Мой первый open-source продукт.
pip install nonaВ реальных наборах данных пропущенные значения создают проблему для дальнейшей обработки. Большую ценность имеет подстановка или заполнение отсутствующих значений. К сожалению, стандартные «ленивые» методы, такие как простое использование медианы столбца или среднего значения, не всегда работают должным образом.
В 2021-ом году ко мне пришла идея создания алгоритма на основе методов машинного обучения с прогнозированием по каждому столбцу с пропусками. Данную идею я воплотил сначала схематично на бумаге.

Суть алгоритма заключается в заполнении пропусков различными методами машинного обучения. Циклом проходим по всем столбцам, если столбец с пропущенными значениями — останавливаемся и делаем этот столбец — target. Предыдущие столбцы делим на X_train, X_test. X_test будет соответствовать пропущенным значениям. Значения Y_train берем из столбца (на котором остановились в цикле) в которых нет пропусков. Обучаем X_train и y_train на выбранном нами методе, например гребневой регрессии (Ridge regression). Делаем предсказания на X_test, заполняем пропущенные значения в столбце предсказанными значениями. Так делаем по всем столбцам с пропусками.
Данный алгоритм я регулярно использовал на практике для заполнения пропущенных значений.
В 2023-м году решил на его основе написать библиотеку для Python и провести сравнение с иными методами заполнения пропусков.
Преимущества метода:
-
Простое и быстрое заполнение пропущенных значений.
-
Кастомизация используемых методов машинного обучения.
-
Высокая точность прогнозирования.
Установка
Исходный код в настоящее время размещен на GitHub по адресу: GitHub — AbdualimovTP/nona: библиотека для заполнения пропущенных значений с использованием методов искусственного интеллекта
Двоичные установщики для последней выпущенной версии доступны в каталоге пакетов Python (PyPI)
# PyPI pip install nonaЗависимости
Быстрый старт
» Из коробки» используем гребневую регрессию, чтобы заполнить пробелы в столбцах где необходимо решить задачу регрессии, и RandomForestClassifier для задачи классификации.
# Загружаем библиотеку from nona.nona import nona # Подготовьте ваш датасет, только численные значения в датасете # Заполняем пропущенные значения nona(YOUR_DATA)Повышение точности алгоритма
Вы можете вставить в функцию иные методы машинного обучения. Они должны поддерживать простую реализацию fit и predict.
Параметры алгоритма:
-
data: подготовленный набор данных
-
algreg: Алгоритм регрессии для прогнозирования отсутствующих значений в столбцах
-
algclass: Алгоритм классификации для прогнозирования пропущенных значений в столбцах
# Загружаем библиотеку from nona.nona import nona # Подготовьте ваш датасет, только численные значения в датасете # Заполняем пропущенные значения nona(data=YOUR_DATA, algreg=make_pipeline(StandardScaler(with_mean=False), Ridge(alpha=0.1)), algclass=RandomForestClassifier(max_depth=2, random_state=0))Сравнение с иными методами заполнения пропусков
Сравниваемые методы:
Baseline — заполнение средним по столбцу.
KNN — заполнение пропущенных значений с использованием k-ближайших соседей. Отсутствующие значения каждой выборки заполняются с использованием среднего значения ближайших соседей n_neighbors, найденных в обучающем наборе.
MICE — Использование класса IterativeImputer sklearn, который моделирует каждую функцию с отсутствующими значениями как функцию других функций и использует эту оценку для заполнения. Он делает это в итерированном циклическом режиме: на каждом шаге столбец признаков обозначается как выход y, а другие столбцы признаков обрабатываются как входы X. Регрессор подходит для (X, y) для известного y. Затем регрессор используется для предсказания пропущенных значений y. Это делается для каждого признака итеративно, а затем повторяется для раундов заполнения max_iter. Возвращаются результаты финального раунда заполнения.
MissForest — алгоритм заполнения данных на основе машинного обучения, который работает на основе алгоритма Random Forest.
NoNA — мой алгоритм «постолбцового» заполнения пропусков при помощи различных методов машинного обучения.
Для работы я взял Framingham heart study dataset доступный на Kaggle.
На данном датасете мы будем моделировать пропуски в объёме 10%, 20%, 30%, 40%, 50%, 70%, 90% пропущенных значений. Заполнять их описанными методами (каждым по отдельности). И сравнивать результаты с истинными значениями. На выходе получим среднеквадратичную ошибку (RMSE).
for i in [0.1, 0.2, 0.3, 0.4, 0.5, 0.7, 0.9]: # we create a random matrix the size of a dataset, randomly fill it with gaps and zeros randomMatrixNA = np.random.choice([0,np.NaN], (data.shape[0], data.shape[1]), p=[1-i, i]) # fill dataset with missing values dataWithNA = data + randomMatrixNA # create datasets with filled gaps # fill in the middle Baseline_1_mean = dataWithNA.fillna(dataWithNA.mean()) print(f'Baseline_MEAN, {i*100}, RMSE:' , np.round(mean_squared_error(data, Baseline_1_mean, squared=False), 2)) dataFrameRMSE.loc['Baseline_MEAN'][f'{int(i*100)}%'] = np.round(mean_squared_error(data, Baseline_1_mean, squared=False), 2) # KNN imputer = KNNImputer(n_neighbors=15) KNN = imputer.fit_transform(dataWithNA) dataFrameRMSE.loc['KNN'][f'{int(i*100)}%'] = np.round(mean_squared_error(data, KNN, squared=False), 2) print(f'KNN, {i*100}, RMSE:' , np.round(mean_squared_error(data, KNN, squared=False), 2)) # MICE mice = IterativeImputer(max_iter=10, random_state=0) MICE = mice.fit_transform(dataWithNA) dataFrameRMSE.loc['MICE'][f'{int(i*100)}%'] = np.round(mean_squared_error(data, MICE, squared=False), 2) print(f'MICE, {i*100}, RMSE:' , np.round(mean_squared_error(data, MICE, squared=False), 2)) # MISSFOREST missforest = MissForest(random_state=0, verbose=0) MISSFOREST = missforest.fit_transform(dataWithNA) dataFrameRMSE.loc['MISSFOREST'][f'{int(i*100)}%'] = np.round(mean_squared_error(data, MISSFOREST, squared=False), 2) print(f'MISSFOREST, {i*100}, RMSE:' , np.round(mean_squared_error(data, MISSFOREST, squared=False), 2)) # nona_Base dataWithNA_NonaBase = dataWithNA.copy(deep=True) nona(dataWithNA_NonaBase) dataFrameRMSE.loc['NONA'][f'{int(i*100)}%'] = np.round(mean_squared_error(data, dataWithNA_NonaBase, squared=False), 2) print(f'NONA, {i*100}, RMSE:' , np.round(mean_squared_error(data, dataWithNA_NonaBase, squared=False), 2))Результаты
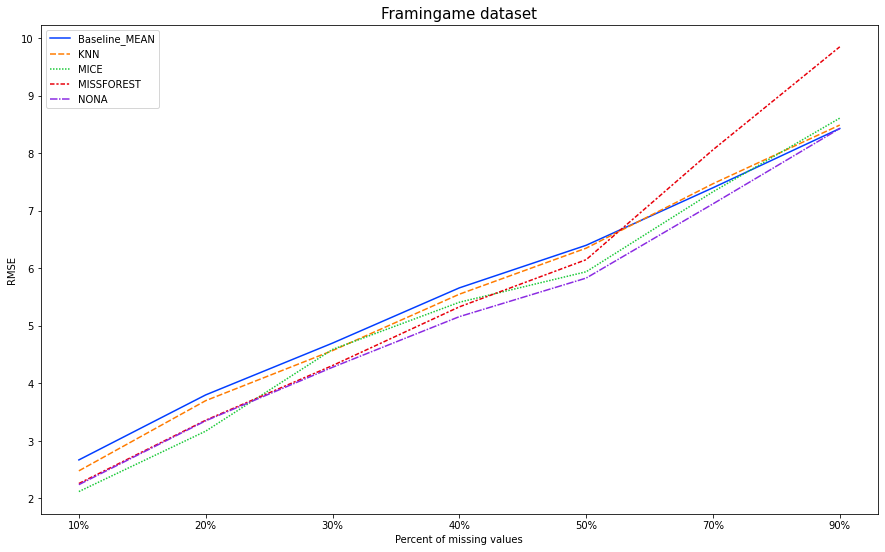
|
|
10% |
20% |
30% |
40% |
50% |
70% |
90% |
|
Baseline — MEAN |
2.67 |
3.8 |
4.7 |
5.66 |
6.4 |
7.4 |
8.43 |
|
KNN |
2.48 |
3.7 |
4.57 |
5.55 |
6.35 |
7.47 |
8.49 |
|
MICE |
2.12 |
3.17 |
4.59 |
5.41 |
5.94 |
7.33 |
8.61 |
|
MISSFOREST |
2.26 |
3.36 |
4.31 |
5.33 |
6.15 |
8.06 |
9.85 |
|
NONA |
2.24 |
3.35 |
4.28 |
5.16 |
5.83 |
7.12 |
8.43 |
Неплохие результаты для работы алгоритма «из коробки».
На 30%, 40%, 50%, 70%, 90% алгоритм NONA показал лучшую RMSE на данном датасете со смоделированными пропусками. На 10%, 20% второе место, первое за MICE.
В дальнейшем планирую проверить точность заполнения на иных датасетах. Также вижу возможности для улучшения качествf прогнозирования. Планирую реализовать в следующих версиях библиотеки.
ссылка на оригинал статьи https://habr.com/ru/post/709748/
Добавить комментарий