
Исторически так сложилось, что LINQ взыскал сомнительную репутацию за его слабую производительность. LINQ медленный, аллоцирует память, сложно читается, поэтому обычно его используют как инструмент запросов к БД и то, зачастую сложные запросы легче написать на SQL. Даже на собеседованиях джунов просят не использовать LINQ в алгоритмах.
«Я знавал одного разраба, который мог написать запрос абсолютно любой сложности на LINQ, но если надо было что-либо в нём поменять, он писал всё заново» — мой тимлид из EPAM…
Но что если я скажу вам, что с .Net7 всё начнёт меняться. Если вы не были заняты последний год чисткой беклога не поднимая головы, то наверное слышали про новые фичи в .Net6 которые капитально облегчат жизнь разработчикам.
Zip() теперь может совмещать 3 коллекции, ElementAt() теперь может принимать оператор индекса «^» чтобы отсчитывать с конца коллекции, Take() теперь принимает диапазон индексов list.Take(2..6). Также появились новые методы TryGetNonEnumeratedCount(), чтобы не проходиться по коллекции для получения Count, MinBy(), MaxBy(), AvarageBy(), название которых говорит само за себя и новый метод Chunk(), дробящий коллекцию\массив на равные части.
.Net7 же берётся за классические методы и творит с ними чудеса, пока-что особое внимание получили только 4 метода:
.Min()
.Max()
.Average()
.Sum()
И раньше, чтобы выиграть несколько наносекунд на крупных проектах, люди иногда писали собственные методы, что-то на подобии такого
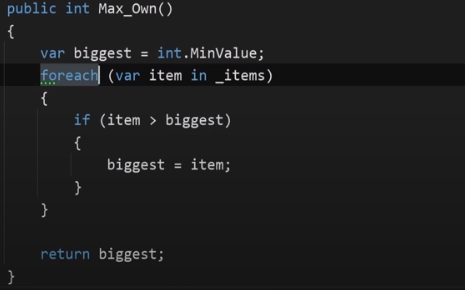
И результат был, но не капитальный. Память всё равно выделялась и написание таких методов раздувало проект.

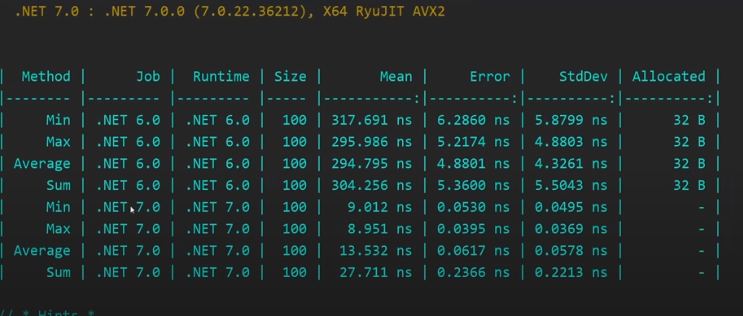
Теперь посмотрим на бенчмарк по одной дженерик коллекции но в разных версиях фреймворка. Net6 и Net7 RC1, все те методы, получившие изменения.

Если мы посмотрим на время выполнения этих методов, то глаза начинают перемещаться на лоб, такого прироста обычно вменяемые люди не ожидают, не говоря уже о том, что в данном случае и память не аллоцируется вовсе!
Надо разобраться. Быть того не может.
Берём для примера реализацию Min() из .Net6, в принципе она не менялась давно.
Для тех кто внезапно не видел реализацию этого метода, вот кодище:

Впринципе всё ожидаемо и ясно как белый день, метод расширения с классической реализацией, даже до конца можно не показывать…
А вот когда мы смотрим реализацию на .Net7, начинается интересное. Тут многое по другому.

Мы не сразу переходим в блок кода, мы видим лямбду на метод MinInteger() куда передаётся коллекция, и уже в нём начинается буст производительности.
Это стало возможным поскольку в методы добавили дополнительное условие:
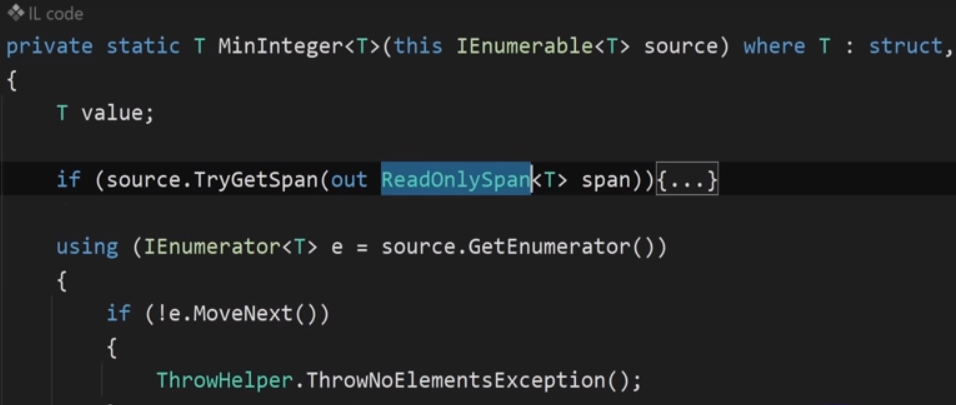


Если начать полностью объяснять процесс векторизации то это займет ещё пару тройку мониторов (Ссылка на полное описание процесса векторизации в конце этой статьи.). Поэтому опишем «грубо говоря»:
Дополнительное условие проверяет, является ли длинна битов нашего полученного Span такой же или больше чем Vector с тем же переданным типом, но умноженным на 2. Это позволяет нам искать не по значению, а по длинам кусков битов нашей непрерывной области памяти, и затем сравнивать только значения совпавших длин с нужным результатом. В итоге мы сокращаем поиск в десятки, а может и в сотни раз так как шанс того, что элементы массива или коллекции будут повально занимать такое же пространство, что и наше желаемое значение, крайне мал.
Также условие IsHardwareAccelerated проверяет возможно ли ускорение процесса со стороны железа. Чтобы вернулось true мы должны быть на х64 платформе, а также в Release моде.

Однако если даже мы в Debug то уже в рантайме параметр вроде как всё равно измениться на true и векторизация сработает.
Так что вот, Microsoft не сидит на месте и я надеюсь что и в дальнейшем они будут радовать нас увеличением производительности и в других методах/библиотеках. Вместо концовки добавлю только скрин бенча по массиву, чтобы глаз ещё раз порадовался.
Почитать про векторизацию можно тут
Скрин бенчмарка и объяснение работы Span<T> на YouTuve каналe Nick Chapsas
2022. Платон Звонков, начинающий разработчик.
ссылка на оригинал статьи https://habr.com/ru/post/697632/
Добавить комментарий