
В этой статье мы поговорим об использовании Chaos Mesh — опенсорс-фреймворка для хаос-инжиниринга в Kubernetes. Все развёртывания из этой статьи доступны на GitLab. Клонируйте репозиторий и продолжайте читать.

Хаос-инжиниринг
Хаос-инжиниринг — это проведение продуманных и спланированных экспериментов, которые показывают, как система ведёт себя в непредвиденных ситуациях. Мы создаём для системы стрессовые условия и пытаемся заранее найти и исправить возможные сбои, пока не случилось что-то страшное. Сначала мы формулируем гипотезу о том, как должна вести себя система, когда что-то пойдёт не так. Затем мы разрабатываем эксперимент в минимальном масштабе. Наконец, мы на каждом этапе измеряем последствия сбоя, обращая внимание на признаки успеха и неудачи. После эксперимента мы начинаем лучше понимать поведение системы в реальном мире.
Впервые концепцию хаос-инжиниринга предложил Netflix в 2012 году. Они придумали Chaos Monkey — инструмент, который вносит разные ошибки в инфраструктуру и бизнес-систему. С этого началась история хаос-инжиниринга. Netflix создали Chaos Monkey при переходе с физической инфраструктуры в облако Amazon Web Services, чтобы убедиться, что потеря инстанса Amazon не повлияет на стабильность стриминга. Chaos Monkey случайным образом завершает инстансы виртуальных машин и контейнеры в продакшене, чтобы инженеры сразу видели, насколько их сервисы надёжны и устойчивы к незапланированным сбоям.
Chaos Mesh
Chaos Mesh — это облачная опенсорс-платформа для хаос-инжиниринга в Kubernetes. Chaos Mesh включает методы внесения ошибок для сложных систем в Kubernetes на уровне pod’ов, сети, файловой системы и даже ядра. Эксперименты можно проводить прямо в продакшене, не меняя логику развёртывания приложения. Мы в реальном времени видим состояние эксперимента и можем быстро откатывать внесённые ошибки. В Chaos Mesh есть дашборд с пользовательским веб-интерфейсом для проектирования сценариев и визуализации состояния экспериментов.
Chaos Mesh использует Kubernetes CRD (Custom Resource Definition — кастомные определения ресурсов) нескольких типов, в зависимости от места возникновения сбоев: сбои на уровне ресурсов, сбои на уровне платформы и сбои на уровне приложения.
1. Basic resource faults 1.1. PodChaos: simulates Pod failures, such as Pod node restart, Pod's persistent unavailablility, and certain container failures in a specific Pod. 1.2. NetworkChaos: simulates network failures, such as network latency, packet loss, packet disorder, and network partitions. 1.3. DNSChaos: simulates DNS failures, such as the parsing failure of DNS domain name and the wrong IP address returned. 1.4. HTTPChaos: simulates HTTP communication failures, such as HTTP communication latency. 1.5. StressChaos: simulates CPU race or memory race. 1.6. IOChaos: simulates the I/O failure of an application file, such as I/O delays, read and write failures. 1.7. TimeChaos: simulates the time jump exception. 1.8. KernelChaos: simulates kernel failures, such as an exception of the application memory allocation. 2. Platform faults: 2.1. AWSChaos: simulates AWS platform failures, such as the AWS node restart. 2.2. GCPChaos: simulates GCP platform failures, such as the GCP node restart. 3. Application faults: 3.1. JVMChaos: simulates JVM application failures, such as the function call delay.Установка Chaos Mesh
В этом эксперименте мы использовали кластер Kubernetes на базе Minikube в окружении разработки. При установке Chaos Mesh в окружении тестирования (разработки), создаётся пространство имён Kubernetes chaos-testing. Дашборд Chaos Mesh предоставляется через порт 2333 и сервис NodePort.
# install chaos mesh curl -sSL https://mirrors.chaos-mesh.org/v2.0.3/install.sh | bash # check pods kubectl get po -n chaos-testing >> output NAME READY STATUS RESTARTS AGE chaos-controller-manager-68769d9df9-qt2js 1/1 Running 0 8m48s chaos-daemon-9nhcs 1/1 Running 0 8m49s chaos-dashboard-6677f99c44-dfjzg 1/1 Running 0 8m48s # check services kubectl get svc -n chaos-testing >> output NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE chaos-daemon ClusterIP None <none> 31767/TCP,31766/TCP 9m27s chaos-dashboard NodePort 10.104.10.190 <none> 2333:31725/TCP 9m27s chaos-mesh-controller-manager ClusterIP 10.97.5.226 <none> 443/TCP,10081/TCP,10080/TCP 9m27s --- # access chaos mesh dashboard via NodePort service # dashboard run on port 2333 as NodePort service # dashboard can acess via NodePort port 2333 mapping port, in my case port 31725 http://<minikube ip>:31725 http://192.168.64.17:31725/dashboard # access dashboard via port forward 3333 -> 2333 # now dashboard can access via localhost:3333 kubectl port-forward -n chaos-testing chaos-dashboard-6677f99c44-dfjzg 8888:2333 http://localhost:3333
Эксперименты в Chaos Mesh
Есть два способа запускать эксперименты в Chaos Mesh: напрямую на дашборде или через YAML. Здесь мы запустили четыре эксперимента: pod-failure, pod-kill, stress, http-abort. В Chaos Mesh их гораздо больше — см. документацию по Chaos Mesh и интерактивные руководства. Эксперименты выполнялись в кластере nginx из трёх нод. Развёртывание кластера nginx:
apiVersion: v1 kind: Namespace metadata: name: chaos --- apiVersion: v1 kind: Service metadata: name: nginxservice labels: name: nginxservice namespace: chaos spec: ports: - port: 80 selector: app: nginx type: LoadBalancer --- apiVersion: v1 kind: ReplicationController metadata: name: nginx namespace: chaos spec: replicas: 3 selector: app: nginx template: metadata: name: nginx labels: app: nginx spec: containers: - name: nginx image: nginx ports: - containerPort: 80# deploy nginx # it will create three node nginx cluster under namespace 'chaos' kubectl apply -f nginx-deployment.yaml # view pods kubectl get pods -n chaos NAME READY STATUS RESTARTS AGE nginx-bmgbr 1/1 Running 0 36m nginx-wlr8x 1/1 Running 0 36m nginx-z9sl7 1/1 Running 0 36m # get services kubectl get svc -n chaos NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nginxservice LoadBalancer 10.96.3.122 <pending> 80:30773/TCP 37mЭксперимент со сбоями pod’а
Эксперименты PodChaos симулируют сценарии сбоя указанных pod’ов или контейнеров. Сейчас в категорию PodChaos входят типы pod-failure, pod-kill, container-kill. В следующем эксперименте Chaos Mesh внедряет pod-failure в указанный pod nginx, и pod становится недоступен на 30 секунд. Для выбора pod’а используется флаг labelSelectors. Эксперимент со сбоями pod’а:
kind: PodChaos apiVersion: chaos-mesh.org/v1alpha1 metadata: name: chaos-failure namespace: chaos spec: selector: namespaces: - chaos labelSelectors: app: nginx mode: one action: pod-failure duration: 30s gracePeriod: 0Развернуть эксперимент можно командой kubectl apply -f chaos-pod-failure.yaml. После развёртывания мы можем просматривать статус эксперимента на дашборде Chaos Mesh.

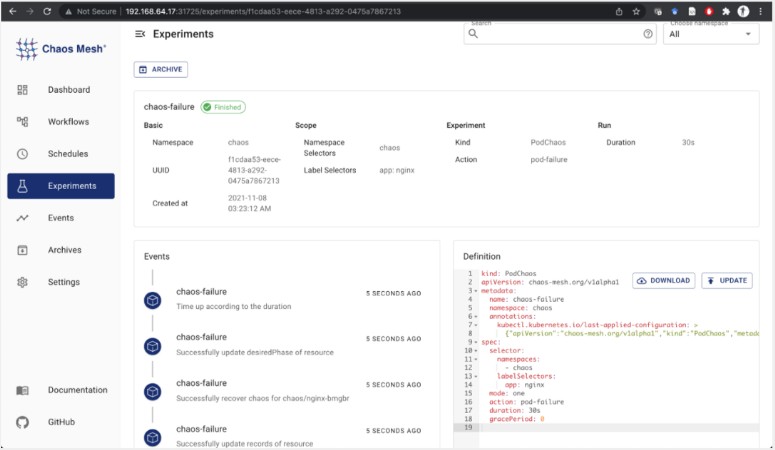
Эксперимент с уничтожением pod’а
В следующем эксперименте Chaos Mesh внедряет pod-kill в указанный pod nginx и уничтожает pod. Эксперимент с уничтожением pod’а:
kind: PodChaos apiVersion: chaos-mesh.org/v1alpha1 metadata: name: chaos-kill namespace: chaos spec: selector: namespaces: - chaos labelSelectors: app: nginx mode: one action: pod-kill duration: 30s gracePeriod: 0Развернуть эксперимент можно командой kubectl apply -f chaos-pod-kill.yaml. После развёртывания мы можем просматривать статус эксперимента на дашборде Chaos Mesh.
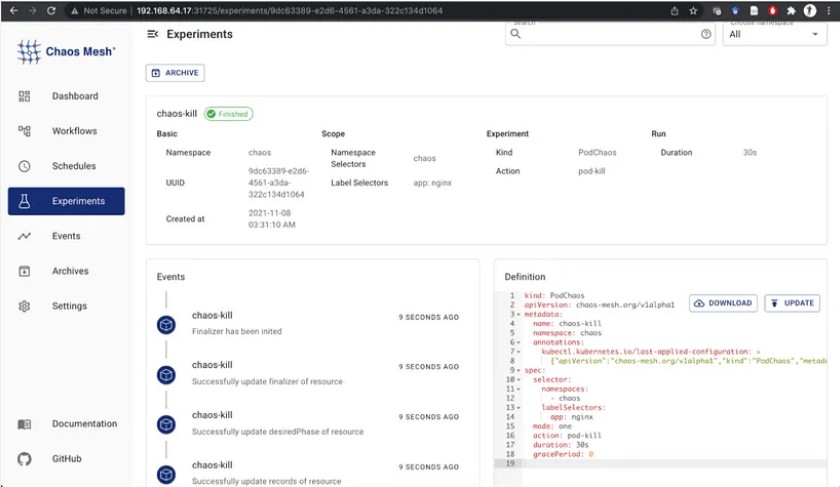
Эксперимент с перегрузкой
Эксперименты StressChaos в Chaos Mesh симулируют повышенную нагрузку в контейнерах. Следующий эксперимент создаст процесс в выбранном контейнере (nginx) и будет постоянно выделять память и выполнять чтение и запись, заняв до 256 МБ.
kind: StressChaos apiVersion: chaos-mesh.org/v1alpha1 metadata: name: chaos-stress namespace: chaos spec: selector: namespaces: - chaos labelSelectors: app: nginx mode: one containerNames: - '' stressors: memory: workers: 4 size: '256MB' duration: 60sРазвернуть эксперимент можно командой kubectl apply -f chaos-stress.yaml. Результаты эксперимента на дашборде Chaos Mesh:
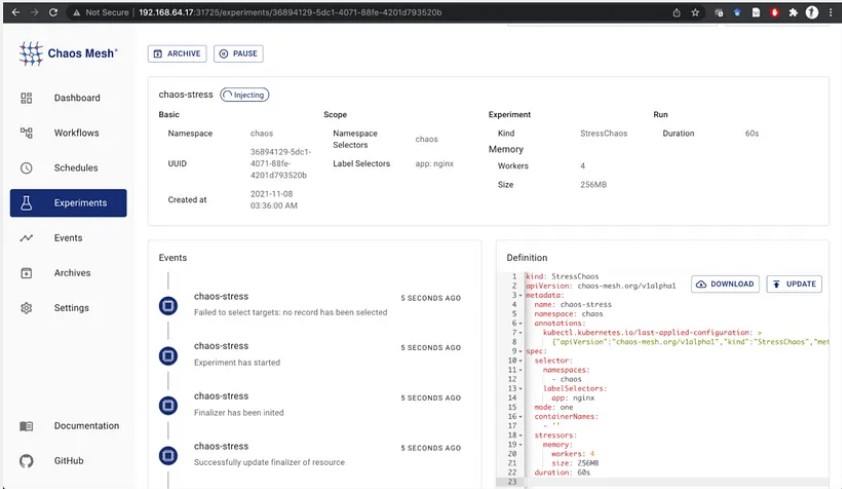
Эксперимент с прерыванием HTTP
HTTPChaos имитирует сбой HTTP-сервера во время обработки HTTP-запросов и ответов. HTTPChaos поддерживает имитацию четырёх действий: abort (прерывание), delay (задержка), replace (замена) и patch (исправление). В этом эксперименте Chaos Mesh каждые 10 минут внедряет abort в указанный pod на 5 минут. В это время запросы GET через порт 80 по пути /api на целевом pod’е будут прерваны.
apiVersion: chaos-mesh.org/v1alpha1 kind: HTTPChaos metadata: name: chaos-http-abort spec: mode: all selector: labelSelectors: app: nginx target: Request port: 80 method: GET path: /api abort: true duration: 5m scheduler: cron: '@every 10m'Развернуть эксперимент можно командой kubectl apply -f chaos-http-abort.yaml. Результаты эксперимента можно посмотреть на дашборде Chaos Mesh.
ссылка на оригинал статьи https://habr.com/ru/company/southbridge/blog/723034/
Добавить комментарий