Сталкивались ли вы хоть раз с ситуацией, когда входящий поток работы огромный, заказчиков много, приоритеты непонятны, при этом на той стороне провода клиент ждет решения проблемы?
Меня зовут Андрей Сидоренко и я главный специалист по процессному управлению в REG.RU. Я хотел бы рассказать о том, как мы решали вполне типичную для большинства крупных IT-компаний проблему.
Суть проблемы заключается в большом количестве поступающих в разработку запросов (инцидентов) от служб поддержки и клиентов, которые нужно быстро и по понятным правилам отсортировать, расставить приоритеты, и направить самые нужные в те команды разработки, которые имеют нужные компетенции для решения.
С этой проблемой я столкнулся примерно два года назад. В то время в разработку поступало 200-350 подобных инцидентов ежемесячно. Они неконтролируемо распределялись по всей компании без четких правил и сроков, и было непонятно, кто, как и когда должен их реализовывать, и нужно ли их вообще реализовывать. Нередко возникал вопрос: а почему простые инциденты, которые можно решить силами клиентских служб, передаются разработчикам? Профильные продуктовые команды разработки испытывали расфокусировку, потому что в их рабочий поток постоянно и неконтролируемо поступали новые задачи. Случалось и такое, что вместо важных и ценных для бизнеса задач решались мелкие и незначительные.
Нам было важно правильно организовать входящий поток запросов, сделать его предсказуемым для служб поддержки и клиентов, а также разгрузить продуктовые команды, чтобы дать им возможность сфокусироваться на важных для бизнеса фичах. Ниже я расскажу, как мы это сделали при помощи практик канбан-метода и Кайтен.
Дисклеймер
В статье будет много упоминаний Kaiten ― моего основного инструмента для управления потоком. Я, как аккредитованный тренер по канбан-методу, рекомендую его тем, кто уже зашел дальше, чем визуализация и простые лимиты. Это действительно хороший инструмент, не сочтите за рекламу.
1. Создание сервиса по обработке и реализации входящих запросов
Мы создали сервис с собственной командой разработки внутри. Сервис будет принимать все входящие запросы от служб поддержки, отсеивать ненужные, сортировать оставшиеся и передавать в разработку только те, которые действительно необходимо сделать.
Задача внутренней команды разработки состоит в том, чтобы исправить проблему или сделать нужные доработки. В первую очередь разработчики стараются решить боль клиента, а уже во вторую – предотвратить системное повторение ошибки. В случае если внутренняя команда сервиса не может самостоятельно справиться с запросом из-за отсутствия компетенций, то запрос, как и раньше, отправляется в профильную команду, но только уже отсортированный и подготовленный к работе.

В Кайтене мы реализовали две потоковые системы:
-
Upstream ― сортирует задачи и доводит до конкретной разработки с нужным функционалом;
-
Delivery ― исправляет инциденты, чтобы как можно скорее закрыть боль клиента, и старается чинить системно повторяющиеся ошибки. Система должна быть стабильной и прогнозируемой.
Пример
Клиент сообщает сотруднику поддержки об инциденте. Сотрудник понимает, что это к разработчикам и передает его в наш сервис. Об инциденте ничего неизвестно: что это такое, для кого, какой приоритет, надо ли вообще решать инцидент, а если надо, то кто его должен решать ― разработчики или кто-то еще? В Upstream менеджер по специальной матрице вручную сортирует задачи и дает ответы на все эти вопросы. Он присваивает задаче определенные тэги и устанавливает метки в Кайтене, с помощью которых можно ориентироваться в общей массе тикетов и собирать статистику.

У инцидента есть четыре варианта его дальнейшей судьбы:
-
он решается прямо на этом этапе, не дойдя до разработки;
-
мы отказываемся от работы над ним из-за его неактуальности или незначительности;
-
он отправляется на Delivery к разработчикам для решения;
-
он, отсортированный и подготовленный, отправляется к другому исполнителю внутри компании.
2. Upstream ― сортировка задач
Совместно с менеджером, который будет работать в системе, мы спроектировали процесс, который нам показался наиболее подходящим.
Мы выделили этапы, приоритеты, критерии готовности к взятию (Definitions of Done) и собрали из них вот такой флоу:

Все поступающие задачи мы отправляли в него. Так как инциденты начали скопом падать в одно место, то и копились они с огромной скоростью.
Спустя месяц работы нашего сервиса доставки (Service Delivery Review) мы получили обратную связь от служб поддержки. По их мнению, некоторые инциденты более приоритетны по отношению к другим. Но, поскольку матрица приоритетов находится дальше по процессу, важные задачи могли зависать в бэклоге, а добирались мы до них только в порядке очереди.
Для решения этой проблемы мы реализовали простое решение. Чтобы из всего потока выделить те задачи, которые нужно рассмотреть в первую очередь, мы разделили бэклог на две дорожки: «Срочно» и «Не срочно». Оценку срочности задачи доверили клиентским службам, так как на входе они лучше нас знают, что действительно важно. В случае ошибочной оценки дальнейший процесс уточнял критичность и ставил всё на свои места.

Пусть такая первичная сортировка и была основана на субъективном взгляде, но путем эксперимента выяснилось, что она работает ― сотрудники поддержки на уровне ощущений понимают приоритетность задачи и не отправляют в дорожку «Срочно» всё подряд. В итоге такое решение позволило быстрее сообщать о серьезных инцидентах.
3. Delivery ― реализация задач
Система Delivery должна принимать подготовленные задачи из Upstream, чтобы предсказуемо и стабильно их реализовывать. Вот как мы ее проектировали:
-
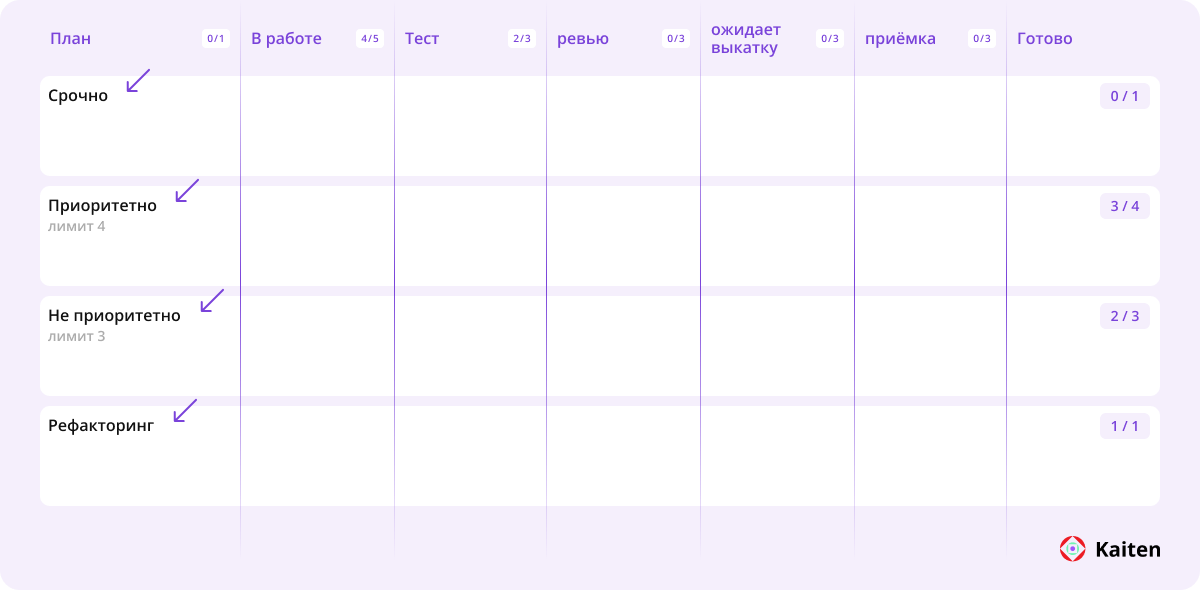
визуализировали реальный рабочий процесс, по которому работали разработчики, с набором этапов «в работе», «ревью», «выкатка» и т. д.;
-
определили и визуализировали классы обслуживания на основании матрицы приоритетов: срочно, приоритетно, не приоритетно, рефакторинг;
-
настроили входной буфер в виде отдельного этапа «План» и договорились, что будем пополнять его ежедневно на дейли-митинге. Чтобы понимать объем пополнения, установили входной лимит, который был рассчитан на основании ежедневной пропускной способности. Таким образом система пополнялась ежедневно, но задачи в плане не протухали;
-
договорились о политиках взаимодействия друг с другом (как делаем ревью, устанавливаем блокировки, тэгируем тикеты и т. д.) и соседними командами. Все скриншоты договоренностей зафиксировали в Кайтене, что сильно помогло в спорных ситуациях. Также обсудили элементы визуализации в тикетах (обязательные чек-листы, описания и т.д.) и мероприятия, которые будем проводить.
В итоге у нас получилась канбан-система, подходящая под наше предназначение: «снижение негатива пользователей от багов и шероховатостей системы». Под негативом мы имеем в виду долгое ожидание решения блокирующих вопросов.
Про дорожку «рефакторинг» стоит сказать отдельно. Рефакторинг не является классом обслуживания (Class of Service). Это скорее тип рабочего элемента (Work Item Type), однако мы решили его визуализировать отдельной дорожкой. Дело в том, что в зоне компетенций данной команды такой работы, как рефакторинг, ранее не было. Но в процессе находились участки легаси-кода, которые был смысл рефакторить. В итоге бэклог с информацией о таких участках потихоньку накапливался. Подобная работа не стоила внимания профильных продуктовых команд разработки, но облегчала жизнь в наиболее нестабильных частях системы. Поэтому мы решили параллельно в небольших объемах делать такую работу.
Такую практику могу порекомендовать тем, кто столкнулся с вечными проблемами, когда незначительный техдолг и рефакторинг копятся на дне бэклога и не получают приоритета.
Теперь важно было систематизировать поток и посмотреть аналитику по нему.
Кроме самой доски Кайтена, мы использовали различные метки, занимались типизацией работы, установкой блокировок и сбором статистики. Благодаря этому мы могли проанализировать работу нашей системы, ее предсказуемость, распределение времени производства (Lead Time) и узкие места.
На основании аналитики мы сделали дашборд с важными для нас метриками:
-
Throughput ― пропускной способностью в период,
-
Lead Time по типам работ и классам обслуживания,
-
данными по количеству и времени блокировок.
Для метрик мы определили целевые и пороговые значения, на которые стали ориентироваться как на ключевые показатели нашего процесса, а также транслировать их заказчикам в качестве внутреннего SLA (Service Level Agreement). Чтобы понимать, как меняется динамика нашей системы и какие есть возможности принятия оперативных решений, данные показатели мы отслеживали 1-2 раза в месяц.
Анализ пропускной способности первого Upstream с момента поступления инцидентов в бэклог до момента, когда рабочие элементы (Work Item) готовы к работе, показал интересную картину.

Оказалось, что из всех инцидентов, поступающих в Upstream, в реальности до разработки должно доходить меньше половины, а часть из них вполне может решаться силами менеджмента и служб поддержки.
В среднем из общего количества входящих инцидентов:
-
около 26% отбрасывалось сразу, не дойдя до Upstream, из-за неактуальности,
-
около 30% отбрасывалось по той же причине, но уже на этапе Upstream,
-
около 13% инцидентов решались силами менеджеров и служб поддержки на Upstream,
-
около 16% отправлялись на Delivery как более приоритетные,
-
около 12% отправлялись на Delivery как менее приоритетные,
-
оставшееся небольшое количество распределялось по другим командам компании.
То есть из числа всех инцидентов за месяц больше 50% были неактуальными. Напомню, что раньше все эти запросы распределялись по внутренним командам разработки, которые тратили время на анализ и исследования по устранению.

Итак, задача Upstream состояла в том, чтобы предотвращать ожидания, задержки, блокировки, а также системно управлять потоком работы, который реализует разработка, максимизируя его ценность. И, кажется, что мы начали нащупывать, как это сделать.
4. Введение WIP-лимитов ― ограничений по количеству одновременно выполняемых задач
На этом этапе я решил настроить распределение емкости (Capacity allocation) при помощи WIP-лимитов. Причем не только по вертикали, но и по горизонтали.
Мы изначально понимали, что сделать абсолютно все задачи не получится. А если делать только приоритетные, мы не доберемся до остальных. Именно поэтому мы и организовали классы обслуживания. А чтобы работа шла управляемо и без перекосов, мы установили WIP-лимиты на дорожки (классы обслуживания).

Это позволило сделать распределение емкости команды на все классы обслуживания, чтобы рабочие элементы не ожидали в бэклоге вечно.
Лимит доски по горизонтали позволил наладить вытягивающую систему, которая сама подсказывала разработчикам, на какую дорожку можно вытягивать задачи в случае освобождения. Меня как менеджера это избавило от ежедневных коммуникаций по вопросам «что взять в работу», «что дальше» и т. д. Свободная емкость системы сама показывала, куда вытягивать следующий рабочий элемент, если в плане пусто.
5. Кластеризация блокеров и задержек (Blocker Clustering)
Нам было важно понимать, что именно является источниками задержек и блокировок в нашей системе, найти наиболее значимые, кластеризовать их и постараться свести к минимуму.
Пример
У нас было много задач, которые блокировались сразу на входе, потому что по ним не хватало какой-то информации. Разработчик берет работу из плана, знакомится с вводными данными и понимает, что не может приступить из-за нехватки данных или явной зависимости. Поскольку работа блокируется, а система обвешана лимитами, встает вопрос о том, что делать дальше. Лимит ― это не просто ограничение, а важный инструмент в создании сигналов о проблемах в нашей системе, поэтому мы достаточно быстро распознали данный источник задержек и приняли меры.
Мы внедрили простую договоренность, по которой каждый день после дейли-митинга (10-15 минут) стали тратить несколько минут на просмотр самых близких к плану рабочих элементов на предмет явных источников задержки. Если рабочие элементы вызывают подозрения, то это сигнал на Upstream о том, что элемент нужно дополнительно доработать до взятия в работу.
В итоге мы на 100% сократили количество задач, которые блокируются сразу на входе, за счет чего время производства по двум классам обслуживания сократилось примерно на один день.
Как мы проводим анализ блокировок задач в Кайтене
Пошагово про наш сбор данных по блокировкам.

-
Нужно явное правило, при котором в карточке ставится блокировка.
-
При блокировке прописывается её контекст. Контекст должен быть понятен всей команде. Если кого-то ждем, то не просто «Ждем», а указываем конкретную причину. Это очень важно.
-
Периодически собираем данные по блокировкам. Например, раз в месяц. Это делается в «Отчете по блокировкам». Я пользовался Excel-версией отчета для кластеризации.
-
Смотрим типы блокировок, их соотношение и на каком этапе они возникали. Например, это можно сделать по тегам в Excel. Так появится понимание, почему задачи блокируются чаще всего. А с этим знанием уже можно придумать решение.
-
После внесения изменений очень важно в следующем месяце снова собрать данные конкретно по этому кластеру блокировок, чтобы понять, работают ли изменения или нет.


Я очень рекомендую проводить такую работу. В Кайтене удобно собирать отчеты по блокировкам. Этот хороший инструмент для понимания и управления источниками вариабельности (изменчивости) вашей системы.
О результатах
Нам удалось создать прозрачную, управляемую и предсказуемую систему. Когда мы только создали команду и поработали первый квартал, мы сняли данные по распределению времени производства по приоритетному классу обслуживания. Взяли 85% как наиболее подходящее значение и посчитали, что 85% рабочих элементов завершается за 12 дней. При этом на контрольной диаграмме в Кайтен наблюдались неоднородные кластеры, что, предположительно, говорило о тех самых источниках вариабельности. Мы понимали, что у нас достаточно большой потенциал для снижения времени производства.
Основные шаги и практики, которые мы применили:
-
гибкая фильтрация и сортировка задач на Upstream по понятным правилам,
-
Capacity allocation и WIP-лимиты в Delivery,
-
анализ блокировок и устранение выявленных проблем,
-
постоянные Service Delivery Review с применением информации, полученной по его результатам,
-
постоянное взаимодействие менеджеров из Upstream и Delivery.
За 3-4 месяца нам удалось сократить время обработки входящих задач с 12 до 7 дней. В настоящее время мы удерживаем его на уровне 6-7 календарных дней.
При этом основной фокус направлен на решение болей клиентов, что в большинстве случаев происходит в течение нескольких часов с момента попадания запроса.


Общие выводы
С помощью применения инструментов канбан-метода и грамотного использования возможностей Kaiten нам удалось разгрузить профильные команды разработки и решить вопрос с непрозрачностью процесса для служб поддержки. За счет такого перераспределения удалось сэкономить на ФОТ значительную сумму ежемесячно.
Кроме того, мы значительно сократили время на коммуникации ― при такой организации не нужно постоянно задавать друг другу вопросы и узнавать, что вообще происходит с проектом. Нам видна вся система целиком. А автоматическая отчетность и графики значительно экономят время менеджеров.
К слову, менеджеру при планировании работы с новой командой, обычно требуется плюс-минус три месяца на то, чтобы понять, как там все устроено, собрать данные и проанализировать их. Если же команда использует инструменты, подобные Kaiten, и все корректно настроено, то порог вхождения сильно ниже. В течение пары дней можно получить данные о том, что происходит и составить предположения о проблемах.
В завершение хочу сказать, что такие инструменты, как Kaiten, действительно экономят много времени при организации потоковых систем. Причем большая часть экономии происходит от применения практик, которые позволяют предотвратить системные проблемы, а не просто их выявить.
Время экономит не сам инструмент, а умение им пользоваться.
ссылка на оригинал статьи https://habr.com/ru/company/regru/blog/696614/
Добавить комментарий