Мы хорошо знаем GAN за успехи в создании реалистичных изображений. Не так хорошо знаем о формировании табличных данных. Однако их возможно применять при одномоментной реализации табличных данных и изображений.
Зачем генерировать одновременно табличные данные и изображение?
Я создал приложение coronarography.ai. На вход нейронной сети подаются структурированные данные (факторы риска развития сердечных заболеваний) и изображение ЭКГ, на выходе получаем патологию магистральных артерий сердца. Мне стало интересно проверить точность прогнозирования обученной нейронной сети на синтетических сгенерированных данных. Почему бы и нет) Проведем аугментацию выборки при помощи GAN и посмотрим точность обученной нейронной сети на синтетических данных. Для этого необходимо эти синтетические данные получить.
Описание проблемы.
Мы имеем структурированные данные. В них содержится информация по каждому наблюдаемому пациенту в виде наличия факторов риска развития сердечно-сосудистых заболеваний в бинарной форме. К каждому наблюдению прикреплено ЭКГ изображение. То есть одному пациенту соответствуют факторы риска и одно изображение ЭКГ, снятое до суток до выполнения инвазивной коронарографии, это данные которые прогнозирует основная обученная нейронная сеть.
Нам необходимо одновременно генерировать структурированные данные (факторы риска и таргеты виде поражения артерий сердца) и картинку — ЭКГ изображение. Я в литературе не встречал подобных примеров, чтобы генерировали одновременно табличные данных и картинку. Что ж, сделаем впервые). Сгенерируем 1500000 синтетических наблюдаемых в виде табличных данных и ЭКГ изображения.
Блок-схема исследования.

Получение синтетических данных при помощи GAN.
На вход генератора подавались 100 рандомных чисел с нормальным распределением. На выходе сгенерировано изображение (200, 200) и структурированные табличные данные размером (1, 35). (одна строка, 35 столбцов). Внутри генератора был обобщающий слой, для сохранения потоковой передачи данных между строкой таблицы и изображением.
На вход дискриминатора подавались сгенерированное изображение размером (200, 200) вместе с реальными ЭКГ-изображениями (200, 200) и сгенерированные табличные данные размером (1, 35) вместе с реальными табличными данными. На выход дискриминатор выдавал бинарную классификацию, соответствующую реальным данным и синтетическим.
Таким образом двум нейронным сетям было необходимо превзойти друг друга. Одна нейронная сеть старалась сгенерировать изображение и таблицу, которые не отличит от реальных дискриминатор. Он, в свою очередь, старался искать признаки характерные для реального изображения и таблицы, чтобы отличить сгенерированные изображения и таблицу от реальных.

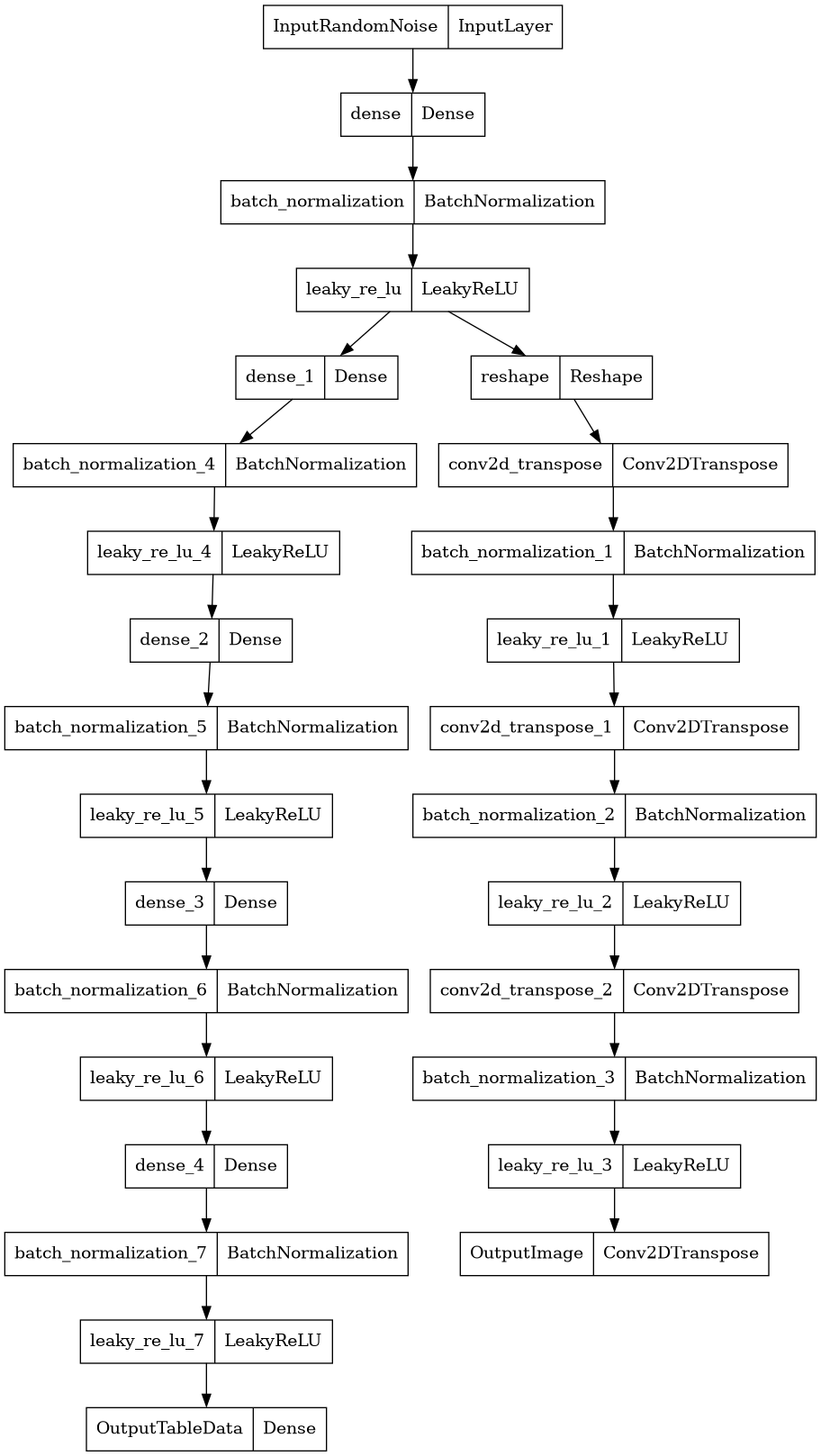
На рисунке представлена структура создаваемой генеративно-состязательной нейронной сети.
Реализация на TensorFlow.
За основу возьмем структуру GAN, описанной в моей статье про генерацию ЭКГ.
Использованные библиотеки
import pandas as pd import glob import imageio import matplotlib.pyplot as plt import numpy as np import os import PIL from PIL import Image from tensorflow.keras import layers import time import tensorflow as tf from IPython import display import seaborn as sns import matplotlib.pyplot as plt import matplotlib.mlab as mlab import matplotlib from matplotlib.pyplot import figure from sklearn.preprocessing import MinMaxScaler import joblib import tensorflow as tf from tensorflow.keras.layers import * from tensorflow.keras.models import Model print(tf.__version__) %matplotlib inline matplotlib.rcParams['figure.figsize'] = (8,6)Загрузка и подготовка набора данных
Здесь мы загружаем изображения ЭКГ из папки в массив. Преобразовываем в одноканальное (черно-белое) изображение, нормализуем его. Проводим небольшую коррективроку и нормализацию табличных данных.
# table data data = pd.read_csv('../AI_coronarography/DATA_WORK/DATA_WORK/DP_cor.csv', sep=';') data.drop(['FIO', 'number_of_affected_coronary_artery'], axis = 1, inplace=True) for i in [ 'trunk_st', 'LAD_st', 'lcx_stenosis', 'RCA_stenosis' ]: data[i] = data[i].apply(lambda x: 1 if x >= 50 else 0) scaler = MinMaxScaler(feature_range=(0, 1)) scaler = scaler.fit(data) data[data.columns] = scaler.transform(data[data.columns]) # image data_image = [] for k in os.listdir('../AI_coronarography/DATA_WORK/DATA_WORK/ЭКГ'): if k.endswith('.jpg'): img = Image.open('../AI_coronarography/DATA_WORK/DATA_WORK/ЭКГ/'+k) img = img.convert('L') img = img.resize((200, 200)) data_image += [(np.array(img) - 127.5) / 127.5]Пример загруженного ЭКГ изображения
Определим размер батча и объединим изображения и структурированные данные для входа в GAN. Перемешаем объединенные ЭКГ изображения и табличные данные.
train_images = np.array(data_image).reshape(np.array(data_image).shape[0], 200, 200, 1).astype('float32') train_data = np.array(data).reshape(np.array(data).shape[0], 35).astype('float32') BUFFER_SIZE = 100 BATCH_SIZE = 10 train_dataset = tf.data.Dataset.from_tensor_slices((train_images, train_data)).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)Создадим генератор
def make_generator_model(): input_1 = Input(shape=(100, ), name = "InputRandomNoise") x = Dense(25*25*256, use_bias=False)(input_1) x = BatchNormalization()(x) conc = LeakyReLU()(x) x = Reshape((25, 25, 256))(conc) x = Conv2DTranspose(256, (5, 5), strides=(1, 1), padding='same', use_bias=False)(x) x = BatchNormalization()(x) x = LeakyReLU()(x) x = Conv2DTranspose(128, (5, 5), strides=(2, 2), padding='same', use_bias=False)(x) x = BatchNormalization()(x) x = LeakyReLU()(x) x = Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False)(x) x = BatchNormalization()(x) x = LeakyReLU()(x) x = Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh', name = "OutputImage")(x) y = Dense(400)(conc) y = BatchNormalization()(y) y = LeakyReLU()(y) y = Dense(200)(y) y = BatchNormalization()(y) y = LeakyReLU()(y) y = Dense(128)(y) y = BatchNormalization()(y) y = LeakyReLU()(y) y = Dense(64)(y) y = BatchNormalization()(y) y = LeakyReLU()(y) y = Dense(35, activation='sigmoid', name = "OutputTableData")(y) model = Model(inputs=input_1, outputs=[x, y]) return model generator = make_generator_model() noise = tf.random.normal([1, 100]) generated_image = generator(noise, training=False)Структура генератора
Создадим дискриминатор
def make_discriminator_model(): input_1 = Input(shape=(200, 200, 1), name = "InputImage") input_2 = Input(shape=(35,), name = "InputTableData") x = Conv2D(64, (5, 5), strides=(2, 2), padding='same')(input_1) x = LeakyReLU()(x) x = Dropout(0.3)(x) x = Conv2D(128, (5, 5), strides=(2, 2), padding='same')(x) x = LeakyReLU()(x) x = Dropout(0.3)(x) x = Conv2D(256, (5, 5), strides=(2, 2), padding='same')(x) x = LeakyReLU()(x) x = Dropout(0.3)(x) x = Conv2D(256, (5, 5), strides=(1, 1), padding='same')(x) x = LeakyReLU()(x) x = Dropout(0.3)(x) x = Flatten()(x) y = Dense(400)(input_2) y = LeakyReLU()(y) y = Dropout(0.3)(y) y = Dense(200)(y) y = LeakyReLU()(y) y = Dropout(0.3)(y) y = Dense(128)(y) y = LeakyReLU()(y) y = Dropout(0.3)(y) y = Dense(64)(y) y = LeakyReLU()(y) y = Dropout(0.3)(y) z = concatenate([x, y]) z = Dense(25)(z) z = Dropout(0.3)(z) z = Dense(1)(z) model = Model(inputs=[input_1, input_2], outputs=z) return modelСтруктура дискриминатора

Определим функции потерь и оптимизаторы для обеих моделей, создадим чекпойнты
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True) def discriminator_loss(real_output, fake_output): real_loss = cross_entropy(tf.ones_like(real_output), real_output) fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output) total_loss = real_loss + fake_loss return total_loss def generator_loss(fake_output): return cross_entropy(tf.ones_like(fake_output), fake_output) generator_optimizer = tf.keras.optimizers.Adam(1e-4) discriminator_optimizer = tf.keras.optimizers.Adam(1e-4) checkpoint_dir = './training_checkpoints' checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt") checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer, discriminator_optimizer=discriminator_optimizer, generator=generator, discriminator=discriminator)Определение цикла обучения
Цикл обучения начинается с того, что генератор получает на вход случайное начальное число. Это число используется для создания ЭКГ и табличных данных. Затем дискриминатор используется для классификации реальных изображений и табличных данных (извлеченных из обучающего набора) и поддельных изображений и табличных данных (сгенерированных генератором). Потери рассчитываются для каждой из этих моделей, а градиенты используются для обновления генератора и дискриминатора.
EPOCHS = 5000 noise_dim = 100 num_examples_to_generate = 16 seed = tf.random.normal([num_examples_to_generate, noise_dim]) @tf.function def train_step(images): noise = tf.random.normal([BATCH_SIZE, noise_dim]) with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape: generated_images = generator(noise, training=True) real_output = discriminator(images, training=True) fake_output = discriminator(generated_images, training=True) gen_loss = generator_loss(fake_output) disc_loss = discriminator_loss(real_output, fake_output) gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables) gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables) generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables)) discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables)) def train(dataset, epochs): for epoch in range(epochs): start = time.time() for image_batch in dataset: train_step(image_batch) display.clear_output(wait=True) generate_and_save_images(generator, epoch + 1, seed) if (epoch + 1) % 500 == 0: checkpoint.save(file_prefix = checkpoint_prefix) print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start)) # Generate after the final epoch display.clear_output(wait=True) generate_and_save_images(generator, epochs, seed) def generate_and_save_images(model, epoch, test_input): predictions = model(test_input, training=False) fig = plt.figure(figsize=(7, 7)) for i in range(predictions[0].shape[0]): plt.subplot(4, 4, i+1) plt.imshow(predictions[0][i, :, :, 0] * 127.5 + 127.5, cmap='gray') plt.axis('off') plt.savefig('image_at_epoch.png'.format(epoch)) plt.show()Обучение модели
Вызовите метод train(), определенный выше, для одновременного обучения генератора и дискриминатора. Важно, чтобы генератор и дискриминатор не подавляли друг друга (например, чтобы они обучались с одинаковой скоростью).
train(train_dataset, EPOCHS)Мы можем контролировать обучение визуально по ЭКГ-изображениям.
В начале обучения сгенерированные изображения выглядят как случайный шум. По мере того, как нейронные сети будут учиться, сгенерированные изображения ЭКГ будут выглядеть все более и более реальными.
Сгенерируем 1500000 синтетических наблюдаемых и сохраним их.
dataset_pred = [] for i in tqdm(range(0, 1500000)): noise = tf.random.normal([1, 100]) generated_image = generator(noise, training=False) Image.fromarray(np.array(generated_image[0] * 127.5 + 127.5, dtype='uint8').reshape(200, 200)).save(f"./new_GANECG/{i}.jpg") dataset_pred.append(generated_image[1].numpy()) with open('dataset_pred.pickle', 'wb') as f: pickle.dump(dataset_pred, f)Сравним ЭКГ изображения. Внешне ЭКГ-изображения практически неотличимы от реальных.

Более сложной проблемой являются табличные данные, насколько они приближены к реальным?
-
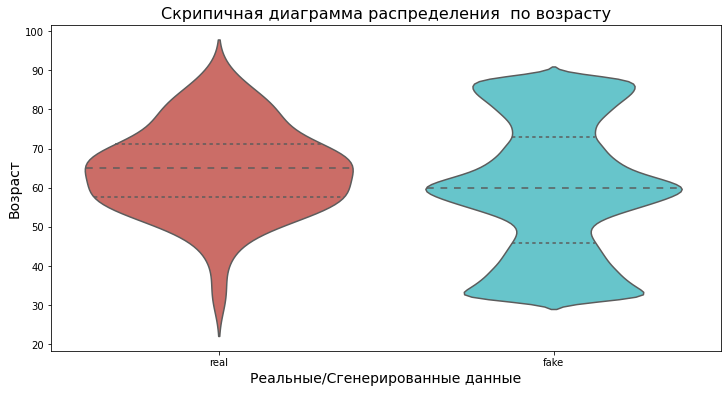
Проведен анализ распределения пациентов по возрасту. Распределение реальных данных нормальное, синтетические данные распределены с тремя пиками, в сторону медианы, минимальных и максимальных значений.
Скрипичная диаграмма распределения по возрасту реальных и сгенерированных данных.
-
Выполнен количественных анализ сгенерированных признаков. Распределение приближено к реальному, однако выявленные отличия в количественном отношении признаков.
Количественное распределение реальных и сгенерированных данных.

-
Создана тепловая карта сравнения базовых описательных статистик (медианы, среднего 25 квантиля, 75 квантиля, минимального и максимального значений). Получены значимые отличия в половине признаках.
Тепловая карта разницы базовых описательных статистик.

-
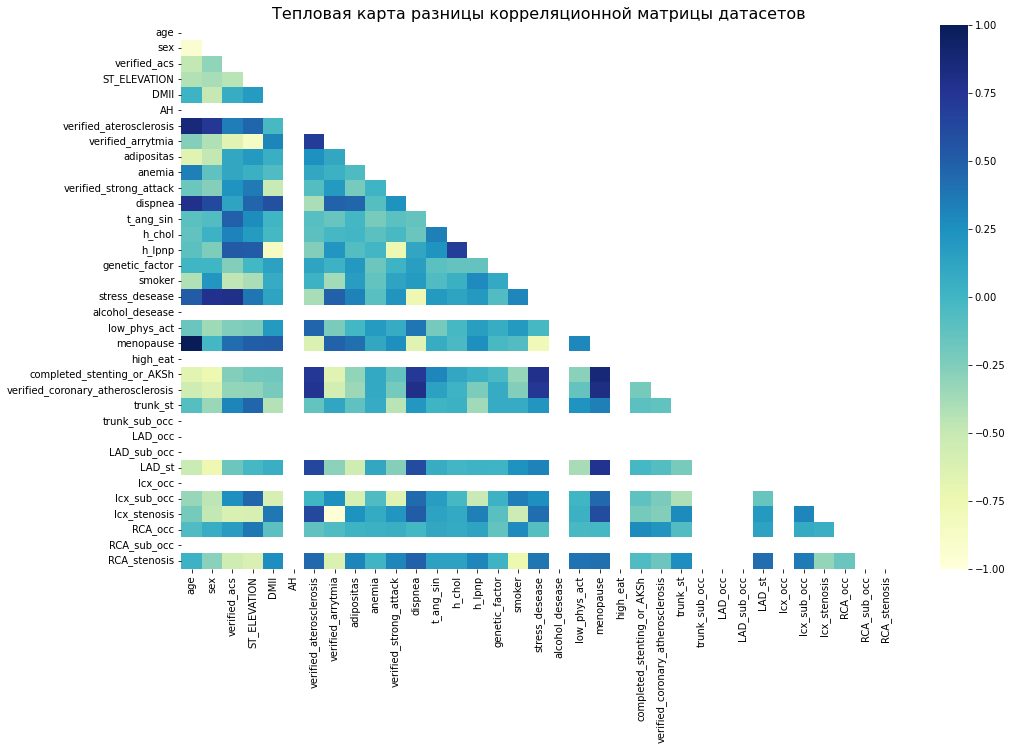
Создана тепловая карта разницы корреляционных матриц реального и синтетического датасетов. Основные корреляционные составляющие сохранены.
Тепловая карта разницы корреляционных матриц датасетов.
-
Проведено вычисление и визуализация главных компонент (PCA) реального и сгенерированного датасетов.
Главные компоненты реального и сгенерированного датасетов.
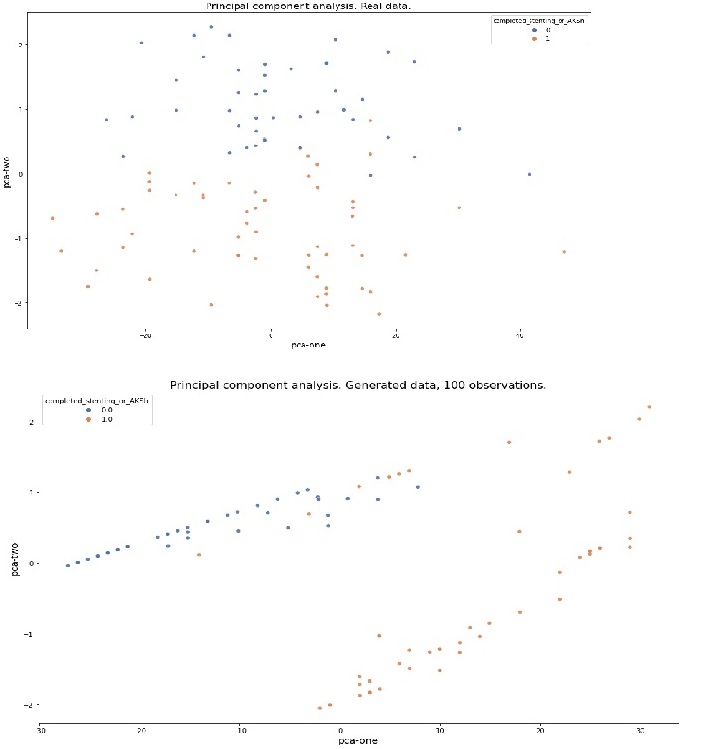
-
Визуализировано cтохастическое вложение соседей с t-распределением (англ. t-distributed Stochastic Neighbor Embedding, t-SNE).
TSNE реального и сгенерированного датасетов.
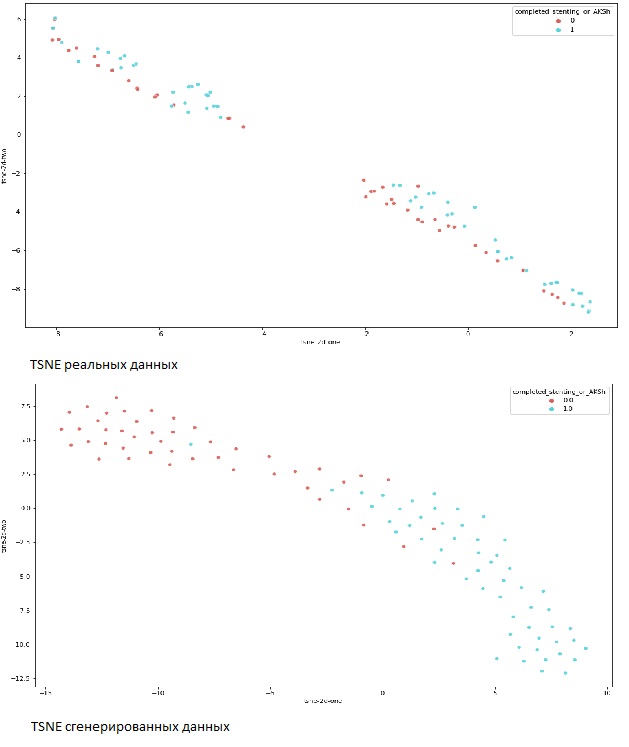
Сравнив синтетические данные с реальными можно сделать вывод о приближенности сгенерированных данных к реальным. Основные базовые потоковые зависимости признаков сохранены, однако сгенерированный датасет не полностью копирует зависимости реального, таким образом можно сделать вывод о наличии новых отличных «рандомных» наблюдений.
Результаты сравнения точности прогнозирования coronarography.ai на входных синтетических данных.
Собственно то из-за чего весь сыр-бор. Какова точность Карл?????
Проведено прогнозирование поражения магистральных коронарных артерий и преходящей ишемии миокарда на 1500000 синтетических наблюдений.
Результат AUC score составил 0.79. Точность (accuracy) достигала 88%, «прецизионная» точность (precision) – 73%, полнота (recall) — 63%, f1 score – 67%.
+-------------------------------------------------------------------------+-----+----------+-----------+--------+----------+ | Predicting damage to the main coronary arteries and myocardial ischemia | AUC | Accuracy | Precision | Recall | F1 score | +-------------------------------------------------------------------------+-----+----------+-----------+--------+----------+ | Non-invasive predictive AI coronary angiography | 79 | 88 | 73 | 63 | 67 | +-------------------------------------------------------------------------+-----+----------+-----------+--------+----------+Mission complete!
ссылка на оригинал статьи https://habr.com/ru/post/709130/
Добавить комментарий