Введение
Для автономного транспорта крайне важно решить задачу автономной навигации. Один из методов автономной навигации – это SLAM (simultaneous localization and mapping), который в зависимости от типа используемых сенсоров бывает: визуальным, визуально-инерциальным, лидарным, радарным, RGBD и др.
Сегодня особый научный и практический интерес представляют методы визуально-инерциального SLAM (viSLAM) [1, 2]. Методы viSLAM делятся на прямые и непрямые. Для непрямых методов viSLAM принципиально важна точность триангуляции трехмерных координат точек [3], которая в свою очередь зависит от точности работы детекторов ключевых точек [4].
Мы провели сравнительный анализ точности ряда существующих методов детектирования
ключевых точек, как «эвристических» (hand-crafted), так и обучаемых (trainable). О наших экспериментах и полученных результатах расскажем в данном материале.

Наш подход
Для определения точности выделения ключевых точек мы провели оценку медианных расстояний между точками и соответствующими им эпиполярными линиями для пар изображений с известной взаимной ориентацией.
Чтобы получить такую оценку, мы выполнили следующие шаги:
1) Берем пары изображений для одной из последовательностей датасета «4-seasons», устраняем дисторсию [5]. Выбор указанной последовательности обусловлен желанием протестировать алгоритмы выделения ключевых точек в условиях, приближенных к реальным условиям работы наземного беспилотного транспорта.
2) Берем соответствующие этим парам изображений значения GT-ориентации (ground-truth).
3) По данным GT-ориентации восстанавливаем фундаментальную матрицу для каждой пары изображений:
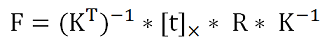
где:
K – матрица внутренних параметров камеры:
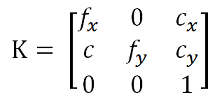
[t]× – кососимметричная матрица, получаемая из вектора смещения t = [x, y, z]:
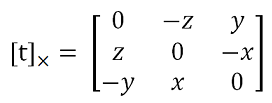
R – матрица поворота;
* – символ матричного перемножения.
def fund(T_cam_cam, mtx): shift = T_cam_cam[0:3, 3] skew = np.array([[0, -shift[2], shift[1]],[shift[2], 0, -shift[0]],[-shift[1], shift[0], 0]]) ess = np.dot(skew, T_cam_cam[0:3, 0:3]) fund = np.dot(np.dot(np.linalg.inv(np.transpose(mtx)),ess),np.linalg.inv(mtx)) return fund4) Для каждого из исследуемых методов детектирования ключевых точек выделяем точки и вычисляем их дескрипторы, где это возможно.
5) Сопоставляем выделенные точки для каждой пары изображений.
6) Фильтруем ложно-отождествленные сопоставления точек при помощи теста Лёва.
def ratio_test(matches, ratio_index): good = [] good_ind0 = [] good_ind1 = [] for m,n in matches: if m.distance < ratio_index*n.distance: good.append([m]) good_ind0.append(m.queryIdx) good_ind1.append(m.trainIdx) return good, good_ind0, good_ind17) Для прошедших фильтр пар точек выполняется two-view refinement [6] для оценки его влияния на точность выделения точек.
8) Для отфильтрованных точек при помощи фундаментальной матрицы из шага 3 рассчитываются эпиполярные линии.
9) Для прошедших фильтр и уточненных сопоставлений рассчитываются целевые метрики – расстояния от точки до ее эпиполярной линии:

где:
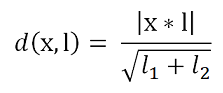

def dist_measure(kp, epi_line): dist = np.multiply(kp, epi_line) dist = np.sum(dist, axis=1, keepdims=True) dist = dist/np.linalg.norm(epi_line[:,:2], axis=1, keepdims=True) dist = np.abs(dist) return dist10) Для каждого рассмотренного метода детектирования ключевых точек оцениваются медианное и среднее расстояния от точек до эпиполярных линий – по всем ключевым точкам для всех пар изображений выборки.
Описание экспериментов
Мы выбрали для исследования ряд методов детектирования ключевых точек, признанных как наиболее точные и перспективные на основе анализа работ [7, 8, 9, 10]. Выбранные методы перечислены в таблице ниже.
Строго говоря, RLOF не является методом детектирования. Однако мы включили его в эксперимент, поскольку данный метод должен предсказывать с субпиксельной точностью положение ключевых точек, выделенных на первом изображении, для второго изображения. Для целей нашего эксперимента в части RLOF выделение ключевых точек на первом изображении выполнено методом SIFT с детектором DOG (difference of Gaussian).
Также отметим, что ORB не является одним из высокоточных методов, на которых мы фокусировались в данном эксперименте, зато характеризуется высокой скоростью работы. И хотя мы понимали, что ORB должен проигрывать остальным рассмотренным методам по точности, мы все же включили его в эксперимент, поскольку нам хотелось оценить, насколько именно он уступает высокоточным, но более медленным методам.
Для каждого из вышеперечисленных методов было проведено 2 эксперимента:
1) Эксперимент с серией пар изображений с малым межкадровым смещением
Серия содержала 39 изображений, из которых мы сформировали 38 пар. Пары образованы только из соседних изображений, последовательно полученных в процессе съемки, в результате чего смещение между двумя изображениями в паре во всех случаях оказывалось минимальным и составило в среднем примерно 1.6 метра. Пример пары последовательных изображений с малым смещением представлен ниже:

2) Эксперимент серией пар изображений с большим межкадровым смещением
Мы получили данную серию, создав пары из 39 изображений первоначальной серии таким образом, чтобы межкадровое смещение между двумя изображениями вновь образованных пар составляло порядка 20 метров. Для этого мы формировали пары, пропуская каждые 11 изображений первоначальной серии, то есть создали пары из изображений: №0 – №12, №1 – №13, №2 – №14 и т.д. В результате был получен набор из 27 пар изображений. Пример пары последовательных изображений с большим смещением представлен ниже:

Для визуальной оценки распределения ключевых точек мы вывели на изображениях детектированные точки и соответствующие им эпиполярные линии. Ниже представлен пример такой визуализации для всех рассмотренных методов, примененных к паре изображений с большим межкадровым смещением.

Результаты
1) Результаты для серии пар изображений с малым межкадровым смещением
В этом эксперименте были получены значения расстояний от точек до эпиполярных линий, представленные в таблице ниже:
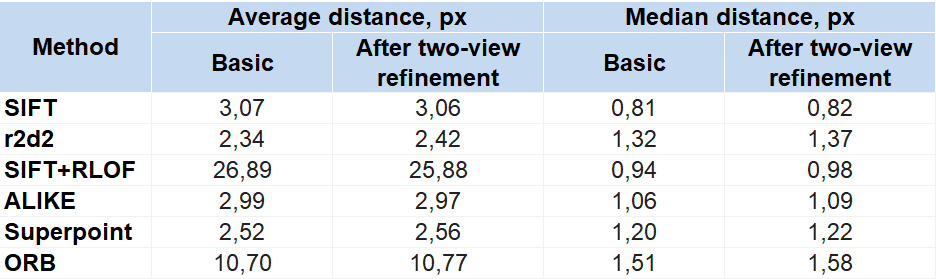
Для серии пар изображений с малым смещением метод SIFT показал максимальную точность идентификации ключевых точек, то есть минимальное медианное расстояние от точек до эпиполярных линий.
Также хорошие показатели медианного расстояния дали методы RLOF и ALIKE. При этом метод RLOF характеризуется наличием существенных выбросов и худшим среди всех исследованных методов показателем среднего расстояния от точек до эпиполярных линий.
Заметим, что только методы SIFT и RLOF позволили достичь субпиксельной точности на малой стереобазе.
Метод ORB в данном эксперименте дал худший результат, с почти двукратным превышением медианного расстояния от точек до эпиполярных линий относительно соответствующего показателя лидирующего метода SIFT (1.51 vs. 0.81 px).
Следует отметить, что для серии пар изображений с малым смещением two-view refinement не дал положительного эффекта ни для одного из исследованных методов идентификации ключевых точек. Это касается даже метода SIFT, использовавшегося при обучении модели two-view refinement в [6].
2) Результаты для серии пар изображений с большим межкадровым смещением
По итогам нашего второго эксперимента были получены значения расстояний от точек до эпиполярных линий, представленные в таблице ниже:

Для серии пар изображений с большим смещением максимальную точность идентификации ключевых точек, то есть минимальное медианное расстояние от точек до эпиполярных линий, дал метод r2d2. Второе место по точности в данном эксперименте занял метод Superpoint.
Метод SIFT, показавший лучший результат в первом эксперименте, оказался лишь третьим для изображений с большим смещением. Его медианное расстояние от точек до эпиполярных линий – в 1.6 раза выше, чему у лидирующего в данном эксперименте метода r2d2 (4.97 vs. 3.16 px).
Методы ALIKE и RLOF, давшие хорошую точность для изображений с малым межкадровым смещением, во втором эксперименте продемонстрировали слабый результат. Их медианные расстояния от точек до эпиполярных линий оказались многократно выше, чем у метода r2d2: в 3 раза выше у метода ALIKE и в 8 раз – у метода RLOF, что ожидаемо для любого из методов оптического потока при большой стереобазе.
Метод ORB снова показал самую низкую точность: его медианное расстояние от точек до эпиполярных линий оказалось в 15 раз выше, чем у метода r2d2.
Отметим, что в эксперименте с серией изображений с большой стереобазой two-view refinement дал некоторое улучшение точности идентификации пар ключевых точек только для метода Superpoint. Для всех остальных рассмотренных методов two-view refinement оказался неэффективен. Его негативное влияние было наиболее существенным для метода r2d2.
Выводы
По результатам проведенных экспериментов мы рекомендуем для максимизации точности при решении задач без ограничений на время обработки данных (например, для оффлайн построения карт для беспилотного транспорта, реконструкции 3D-сцен методом SFM) использовать:
-
метод SIFT для данных с малым межкадровым смещением;
-
метод r2d2 для данных с большим межкадровым смещением.
Источники:
[1] Cheng J et al (2022) A review of visual SLAM methods for autonomous driving vehicles. https://www.sciencedirect.com/science/article/abs/pii/S0952197622001853
[2] Bala JA, Adeshina SA, Aibinu AM (2022) Advances in Visual Simultaneous Localisation and Mapping Techniques for Autonomous Vehicles: A Review. https://pubmed.ncbi.nlm.nih.gov/36433549/
[3] Herrera DC et al (2014) DT-SLAM: Deferred Triangulation for Robust SLAM. https://www.kihwan23.com/papers/3DV14/dtslam_3dv14.pdf
[4] Murphy TC (2022) Examining the Effects of Key Point Detector and Descriptors on 3D Visual SLAM. https://etd.ohiolink.edu/apexprod/rws_etd/send_file/send?accession=ouhonors1461320700&disposition=inline
[5] Wenzel P et al (2020) A Cross-Season Dataset for Multi-Weather SLAM in Autonomous Driving. https://arxiv.org/abs/2009.06364
[6] Dusmanu M, Schönberger JL, Pollefeys M (2020) Multi-View Optimization of Local Feature Geometry. https://arxiv.org/abs/2003.08348
[7] Revaud J et al (2019) R2D2: Repeatable and Reliable Detector and Descriptor. https://arxiv.org/pdf/1906.06195.pdf
[8] Bojanic D et al (2020) On the Comparison of Classic and Deep Keypoint Detector and Descriptor Methods. https://arxiv.org/pdf/2007.10000.pdf
[9] Zhao X et al (2022) ALIKE: Accurate and Lightweight Keypoint Detection and Descriptor Extraction. https://arxiv.org/pdf/2112.02906.pdf
[10] Senst T, Eiselein V, Sikora T (2012) Robust Local Optical Flow for Feature Tracking. http://elvera.nue.tu-berlin.de/files/1349Senst2012.pdf
ссылка на оригинал статьи https://habr.com/ru/post/724580/
Добавить комментарий