Эта серия статей представляет собой исчерпывающий обзор системных паттернов проектирования для обучения, обслуживания и эксплуатации систем машинного обучения в производственной среде.
Цели
Главная задача этой статьи — перечислить и описать системные паттерны для проектирования систем машинного обучения в производственной среде. Паттерны проектирования, которые помогают в разработке моделей машинного обучения, достигающих определенных показателей точности, не являются приоритетом, хотя для некоторых из перечисленных паттернов такие юзкейсы все-таки будут указаны.
Минимальные требования
Все системные паттерны машинного обучения, приведенные здесь, предназначены для развертывания в публичной облачной среде или на кластере Kubernetes. В рамках подготовки обзора мы пытались максимально абстрагироваться от конкретных языков программирования или платформ, хотя, поскольку Python является наиболее значимым языком для технологии машинного обучения, большинство шаблонов можно реализовать с применением Python.
Источник
Полный список всех паттернов можно найти здесь:
GitHub Pages
Примеры реализации
Некоторые примеры реализации доступны по ссылке ниже: https://github.com/shibuiwilliam/ml-system-in-actions
Паттерны
Паттерны проектирования обслуживающих систем
Паттерны обслуживающих систем — это набор готовых проектных решений, которые можно использовать для организации производственных рабочих процессов, предполагающих использование моделей машинного обучения.
Паттерн “Единый веб-сервер” (Web single pattern)
Применение
-
Когда вам нужно быстро зарелизить предиктор в самой простой архитектуре.
Архитектура
Паттерн “Единый веб-сервер” предлагает архитектуру, в рамках которой все артефакты и код для модели прогнозирования заключены в одном веб-сервере. Поскольку в этом паттерне REST (или GRPC) интерфейс, предварительная обработка и обученная модель находятся в одном месте (на сервере), вы можете создать и развернуть их в виде простого предиктора.
Если вам нужно развертывать сразу несколько реплик, для доступа к ним вам придется реализовать балансировщик нагрузки или прокси-сервер. Если вы используете в качестве интерфейса GRPC, то вам всерьез стоит подумать о реализации балансировки нагрузки на стороне клиента или layer-7 балансировщика.
Чтобы встроить вашу модель в веб-сервер, вы можете воспользоваться паттерном “модель в образе” или паттерном с загрузкой модели.
Диаграмма
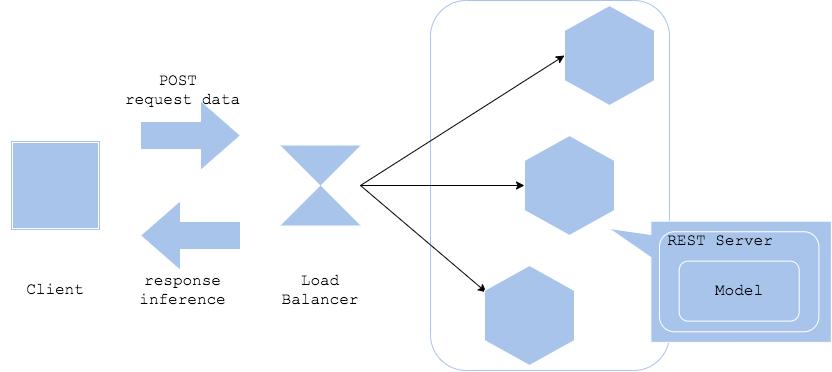
Плюсы
-
Возможность использовать один язык программирования, например Python, для веб-сервера, предварительной обработки и логического вывода.
-
Удобен в управлении из-за своей простоты.
-
Проще устранять неполадки.
-
Минимальные затраты времени на дообучение модели.
-
В качестве стартовой производственной архитектуры обычно рекомендуется именно развертывание на едином веб-сервере с синхронной обработкой.
Минусы
-
Так как все компоненты заключены в один сервер или докер-образ, даже небольшой патч потребует обновления всего образа.
-
Обновления также потребуют развертывания сервиса, что в более крупных организациях требует выполнения серьезного SDLC.
О чем нужно подумать
-
Процедуры обновления и обслуживания для каждого компонента.
-
Масштабирование предполагает изменения в управлении веб-сервером.
Пример
Паттерн синхронной обработки (Synchronous pattern)
Применение
-
Вывод модели блокирует переход к следующему шагу в вашей бизнес-логике.
-
Когда ваш рабочий процесс зависит от вывода.
Архитектура
Паттерн синхронной обработки реализует синхронный процесс прогнозирования. В нем рабочий процесс блокируется до завершения прогнозирования. Если вы разрабатываете сервер логических выводов c REST или GRPC, то скорее всего он будет реализовывать паттерн синхронной обработки. Это один из самых простых в использовании паттернов, поскольку весь его рабочий процесс можно визуализировать простым пошаговым алгоритмом.
Диаграмма

Плюсы
-
Легкий в управлении благодаря своей простоте. Все операционные аспекты, такие как отслеживание транзакций, мониторинг и т.д., также довольно просты.
-
Рабочий процесс сервиса тоже довольно прост, поскольку процесс не будет продолжаться, пока прогноз не завершится.
Минусы
-
Задержка прогнозирования может стать узким местом в производительности.
-
Возможно, вам придется что-то придумывать, чтобы не портить пользовательский опыт задержкой на прогнозирование.
-
Если клиентом вашего сервиса является другой сервис, то этот шаблон неминуемо станет причиной блокировки потоков на стороне клиента.
О чем нужно подумать
-
Вам нужно придумать что-нибудь, чтобы сгладить влияние задержки прогнозирования на пользовательский опыт.
-
Требуются тайм-ауты, если задержка слишком велика.
Пример
Паттерн асинхронной обработки (Asynchronous pattern)
Применение
-
Когда текущий процесс не зависит от предсказания.
-
Чтобы отделить клиента, который делает запрос прогнозирования, от места назначения, где ожидается ответ.
Архитектура
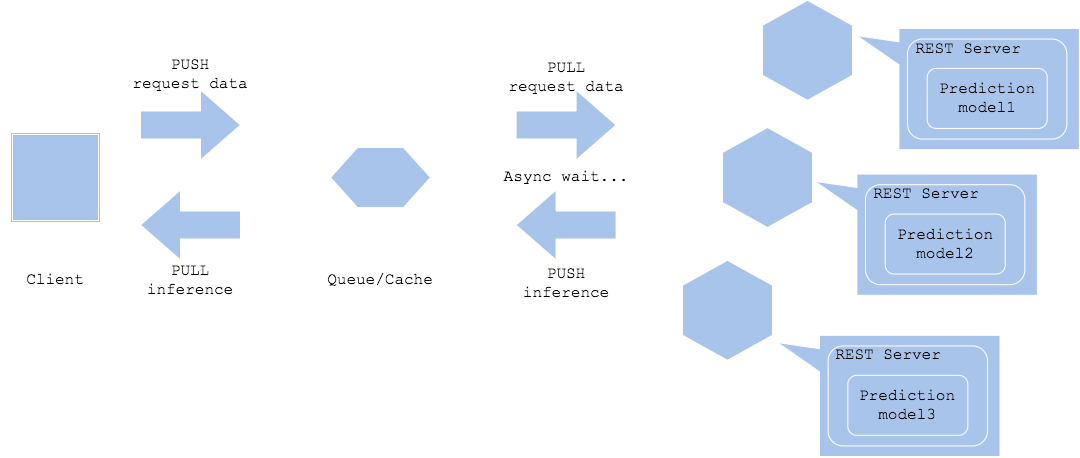
Паттерн асинхронной обработки предполагает разделение запроса прогноза и извлечения прогноза с помощью очереди или кэша между клиентом и предиктором. Это позволит клиенту не стопориться из-зв задержки на получение вывода модели. Чтобы клиент мог получить прогноз, необходимо добавить какого-нибудь агента, чтобы получить результат из очереди. Если вы хотите, чтобы результат прогнозирования был получен ресурсом, отличным от клиента, например, как на Диаграмме 2, то он может перейти к следующему шагу, не дожидаясь завершения прогнозирования.
Кроме того, как в случае, описанном на Диаграмме 1, так и для Диаграммы 2, вы можете заставить сервер прогнозов передавать результат другому компоненту. Но это требует от вас тщательной проработки такого варианта использования. так как и система, и сам рабочий процесс становятся довольно сложным.
Диаграмма
Диаграмма 1
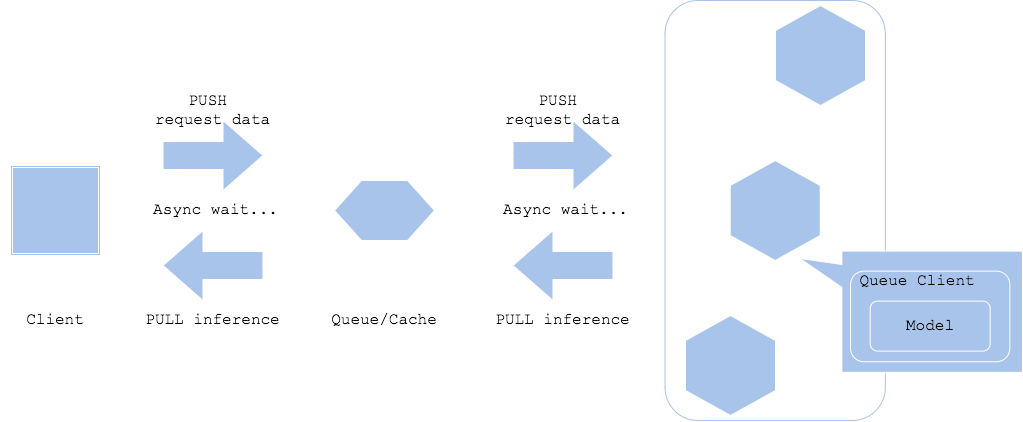
Диаграмма 2
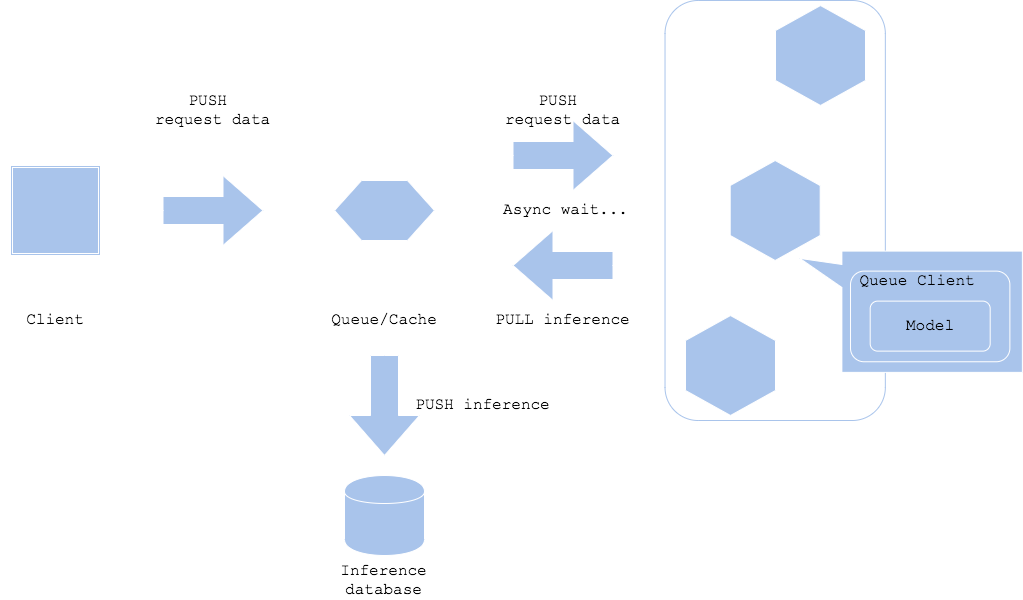
Плюсы
-
Вы можете разделить клиент и прогнозы.
-
Клиенту не нужно ждать, пока будет сгенерирован прогноз.
Минусы
-
Требуется очередь, кэш или какой-нибудь другой посредник.
-
Не подходит для использования в реальном времени.
О чем нужно подумать
-
Как запустить предсказание:
-
Очередь: прогноз будет FIFO
-
Кэш: зависит от доступного кэша
-
PubSub: подписка предиктора на запуск предсказания
-
-
Необходимо учитывать ошибку прогнозирования:
-
Если вам нужно повторить попытку, рассмотрите возможность запуска повторной попытки на сервере прогнозирования или возврата в очередь.
-
Если ошибка вызвана проблемой с данными или программой, может быть вероятность того, что запрос будет повторяться до тех пор, пока вы не удалите его вручную.
-
-
Поскольку паттерн не поддерживает упорядоченное предсказание, вам нужно будет как следует проработать ваш рабочий процесс, если в вашем варианте использования важен порядок ввода или событий.
Пример
Паттерн пакетной обработки (Batch pattern)
Применение
-
Если нет необходимости в прогнозировании в реальном или почти реальном времени.
-
Если прогнозы должны отрабатываться для большого количества данных.
-
Если запуск прогнозов можно запланировать; ежечасно, ежедневно, еженедельно или ежемесячно.
Архитектура
Если вам не нужно запускать прогнозы в реальном времени, вы можете реализовать паттерн пакетной обработки для запуска прогнозов с желаемым интервалом. Вы можете запланировать пакетное прогнозирование для большого количества данных на регулярной основе, например, ежедневно, и сохранять результаты. Конечно, вы также можете выполнять прогнозы ежечасно или даже ежемесячно, в зависимости от ваших потребностей. Этот паттерн требует, чтобы сервер управления задачами запускал пакетную задачу (batch job). Управляющий сервер запустит задачу в соответствии с заданными вами правилами. Сервер прогнозирования будет развернут в рамках запуска пакетной задачи. Если вы используете какой-нибудь облачный сервис или Kubernetes, привязка запуска и удаление сервера к задачам позволит вам значительно сократить расходы, поскольку сервер не должен будет работать круглосуточно и без выходных.
Диаграмма
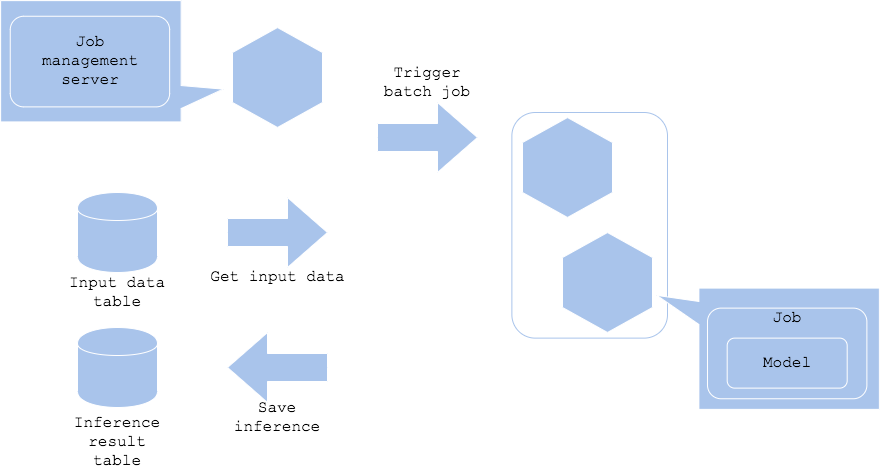
Плюсы
-
Вы можете гибко управлять ресурсами сервера в строгом соответствии со спросом.
-
Вы можете перезапустить задачу в случае ошибки.
-
В вашей серверной системе нет требований к высокой доступности.
Минусы
-
Вам нужен сервер для управления задачами.
О чем нужно подумать
-
Вам нужно будет выбрать пакет (батч), или диапазон, или набор данных для прогнозирования в рамках одной задачи. Если размер набора данных для определенного интервала слишком велик, его обработку необходимо разделить и скоординировать между несколькими мини-задачами.
-
Если у вас есть определенное ограничение по времени на получение результатов прогнозирования, то вам необходимо будет брать в расчет расписание пакетных задач и ресурсы сервера. Если обработка пакета приходится на ночь, то скорее всего вам будет успеть закончить работу к следующему утру.
-
Варианты перезапуска задачи в случае сбоя:
-
Повторить все: повторно выполнить прогноз для всего пакета. Используется, когда прогноз или данные имеют какие-либо взаимозависимости.
-
Частичная повторная попытка: повторно запустить набор данных, в котором произошел сбой. Используется при отсутствии зависимости.
-
Без повторных попыток: запустить прогноз для давшего сбой набора данных в следующем пакете. Используется, когда нет строгого ограничения по времени.
-
-
Если временные рамки пакета достаточно свободные, например, один раз в месяц или один раз в год, настоятельно рекомендуется мониторить и делать пробные запуски пакетной обработки, поскольку модель или система могут устареть.
Пример
Паттерн вертикальной организации микросервисов (Microservice vertical pattern)
Применение
-
Когда вам нужно получить несколько выводов по порядку.
-
Когда у вас есть несколько логических выводов, и между ними есть зависимости.
Архитектура
Паттерн вертикальной организации микросервисов позволяет запускать несколько моделей по порядку. Паттерн предполагает развертывание моделей прогнозирования на отдельных серверах или в контейнерах в качестве сервисов. Вы выполняете запрос на прогнозирование синхронно сверху вниз и собираете результаты для ответа клиенту. Если порядок прогнозов имеет значение, то паттерн вертикальной организации микросервисов — отличный выбор. Он также позволяет вам разделить жизненный цикл обслуживания, локализовать сбои, а также развертывать серверы независимо.
Вы можете разместить между клиентом и сервисами прогнозирования прокси-сервер. Скорее всего этот прокси-сервер и будет контролировать порядок извлечения данных и прогнозирования. Вы можете позволить прокси-серверу или даже самим предикторам выполнять дополнительное извлечение нужных данных (Диаграмма 2). Преимущество использования прокси для извлечения данных заключается в том, что он уменьшит количество запросов к DWH или хранилищу, что уменьшит накладные расходы. Если реализовать извлечение в предикторах, то это позволит вам контролировать структуру данных в зависимости от конкретной модели прогнозирования, благодаря чему вы сможете выстроить более сложный рабочий процесс.
Диаграмма
Диаграмма 1
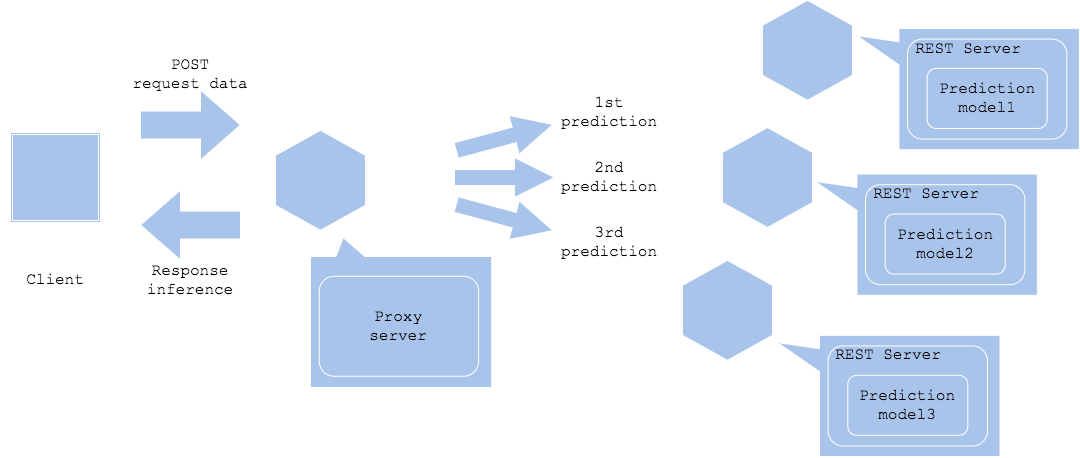
Диаграмма 2
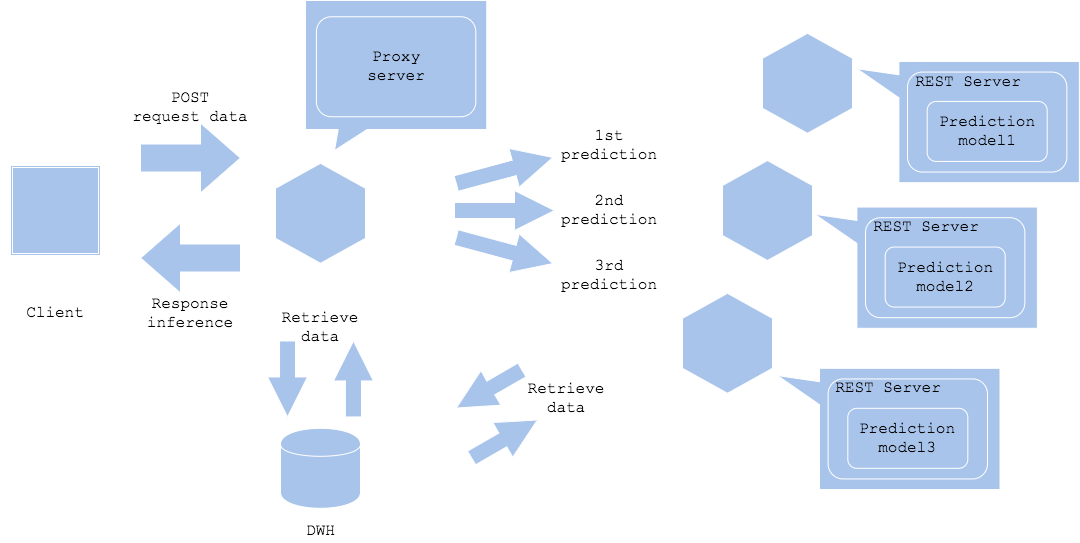
Плюсы
-
Вы можете запускать несколько прогнозов по порядку.
-
Можно выбирать следующий сервис-предиктор в зависимости от результата текущего предсказания.
-
Вы можете сделать использование ресурсов более эффективным, независимым от сервера и кода и изолировать сбой.
Минусы
-
Поскольку прогнозы выполняются в синхронном порядке, это выльется в более высокую задержку.
-
Вышеупомянутая задержка предсказания может оказаться серьезным узким местом.
-
Сложная структура системы и рабочего процессы.
Что нужно учитывать
-
Возможно, вам придется повозиться с оптимизацией производительности, чтобы соответствовать требуемому уровню обслуживания.
-
Структура системы неминуемо будет сложной. Лучше стараться делать интерфейсы и серверы общими.
Паттерн горизонтальной организации микросервисов
Применение
-
Когда рабочий процесс может выполнять несколько прогнозов параллельно.
-
Когда вы хотите получить совокупный результат прогнозирования.
-
Требуется для запуска нескольких прогнозов для одного запроса.
Архитектура
Паттерн горизонтальной организации микросервисов позволяет параллельно запускать несколько независимых моделей. Вы можете отправить один запрос сразу к нескольким моделям, чтобы получить несколько прогнозов или один совокупный прогноз. Можно получать в качестве ответа агрегированный результат или просто конкретный прогноз.
Вы можете выбрать синхронный или асинхронный режим в зависимости от вашего варианта использования. Если вы решите работать синхронно, может потребоваться совершать ответ с результатом после агрегированных прогнозов из всех моделей. Если рабочий процесс будет асинхронным, вы можете запустить следующее действие сразу после получения определенного прогноза (Асинхронная горизонтальная реализация).
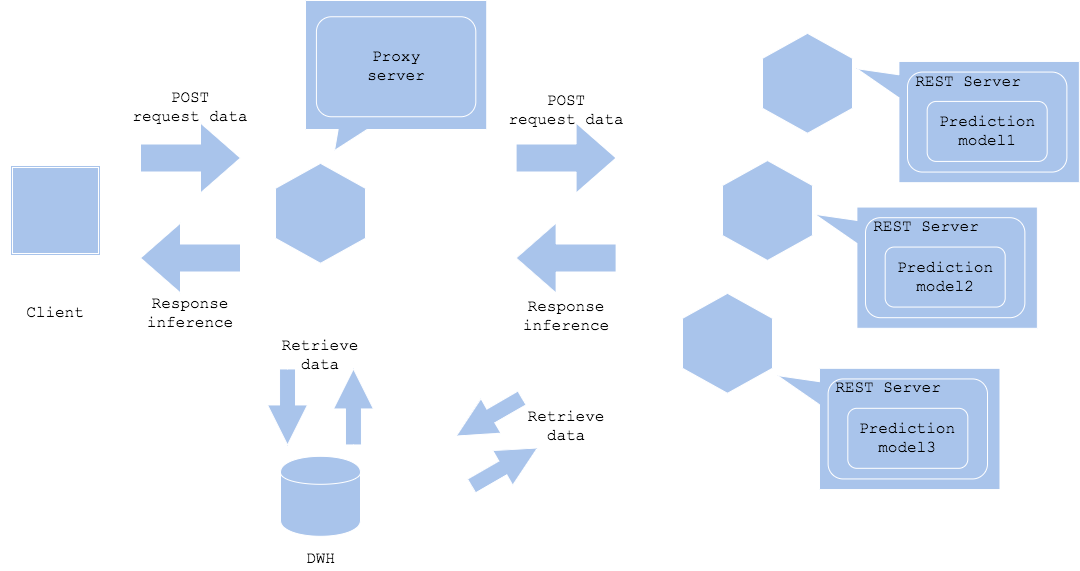
Вы можете разместить прокси-сервер между клиентом и сервисами-предикторами. Опять же, прокси-сервер может контролировать порядок извлечения данных и прогнозирования вне клиента. Вы можете позволить прокси-серверу или каждому из предикторов выполнять дополнительный поиск данных (Синхронизированная горизонтальная реализация с извлечением данных). Преимущество использования прокси для извлечения данных заключается в том, что он уменьшит количество запросов к DWH или хранилищу, что уменьшит накладные расходы. Если реализовать извлечение в предикторах, то это позволит вам контролировать структуру данных в зависимости от конкретной модели прогнозирования, благодаря чему вы сможете выстроить более сложный рабочий процесс.
Диаграмма
Синхронная горизонтальная реализация
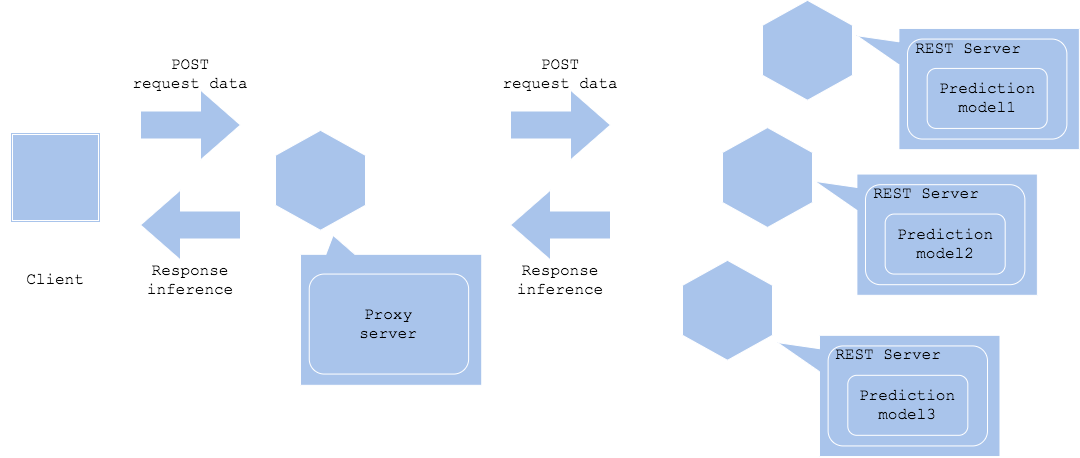
Синхронная горизонтальная реализация с извлечением данных
Асинхронная горизонтальная реализация
Плюсы
-
Вы можете независимо настраивать использование ресурсов и изолировать сбой.
-
Вы можете разрабатывать модель и систему, которая не будет зависеть от других моделей.
Минусы
-
Система может стать очень сложной.
-
Для синхронного варианта использования самый медленный вывод становится узким местом.
-
Для асинхронного варианта использования вы должны подключить постпроцессор, который будет управлять задержками прогнозирования.
О чем нужно подумать
-
Нужно выбрать синхронный или асинхронный вариант.
-
Что делать с медленной синхронной моделью: тайм-аут или ожидание.
-
Как управлять задержкой для асинхронного режима.
Пример
Представьте ситуацию: данные ещё умещаются на дисковый массив, но 16 ядер уже явно не хватает для быстрой обработки. Dask готов помочь, предоставляя возможность для распределенных вычислений на нескольких узлах. Поддерживать отдельный Dask-кластер из такого большого числа узлов становится нерентабельным, и мы переезжаем в общий Spark-кластер. Но благодаря pandas API on Spark всё еще остаемся вместе с так полюбившимся нам многоликим зверьком. Приходите сегодня вечером на открытый урок — обсудим всё подробнее.
ссылка на оригинал статьи https://habr.com/ru/companies/otus/articles/735170/
Добавить комментарий