Всем привет! На связи Андрей Нестеров, я занимаюсь компьютерным зрением в применении к мобильным приложениям в компании Friflex.
Мы создаем продукты по оцифровке спорта, которые позволяют распознавать спортивные события и анализировать их.
В этой статье я приведу простейший пример использования ChatGPT в машинном обучении, предложу несколько способов, которые помогут обращаться к ChatGPT для решения реальных задач, а также подчеркну моменты, в которых она совершенно неприменима.

Многие из нас видели большое количество новостей и различных статей про ChatGPT – нейросеть, с которой можно разговаривать, задавать вопросы, а также просить ее помочь в написании кода. Уже больше месяца я пробую использовать ее для рабочих задач и чем глубже изучаю, тем больше открываю ее скрытые возможности.
И так как дисклеймер «данная статья была написана полностью при помощи ChatGPT» больше не является чем-то новым, то по традиции, дадим слово самой ChatGPT рассказать о себе:
«Я – ChatGPT, крупнейшая модель языкового обучения, созданная OpenAI для предоставления ответов на разнообразные вопросы и участия в разговорах на различные темы. Я обучена на огромном количестве текстовых данных и могу генерировать ответы, похожие на человеческие, используя техники обработки естественного языка».
Далее обращаться мы будем к ней на английском языке. Так проще задавать вопросы, связанные с конкретной имплементацией кода.
Построение основ
Начнем наш путь к решению реальных задач при помощи ChatGPT с простейшего примера построения обучающего пайплайна для задачи классификации изображений. В данном случае, мы хотим получить основу, простейший каркас пайплайна, который далее будем усовершенствовать. В качестве примера возьмем стандартную задачу MNIST. Первым шагом попросим ChatGPT создать базовую модель для классификации изображений:
“Construct a CNN model for the MNIST task”
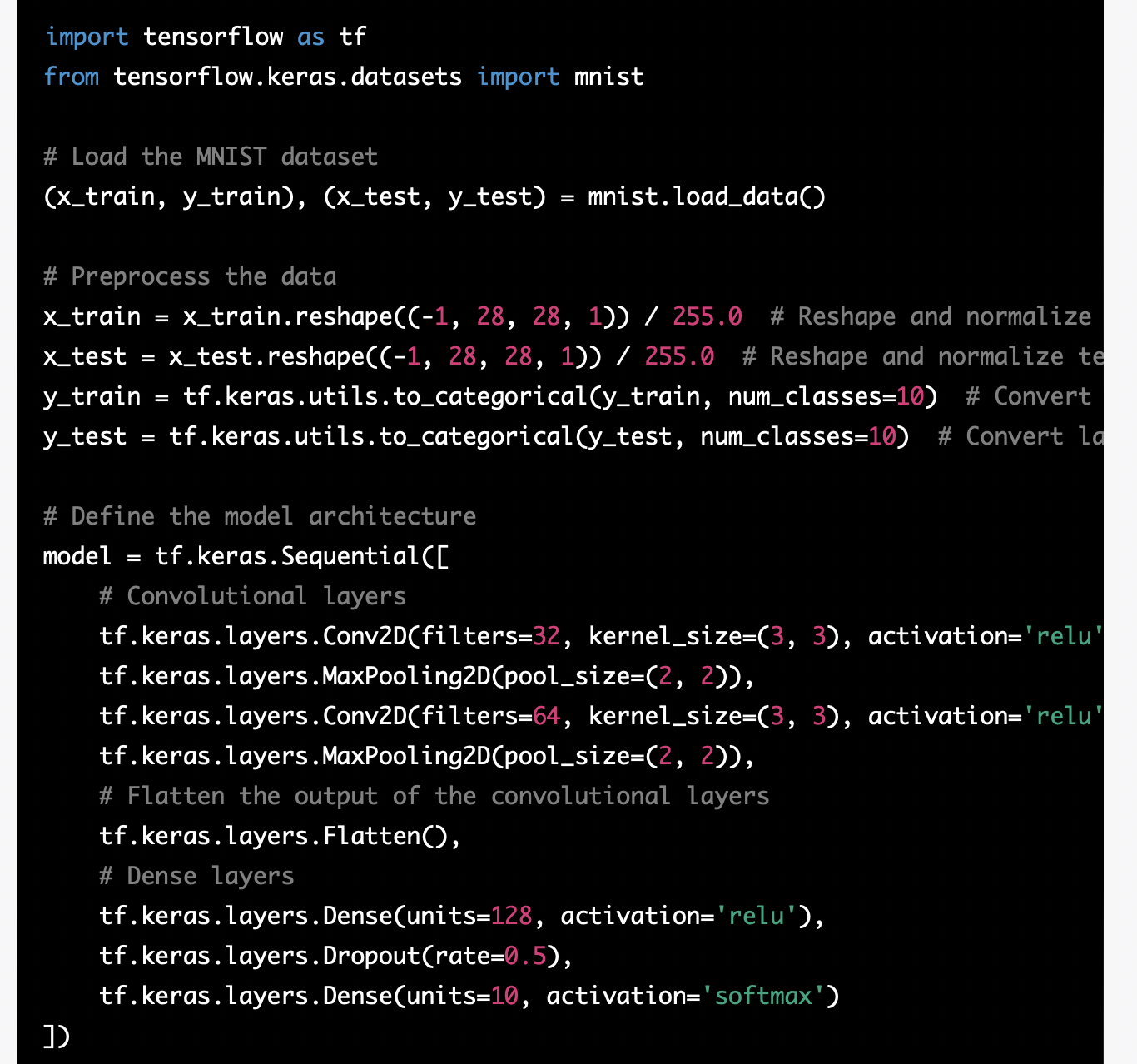
Теперь, когда модель у нас готова, запросим создать пример обучающего пайплайна.
-
“Give me a short baseline example of tensorflow data loader for image classification task using MNIST as an example”
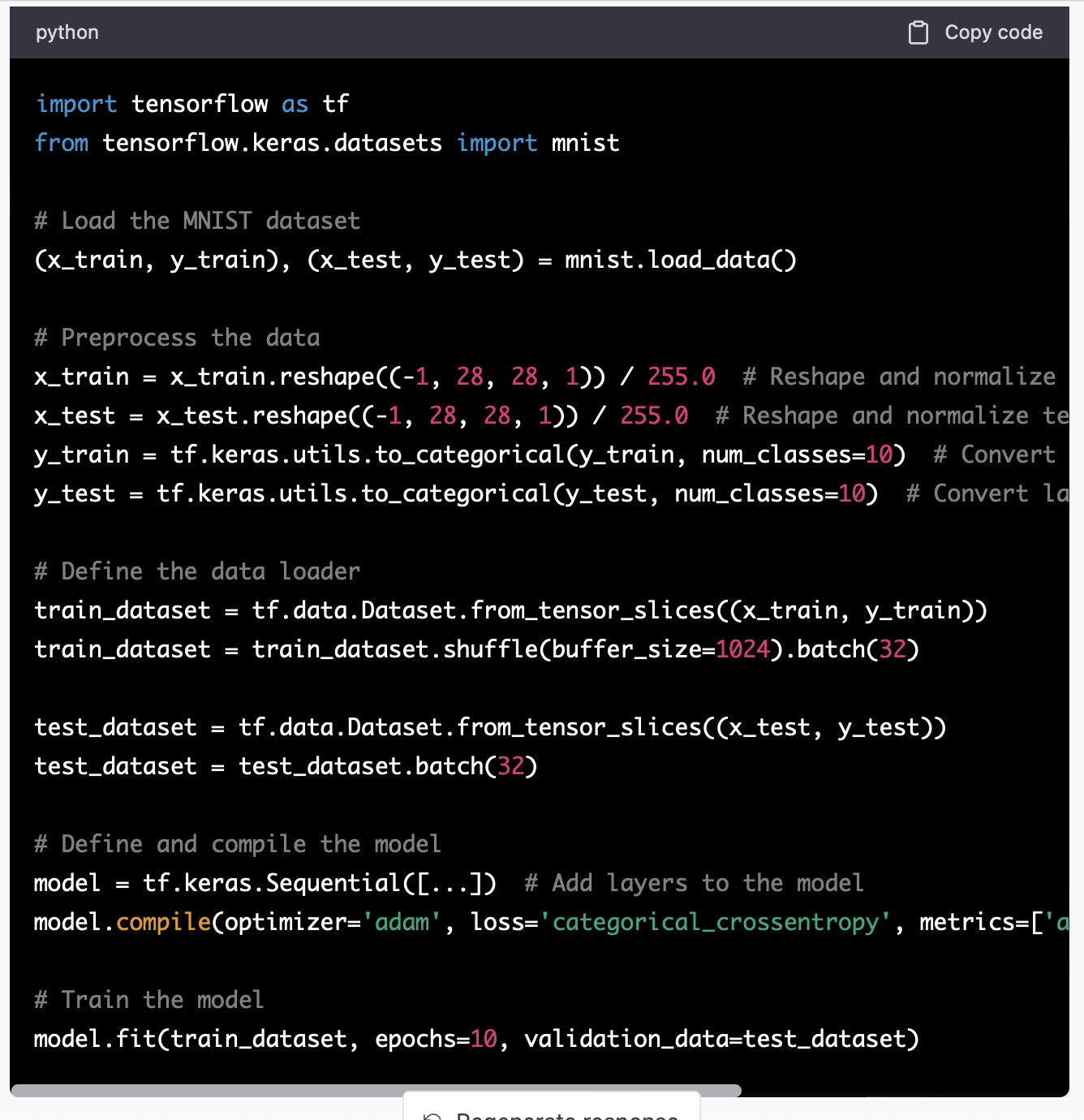
В конце попросим ее подготовить графики обучения.
-
“Create plots for training losses and accuracies”
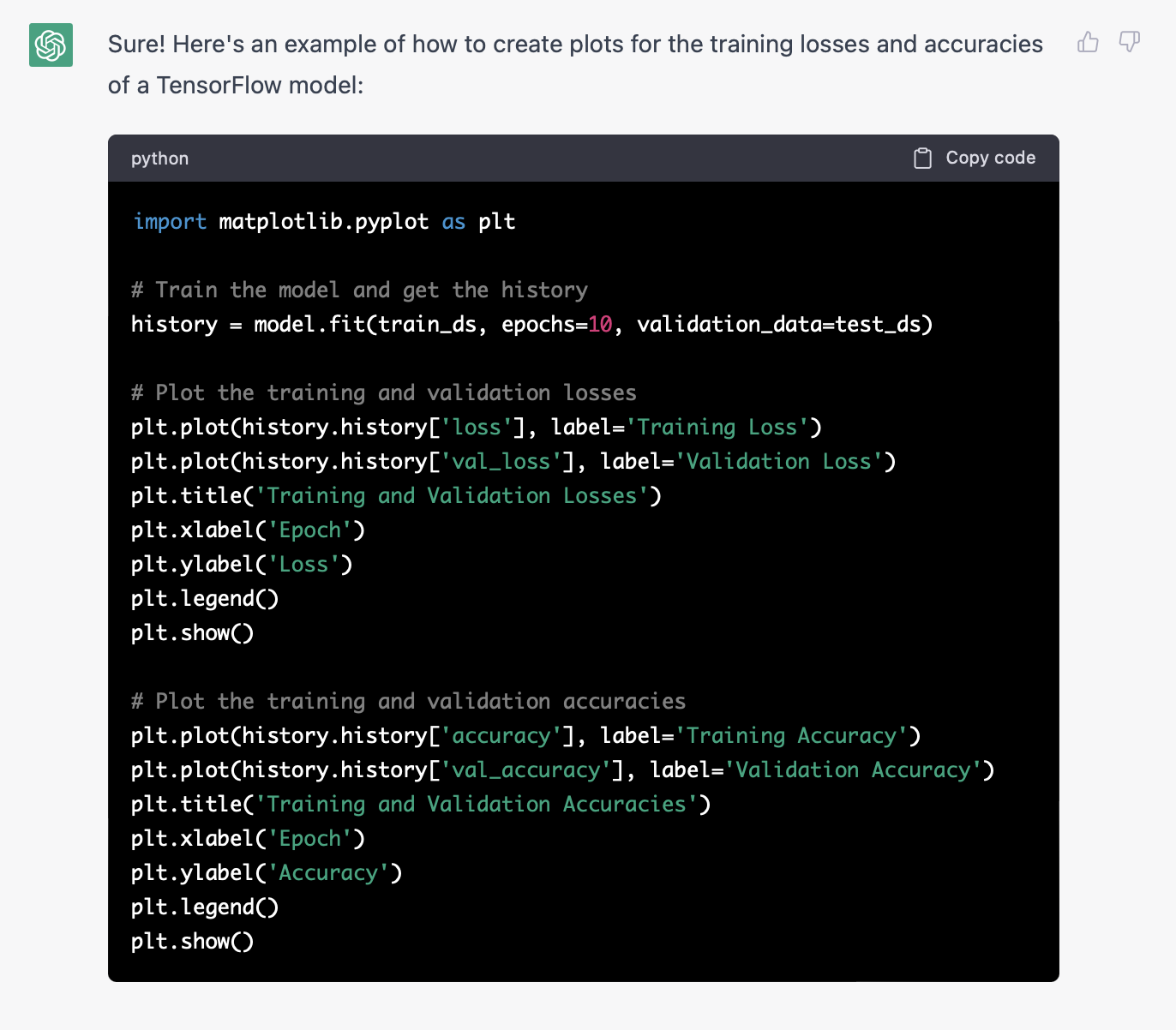
Так в несколько шагов, используя только ChatGPT, мы получили основу обучающего пайплайна на примере MNIST датасета. Теперь пора приступать к задачам, более приближенным к реальности.
Улучшение ответов
В большинстве случаев ChatGPT отлично справляется со стандартными запросами, но как добиться качественного ответа на более сложные вопросы?
-
Итеративные вопросы
ChatGPT может отвечать на последовательно заданные вопросы, ориентируясь на предыдущий разговор в контексте одного диалога. В том случае, когда вы не до конца уверены, какой ответ хотите получить или какой конкретно вопрос задать, можно последовательно подступать к желаемому результату.
Рассмотрим данную технику на одном примере. Допустим, на определенном этапе обучения мы хотим сохранить состояние оптимизатора, чтобы использовать его для другой нейросетевой модели.
-
“How to save the state of an optimizer in a keras model?”
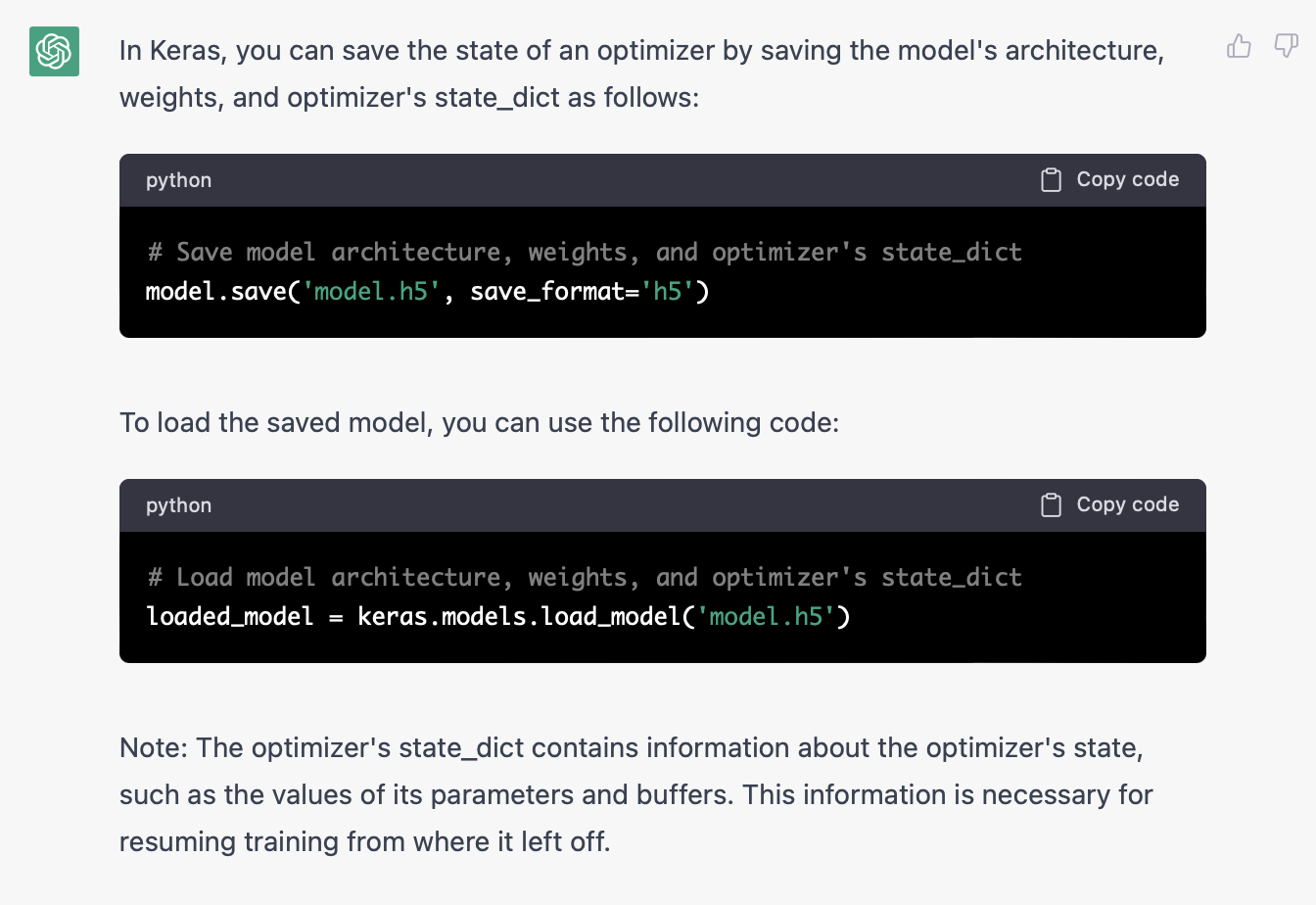
Здесь мы можем увидеть стандартный ответ. Однако, в этой задаче стоит цель получить именно состояние оптимизатора, а не всей модели.
Поэтому, чтобы получить нужный для нас ответ, зададим уточняющий вопрос:
-
“Can I save only the state of the optimizer?”

Результат выглядит уже намного ближе к желаемому. В нашем случае, когда все обучение проходит на Tensorflow, сделаем последнюю итерацию:
-
“Yes, the same but in tensorflow/keras”
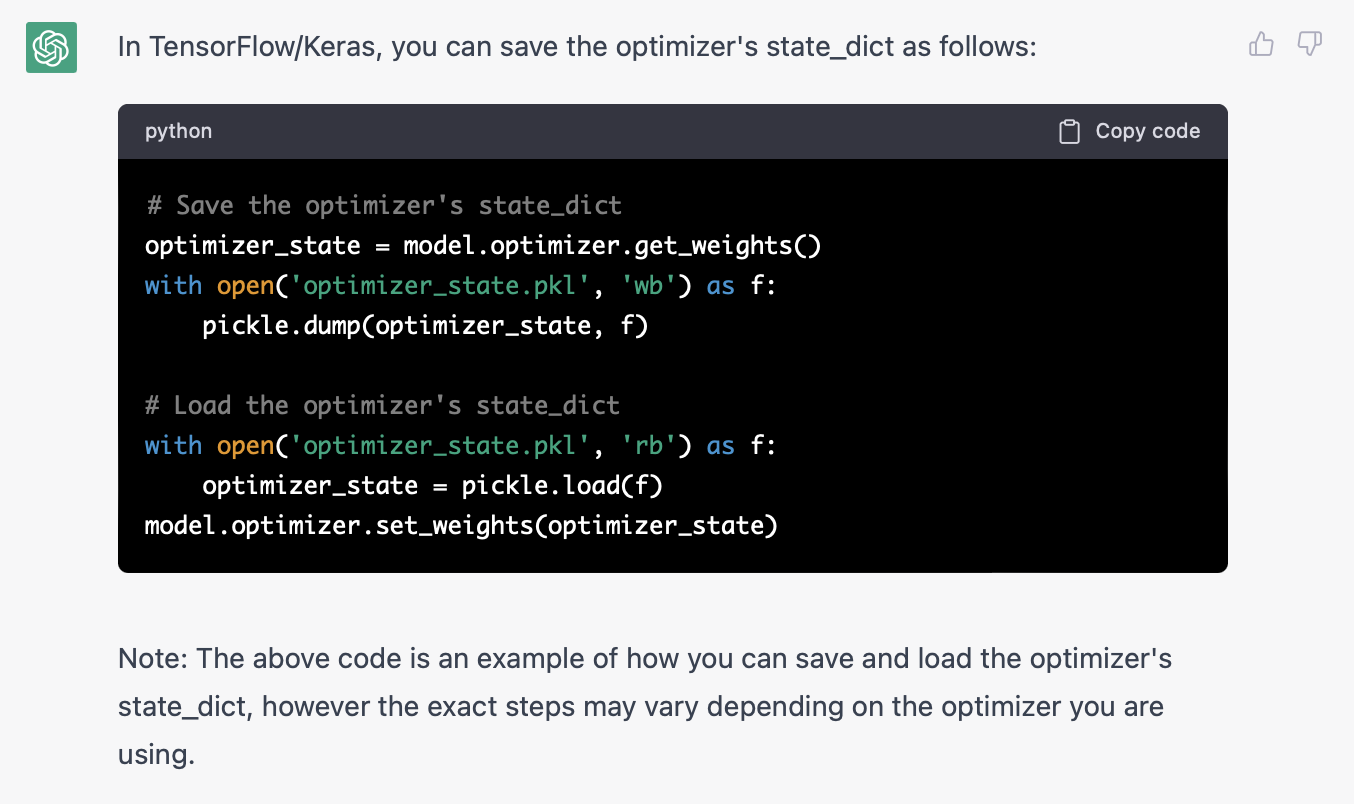
Именно то что и было нужно!
-
Детализированные запросы
ChatGPT использует большую часть всех ключевых слов, которые вы ей даете. Чем точнее запрос и чем больше в нем содержится контекста – тем больше вероятность получить качественный ответ. Этот способ может отлично подойти, когда вам понятен желаемый результат и методы его получения.
Вспомним наш пример готового бейзлайна, который мы получили в начале. Теперь мы хотим добавить аугментации в процесс обучения. Исходим из того, что мы знаем библиотеку, которую хотим использовать – Albumentations. А также, мы знаем примерный вид решения и методы, которые будут использоваться. В таком случае зададим как можно более конкретный вопрос ChatGPT:
-
“Create a tensorflow data loader for image classification task, MNIST as an example. Prepare a class called Transformation that gets a list of albumentations, uses __call__ to process a sample with tf.numpy_function”
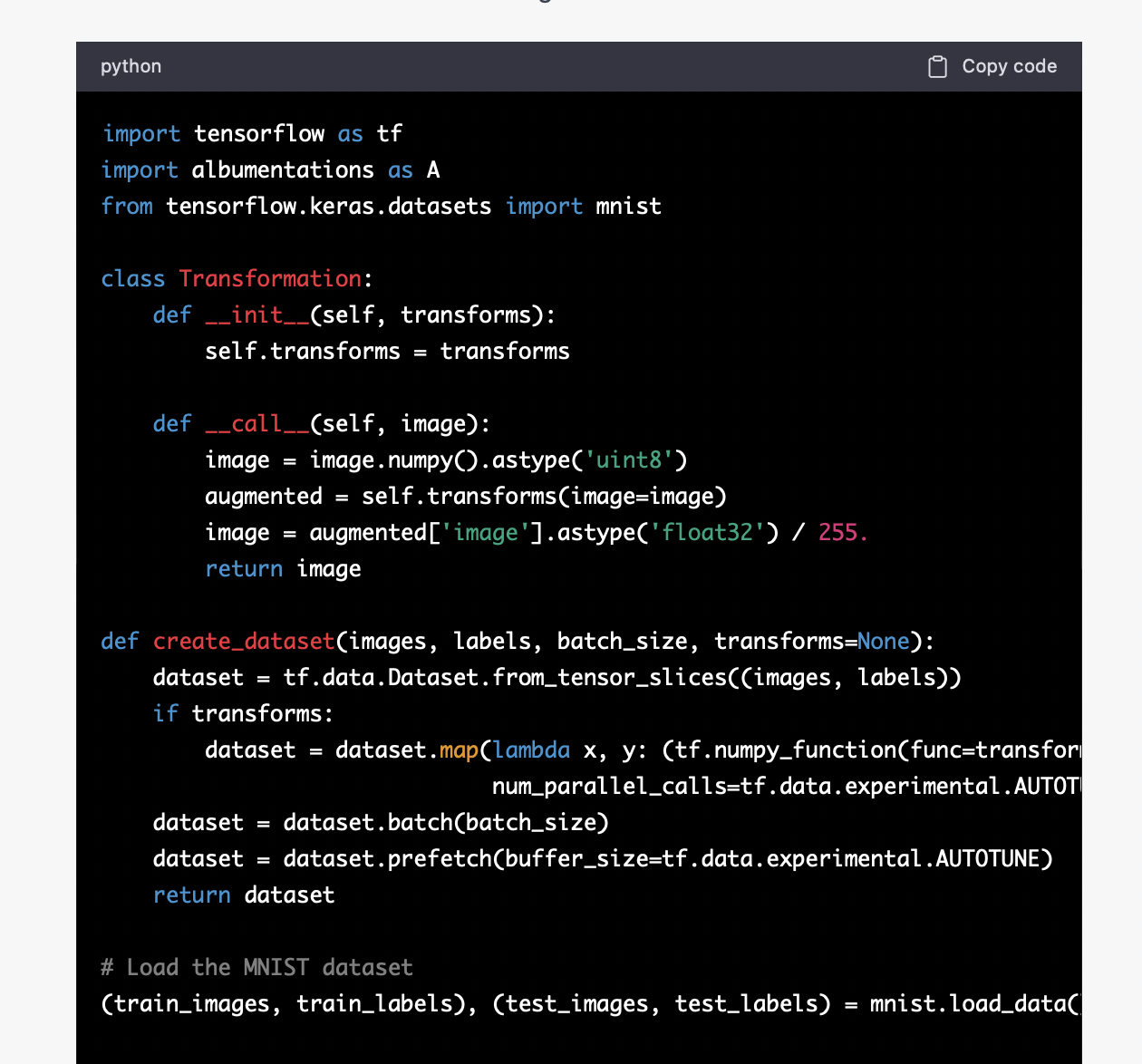
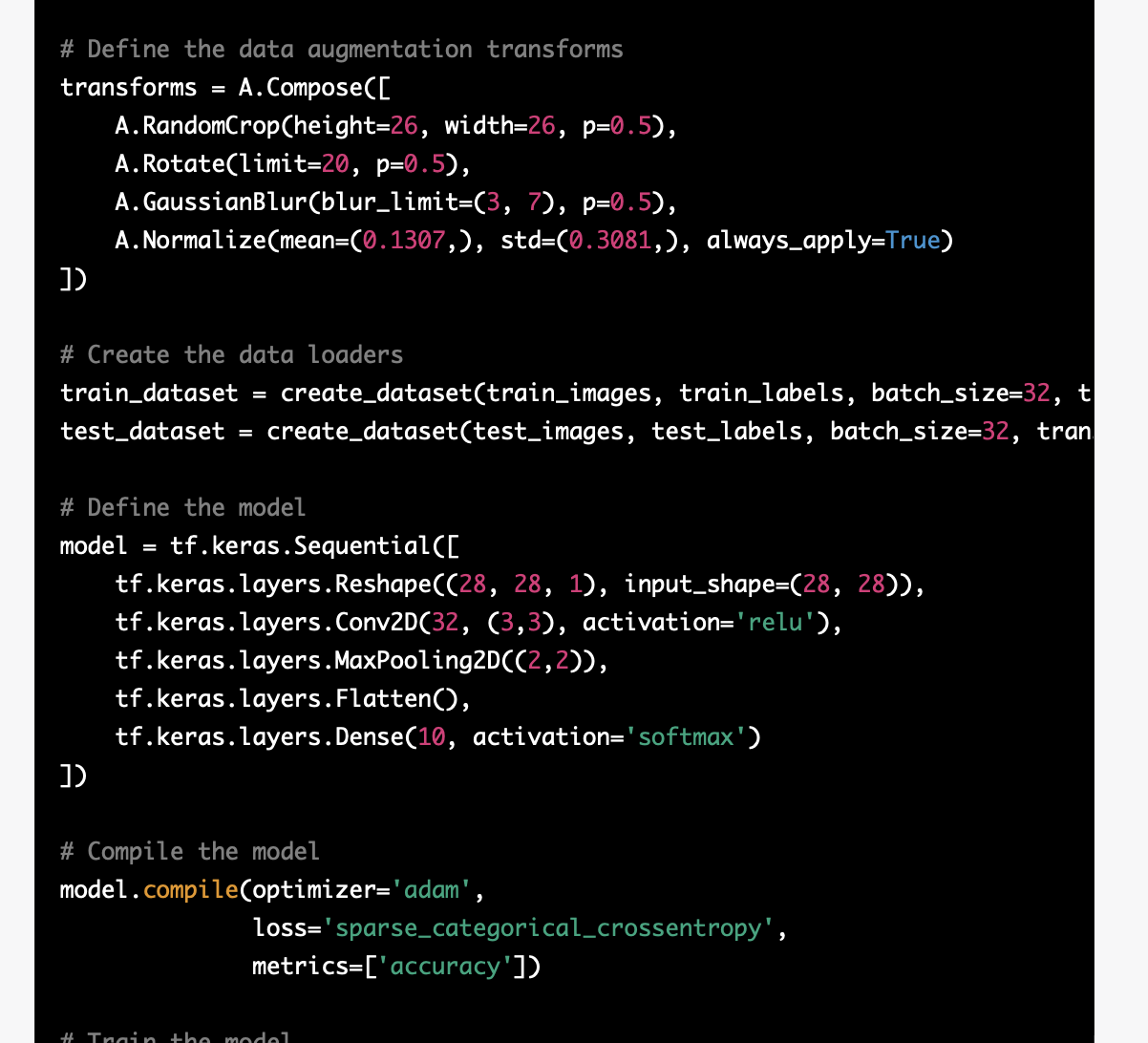
Получаем отличную обертку для аугментаций и создания Tensorflow датасета, который можем использовать в реальных задачах.
-
Корректировка ошибок
Несмотря на отличные результаты ChatGPT при точных запросах и при итеративном уточнении, данная нейросеть довольно часто выдаёт ответы, содержащие довольно очевидные ошибки. Такие проблемы вполне поддаются корректировке. В некоторых случаях достаточно сгенерировать выдачу заново. На один и тот же запрос ChatGPT может выдавать различные ответы. Какие-то из них будут лучше прочих. Также можно прямо спрашивать о том, что могло пойти не так. Вбивая в чат ошибку выдачи, ChatGPT подтягивает предыдущий разговор и старается исправиться в нужном направлении.
Например, на один из запросов, с которым мы уже сталкивались, ChatGPT выдала следующее:
-
“Provide an example of how to use albumentations on MNIST dataset with tensorflow”
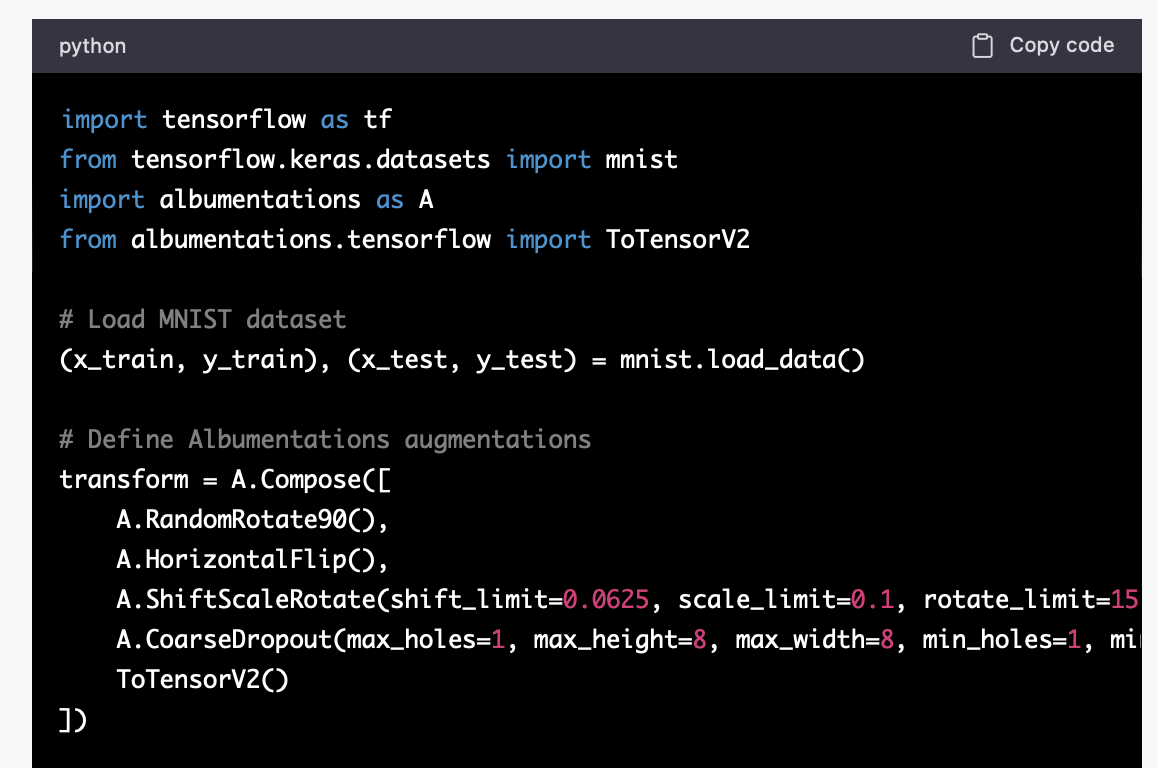
Здесь мы получаем очевидную ошибку:
-
ModuleNotFoundError: No module named ‘albumentations.tensorflow’
В данном случае ChatGPT совместила методы из PyTorch’а и Tensorflow и придумала albumentations.tensorflow.ToTensorV2. Задав тот же вопрос, на второй раз мы получаем рабочий вариант без ошибок.
Однако в некоторых случаях ни один из подходов совершенно не работает.
Допустим, мы хотим оптимизировать модель, используя метод прунинга.
-
“Give me a script for pruning a tensorflow keras model”

Как и в одном из примеров, мы получили код, в котором присутствуют несуществующие методы. При этом, если попробовать итеративно улучшить ответ, получится бесконечный цикл ошибок:
-
Q:“tf.keras.callbacks has no PruningCallback”
-
A:“My apologies, you are correct. As of my knowledge cutoff (2021), the PruningCallback was not available in the tf.keras.callbacks module. Instead, you can use the tf.keras.mixed_precision module, which provides a pruning API for both weight and activation pruning.”
…
-
A:“Sure, here’s an example of pruning a TensorFlow Keras model using the MNIST dataset and tf.keras.optimizers.schedules.PolynomialDecay:”
-
Q:(обнаруживая, что в ответе не существует таких аргументов) I think the arguments in PolynomialDecay are wrong here
-
A:“You’re correct, I apologize for the mistake. Here is the corrected version of the code using the correct arguments for tf.keras.optimizers.schedules.PolynomialDecay:”
-
Q:“This code gives me this error: RuntimeError: You must compile your model before training/testing. Use `model.compile(optimizer, loss)`.”
-
A:“… Here is an updated version of the code to include the compile step:”
-
Q:“ValueError: Index out of range using input dim 0; input has only 0 dims for ‘{{node sequential_1/prune_low_magnitude_dense_2/strided_slice}}”
…
Заключение
В данной статье мы рассмотрели пример построения основ для задачи машинного обучения, исследовали несколько способов обращения с ChatGPT для улучшения результатов выдачи и взглянули на ошибки, которые может выдавать ChatGPT, а после узнали, как с ними работать.
Несмотря на впечатляющий прогресс языковых моделей, ChatGPT не может заменить человека. Она часто совершает ошибки, выдает правдоподобные, но ложные ответы, а иногда совсем не может справиться с задачей. Однако для человека, который чувствует себя уверенно в своей области, этот инструмент может отлично пригодиться для улучшения продуктивности. Совмещая интуицию опытного специалиста и понимание, как работает данная нейросеть, можно:
-
ускорить свою разработку;
-
получать быстрые готовые варианты для прототипирования;
-
добиваться правильного решения сложной проблемы через череду уточняющих запросов.
Используете ли вы ChatGPT в своих задачах? Делитесь вашим опытом в комментариях??
ссылка на оригинал статьи https://habr.com/ru/company/friflex/blog/719988/
Добавить комментарий