ответе:
-
Weak(true/false) — нашли пару логин-пароль либо просто переданный пароль в любом из спейсов Taneleer. -
LookupInfoBonds— если переданный пароль найден в спейсе bonds-
Weak(true/false) — нашли пару логин-пароль в любом из списков из публичных утечек.
-
-
LookupInfoWeakPasswords— если переданный пароль найден в спейсе weak password:-
Weak(true/false) — нашли переданный пароль в спейсе со списком слабых паролей.
-
-
LookupInfoPredicted— если переданный пароль найден в спейсе predicted:-
Weak(true/false) — нашли пару логин-пароль в спейсе со списком пар логин-пароль, с которыми была замечена аномальная активность в аккаунте.
-
-
Описание протокола
syntax = "proto2"; package taneleer; message LookupReq { optional string Username = 1; optional string Password = 2; } message LookupInfoBonds { optional bool Weak = 1; } message LookupInfoWeakPasswords { optional bool Weak = 1; } message LookupInfoPredicted { optional bool Weak = 1; } message LookupResp { optional bool Weak = 1; optional LookupInfoBonds InfoBonds = 2; optional LookupInfoWeakPasswords InfoWeakPasswords = 3; optional LookupInfoPredicted InfoPredicted = 4; } service Search { rpc Lookup(LookupReq) returns (LookupResp) {} }Сначала переданные на проверку данные пользователей нормализуются. Это необходимо для того, чтобы иметь возможность нечёткого сравнения для более продвинутого credential stuffing, но попутно экономит место в хранилище.
Алгоритмы нормализации пароля и логина были спроектированы на основе анализа инструментов, которыми пользуются злоумышленники, и опыта, полученного при расследовании взломов пользователей с использованием модификации исходных данных из утечек. В качестве алгоритма нормализации пароля мы решили использовать следующую последовательность действий:
-
Перевод пароля в нижний регистр.
-
Выделение в пароле всех подстрок, состоящих из “[a-z]”.
-
Для каждой подстроки:
-
Удаление повторяющихся подряд символов.
-
Если длина подстроки после этого <= 3, то замена подстроки на “X”.
-
Иначе удаление последнего символа, замена предпоследнего и первого на “X”.
-
-
Выделение в пароле всех подстрок, состоящих из цифр.
-
Для каждой подстроки:
-
Удаление повторяющихся разрядов.
-
Если длина подстроки после этого <= 3, то замена подстроки на “Z”.
-
Иначе удаление последнего разряда, замена предпоследнего и первого на “Z”.
-
Условный результат работы:
-
На входе “P@ssword1”.
-
На выходе “X@XwoXZ”.
Например, qwerty123 и Qwertz139 будут иметь совпадающую нормализованную форму, также при сравнении будет обнаружено сходство между qwerty12 и qwerty123.
Пример реализации на Go:
Нормализация пароля пользователя
func toLowerPrintableASCII(in, out []byte) ([]byte, bool) { for i := 0; i < len(in); i++ { if in[i] > unicode.MaxASCII || !unicode.IsPrint(rune(in[i])) { return out[0:0], false } out[i] = byte(unicode.ToLower(rune(in[i]))) } return out, true } func trickyTrim(in, out []byte, sym byte, belongs func(byte) bool) []byte { if len(in) == 0 { return out[0:0] } inside, start, j := belongs(in[0]), 0, 1 out[0] = in[0] for i := 1; i < len(in)+1; i++ { shouldCopy, hit := true, false if i < len(in) { hit = belongs(in[i]) } switch { case inside && hit: if out[j-1] == in[i] { shouldCopy = false } case inside && !hit: if j-start > 3 { out[start] = sym out[j-2] = sym j-- } else { out[start] = sym j = start + 1 } case !inside: if hit { start = j } } inside = hit if shouldCopy && i < len(in) { out[j] = in[i] j++ } } return out[:j] } func NormalizePassword(in, out []byte) ([]byte, bool) { if out == nil { out = make([]byte, len(in)) } if len(in) == 0 { return out[0:0], true } out, ok := toLowerPrintableASCII(in, out) if !ok { return nil, false } out = trickyTrim(out, out, 'X', func(c byte) bool { return c >= 'a' && c <= 'z' }) out = trickyTrim(out, out, 'Z', func(c byte) bool { return c >= '0' && c <= '9' }) return out, true }После того, как пароль был нормализован, он хешируется с помощью SHA256.
В качестве алгоритма нормализации логина мы используем следующую последовательность действий:
-
Отброс домена (это необходимо на тот случай, если запрос на проверку будет выполнен с передачей полного email’а пользователя).
-
Перевод логина в нижний регистр.
-
Удаление из логина всех спецсимволов.
-
Выделение в логине всех подстрок, состоящих из цифр.
-
Для каждой подстроки:
-
Удаление повторяющихся разрядов.
-
Если длина подстроки после этого <= 3, то замена подстроки на “0”.
-
Иначе удаление последнего разряда, замена предпоследнего и первого на “0”.
-
Условный результат работы:
-
На входе “vasya-1@mail.ru”.
-
На выходе “vasya0”.
Пример реализации на Go:
Нормализация имени пользователя
func NormalizeUsername(in, out []byte) ([]byte, bool) { if out == nil { out = make([]byte, len(in)) } if len(in) == 0 { return out[0:0], true } out, ok := toLowerPrintableASCII(in, out) if !ok { return nil, false } out = trimDomain(out) out = cutNonAlphaNumericalASCII(out) out = trickyTrim(out, out, '0', func(c byte) bool { return c >= '0' && c <= '9' }) } return out, true
Наличие операций нормализации и хеширования позволили нам использовать наш сервис для решения не менее интересной задачи, которая нам поступила во время проектирования системы от коллег из другого отдела. Об этом в скором времени будет отдельная подробная статья.
Ресурсы
Новый сервис, а точнее его часть на Go, согласно современным тенденциям подняли в k8s, на текущий момент это 15 pod’ов. Конфигурация ресурсов на один под следующая:
request_cpu: 0.5 request_memory: 512Mi limit_cpu: 1 limit_memory: 1GiЭтого хватает, чтобы держать всю нагрузку с n-кратным запасом по количеству запросов.
Tarantool’ы разместили на четырёх «тазиках» (2×6230 CPU, 1 TB RAM) парами в двух ЦОД’ах:
-
ЦОД #1:
-
мастера первых 12 шардов;
-
реплики вторых 12 шардов.
-
-
ЦОД #2:
-
мастера вторых 12 шардов;
-
реплики первых 12 шардов.
-
Для распределения нагрузки на горячее хранилище было принято решение разделить роли между несколькими экземплярами Tarantool’а. Так, мы имеем два мастер-инстанса, в которые производится добавление новых списков с утечками, и две реплики, используемые в работе сервиса для чтения — такая организация позволила нивелировать влияние загрузки новых списков на работу сервиса в целом.
Как с этим всем работать
Регламент взаимодействия с системой получился на порядок более простым, в сравнении с тем, что было раньше:
-
Аналитик обнаруживает публично доступную утечку.
-
Скачивает, первично анализирует и обрабатывает. Это необязательное, но крайне рекомендуемое действие, которое может выглядеть как что-то вроде:
perl -p -e 'use open ":std", ":encoding(UTF-8)"; $_;' | python3 -c 'import html, urllib.parse, sys, itertools; [print(html.unescape(urllib.parse.unquote(line)), end="") for line in itertools.islice(sys.stdin, None)]' | perl -p -e 's/[^[:ascii:]]//g' | sed 's/[^[:print:]]//g' | sed 's/ //g' | awk '{if (index($0,";") == 0 && index($0,":") != 0) {sub(":"," ",$0); print $0} else if (index($0,":") == 0 && index($0,";") != 0) {sub(";"," ",$0); print $0} else if (index($0,":") < index($0,";")) {sub(":"," ",$0); print $0} else {sub(";"," ",$0); print $0}}' | sed 's/^\( \)\1*//g' | sed 's/\( \)\1*/\1/g' | sed 's/^\(@\)\1*//g' | awk '{n = split(tolower($1), line, "@"); split(line[1], user, "+"); if (user[1] ~ /^[[:alnum:]\._-]+$/ && user[1] !~ /^[\._-]+$/ && length(user[1]) < 32) {if (n > 1 && line[n] ~ /^([[:alnum:]\._-]+\.)?[[:alnum:]\._-]+\.[[:alpha:]]+$/) {print user[1]"@"line[n], $2} else {print user[1], $2}}}' | grep -iv " [a-f0-9]\{8\}-[a-f0-9]\{4\}-[a-f0-9]\{4\}-[a-f0-9]\{4\}-[a-f0-9]\{12\}\| \$[a-z0-9]\$\| \$[0-9][a-z]\$\| \$hex\| \$apr[0-9]\$\| \!md5\!" | awk '{ if ($2 ~ /[a-f0-9]{28,40}/ || $2 ~ /[A-F0-9]{28,40}/) { gsub(/[a-fA-F0-9]{28,40}/, "", $2) }; print $0 }' | awk '{ if (length($2) > 2 && length($2) < 41 && $2 !~ /@([[:alnum:]\._-]+\.)?[[:alnum:]\._-]+\.[[:alnum:]]+([;:\s])?/ ) print $0 }' | sort -u > leak.list-
Загружает полученный список в холодное хранилище через панель управления (режим работы списка после загрузки по умолчанию “shadow”).
-
Анализирует результаты проверок:
-
общую нагрузку на сервис, количество потребляемых ресурсов и т.д.;
-
количество и результат проверок логинов и паролей по каждому списку в отдельности.
-
-
Переключает режим работы списка в “on”.
Как это видит пользователь
Пользовательское взаимодействие с сервисом выглядит следующим образом:

Результаты
Новый сервис используется в момент аутентификации пользователя — после успешной проверки валидности пары логин-пароль, она передаётся новому сервису для проверки на скомпрометированность. Это позволяет отказаться от «офлайн»-брутфорса, нам больше не нужно перебирать все записи из утечек в попытках ткнуть пальцем в небо скомпрометированного пользователя.
Информирование пользователей о том, что они находятся в зоне риска, происходит при выполнении ими целевого действия, что увеличивает конверсию в смену пароля, и при этом снижает вероятность неправомерного или случайного доступа к аккаунту.
Автоматическое наполнение хранилища учётными записями заблокированными за подозрительную активность позволяет нам минимальными средствами увеличить покрытие, потому что наш процесс предполагает получение утечек, находящихся в публичном доступе, без сотрудничества с сомнительными сервисами, торгующими оными.
Теперь у нас есть единое хранилище для проверки пароля в момент регистрации и его смены пользователем, что не позволяет регистрировать новые или превращать уже зарегистрированные учётные записи в записи с заведомо слабым или скомпрометированным паролем, и помогает расходовать меньше ресурсов на поддержку и эксплуатацию нескольких отдельных решений.
Подробные графики в мониторинге позволяют не просто оценивать количество скомпрометированных пар логин-пароль, но и видеть возможные аномалии в распределении результатов проверок и оперативно реагировать на них.

Говоря о цифрах:
-
После включения режима “shadow” мы увидели, что около 8 % всех попыток аутентификации выполняются с паролями, которые обнаружены в утечках.
-
Конверсия седьмого дня в смену пароля после ограничения доступа к аккаунту составляет 65 %, что примерно в 20 раз больше, чем если показывать пользователю даже самые навязчивые уведомления в живой сессии.
-
1 % пользователей, которые столкнулись с ограничением доступа, демонстративно не хотят менять пароль.
-
Полный цикл обработки утечки от «найти» до «обезвредить» сократился на порядки, в сравнении с техниками, применяемыми ранее, что позволило направить освободившиеся человеческие ресурсы на другие, не менее важные задачи.
Над сервисом, о котором мы рассказали, работал большой коллектив – это команды:
-
разработки API Почты
-
разработки авторизации Почты
-
кросс-проектной разработки Почты
-
веб-разработки
-
тестирования
-
информационной безопасности.
Также хотим рассказать, что 3-4 сентября у нас пройдет Weekend Offer для frontend, backend и mobile-разработчиков. Если ты хочешь стать частью нашей команды и решать не менее интересные задачи, этого можно достичь всего за одни выходные!

ссылка на оригинал статьи https://habr.com/ru/company/vk/blog/684626/
Добавить комментарий