
Немного истории
Меня зовут Артем Толстогузов, и я вхожу в группу анонимных Unity‑программистов.
У меня:
-
навязчивое желание переложить всю работу с CPU на GPU;
-
небольшой фетиш в области оптимизаций всего что только возможно;
-
хронический интерес к шейдерам, графическому пайплайну и технологиям;
-
патологический синдром самозванца.
Люблю тестировать разные алгоритмы, подходы и технологии, доводить до совершенства отдельные механизмы, искать нетрадиционные методы изобретения велосипедов, а также проверять имеющиеся на возможность усовершенствования под конкретные задачи.
Так уж вышло, что в конце 2014 года меня позвали на проект, в котором моя страсть к оптимизациям и хронический интерес к шейдерам сильно обострились.
Одно из направлений нашей работы — оперативная подготовка роликов. У нас есть отдел картографии, в задачи которого входит работа именно с геокартами. Если вы знакомы со спецификой работы студии дизайна, вы знаете, что совместить слова КАРТЫ, ВЫСОКОКАЧЕСТВЕННЫЕ РОЛИКИ и ОПЕРАТИВНО в одном предложении можно только использовав минимум 1 частицу НЕ.
Чтобы ускорить работу на эфире, в далеком 2012 был сделан прототип интерактивных карт Москвы на эфирном движке VizRt. В сцену подгружалась одна из крайне простых и маленьких областей Москвы, заранее подготовленная в 3D движке, и на ней можно было расставить лейблы и некоторые иконки. Подложка состояла из четырёх текстур, высота и угол обзора камеры были заблокированы, а из 3D элементов в сцене был только слой с домами одной высоты.
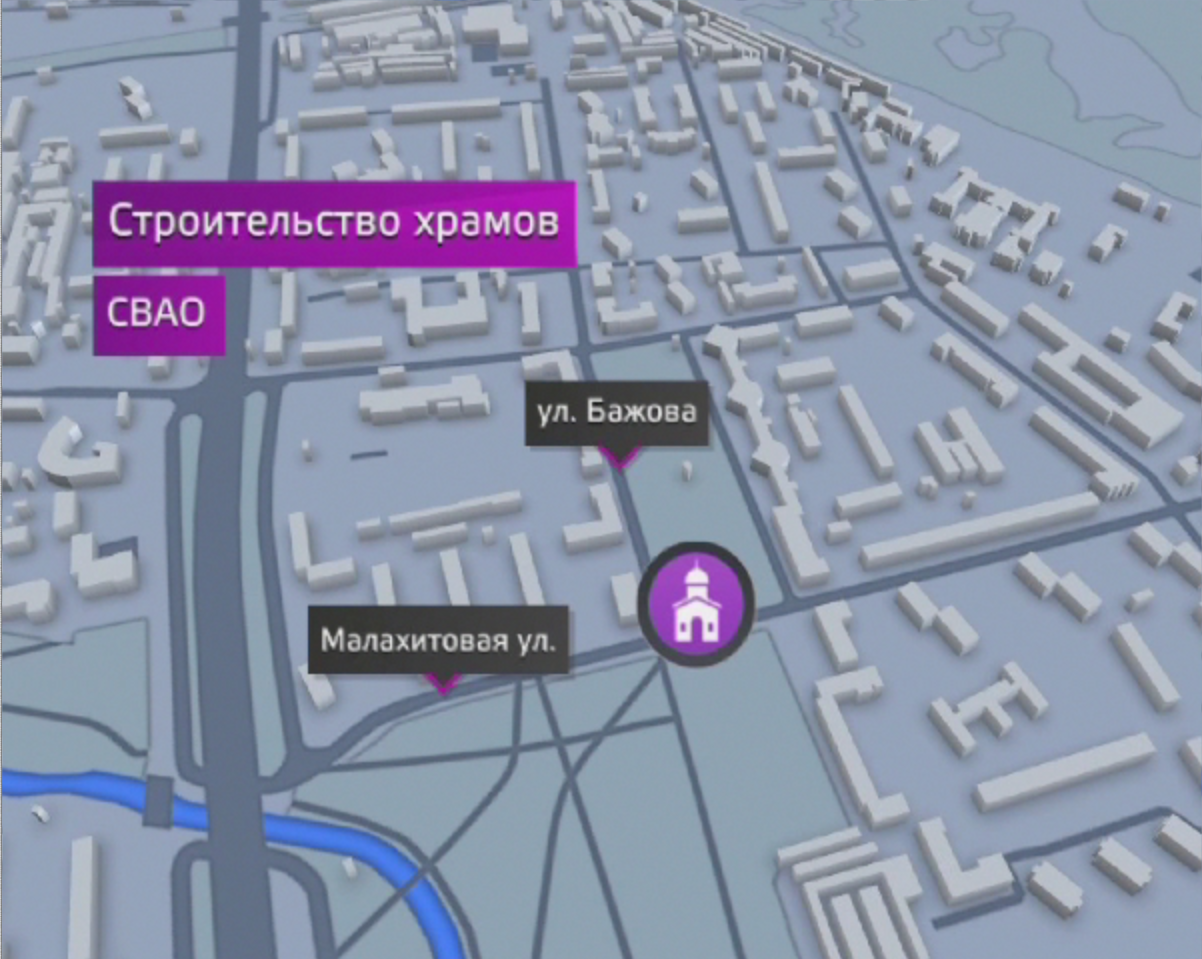
Из‑за ограничений VizRt, развивать такую карту было невозможно. Тогда мы решили перенести ее на игровой движок Unity. Все объекты из геоданных были выгружены в отдельные .obj‑файлы, и в Unity была собрана Alfa версия. В ней на высоте в несколько километров использовалась 2D подложка (четыре текстуры разрешением 8К), а при приближении к интересующему участку загружались 3D модели сразу для нескольких картографических слоев (вода, кварталы, зелень, дороги, ЖД, здания). Тут уж стало возможно работать с камерой (делать незначительные перелеты внутри загруженной области, менять высоту и угол обзора), добавлять подписи и выгружать готовую анимацию в ролик. Здания приобрели индивидуальную высотность.
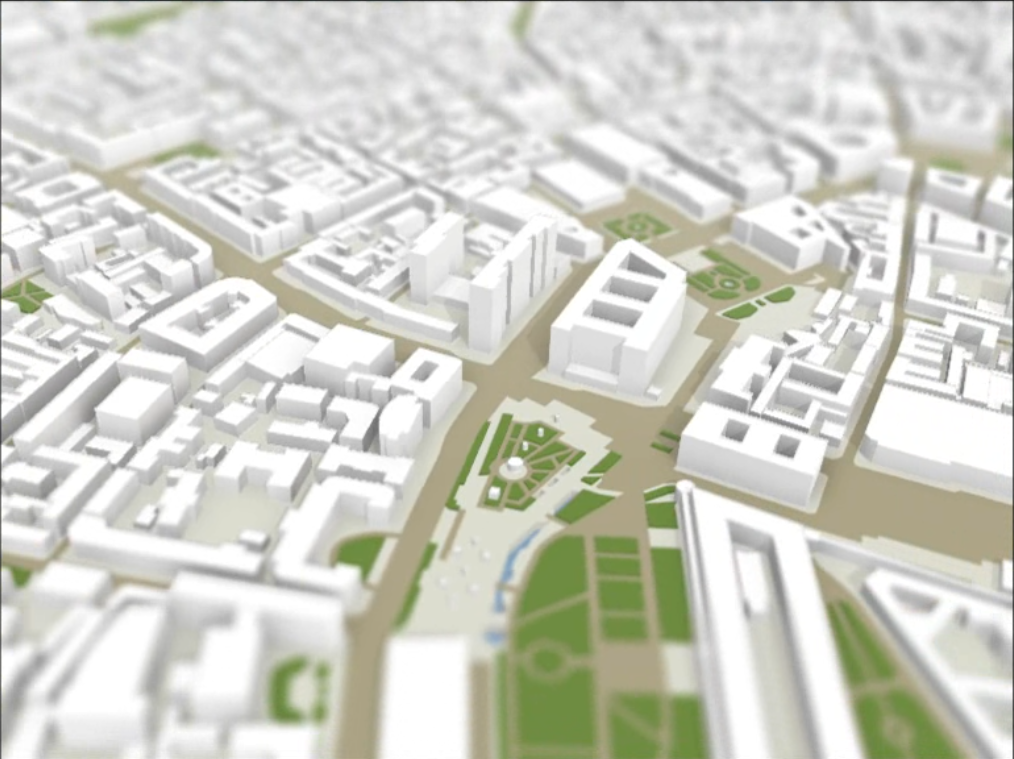
Когда концепция подтвердила жизнеспособность, студия решила развивать это направление и нанять отдельного Unity‑программиста. Именно в этот момент я попал на проект.
Начальные параметры
Первое с чем я столкнулся, это крайне медленная загрузка требуемой области и очень низкая производительность. Перед началом работ я выбрал некоторую тестовую область в центре Москвы и провел контрольные замеры. Вот они:
-
Объектов в кадре 37 500
-
Кол-во △ 450 000
-
Рендер 14 fps
-
Загрузка сцены 130 500 ms
-
Скорость загрузки450 000△ / 130 500ms = 3,45 △/ms
Как видите, чтобы просто подлететь к нужной точке Москвы и дождаться загрузки 3D подложки, приходилось ждать 2–3 минуты. После чего нужно было настраивать анимацию в приложении с 10–15 fps. И в финале для просчета минутного ролика требовалось еще 3–4 минуты. Это несколько не соответствовало критерию ОПЕРАТИВНО.
Оптимизация скорости рендера
Перед тем как заняться оптимизацией загружаемых в сцену карт, я решил разобраться со скоростью рендера. Естественно, что при общем объеме рендера в 0,5 миллиона △, скорость в 14 fps была, мягко говоря, неадекватной. Производительность упиралась в те самые пресловутые 37 500 объектов в сцене, которые CPU каждый кадр обрабатывал и посылал на рендер. Самым логичным выходом было минимизировать количество объектов сцены, объединив объекты из 1 слоя в более крупные меши. Т.к. предстояло заняться созданием более крупных мешей, решили в первую очередь протестировать различные способы добавления в сцену новой геометрии.
А. Первым шагом любых оптимизаций, как всегда, является тест текущего состояния. Профилирование создания новых объектов (new GameObject(), new MeshRenderer(), new MeshFilter(), new Mesh()) показало, что 37 500 объектов добавлялись в сцену за 1 350 ms.
B. Первым тестом стала попытка не создавать каждый раз новый объект, а клонировать уже существующий объект‑прототип и изменять его геометрию на нужную. В итоге, скорость создания уменьшилась до 1150 ms, но на скорость рендера это никак не повлияло. В принципе, и не должно было — количество объектов в сцене осталось таким же.
C. Следующий тест заключался в том, что при загрузке новой геометрии я комбинировал её в большие меши, сократив таким образом кол‑во объектов в сцене и увеличив скорость рендера до 1500 fps. При этом загрузка геометрии уменьшилась до 900 ms.
D. Финальным этапом была проведена оптимизация. В сцене имелся один объект с мешем большого фиксированного размера (около 20 000 △), в момент загрузки создавался его клон, с диска подгружались только данные расположения точек и подготовленные нормали, в меше клонированного объекта подменялись соответствующие данные на загруженные с диска. Таким образом, удалось сократить время создания объектов до 45 ms, а скорость рендера увеличить до рекордных 1800 fps.

Оптимизация загрузки с HDD
Обращение к внешними данными часто является самой медленной операцией в программировании, а двукратная оптимизация процесса, который занимает 90% времени, гораздо выгоднее 100-кратной оптимизации оставшихся 10%.
Что меня крайне смутило в Alfa версии, так это работа с огромным количеством мелких файлов. Каждый объект карты был выгружен в свой собственный .obj файл. Сами объекты представляли из себя очень простые примитивы (чаще всего четырехугольные), и файл с описанием подобной геометрии занимал меньше 1 Кб. Таких объектов были сотни тысяч, и попытка зайти в их папку приводила к подвисанию Windows. Для дальнейших оптимизаций надо было существенно уменьшать количество файлов, объединяя их содержимое — что также требовалось и для оптимизации скорости рендера.
Чтобы понять оптимальный объем требуемых файлов, был написан маленький тест. Он считывал с диска множество файлов разного размера и замерял время доступа. Проведя этот тест на нескольких компьютерах, мы вывели, что оптимальный размер файла должен быть не менее 3 Кб.

Стоит упомянуть, что файловая система имеет свой размер кластера. Если остаток файла в нее не помещается, то это место остается физически зарезервировано системой, но в реальности данные там отсутствуют. Поэтому, если сохранить 1 млн файлов в 1Кб на диске с файловой системой, у которой указан размер кластера 16Кб, в свойствах папки будет написано «Размер: 976.56 Мб На диске: 15,25 Гб».
Таким образом, для оптимальной работы с внешним хранилищем данных требовалось выбрать размер файла, занимающего не меньше 3Кб. Но желательно не более 99% от размера кластера ФС, если оставлять размер файла минимально возможным.
Использование SHP файлов
Первая попытка отказаться от кучи мелких файлов заключалась в том, чтобы полностью избавиться от посредников в виде кучи мелких .obj файлов и воспользоваться картографическими данными, на основании которых эти файлы были сгенерированы. Большой плюс.shp файлов в том, что один файл хранит сразу все данные для одного картографического слоя в бинарном виде. Конечно, бинарные данные занимают гораздо меньше места чем текст, но т.к. это формат хранения не 3D геометрии, а 2D проекций, для него требовалось гораздо больше расчетов. Был написан парсер для.shp файлов и простой генератор 3D объектов из 2D проекций (с возможностью выбора нескольких типов итоговой геометрии).
Итоги по загрузке тестовой области:
-
Объектов в кадре 24
-
Кол-во △ 481 000
-
Рендер 1800 fps
-
Загрузка сцены6 528 ms
-
Чтение 805 Мб с диска 270 ms
-
Выборка данных 170 ms
-
Просчет геометрии 6 040 ms
-
Clone Big Mesh & Change48 ms
-
-
Скорость 481 000△/6 528 ms = 73,7 △/ms (x21)
Как видите, при таком подходе уже удалось ускорить загрузку в 21 раз, сократить время ожидания загрузки тестовой с 2 минут до 6 секунд и увеличить скорость рендера в 120 раз.
Но как же обойтись без ложки дегтя в этом бочонке меда оптимизации? Помимо своих преимуществ, данный метод также имеет и свои недостатки:
-
Еще до начала работы необходимо загрузить в память все SHP файлы и хранить их там все время. т. е. мы резервируем 2–3 Гб в памяти под данные, из которых в реальной работе может использоваться всего 20–30 Мб;
-
Если настраивать работу не с локального диска, а из сети с единой базой данных, то загрузка 2 Гб может занять не секунды, а минуты времени;
-
При подгрузке, где‑то 0,2 сек времени занимает выборка данных из слоя. Если слоев будет больше, то выборка может занять уже 0,5 сек. И эта выборка будет происходить каждый раз при изменении положения камеры в пространстве.
т. е. каждый раз при просчёте кадра или настройке анимации будет происходить микрофриз; -
6 секунд из всего процесса загрузки и построения занимает подготовка геометрии на основании географических данных. Если предыдущие пункты можно было каким‑то образом оптимизировать, то данный пункт, к сожалению, оптимизации почти не подлежит. Так как этот пункт занимает 90% от всего процесса, мы уже не сможем существенно ускорить загрузку.
Оптимизация работы с OBJ
Как сказано выше, чтобы ускорить загрузку .obj файлов, нам в первую очередь необходимо объединить их в .obj файлы бóльшего размера. Конкретно в этом случае нам уже были известны конкретные 37 500 файлов, которые необходимо модифицировать. Сам процесс объединения проходил почти таким же способом, что в тестах по комбинации геометрии в большие меши. Я установил ограничение в 32 760△ для 1.obj файла и получил и итоге 14 файлов. Все дальнейшие рассуждения будут идти при работе с одним таким файлом, и лишь в конце будет проведен финальный тест со всеми файлами.
Размер реальных данных при банальном слиянии геометрии уменьшился в среднем в 1,6 раза (10,5 Mb → 6,4 Mb). Думаю, из‑за того, что в изначально маленьких файлах присутствовали тэги и комментарии, которые в больших файлах исчезли или стали присутствовать всего 1 раз. А вот время загрузки файла с диска уменьшилось в 50 000 раз (115 875 ms → 2.2 ms) по сравнению с загрузкой 2680 отдельных микро файлов.
Следующим делом, я убрал из .obj файлов UV развертку, т.к. она не использовалась в Unity. На этом же шаге я сделал тест по загрузке и просчету нормалей:
-
Парсинг нормалей из .obj 525 ms
-
mesh.RecalculateNormals() 15,12 ms
Узнав, что посчитать нормали по геометрии в 35 раз быстрее, чем распарсить их, я выкинул и их тоже.
Следующим шагом я заметил, что 90% из всей геометрии — это 4 угольные квады, представляющие из себя боковые грани домов и других объектов. Заменив треугольники на квады, в .obj файле стали сохраняться четыре ссылки для каждого квада вместо 6 ссылок для двух △. Конечно, в этом случае, если у объекта имелись △, не образующие квады, на них закладывалась геометрия с пустым △. Но такие незначительные пустышки никак не повлияли на скорость рендера и почти не внесли вклад в увеличение файла.
Удалив все лишнее и оптимизировав формат хранения, я уменьшил размер данных еще в 2,7 раза (6,4 Mb → 2,4 Mb). Т.к. в оптимизированном файле было меньше данных для парсинга, он ускорился в 3,5 раза (3 317 ms → 944 ms).
Скомбинировав данные до приемлемого уровня и уменьшив размеры полученных файлов до минимально возможного значения, я взялся за оптимизацию парсинга этих файлов на стороне Unity. Замечу, что .obj файл представляет из себя текстовый файл с описанием геометрии, и на тот момент для парсинга использовался скрипт ObjImporter.cs. Банальной заменой построчного считывания через StringReader в имеющемся скрипте, на считывание сразу всего файла и работой с string[], я повысил скорость парсинга в 2,4 раза (944 ms → 390 ms).
Следующим шагом был поиск альтернативных парсеров:
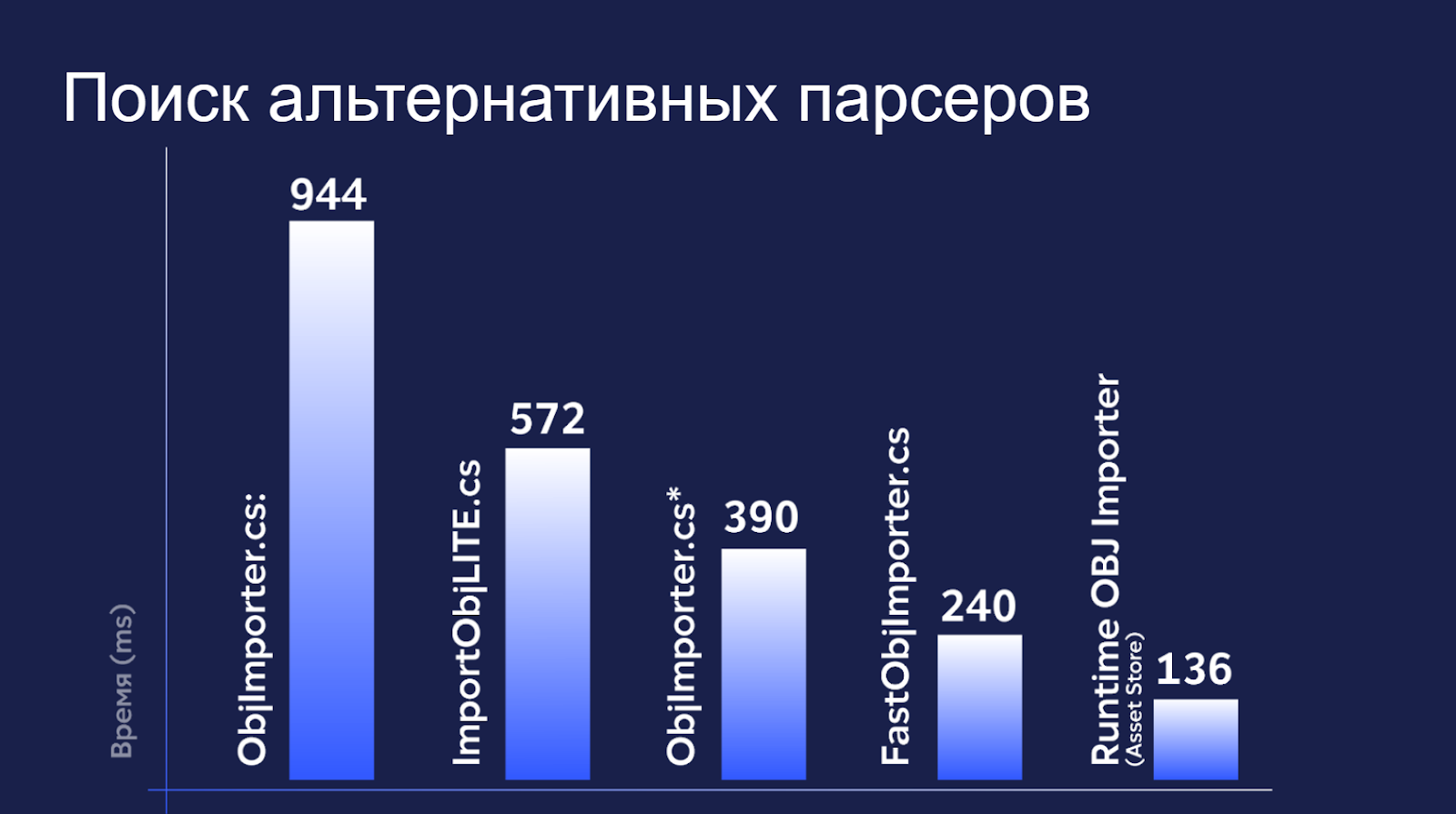
Как видите, самым быстрым оказался бесплатный парсер из AssetStore. Он сократил время парсинга еще в 2,9 раза (390 ms → 136 ms).
Если вы думаете, что, уменьшив размер файлов в четыре раза, время загрузки в 50 000 раз и время парсинга в 24 раза, я остановился, то нет. К тому моменту мой фетиш к оптимизациям уже перешел в острую фазу. Я проверил время загрузки имеющихся файлов разными методами:

Я обратил внимание, что считывание .obj файла как массива байт занимает 58 раз меньше времени, чем чтение того же файла как массива строк.
Я задался вопросом: «А может и парсинг этого файла как бинарного файла тоже будет идти в десятки раз быстрее?».
Дело в том что .obj является текстовым файлом, но текст — это лишь форма представления байт в удобном для человека виде. Для компьютера же работа с текстом является крайне медленной операцией. Я стал считывать .obj файл как массив байт и написал парсер как конечный автомат, в котором каждый последующий байт меняет состояние 3D модели, добавляя или уточняя имеющиеся данные. В итоге, код избавился от всех string и получившийся парсер ускорил парсинг еще в 2,5 раза (136 ms → 55 ms). На тот момент я остановился с оптимизацией работы через .obj файлы, хотя в данный момент думаю, что смог бы провести еще парочку тестов и улучшить полученный результат.
Результат тестирования:
-
Объектов в кадре 14
-
Кол-во △ 450 000
-
Рендер 1800 fps
-
Загрузка сцены 800 ms
-
Чтение 33 Мб с диска 9 ms
-
Парсинг .obj файлов 747 ms
-
Clone Big Mesh & Change 44 ms
-
-
Скорость 450 000△/800 ms = 562,7 △/ms (x163)
Первые результаты и новые вызовы
Как вы заметили, мне удалось снизить объем хранящихся данных и увеличить скорость загрузки тестовой сцены в 163 раза. Если раньше приходилось ждать больше двух минут, пока прогрузятся тестовая сцена, то сейчас она подгружалась за 0,8 секунды. Казалось бы, теперь можно масштабировать полученную технологию на весь проект и полностью забыть про дальнейшие оптимизации. Но мы люди, нам всегда нужно больше.

Как только мы смогли рендерить 0,5 миллиона △ c 1800 fps, мы захотели добавить деталей домам и другим объектам. Как только мы смогли почти мгновенно загружать 37 500 объектов, мы захотели показывать не только часть карты сверху, но и панорамные виды с взглядом вдаль. Как только мы добавили всю Москву, мы захотели добавить и всю Московскую Область.
Для понимания дальнейшей проблематики нужна некоторая статистика.
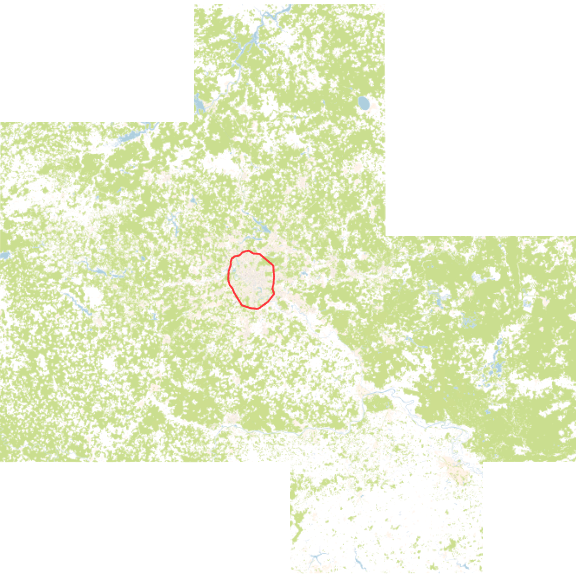
Красным контуром отмечен МКАД, ограничивающий 900 км². Московская Область занимает более 160 000 км².
Если же говорить даже о незначительном отлете камеры, то увеличение высоты на 300 метров может означать увеличение количества геометрии в кадре в десятки раз.


Для увеличения детализации, домам был добавлен поребрик и на фасады наложены окна. Там, где раньше хватало 10△, сейчас требуется 26△. Там, где мы раньше обходились без UV развертки, сейчас она понадобилась.

Как только мы убрали ограничение на угол поворота камеры относительно горизонта, количество геометрии в кадре еще раз скакнуло на порядок.

Сцена со смотрящей вдаль камерой включает в себя 22 000 000△. Если сейчас взять эту сцену за тестовую, то на ее загрузку у нас уйдет: 22 000 000 / 562,7 = 39 097 ms = 39 сек. Это конечно не те 2 минуты, с которых мы начинали, но и приемлемым ожидание 39 секунд при каждом повороте камеры тоже не назовешь.
Оптимизация через шейдеры
Как всегда, при оптимизации тех или иных механизмов следует в первую очередь сделать профилирование всех шагов, а также поискать и протестировать все возможные альтернативы каждого из них.
Уменьшать размер.obj файлов я уже не мог (а с учетом новых запросов на фасады домов мне еще требовалось добавить в них UV). Увеличить скорость работы с диском тоже не представлялось возможным, т.к. файлы уже были больше 2 Мб.
Для работы над парсингом .obj файлов я потратил уже достаточно времени и считал, что выжать из него еще больше скорости я уже не смогу (сейчас я так не думаю). Т.к. эти шаги занимали 95% от общего времени, как бы я ни оптимизировал последний шаг, я бы не смог существенно ускорить процесс на .obj файлах. Соответственно, надо было менять формат хранения — на открытый бинарный или самописный.
Из проведенных ранее тестов было установлено, что быстрее всего создавать новую геометрию в сцене и хранить в ней некую большую заготовку, делая ее копию и меняя позиции финальных точек. Когда же я разбил и этот процесс на этапы и провел более глубокий анализ, я наткнулся на удивительный факт. Из 45 ms процесса создания геометрии непосредственно клонирование занимало всего 0,35 ms. Фактически, можно за очень короткий срок «забить» сцену одинаковой геометрией, находящейся в разных местах. И тут я вспомнил одну очень интересную технику, когда в вертексный шейдер прописывается какое‑либо смещение финальных точек меша, в зависимости от входных параметров и некой текстуры. Я решил попробовать клонировать большой меш за 0,35 ms, установить в него материал с моим шейдером и текстурой, которые поменяют положение ее вертексов на нужное мне, и проверить скорость данного подхода.
Как всегда, я начал с тестов различных вариантов создания текстуры внутри Unity. Стоит пояснить, что в качестве формата хранения я выбрал .png , т.к. он позволял хранить 4 байта данных в 1 пикселе, и использовал сжатие без потери качества, что уменьшало размер хранимых данных на 65%.

Как видно из результатов, быстрее всего создать текстуру и инициализировать ее, задав цвета как массив байт. Но .png не хранит массив байт — это сжатый формат данных. Соответственно, у меня встал выбор: либо хранить png и тратить около 30 ms на его декомпрессию, либо хранить «чистые» данные и создавать текстуру за 3 ms. С учетом, что png сжимал данные приблизительно в 3 раза, то можно было посчитать скорость работы со обоими подходами:
-
2 Mb .png файла считываются с диска за 0,6 ms + 30 ms на декомпрессию = 30,6 ms
-
6 Mb «чистых» данных считается с диска за 1,8 ms + 3.3 ms на создание текстуры = 5,1 ms
Думаю, выбор очевиден.
Следующим шагом было написание умного шейдера и компрессора, который сжимал имеющиеся дома с UV разверткой до минимально возможной текстуры.

Получилась подобная текстура, в которой хранились данные для отображения сразу нескольких рядом стоящих регионов. Размеры полученной текстуры были 1342 x 1342 px, и в чистом виде данные для нее занимали 7 032 Kb. В результаты мы определяли, какие из регионов попадали в камеру, загружали их, делали клоны большого меша и назначали каждому новому мешу эту текстуру. Т.к. в текстуру дома́ объединялись по пространственному признаку, часть из них выходила за пределы камеры, общий объем рендера немного увеличился относительно предыдущего теста.
Результат тестирования:
-
Объектов в кадре 36
-
Кол-во △ 458 640
-
Рендер 1650 fps
-
Загрузка сцены 5,95 ms
-
Чтение 7 Мб с диска 1,9 ms
-
Создание текстуры 3,5 ms
-
Назначение материала 0,2 ms
-
Clone Big Mesh 0,35 ms
-
-
Скорость 458 640△/5.95 ms = 77 082,4 △/ms (x22 342)
Как видите скорость рендера немного упала из-за использования более сложного шейдера. Но финальное ускорение загрузки в 22 342 раза с лихвой окупает столь незначительные изменение в производительности.
Результаты
Не существует серебрянной пули оптимизации, подходящей всем всегда и во всех ситуациях. Ну, по крайней мере, я о такой не знаю. Например, технология Unity Dynamic batching, по своей сути также объединяющая геометрию на лету и увеличивающая за счет этого fps в данном проекте, наоборот лишь замедляла рендер.
Могу лишь дать несколько общих советов по оптимизации, которыми пользуюсь сам:
-
Перед любой оптимизацией определите, какой параметр вы хотите улучшить и создайте тест, который бы мог измерить объективные показатели интересующего вас параметра. Нельзя управлять тем, что невозможно измерить;
-
К любой оптимизации можно подходить сразу с нескольких сторон, иногда очень неожиданных и не обязательно программных. В аэропорту Хьюстона пассажиры постоянно жаловались на долгое ожидание багажа. Когда администрация увеличила штат грузчиков (увеличив свои затраты), жалобы не исчезли. Когда же они стали сажать самолеты на дальнем конце (0 затраты), и пассажирам приходилось намного дольше идти к лентам, жалобы упали почти до 0;
-
Разбивайте интересующий вас процесс на мелкие отрезки и оптимизируйте каждый из них по‑отдельности;
-
Помните, что 20% оптимизация шага, занимающего 80% общего времени, выгоднее 2х кратного ускорения процесса, занимающего всего 10%;
-
Цели можно достичь разными путями. Чем больше тропинок вы знаете, тем больше у вас вариантов для оптимизации. Поддерживайте в себе любопытство и интересуйтесь, какими еще способами можно делать те вещи, которые вы годами делали привычным способом;
-
Одна из самых долгих операций — это обращение к внешним данным. Старайтесь избегать ее, удаляйте неиспользуемые данные, сжимайте то, что можно сжать, разбейте большие данные на более мелкие и обращайтесь к ним по необходимости, используйте отдельные потоки и растягивайте эти процессы по времени;
-
Если данные уже в памяти, то всеми силами старайтесь избегать работы со строками. Они удобны для человека, но не для компьютера. Каждая конкатенация создает новую строку и выделят в памяти дополнительное место — если без этого не обойтись, используйте StringBuilder;
-
Шейдерами можно не только менять цвета, но и ОЧЕНЬ быстро манипулировать геометрией. Зачастую, скорость рендера никак не изменится, если вы добавите в вертексный шейдер простое смещение или анимацию;
-
Иногда замена алгоритма или используемой библиотеки на аналогичную может улучшить результаты в несколько раз;
-
Если у вас в проекте есть сложные расчеты, использование Burst compiler и Job System может ускорить их десятки раз;
-
Помните, что у CPU с десяток ядер, которые используются для поддержки работы всей системы, ядра Unity и вашего кода. У GPU до 10 000 процессоров. Если у вас есть задачи, которые могут быть распараллелены и выполнены на GPU — сделайте это. Иногда такой подход может дать x100 вашей задаче.
В финале скажу ещё одну, казалось, очевидную вещь. Оптимизировать можно много, долго и очень продуктивно, но «можно» не значит «нужно».
Перед тем как что‑либо оптимизировать, убедитесь, что эта оптимизация нужна вам/проекту/бизнесу, иначе может получиться, что вы будете полгода оптимизировать проект и добьетесь самой красивой графики, самого быстрого запуска, самых высоких fps, НО это ничего не будет значить, если ваша игра не будет опубликована/заказчик откажется от проекта/бизнес закроет направление/сессия закончится и вы не успеете дописать дипломную работу. Тут, как в принципе и во всем программировании, лучше идти по итеративной схеме с промежуточными шагами и постоянным фидбеком от конечного пользователя вашего продукта:
-
Находите самое проблемное место.
-
Оптимизируете его (хотя бы минимально).
-
Собираете готовый проект с улучшением.
-
Получаете фидбек по изменениям от реальных пользователей.
-
Если пользователей все устраивает продолжаете разработку, если нет — возвращаетесь на п.1.
Я постарался детально раскрыть свой подход к философии оптимизации на очень показательном примере. Если проследить, каким образом менялась скорость загрузки по мере поэтапных оптимизаций, то можно составить такой график:

Эти цифры не остались просто цифрами в вакууме. Мы смогли в разы ускорить работу приложения (и, соответственно, картографов), а наши карты сделали большой скачок в графике:

ссылка на оригинал статьи https://habr.com/ru/post/719224/
Добавить комментарий