
Потоковый гроссбух Кафки
В предыдущей статье мы обсуждали, как именно работает сторона producer при отправке сообщений, и с учетом данных, хранящихся внутри темы, давайте теперь углубимся в сторону consumer.
Цель этой части — охватить следующее:
-
Как работает сторона consumer;
-
Как работает масштабирование групп потребителей;
-
Как работает масштабирование с помощью параллельного consumer’а;
-
Настройка, позволяющая избежать медленных consumer’ов.
Вы можете найти соответствующие примеры кода на Github здесь.
Типичный Сonsumer-цикл Kafka должен выглядеть примерно так, как показано в следующем фрагменте:

Мы запускаем метод poll() для consumer’а, имитируем небольшой объем работы и, наконец, показываем записи, которые он обработал.
Примечание: Метод show() для записей получен из вспомогательной функции расширения для печати записей удобным и структурированным способом:
Итак, давайте попробуем получше разобраться в том, что здесь происходит. Следующая диаграмма дает более подробное объяснение.
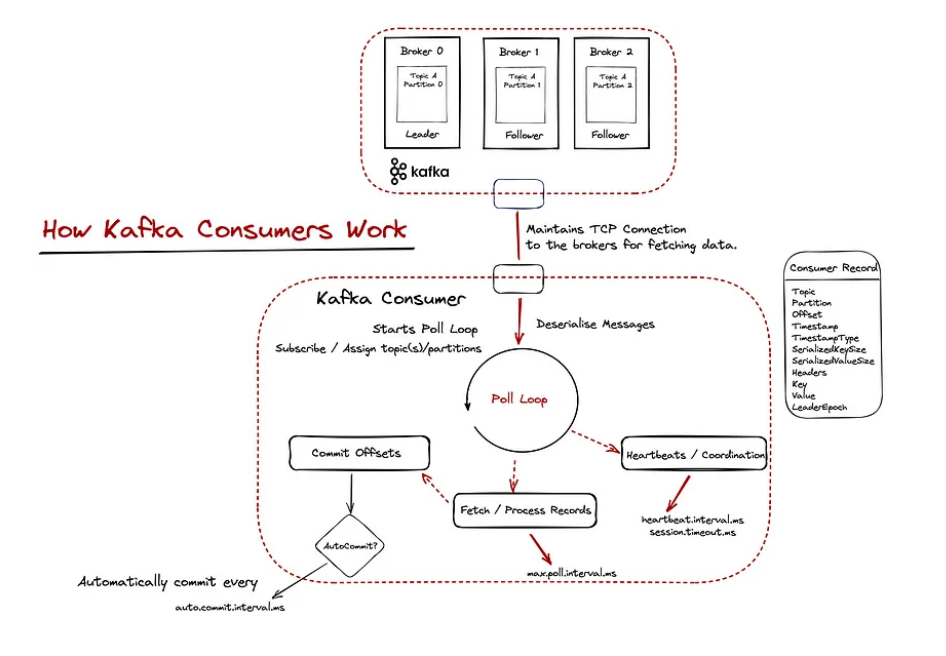
Kafka использует модель, основанную на извлечении данных. В «сердце consumer’а» находится poll loop. Poll loop важен по двум причинам:
-
Он отвечает за выборку данных (предоставление Consuming Records) для обработки consumer’ом;
-
посылает сигналы тревоги и координирует consumer’ов, чтобы группа consumer’ов знала о доступных consumer’ах и о необходимости перебалансировки.
Приложения-consumer’ы поддерживают TCP-соединения с брокерами и отправляют запросы на выборку для извлечения данных. Данные кэшируются и периодически возвращаются из метода poll(). Когда данные возвращаются из метода poll(), происходит фактическая обработка, и, как только она завершается, запрашиваются дополнительные данные и так далее.
Что здесь важно отметить (и мы углубимся в это в следующей части статьи), так это фиксацию смещений сообщений. Это способ Кафки узнать о том, что сообщение было получено и успешно обработано. По умолчанию смещения фиксируются автоматически через регулярные промежутки времени.
Объем данных — сколько их будет извлечено, когда необходимо запросить больше данных и т.д. — определяется параметрами конфигурации, такими как fetch.min.bytes, max.partition.fetch.bytes, fetch.max.bytes, fetch.max.wait.ms. Вы можете подумать, что параметры по умолчанию могут подойти вам, но важно протестировать их и тщательно продумать свой вариант использования.
Чтобы сделать это понятнее, давайте предположим, что вы извлекаете 500 записей из цикла poll() для обработки, но обработка по какой-то причине занимает слишком много времени для каждого сообщения. max.poll.interval.ms определяет максимальное время, в течение которого consumer может бездействовать, прежде чем извлекать дополнительные записи; т.е. вызывать метод опроса, и если этот порог достигнут, consumer считается потерянным, и будет инициирована перебалансировка — хотя наше приложение просто медленно обрабатывалось.
Таким образом, при уменьшении количества записей, которые должен возвращать цикл poll(), и/или улучшении настройки некоторых конфигураций, таких как heartbeat.interval.ms и session.timeout.ms, в этом случае может быть разумным использовать для координации группы consumer’ов.
Запуск consumer’а
На этом этапе я запущу один потребляющий экземпляр в моем ecommerce.events. Помните из части 1, что этот раздел состоит из 5 партиций. Мы будем выполнять в своем кластере Aiven для Kafka, используя параметры конфигурации потребителя по умолчанию, и моя цель — посмотреть, сколько времени требуется consumer’у, чтобы прочитать 10 000 сообщений из темы, предполагая, что время обработки каждого сообщения составляет 20 мс. Вы можете найти код здесь.
Мы можем видеть, что одному consumer’у требуется около 4 минут для такого рода обработки. Итак, как мы можем сделать лучше?
Масштабирование стороны consumer’а
Группы consumer’ов и параллельная модель потребления
Группы consumer’ов — это способ Кафки разделить работу между разными consumer’ами, а также уровень параллелизма. Самый высокий уровень параллелизма, которого вы можете достичь с помощью Kafka, — это наличие одного consumer’а, потребляющего из каждой партиции темы.
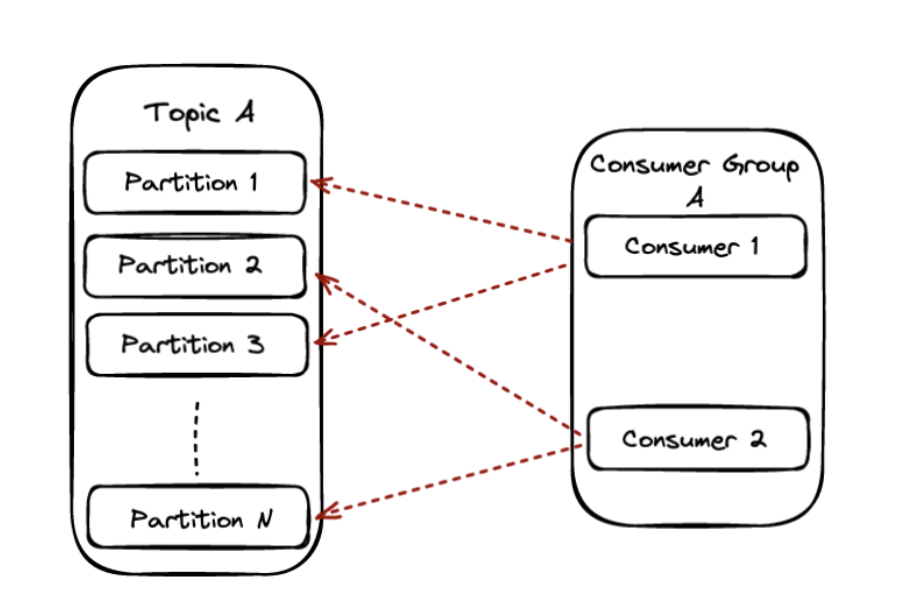
Сценарий 1: #Partitions = #consumers
В этом сценарии доступные партиции будут распределены поровну между доступными consumer’ами группы, и каждый consumer будет владеть этими партициями.
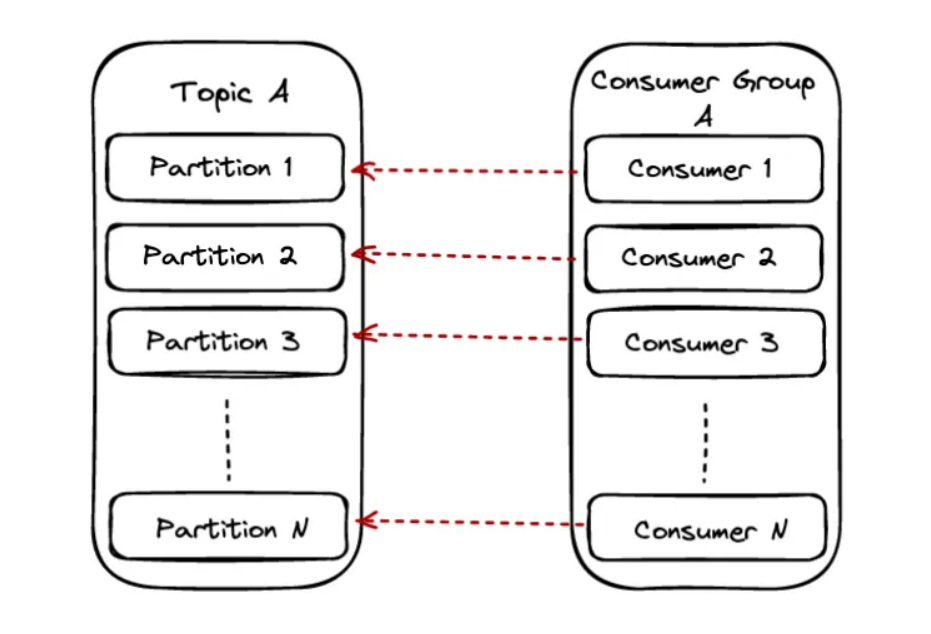
Сценарий 2: #Partitions = #consumers
Когда номер партиции равен доступным consumer’ам, каждый consumer будет считывать данные ровно из одной партиции. В этом сценарии мы также достигаем максимального параллелизма, которого можем достичь по конкретной теме.
Сценарий 3: #Partitions = #consumers
Этот сценарий похож на предыдущий, только теперь у нас будет один consumer, работающий, но бездействующий. С одной стороны, это означает, что мы тратим ресурсы впустую, но мы также можем использовать этого consumer’а в качестве Failover на случай, если другой consumer в группе выйдет из строя.
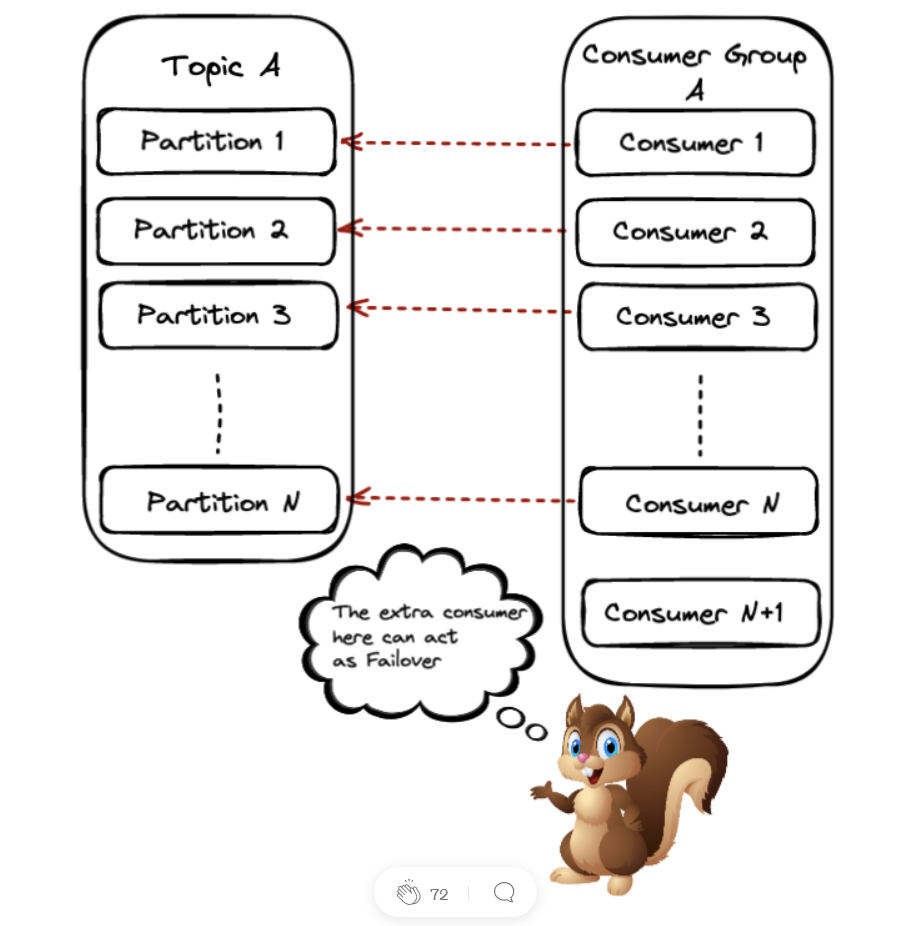
Когда consumer выходит из строя или аналогичным образом к группе присоединяется новый, Kafka должна будет инициировать перебалансировку. Это означает, что партиции необходимо отозвать и переназначить доступным consumer’ам в группе.
Давайте снова запустим наш предыдущий пример — потребление 10 тысяч сообщений — но на этот раз с 5 consumer’ами в нашей группе consumer’ов. Я буду создавать 5 потребляющих экземпляров из одной JVM (используя сопрограммы kotlin), но вы можете легко перенастроить код (найти здесь) и просто запустить несколько JVM.
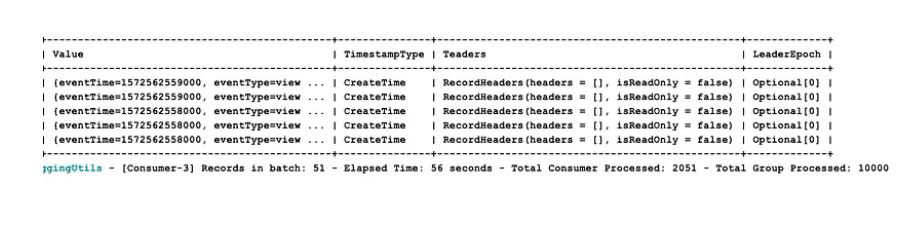
Как и ожидалось, мы видим, что время потребления сократилось менее чем до минуты.
Но если максимальный уровень параллелизма Kafka составляет один consumer на партицию, означает ли это, что мы достигли предела масштабирования? Давайте посмотрим, как с этим бороться дальше.
А как насчет модели параллельного потребления?
До этого момента у нас могли бы быть на уме два вопроса:
-
Если #partitions = #consumers в группе consumer’ов, как я могу масштабироваться еще больше, если это необходимо? Не всегда легко заранее рассчитать количество партиций, и/или нам могут потребоваться учитывать внезапные скачки.
-
Как я могу свести к минимуму время перебалансировки?
Одним из решений этой проблемы может быть параллельный шаблон consumer. У вас могут быть consumer’ы в вашей группе, потребляющие из одного или нескольких партиций темы, но затем они распространяют фактическую обработку на другие потоки.
Одну из таких реализаций можно найти здесь.
Он обеспечивает три гарантии упорядочения — Unordered, Keyed and Partition.
Unordered — не дает никаких гарантий.
Keyed — гарантирует упорядочение по ключу, но с оговоркой, что пространство ключей должно быть довольно большим, иначе вы можете не заметить значительного улучшения производительности.
Partition — в любой момент на каждую партицию будет обработано только одно сообщение.
Наряду с этим он также предоставляет различные способы фиксации смещения. Это довольно приятная библиотека, на которую вы, возможно, захотите взглянуть.
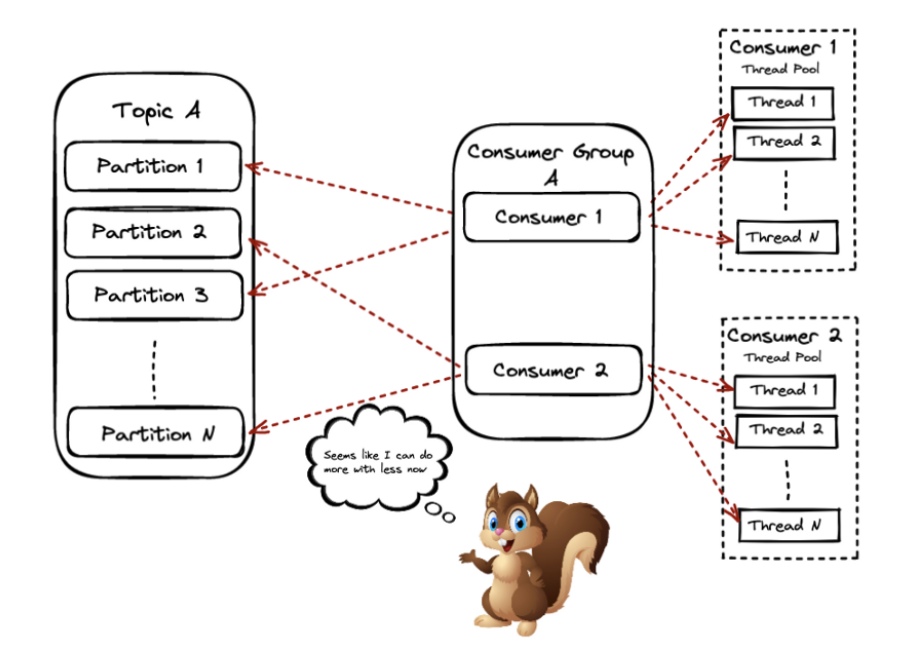
Возвращаясь еще раз к нашему примеру, чтобы ответить на вопрос — как мы можем нарушить ограничение масштабирования? Мы будем использовать шаблон parallel consumer — вы можете найти код здесь.
Использование одного параллельного экземпляра consumer в нашей теме с 5 партициями, указание порядка ключей и использование параллелизма в 100 потоков.

В результате время приема и обработки 10 тысяч сообщений занимает целых 6 секунд.
Обратите внимание на скриншоте, как разные пакеты обрабатываются в разных потоках одного и того же экземпляра-consumer’а.
и если мы используем 5 параллельных экземпляров consumer

нам удалось сократить это время до 3 секунд.
Обратите внимание на скриншоте, как разные пакеты обрабатываются в разных потоках в разных экземплярах-consumer’ах.

«Apache Kafka для разработчиков» — углублённый курс с практикой на Java или Golang и платформой Spring+Docker+Postgres
Подведение итогов
В этой части мы увидели, как работает consumer-сторона Kafka. В качестве рекомендаций при создании приложений-consumer’ов:
-
Нам нужно принять во внимание количество партиций, которые есть в каждой теме.
-
Подумайте о наших требованиях с точки зрения обработки и постарайтесь учесть медлительность consumer’ов.
-
Как именно мы можем масштабироваться как с группами consumer’ов, так и с параллельной моделью потребления?
-
Здесь необходимо принять во внимание порядок сообщений, количество ключевого пространства и гарантии партиций и посмотреть, какой подход работает лучше всего (или комбинация того и другого).
Прокачай свои навыки разработчика вместе с Apache Kafka!
Нельзя просто так взять…и не использовать Кафку.
Знание Apache Kafka в 2023 году просто необходимо для инженеров инфраструктуры и программистов, желающих расширить свои возможности.
Углублённый курс с практикой на Java или Golang и платформой Spring+Docker+Postgres переведёт вас на новый уровень владения инструментом.
Стартуем уже 10 марта 2023. Вас ждут встречи, живые трансляции, ответы на вопросы от спикеров, обсуждение Kafka с другими участниками интенсива, много практики на стендах и закрепление материала.
На нашем курсе ты за несколько дней начнешь разбираться в Kafka, как будто создал её сам, а ещё расскажем про архитектуру — регистрируйся прямо сейчас: slurm.club/3xKd9nl
ссылка на оригинал статьи https://habr.com/ru/company/southbridge/blog/718728/
Добавить комментарий