
Компания Hostkey предоставляет серверы в аренду — это накладывает на нас, сотрудников компании, обязательства по контролю качества работы оборудования. Одним из ключевых элементов поддержания большой инфраструктуры является эффективная система мониторинга, позволяющая оперативно выявлять сбои в работе серверов. Мы хотим поделиться нашим опытом внедрения и использования различных инструментов, позволяющих отслеживать работу оборудования.
В этой статье мы кратко рассмотрим варианты установки федерации Prometheus, Alertmanager и Node Exporter, остановимся на некоторых особенностях и конфигурации. Можно использовать установку из docker-compose файла или же развернуть систему в Kubernetes-кластере. Наша задача — собирать метрики серверов и сервисов инфраструктуры компании, хранить их, реагировать на алерты. Для решения этих задач необходима база данных.
Мы выбрали Prometheus по ряду причин:
-
это популярный инструмент с обширной документацией и большим сообществом;
-
открытый исходный код, написанный на Golang;
-
совместим c Docker и т. д.
Prometheus представляет собой систему мониторинга систем и служб. Он собирает метрики от настроенных целей через заданные временные интервалы, оценивает выражения правил, отображает результаты и может запускать оповещения при соблюдении определенных условий. Для установки всех компонентов системы мы используем ansible-playbook.
Одной из особенности нашей компании является geo-распределенная инфраструктура: HOSTKEY располагает оборудованием в нескольких ЦОДах в Москве, Амстердаме и Нью-Йорке. Иерархическая федерация позволяет серверу Prometheus собирать выбранные временные ряды с другого сервера Prometheus, а также масштабироваться до сред с множеством центров обработки данных и узлов. В этом случае топология федерации напоминает дерево, где серверы Prometheus более высокого уровня собирают агрегированные данные временных рядов с большего числа подчиненных серверов.
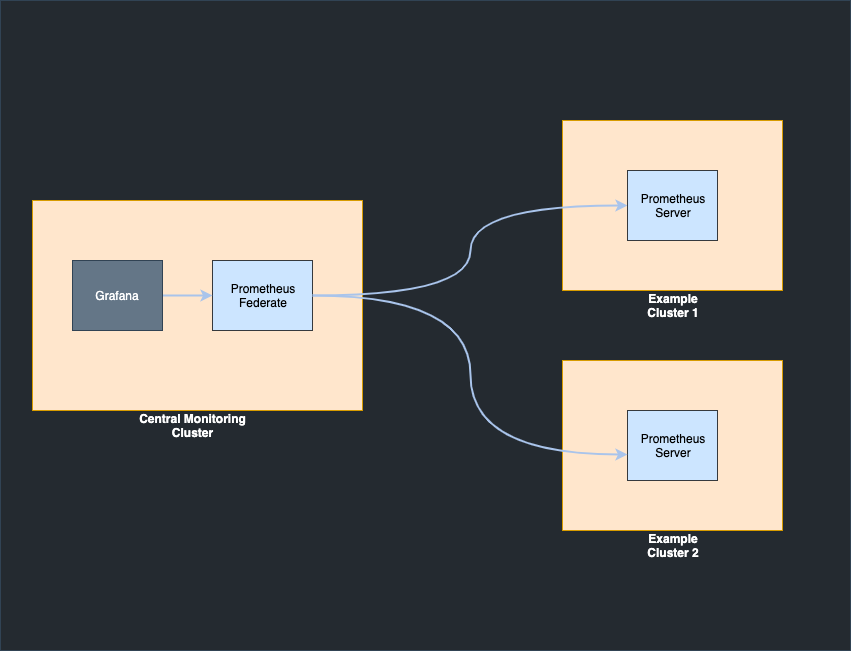
Пример конфигурации с объединения метрики с одного сервера на другой:
scrape_configs: - job_name: 'federate' scrape_interval: 15s honor_labels: true metrics_path: '/federate' params: 'match[]': - '{job="prometheus"}' - '{__name__=~"job:.*"}' static_configs: - targets: - 'ru-<instance_address>:9090' - 'nl-<instance_address>:9090' - 'us-<instance_address>:9090'В качестве источника базовых метрик для Prometheus используется Node Exporter — http-приложение, собирающее метрики операционной системы.
Prometheus собирает данные с одного или нескольких экземпляров Node Exporter (о том, как написать собственный экспортер, расскажем в следующих статьях). Node Exporter должен быть установлен на каждом хосте.
После запуска метрики доступны на 9100 порту:
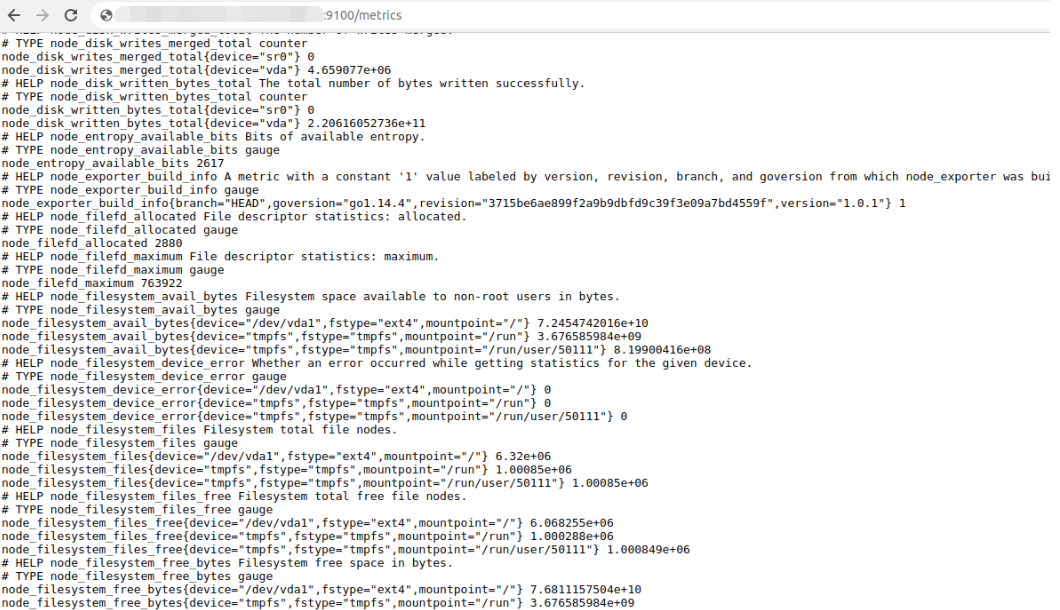
Чтобы метрика попала в базу Prometheus, необходимо описать конфигурацию в файле:
ru-federation-app01a / # vim /etc/prometheus/prometheus.yml
- job_name: 'infra.hostkey' static_configs: - targets: - <instance_address>:9100 - <instance_address>:9100 - <instance_address>:9100Файл должен быть в формате .yaml (управление конфигурацией мы рассмотрим в следующих статьях).
После рестарта сервиса Prometheus можно открыть его пользовательский интерфейс в браузере «<server_address>:9090». На странице «/targets» отображается статус систем, с которых вы получаете метрики.

Визуализация
Grafana — фронтенд к различным time series db: Graphite, InfluxDB, Prometheus — с красивыми и понятными графиками, а самое главное — с множеством шаблонов, подходящих для 90% возможных задач. Формат .json позволяет легко дорабатывать графики. Для удобства проксируем порт Grafana через nginx и подключаем ldap-авторизацию.
Почти все значения Node Exporter по умолчанию представлены в виде графика. Импортируем дашборд:
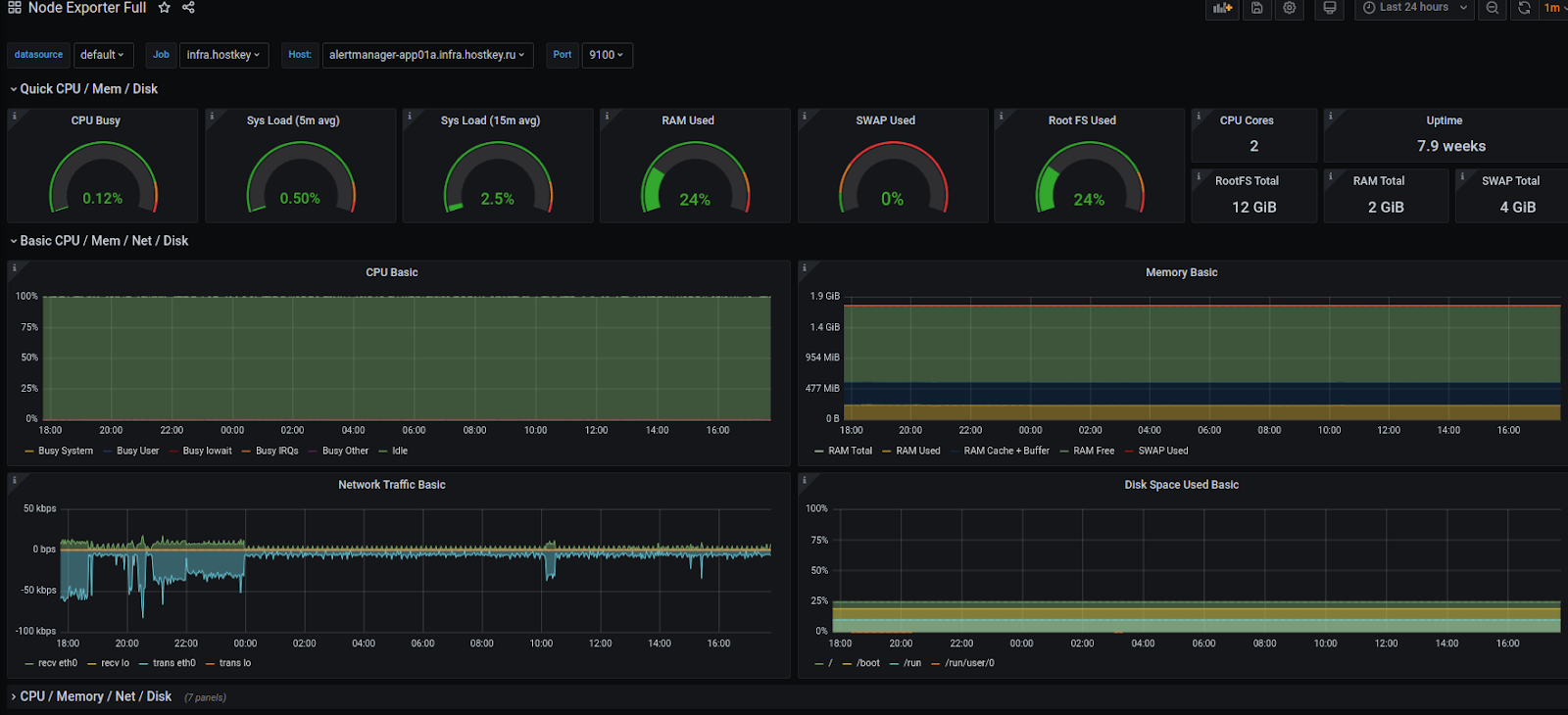
Отображение алертов
Создаем конфигурацию правил алертов <instance_address>.yml.
По сути, можно управлять алертингом любого параметра, доступного в node_exporter:
groups: - name: <instance_address> rules: - alert: InstanceDown expr: up{job="<instance_address>"} == 0 for: 5m labels: severity: page annotations: summary: "Instance {{ .instance }} down" description: "{{ .instance }} of job {{ .job }} has been down for more than 5 minutes." #==========CPU================================================================== - alert: NodeCPUUsage expr: (100 - (irate(node_cpu{mode="idle", job="<instance_address>"}[5m]) * 100)) > 50 for: 2m labels: severity: page annotations: summary: High CPU usage detected CPU usage is above 75% # ==============Memory========================================================== - alert: NodeSwapUsageSwap expr: (((node_memory_SwapTotal-node_memory_SwapFree{job="<instance_address>"})/node_memory_SwapTotal{job="<instance_address>"})*100) > 30 for: 2m labels: severity: page annotations: summary: Swap usage detected Swap usage usage is above 50% - alert: NodeMemoryUsageMemFree expr: (((node_memory_MemTotal-node_memory_MemFree-node_memory_Cached{job="<instance_address>"})/(node_memory_MemTotal{job="<instance_address>"})*100)) > 30 for: 2m labels: severity: page annotations: summary: High memory usage detected, Memory usage is above 50% #==============Load============================================================= - alert: nodeLoad1 expr: node_load1{job="<instance_address>"} > 0.7 for: 1m labels: severity: page annotations: summary: Load #================Dis space Used ================================================ - alert: diskSpaceUsed expr: (100.0 - 100 * (node_filesystem_avail{job="<instance_address>"} / node_filesystem_size{job="<instance_address>"})) > 80 for: 10m labels: severity: page annotations: summary: Disk space userd 80 #=============nodeContrack======================================== - alert: nodeContrack expr: node_nf_conntrack_entries{job="<instance_address>"} > 200 for: 10m labels: severity: page annotations: summary: nodeContrack #=============nodeCntextSwitches ======================================== - alert: nodeCntextSwitches expr: irate(node_context_switches{job="<instance_address>"}[5m]) > 100 for: 5m labels: severity: page annotations: summary: nodeCntextSwitches #=============Disk Utilization per Device ======================================== - alert: DiskUtilizationPerDevice expr: irate(node_disk_io_time_ms{job="<instance_address>"}[5m])/10 > 0.2 for: 5m labels: severity: page annotations: summary: DiskUtilizationPerDevice #============Disk IOs per Device ======================================== - alert: DiskIOsPerDeviceRead expr: irate(node_disk_reads_completed{job="<instance_address>"}[5m]) >10 for: 5m labels: severity: page annotations: summary: DiskIOsPerDevice - alert: DiskIOsPerDeviceWrite expr: irate(node_disk_writes_completed{job="<instance_address>"}[5m]) > 10 for: 5m labels: severity: page annotations: summary: DiskIOsPerDevice #===========Disk Throughput per Device======================================== - alert: DiskThroughputPerDeviceReads expr: irate(node_disk_sectors_read{job="<instance_address>"}[5m]) * 512 >10000000 for: 5m labels: severity: page annotations: summary: DiskIOsPerDevice - alert: DiskThroughputPerDeviceWrites expr: irate(node_disk_sectors_written{job="<instance_address>u"}[5m]) * 512 > 10000000 for: 5m labels: severity: page annotations: summary: DiskIOsPerDevice #===========Network Traffic======================================== - alert: NetworkTrafficReceive expr: irate(node_network_receive_bytes{job="<instance_address>"}[5m])*8 > 5000 for: 5m labels: severity: page annotations: summary: NetworkTrafficReceive - alert: NetworkTrafficTransmit expr: irate(node_network_transmit_bytes{job="<instance_address>"}[5m])*8 > 5000 for: 5m labels: severity: page annotations: summary: NetworkTrafficTransmit #===========Netstat======================================== - alert: Netstat expr: node_netstat_Tcp_CurrEstab{job="<instance_address>"} > 20 for: 5m labels: severity: page annotations: summary: Netstat #===========UDP Stats============================ - alert: UDPStatsInDatagrams expr: irate(node_netstat_Udp_InDatagrams{job="<instance_address>"}[5m]) > 50 for: 5m labels: severity: page annotations: summary: UDPStats - alert: UDPStatsInErrors expr: irate(node_netstat_Udp_InErrors{job="<instance_address>"}[5m]) > 20 for: 5m labels: severity: page annotations: summary: UDPStats - alert: UDPStatsOutDatagrams expr: irate(node_netstat_Udp_OutDatagrams{job="<instance_address>"}[5m]) > 50 for: 5m labels: severity: page annotations: summary: UDPStats - alert: UDPStatsNoPortsл expr: irate(node_netstat_Udp_NoPorts{job="<instance_address>"}[5m]) > 20 for: 5m labels: severity: page annotations: summary: UDPStats Конфигурацию алерта подключаем в prometheus.yml:
rule_files:
— «<instance_address>.yml»
Alertmanager
Перенаправить алерты можно почти в любую систему: email, Telegram, Slack, Rocket.Chat.
alerting: alertmanagers: - static_configs: - targets: - alertmamager-app01a.infra.hostkey.ru:9093Пример для Rocket.Chat:
alertmanager-app01a ~ # vin /etc/alertmanager/alertmanager.yml route: repeat_interval: 5m group_interval: 5m receiver: 'rocketchat' receivers: - name: 'rocketchat' webhook_configs: - send_resolved: false url: 'https://chat_address/hooks/devtest' Рассмотрим основное содержание конфигурационного файла:
global: route: group_by: ['по каким параметрам группировать правила'] group_wait: "время ожидания перед отправкой уведомления для группы" group_interval: "время отправки повторного сообщения для группы" repeat_interval: "время до отправки повторного сообщения" receiver: "имя способа отправки сообщений" receivers: - name: "имя способа отправки сообщений" конфигурацияВсе алерты, поступившие в AlertManager, необходимо группировать, чтобы не отправлять информацию об одних и тех же событиях несколько раз. Директива group_by указывает, какие поля использовать во время группировки. После создания новой группы алертов к делу подключается параметр group_wait. Он указывает время ожидания перед отправкой первого сообщения. Параметр позволяет получить одним сообщением всю совокупность алертов группы, а не отдельное сообщение для каждого алерта.
Параметр group_interval указывает, сколько необходимо ждать после отправки первого сообщения для группы до отправки повторных сообщений из этой же группы. Однако не только он влияет на интервал между сообщениями, еще есть параметр repeat_interval, который указывает, через какой промежуток времени можно повторить отправку того же алерта.
Получаем:
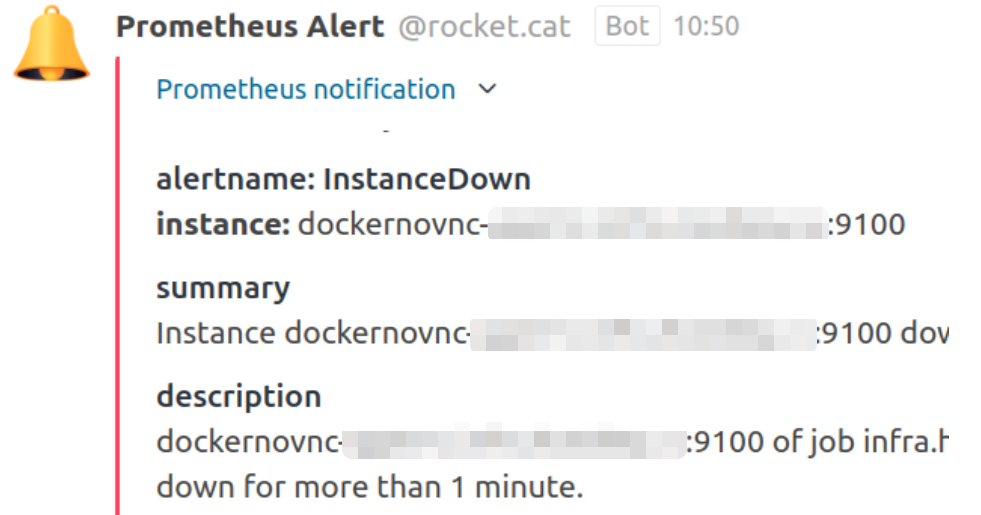
Prometheus AlertManager
Панель инструментов для визуализации на основе одного дашборда в нашей компании используется для мониторинга дежурной сменой:
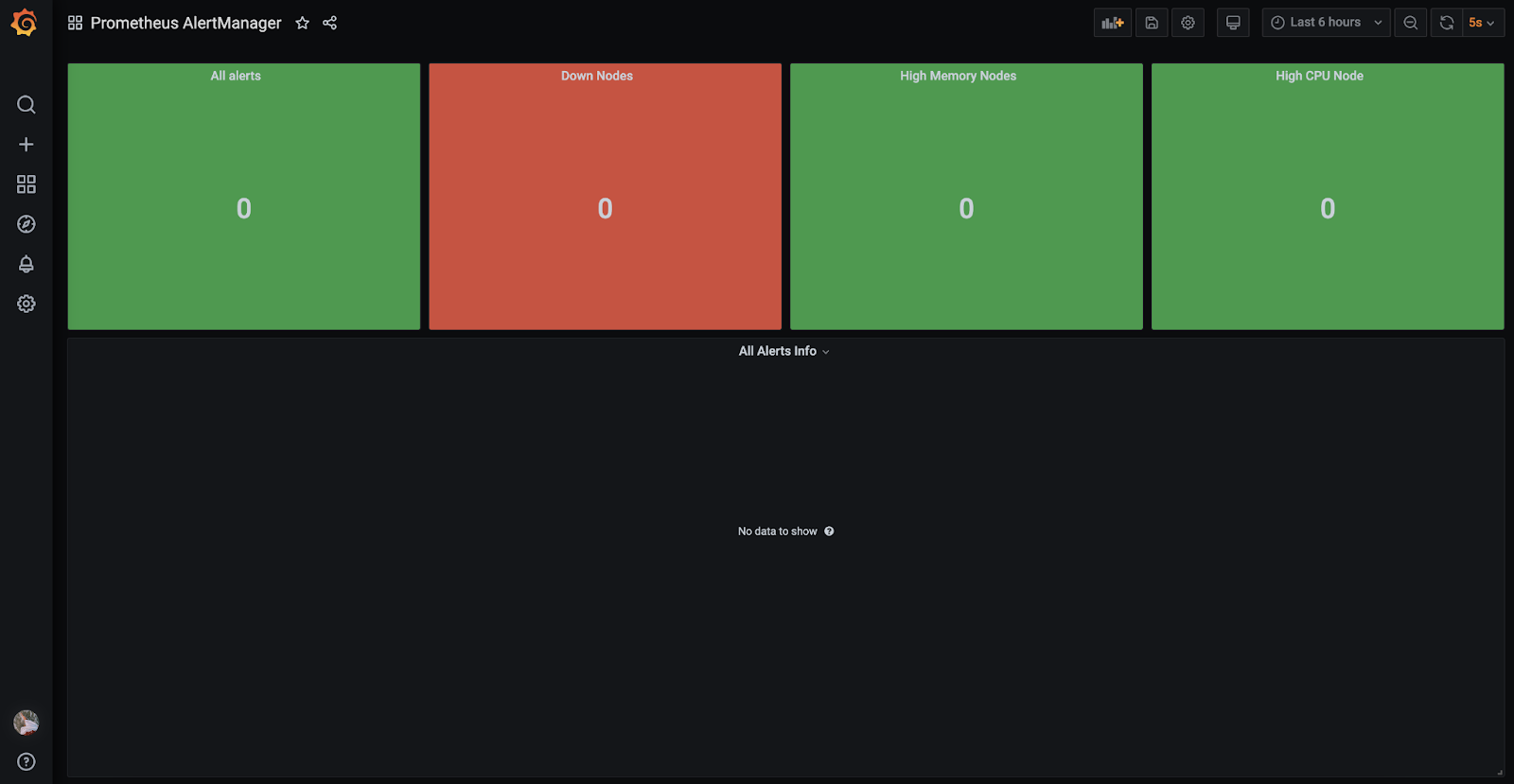
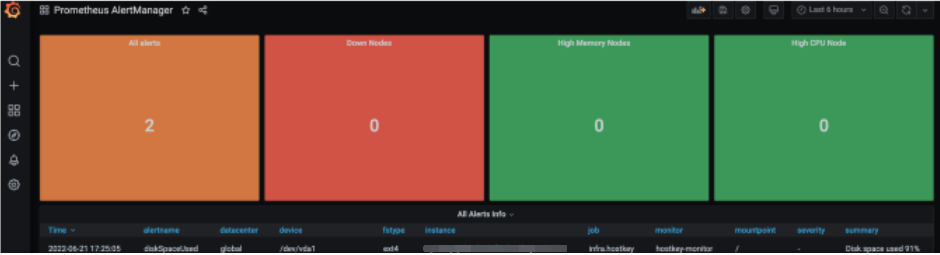
В результате мы получили рабочую систему мониторинга для geo-распределенной инфраструктуры, которую в дальнейшем адаптировали к нашей специфике (об этом опыте расскажем в следующих статьях). Гибкость настроек описанных сервисов позволяет адаптировать систему мониторинга под конкретные нужды любой компании и значительно снизить трудозатраты инженеров и иных специалистов на поддержание инфраструктуры.
ссылка на оригинал статьи https://habr.com/ru/company/hostkey/blog/695726/
Добавить комментарий