
Мне стало интересно разобраться, как PostgreSQL хранит данные на диске, и в процессе своего исследования я обнаружил несколько интересных фактов, которыми хочу с вами поделиться.
Мы будем рассматривать только файлы кучи (heap). Heap-файл — это просто файл записей. Не путайте heap-файл с heap-памятью. Хотя их использование очень похоже: хранение динамических данных.
Как строки организованы в файлах
PostgreSQL разбивает файлы данных на сегменты. Размер сегмента фиксирован и обычно составляет 1 ГБ, но его можно изменить при компиляции, используя параметр --with-segsize. Когда размер таблицы или индекса превышает 1 ГБ, они разбиваются на сегменты по гигабайту. Такой подход позволяет избежать проблем на платформах с ограничением размера файла, 1 ГБ — очень консервативный выбор для любой современной платформы.
Данные хранятся на страницах фиксированного размера. Размер страницы обычно 8 КБ, который можно изменить при компиляции через параметр --with-blocksize. Хотя изменяют его редко. Страница в 8 КБ — компромисс между производительностью и надежностью. Если размер страницы слишком мал, строки не поместятся внутри страницы, а если слишком большой, существует риск сбоя записи, поскольку оборудование обычно гарантирует атомарность только для блоков фиксированного размера, который может отличаться от диска к диску (обычно в диапазоне от 512 до 4096 байт).
Страницы выглядят следующим образом:
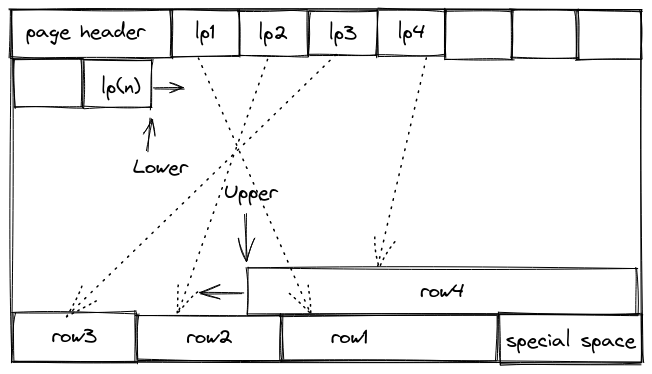
lp(1…N) — массив указателей на строки (line pointer array). Указатель содержит логическое смещение на странице. Поскольку это массив, то все элементы имеют фиксированный размер, но количество элементов на странице может изменяться.
row(1…N) — непосредственно данные. Обычно они переменной длины и для доступа к определенному кортежу используются указатели строк. Строки добавляются от конца к началу страницы, а указатели строк — от начала к концу.
Область special space обычно используется при хранении индексов, например, для ссылок на соседние узлы в B-Tree. Для табличных данных не используется.
Указатели lower и upper указывают занятое пространство на странице. Таким образом, по разности (upper — lower) можно определить, используется страница или нет.
Заголовок страницы (page header) сам по себе не так уж и интересен, он содержит информацию о странице, включая указатели lower и upper. Его структура выглядит следующим образом:
|
Поле |
Размер |
Описание |
|
pd_lsn |
8 байт |
LSN: следующий байт после последнего байта записи xlog для последнего изменения на этой странице |
|
pd_checksum |
2 байта |
Контрольная сумма страницы |
|
pd_flags |
2 байта |
Биты признаков |
|
pd_lower |
2 байта |
Смещение до начала свободного пространства |
|
pd_upper |
2 байта |
Смещение до конца свободного пространства |
|
pd_special |
2 байта |
Смещение до начала специального пространства (special space) |
|
pd_pagesize_version |
2 байта |
Информация о размере страницы и номере версии компоновки |
|
pd_prune_xid |
4 байта |
Самый старый неочищенный идентификатор XMAX на странице или ноль при отсутствии такового |
У такого способа хранения данных есть несколько особенностей:
-
Во-первых, кортежи не могут занимать несколько страниц. Невозможно напрямую хранить очень большие значения полей. Значения больших полей сжимаются и/или разбиваются на несколько физических строк.
-
Во-вторых, максимальное количество столбцов ограничено от 250 до 1600 в зависимости от типа столбца.
-
В-третьих, если вы полагаете, что указав в select только нужные столбцы для таблицы с несколькими столбцами, запрос будет выполняться быстрее из-за меньшего количества дисковых операций ввода-вывода, то это не так.
-
Такой тип хранилища не оптимизирован для аналитических рабочих нагрузок, потому что необходимо считывать с диска данные, не имеющие отношения к запросу. Поэтому большинство аналитических баз данных (OLAP), таких как Vertica, используют колоночное хранилище.
Заглянем внутрь страниц
Давайте попробуем заглянуть внутрь страницы и посмотрим, какие у PostgreSQL есть инструменты для этого. Начнем с создания базы данных и таблицы с дальнейшим заполнением ее некоторыми данными.
postgres=# \c hail_mary ; You are now connected to database "hail_mary" as user "postgres". hail_mary=# hail_mary=# create table users(id int, name text); CREATE TABLE hail_mary=# insert into users(id, name) select i,md5(i::text)::text from generate_series(1, 50000, 1) as i; INSERT 0 50000 hail_mary=# select * from users limit 5; id | name ----+---------------------------------- 1 | c4ca4238a0b923820dcc509a6f75849b 2 | c81e728d9d4c2f636f067f89cc14862c 3 | eccbc87e4b5ce2fe28308fd9f2a7baf3 4 | a87ff679a2f3e71d9181a67b7542122c 5 | e4da3b7fbbce2345d7772b0674a318d5 (5 rows)Для каждой строки PostgreSQL создает внутренний уникальный идентификатор, который обычно не виден пользователям. Но его можно запросить явно.
hail_mary=# select ctid, * from users limit 5; ctid | id | name -------+----+---------------------------------- (0,1) | 1 | c4ca4238a0b923820dcc509a6f75849b (0,2) | 2 | c81e728d9d4c2f636f067f89cc14862c (0,3) | 3 | eccbc87e4b5ce2fe28308fd9f2a7baf3 (0,4) | 4 | a87ff679a2f3e71d9181a67b7542122c (0,5) | 5 | e4da3b7fbbce2345d7772b0674a318d5 (5 rows)Первая цифра в ctid — это номер страницы, а вторая — номер кортежа. Использование физических строк на странице, мы можем наблюдать при запуске VACUUM для дефрагментации страницы. Давайте удалим одну запись и вставим новую.
hail_mary=# select ctid, * from users OFFSET 49995 limit 5; ctid | id | name ----------+-------+---------------------------------- (416,76) | 49996 | 2acfa04df8cc1e5b051866c32f9eb072 (416,77) | 49997 | 87aa98d07ec242cc4d8f685f0299257b (416,78) | 49998 | 12775d2a4498f0ec748a4beed90e5ad2 (416,79) | 49999 | c703af5c89b1d0bc2e99f540f553f182 (416,80) | 50000 | 1017bfd4673955ffee4641ad3d481b1c (5 rows) hail_mary=# hail_mary=# delete from users where name = 'c703af5c89b1d0bc2e99f540f553f182'; DELETE 1 hail_mary=# insert into users VALUES(9999999, 'ryland grace'); INSERT 0 1 hail_mary=# select ctid, * from users OFFSET 49995 limit 5; ctid | id | name ----------+---------+---------------------------------- (416,76) | 49996 | 2acfa04df8cc1e5b051866c32f9eb072 (416,77) | 49997 | 87aa98d07ec242cc4d8f685f0299257b (416,78) | 49998 | 12775d2a4498f0ec748a4beed90e5ad2 (416,80) | 50000 | 1017bfd4673955ffee4641ad3d481b1c (416,81) | 9999999 | ryland grace (5 rows)Здесь мы видим, что PostgreSQL оставил физическую строку с name равным c703af5c89b1d0bc2e99f540f553f182, которая была удалена, и добавил данные на новую физическую строку. Давайте запустим VACCUM.
hail_mary=# VACUUM FULL; hail_mary=# select ctid, * from users OFFSET 49995 limit 5; ctid | id | name ----------+---------+---------------------------------- (416,76) | 49996 | 2acfa04df8cc1e5b051866c32f9eb072 (416,77) | 49997 | 87aa98d07ec242cc4d8f685f0299257b (416,78) | 49998 | 12775d2a4498f0ec748a4beed90e5ad2 (416,79) | 50000 | 1017bfd4673955ffee4641ad3d481b1c (416,80) | 9999999 | ryland grace (5 rows)VACCUM, как и ожидалось, дефрагментировал страницу, переместив кортежи.
Выглядит это следующим образом:



Мы также можем заглянуть внутрь страниц с помощью расширения pageinspect.
hail_mary=# create extension pageinspect; CREATE EXTENSIONВзглянем на последнюю страницу (416).
hail_mary=# select * from page_header(get_raw_page('users', 416)); lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid -----------+----------+-------+-------+-------+---------+----------+---------+----------- 0/428E4F0 | 0 | 0 | 344 | 3088 | 8192 | 8192 | 4 | 0 Указатель lower равен 344, а upper 3088, то есть свободного места на этой странице 2744 байт.
Указатель special указывает на 8192 — это конец страницы. Можно сделать вывод, что данных в special space нет.
Посмотрим еще на предыдущую страницу — мы ожидаем, что на этой странице недостаточно свободного места.
hail_mary=# select * from page_header(get_raw_page('users', 415)); lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid -----------+----------+-------+-------+-------+---------+----------+---------+----------- 0/428CF58 | 0 | 0 | 504 | 512 | 8192 | 8192 | 4 | 0 (1 row)Как и ожидалось, 8 байт недостаточно для хранения id + name.
Также можем заглянуть внутрь элементов страницы, используя следующий запрос:
hail_mary=# select * from heap_page_items(get_raw_page('users', 416)) offset 78 limit 2; lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data ----+--------+----------+--------+--------+--------+----------+----------+-------------+------------+--------+--------+-------+------------------------------------------------------------------------------ 79 | 3136 | 1 | 61 | 11780 | 0 | 0 | (416,79) | 2 | 2818 | 24 | | | \x50c30000433130313762666434363733393535666665653436343161643364343831623163 80 | 3088 | 1 | 41 | 11783 | 0 | 0 | (416,80) | 2 | 2818 | 24 | | | \x7f9698001b72796c616e64206772616365 Ссылки
-
Database Physical Storage — https://www.postgresql.org/docs/9.5/storage.html
-
Расширение PageInspect — https://www.postgresql.org/docs/12/pageinspect.html
-
Row storage in PostgreSQL, heap file page layout — https://www.youtube.com/watch?v=L-dw1yRFYVg
-
Database Storage I (CMU Databases Systems / Fall 2019) — https://www.youtube.com/watch?v=1D81vXw2T_w
Материал подготовлен в преддверии старта онлайн-курса «Базы данных».
ссылка на оригинал статьи https://habr.com/ru/company/otus/blog/699812/
Добавить комментарий