«Я тебя по IP вычислю!» – помните такую угрозу из интернета времен нулевых годов? Мы в Big Data МТС решили выяснить, можно ли составить хотя бы приблизительное представление о человеке, обладая информацией о сайтах, которые он посещает. Для этого мы сгенерировали полусинтетические данные, чтобы понять, насколько смелыми можно быть в этих ваших интернетах.

Информация о посещенных сайтах доступна не по конкретному Иван Иванычу, а по обезличенной сущности cookie, используемой в качестве id пользователя при обмене данными между рекламными DSP- и SSP- площадками.
Вопрос звучит так: сможем ли мы по цифровым следам пользователя (на каких сайтах с каких IP он сидел, сколько раз заходил, какое у него устройство) понять, кто этот пользователь? Студент или пенсионер? Мужчина или женщина? Как много информации мы вообще сможем получить?
Вообще в Digital-рекламе сегмент часто включает себя пол и один из бакетов по возрасту (<18, 18-24, 25-34, 35-44, 45-54, 55-64, 65+). Эта задача особенно актуальна для рекламных DSP-площадок, которые в OpenRTB запросах получают такие данные с частотой 200 000 запросов в секунду со всех сайтов, размещающих рекламу за деньги.
Приглашаем и вас попробовать составить портрет рядового пользователя Хабра десятка почти случайных сайтов и посмотреть, насколько точным он получится.
Ниже – наш baseline решения – без кросс-валидации, подбора гиперпараметров, feature engineering и прочих приятных сердцу вещей. Такое решение можно написать в метро по дороге от Речного вокзала до Технопарка (именно здесь находится офис МТС Digital). Этот путь займет чуть больше 30 минут.

Знакомый всем DS-иконостас
Однако в этот раз мы оставили только самое нужное =) (ну почти).
import sys import os import warnings os.environ['OPENBLAS_NUM_THREADS'] = '1' warnings.filterwarnings('ignore')import pandas as pd import numpy as np import time import pyarrow.parquet as pq import scipy import implicit import bisect import sklearn.metrics as m from catboost import CatBoostClassifier, CatBoostRegressor, Pool from sklearn.model_selection import train_test_split from sklearn.calibration import calibration_curve, CalibratedClassifierCVLOCAL_DATA_PATH = './context_data/' SPLIT_SEED = 42 DATA_FILE = 'competition_data_final_pqt' TARGET_FILE = 'competition_target_pqt'Прочитаем файлы
data = pq.read_table(f'{LOCAL_DATA_PATH}/{DATA_FILE}') pd.DataFrame([(z.name, z.type) for z in data.schema], \ columns = [['field', 'type']])
В таблице выше:
-
регион;
-
населенный пункт;
-
производитель устройства;
-
модель устройства;
-
домен, с которого пришел рекламный запрос;
-
тип устройства (смартфон или что-то другое);
-
операционка на устройстве;
-
оценка цены устройства;
-
дата;
-
время дня;
-
число запросов к домену в эту часть дня в эту дату;
-
id пользователя.
data.select(['cpe_type_cd']).to_pandas()['cpe_type_cd'].value_counts()
Для себя открыл слово фаблет.
targets = pq.read_table(f'{LOCAL_DATA_PATH}/{TARGET_FILE}') pd.DataFrame([(z.name, z.type) for z in targets.schema], \ columns = [['field', 'type']])
Ок, нам лень генерить фичи
Вместо этого посмотрим на задачу, как на рекомендательную систему: факторизуем матрицу взаимодействий Users и Items (под которыми понимаем посещенные домены) – ожидаем, что получим полезный эмбеддинг, да и придумывать ничего не придется. Понятно, что мы потеряем последовательность и временные характеристики, но что делать, мы уже почти на Белорусской.

%%time data_agg = data.select(['user_id', 'url_host', 'request_cnt']).\ group_by(['user_id', 'url_host']).aggregate([('request_cnt', "sum")])
url_set = set(data_agg.select(['url_host']).to_pandas()['url_host']) print(f'{len(url_set)} urls') url_dict = {url: idurl for url, idurl in zip(url_set, range(len(url_set)))} usr_set = set(data_agg.select(['user_id']).to_pandas()['user_id']) print(f'{len(usr_set)} users') usr_dict = {usr: user_id for usr, user_id in zip(usr_set, range(len(usr_set)))}
%%time values = np.array(data_agg.select(['request_cnt_sum']).to_pandas()['request_cnt_sum']) rows = np.array(data_agg.select(['user_id']).to_pandas()['user_id'].map(usr_dict)) cols = np.array(data_agg.select(['url_host']).to_pandas()['url_host'].map(url_dict)) mat = scipy.sparse.coo_matrix((values, (rows, cols)), shape=(rows.max() + 1, cols.max() + 1)) als = implicit.approximate_als.FaissAlternatingLeastSquares(factors = 50, \ iterations = 30, use_gpu = False, calculate_training_loss = False, regularization = 0.1)
%%time als.fit(mat) u_factors = als.model.user_factors d_factors = als.model.item_factors
Получим оценку по полу
Раз уж у нас есть эмбеддинг пользователя, потестируем его на задаче – предсказать пол пользователя, запуская все из коробки и забывая про все остальные фичи.
%%time inv_usr_map = {v: k for k, v in usr_dict.items()} usr_emb = pd.DataFrame(u_factors) usr_emb['user_id'] = usr_emb.index.map(inv_usr_map) usr_targets = targets.to_pandas() df = usr_targets.merge(usr_emb, how = 'inner', on = ['user_id']) df = df[df['is_male'] != 'NA'] df = df.dropna() df['is_male'] = df['is_male'].map(int) df['is_male'].value_counts()
%%time x_train, x_test, y_train, y_test = train_test_split(\ df.drop(['user_id', 'age', 'is_male'], axis = 1), df['is_male'], test_size = 0.33, random_state = SPLIT_SEED) clf = CatBoostClassifier() clf.fit(x_train, y_train, verbose = False) print(f'GINI по полу {2 * m.roc_auc_score(y_test, clf.predict_proba(x_test)[:,1]) - 1:2.3f}')
Не так уж плохо! Но мы почти доехали до Павелецкой.

Получим оценку по возрасту
import seaborn as sns import matplotlib.pyplot as plt import plotly.express as px %matplotlib inline sns.set_style('darkgrid')def age_bucket(x): return bisect.bisect_left([18,25,35,45,55,65], x)df = usr_targets.merge(usr_emb, how = 'inner', on = ['user_id']) df = df[df['age'] != 'NA'] df = df.dropna() df['age'] = df['age'].map(age_bucket) sns.histplot(df['age'], bins = 7)
x_train, x_test, y_train, y_test = train_test_split(\ df.drop(['user_id', 'age', 'is_male'], axis = 1), \ df['age'], test_size = 0.33, random_state = SPLIT_SEED) clf = CatBoostClassifier() clf.fit(x_train, y_train, verbose = False) print(m.classification_report(y_test, clf.predict(x_test), \ target_names = ['<18', '18-25','25-34', '35-44', '45-54', '55-65', '65+']))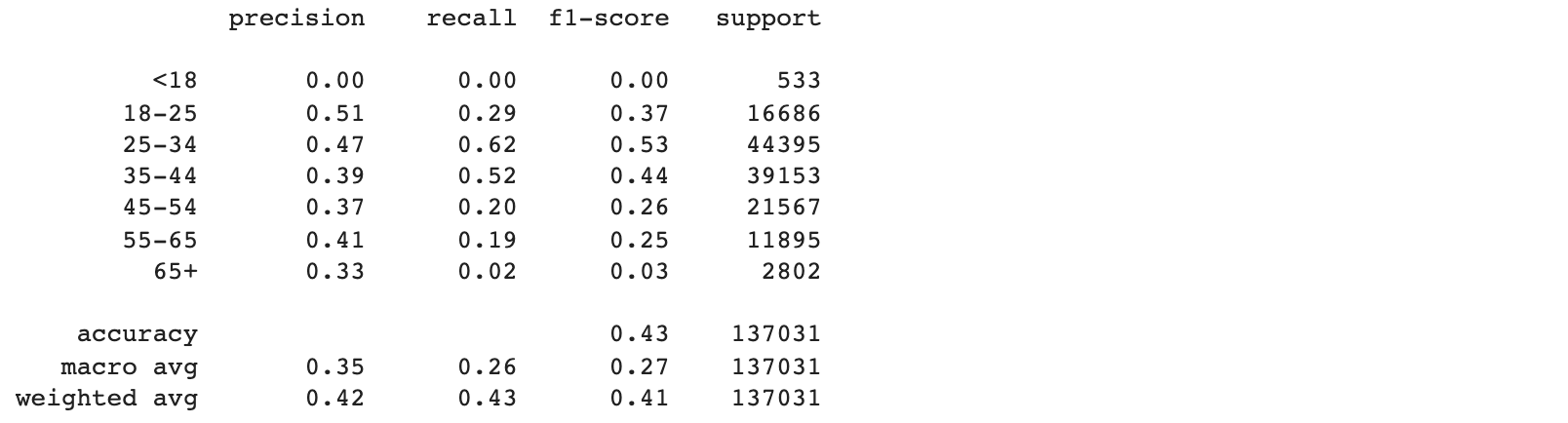
Критерии сравнения
Оказалось, что пол определить намного проще, чем возраст.
Поэтому в итоговый скор соревнования войдут Gini по полу (от 0 до 1) и f1 weighted по возрасту – с весом два:

Итого общий скор: 0.665 + 2 * 0.41 = 1.485
Для поездки от Речного до Технопарка терпимо. =)
На этом все! Если же хочется более серьезных задач – ждем вас на соревнованиях по Machine Learning 30 января, это турнир по определению пола/возраста владельца cookie от МТС Digital. Призовой фонд MTC ML Cup – 650 000 рублей: победитель получит 350 000 рублей, обладатель серебра – 200 000 рублей, а третий призер станет богаче на 100 000 рублей. Регистрация уже открыта, простая анкета для участников и все подробности – на сайте. Увидимся на соревновании!

Спасибо за уделенное время! Если у вас есть иные способы решения поставленной задачи или же вы знаете, как сократить необходимое на решение время до пары перегонов между станциями метро – обязательно расскажите об этом в комментариях!
P.S.
Возможно, вам полезно будет попробовать более новые и быстрые библиотеки по работе с табличками вместо Pandas и PyArrow:
Polars
CuDF
И библиотеки для RecSys:
MTS RecTools
LightFM
Transformers4Rec
ReChorus
RecBole
ссылка на оригинал статьи https://habr.com/ru/company/ru_mts/blog/709602/
Добавить комментарий