В последнее время на Хабре уже несколько раз всплывала тема сложности загрузки видео из VK для дальнейшего просмотра оффлайн. Я решил подойти к этому вопросу с помощью создания телеграм-бота.
У нового бота сразу несколько преимуществ над другими решениями:
-
Не нужно ставить никаких дополнительный приложений или плагинов: скорее всего Telegram и так уже установлен на телефоне и/или на компе.
-
Возможна автоматическая синхронизация между устройствами: можно поставить на закачку на компе, а тот же файл появился в телефоне.
-
Можно просматривать / прослушивать видео / аудио с выключенным экраном телефона (привет, премиум подписки vk.com/youtube.com).
-
Можно выбрать необходимый формат аудио или видео различного качетсва.
Что мы хотим получить в результате?
Задача бота заключается в том чтобы трансворфмировать ссылку, полученную от пользователя, в аудио / видео выбранного формата. То есть сначала пользователь присылает ссылку на видео из VK, потом бот предлагает формат для скачивания.
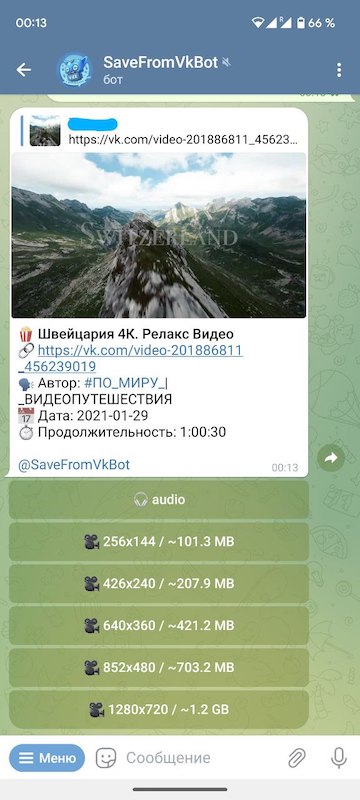
А после выбора формата в ответ бот присылает соответствующее видео.
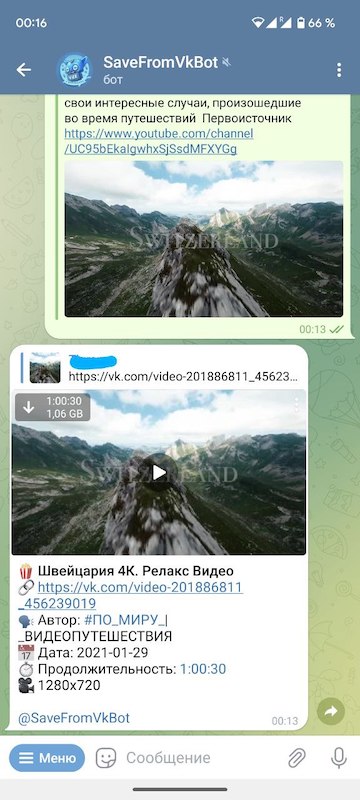
Выбор способа скачивания
Только вот как получить из ссылки вида https://vk.com/video-201886811_456239019нужный файл для скачивания? Можно воспользоваться VK API, которое предоставит временную ссылку на файл. А можно попытаться «выковырить» данные из страницы с помощью javascript, как это делается в соседних статьях.
Но всё это требует не только глубого погружения в особенности VK, что довольно трудоёмко. А ведь мы хотим делать бота расширяемым, чтобы для добавления нового источника (youtube, rutube и т.д.) не пришлось бы погружаться в новое API.
Поэтому я решил воспользоваться уже готовым решением, а именно проектом youtube-dl, а точнее его форком — yt-dlp (о разнице между этими двумя проектами можно почитать здесь).
Это консольная утилита, написанная на python, в которой уже реализована поддержка более 1000 видео-хостингов. Таким образом добавление нового сайта (к примеру, youtube-а) дело небольшого допиливания конфига. По крайней мере, так казалось в теории, но на практике у каждого хостинга свои особенности, с которыми нужно разбираться.
Собственно, на этом этапе я принял решение не ограничиваться одним vk — пусть бот скачивает и с youtube.com тоже.
Разбираемся с yt-dlp cli
Пользоваться проектом довольно удобно и даже не обязательно устанавливать ни python, ни даже yt-dlp себе на компьютер, все можно запустить его через докер.
К примеру, для получения списка форматов запускаем:
docker run --rm -it jauderho/yt-dlp:latest https://vk.com/video-6246566_163356305 -FОтвет будет примерно таким:
[vk] Extracting URL: https://vk.com/video-6246566_163356305 [vk] -6246566_163356305: Downloading JSON metadata [vk] -6246566_163356305: Downloading m3u8 information [info] Available formats for -6246566_163356305: ID EXT RESOLUTION FPS │ FILESIZE TBR PROTO │ VCODEC VBR ACODEC ABR ───────────────────────────────────────────────────────────────────────────────────────── hls-146 mp4 256x144 25 │ ~ 4.23MiB 146k m3u8 │ unknown 146k unknown 0k hls-365 mp4 426x238 25 │ ~10.57MiB 365k m3u8 │ unknown 365k unknown 0k url240 unknown_video 240p │ https │ unknown unknown url360 unknown_video 360p │ https │ unknown unknown hls-738 mp4 640x360 25 │ ~21.36MiB 738k m3u8 │ unknown 738k unknown 0k hls-1067 mp4 852x478 25 │ ~30.87MiB 1067k m3u8 │ unknown 1067k unknown 0k url480 unknown_video 480p │ https │ unknown unknownА для скачивания видео в нужном формате запускаем (здесь -f hls-1067— это формат из таблицы выше):
docker run --rm -it -v $(pwd)/downloads:/tmp jauderho/yt-dlp:latest https://vk.com/video-6246566_163356305 -o "/tmp/%(extractor)s/%(format_id)s/%(extractor)s%(id)s.%(ext)s" -f hls-1067 -N 10 --print after_move:filepathА раз уж мы умеем оборачивать скачивалку в docker image, то тут один шаг и до kubernetes job. Зачем усложнять и делать job? А это сразу дает нам и retry, и удобный api для мониторинга статуса, и автоматическую очистку ресурсов после завершения задачи.
Итак, с «движком» определились, дело за малым — «склеить» запросы из телеги с запросами в yt-dlp.
Немного system design-а
Если порисовать картинки в стиле system-design собеседований, то верхнеуровнево схема, к которой я пришел, выглядит следующим образом.

Обработка запроса на загрузку конкретного видео, выполняются в следующей последовательности:
-
На первом шаге запрос из telegram-a попадает в Local Bot API Server (о том что это, и зачем он нужен — ниже).
-
Local Bot API передает запрос нашему приложению с помощью http webhook (почему именно
webhook, а неlong-polling, также — ниже). -
Spring Boot приложение принимает запрос, создаёт и запускает kubernetes job-у, для загрузки видео, после чего переходит в режим ожидания завершения работы job-ы.
-
Kubernetes job-а начинает скачивать видео из источника (vk.com/youtube.com) в выбранном формате.
-
Источник отдает файл нашей job-е, плюс, в случае необходимости, применяются пост-обработки.
-
Как только файл скачен, job-а заканчивает работу, передавая ссылку на файл в Spring Boot приложение.
-
Приложение сохраняет полученные метаданые в PostgreSQL базу (в дальнейшем, повторная загрузка данного видео не потребуется).
-
Приложение отправляет файл в Local Bot API — сервер.
-
Local Bot API сервер отправляет видео в Telegram.
Telegram Local Bot API server и зачем он нужен?
Большинство ботов для telegram взаимодействуют с дефолтным endpoint-ом https://api.telegram.org для отправки запросов и это работает. Но у этого способа есть ограничение на пересылку файлов более 50 МБ. А так как подавляющее большинство видео не вписываются в этот лимит, то нам этот способ не подойдет.
Благо, Telegram сам предоставляет решение для этой проблемы: нужно настроить Local Bot API Server. Помимо того, что он поднимает лимит на размер загружаемого файла в 40 раз (до 2000 МБ), он также позволяет при загрузке видео ссылаться на него с помощью file URI scheme, а не http-scheme.
Плюс, так как Local Bot API Server находится внутри нашего kubernetes-кластера и держит соединение с Telegram Cloud API, нам больше нет необходимости выставлять наше приложение наружу кластера (настраивать dns, конфигурировать cert-manager, настравивать ingress и т.д.). Плюс, взаимодействие telegram local bot api <-> spring boot app внутри кластера будет осуществляться по протоколу http, а не https, и все вопросы шифрования и безопасности Local Bot API Server берёт на себя.
Более того, всё уже украдено сделано до нас, и для Local Bot API Server-а существует docker-образ, завернуть который в kubernetes service не составляет особых проблем. Главное, не забыть к deployment-у «привязать» тот же PersistentVolumeClaim, который привязывается кyt-dlp job-ам.
Конфиг deployment-а telegram local bot api
apiVersion: apps/v1 kind: Deployment metadata: name: tdlightbotapi namespace: savefromvk labels: app.kubernetes.io/name: tdlightbotapi spec: selector: matchLabels: app.kubernetes.io/name: tdlightbotapi template: metadata: labels: app.kubernetes.io/name: tdlightbotapi spec: volumes: - name: pv-downloads persistentVolumeClaim: claimName: pvc-downloads containers: - name: tdlightbotapi image: tdlight/tdlightbotapi ports: - containerPort: 8081 - containerPort: 8082 env: - name: TELEGRAM_API_HASH value: < api - hash > - name: TELEGRAM_API_ID value: < api - id > - name: TELEGRAM_LOCAL value: "true" - name: TELEGRAM_VERBOSITY value: "1" - name: TELEGRAM_STAT value: "true" volumeMounts: - mountPath: "/downloads" name: pv-downloadsИспользование Spring Boot для бота
Так как я программирую в первую очередь на Java, то spring boot — вполне естественный выбор. Создаем новый проект, добавляем jpa, postgresql, actuator, flyway и spring-cloud-starter-kubernetes. В моём случае, я ещё решил выбрать Kotlin вместо Java, чтобы убить двух зайцев: не только написать бота, но и попрактиковаться в новом для меня языке.
Для Java есть 3 библиотеки для работы с Telegram, и мой выбор пал на TelegramBots, как имеющую поддержку spring-а. Правда, довольно быстро выяснилось, что поддержка спринга устаревшей версии 2.x, а потому работает криво.
Помимо этого, в довесок к самой библиотеке в качестве зависимости идёт Project Grizzly, который был немедленно выжжен каленым железом исключен с помощью gradle exclude. У нас все быстро и легковесно, никакой javaee нам не нужен. Принять http-request и отправить http-response мы можем и сами.
Glassfish — не нужен
configurations.all { exclude(group = "com.fasterxml.jackson.jaxrs") exclude(group = "org.glassfish.jersey.inject") exclude(group = "org.glassfish.jersey.media") exclude(group = "org.glassfish.jersey.containers") exclude(group = "org.glassfish.jersey.core") }Но всеми минусами этой либы можно пренебречь, ведь главное, что в ней есть — это замапленные с помощью jackson-аннотаций классы объектов и методов API. Собственно большего нам и не нужно, всю остальную обвязку сделаем сами.
О том, как зарегистрировать бота, всё уже разжеванно миллион раз, так что не буду повторяться. Нам же необходимо определиться, в каком режиме будет работать бот — long-polling или webhooks.
Long-polling хорошо подходит для быстрого старта и небольших ботов: минимальный конфиг и нет необходимости выставлять наш сервис в интернет (да ещё и с корректным ssl-сертификатом).
Но если мы хотим работать из kubernetes-а, где будет запущен сервис на несколько pod-ов, и притом они регулярно будут подниматься новые и убиваться старые, это решение не подходит. Значит выбираем webhook, а на этапе локальной разработки воспользуемся ngrok.
Собственно в самом приложении ничего особо хитрого нет. Нам достаточно единственного @RestController-а, который будет принимать все запросы со стороны Telegram. Далее, в зависимости от типа запроса (загрузка метаданных или загрузка видео), запускается соответствующая job-а. После чего мы дожидаемся результата работы job-ы, сохраняем метаданные в БД и отправляем ответ обратно в telegram.
Исключая неважные вещи, код controller-а:
TelegramController.kt
@RestController class TelegramController( private val handlers: List<TelegramMessageHandler>, ) { @PostMapping("/telegram") fun telegram(@RequestBody update: Update): Any { // validation checks and early return // ... // ... val handler = handlers.first { handler -> handler.canHandle(update) } handler.handle(update) return ResponseEntity.noContent().build<Unit>() } }Интерфейс обработчика запроса позволяет расширять бота и добавлять новые команды, не задевая старые:
TelegramMessageHandler.kt
interface TelegramMessageHandler { fun canHandle(update: Update): Boolean fun handle(update: Update) }Для взаимодействия с kubernetes-кластером я использовал fabric8-client в spring-овой обвязке. Саму job-у я сконфигурировал с помощью yaml-файла и запускал её из приложения, передавая лишь environment variables URL и FORMAT. Вот как выглядит пример запуска kubernetes-job-ы:
MediaExtractorHandler.kt
private fun extractMediaInternal(id: Long, url: String, format: String, isVideo: Boolean): String { val name = "extract-media-job-${id}" val jobTemplate = kubernetesClient.batch().v1().jobs().load(extractMediaJobDefinition.url).get() val job = JobBuilder(jobTemplate) .editMetadata() .withName(name) .endMetadata() .editSpec() .editTemplate() .editSpec() .editContainer(0) .withImage(image) .withName(name) .addToEnv( EnvVarBuilder().withName("URL").withValue(url).build(), EnvVarBuilder().withName("FORMAT").withValue(format).build(), ) .endContainer() .endSpec() .endTemplate() .endSpec() .build() val resource = kubernetesClient.batch().v1().jobs().resource(job) resource.createOrReplace() val finishedJob = resource.waitUntilCondition({ it.status.succeeded == 1 || it.status.failed == 1 }, 2, TimeUnit.MINUTES) logger.info("Job finished with status {}", finishedJob.status) val logs = kubernetesClient.batch().v1().jobs().withName(name).getLog(true) if (finishedJob.status.failed == 1) { logger.info("Job {} failed with output: \n{}", name, logs) throw JobFailedException(finishedJob.status, logs) } return logs.lines().last(String::isNotEmpty) }Настройка Kubernetes кластера
Как только мы запилили минимально работающее приложение, следующий шаг — деплой. Для старта нам не обязательно брать «полноценный» kubernetes, вполне достаточно лёгковесного k3s. Его можно развернуть поверх обычных виртуалок, достаточно иметь ssh-доступ. А вот если нагрузка начнет серьёзно расти, то тогда уже можно будет переезжать на «честный» kubernetes.
Вместе с k3sup запустить kubernetes-кластер можно меньше чем за 5 минут. И это реально быстрее, чем поднимать SaaS kubernetes на большинстве облачных провайдеров, плюс очень удобно для тестов.
One-liner для поднятия кластера:
k3sup install --host mybot.mydomain.com --user ubuntu --local-path ~/.kube/config --merge --context mycontext --k3s-extra-args '--tls-san 11.22.33.44 --disable traefik'Далее накатываем необходимый минимум для работы бота:
-
gitlab-agent (необходим для корректной работы gitlab CI/CD)
-
настройки PersistentVolume+PersistentVolumeClaim для временного хранения видео
PostgreSQL и Kubernetes
Про настройку базы расскажу немного подробнее. Вообще опираться на stateful-сервисы в kubernetes — довольно скользкая тема, имеющая много подводных камней. Некоторые даже считают, что это anti-pattern. Ведь гораздо проще: взять условный RDS, в котором из коробки будут и бэкапы, и мониторинг, и алерты, и масштабирование.
Но раз уж решили всё делать в kubernetes-е, то можно попробовать и базу тоже настроить cloud-native way. Большое спасибо компании flant, за обзоры на postgresql-operators (1, 2, 3). Ознакомившись с вариантами, я выбрал CloudNativePG, в котором из коробки и отказоустойчивость, и бэкапы, и поддержка мониторига.
Пользоваться оператором понравилось, для быстрого старта достаточно установить helm-чарт, а вот настройки backup-ов в режиме wal потребовали небольшой допилки напильником.
Spring Boot и Helm chart
Как только все подготовительные сервисы развернуты, очередь непосредственно за ботом. Для удобного развертования его в kubernetes, хорошо бы обернуть его в helm-chart, что облегчит последующую настройку deploy-я, версионирование, rollback в случае багов и т.д.
Для создания chart-а на основе нашего приложения выполняем:
helm create helmЭта команда создает примерно такую структуру helm-chart файлов в нашей директории:

После чего допиливаем настройки до нужного состояния в файле helm/values.yaml. В моём случае, я поменял image/repository, добавил imagePullSecrets/name, отключил ingress и проставил нужные env переменные.
Запуск
Теперь, когда все элементы мозайки собраны, запускаем бота и приступаем к тестированию. Ествественно, не всё идёт гладко с первого раза, постоянно вылезают косяки и «особенности» vk.com/youtube.com, но после n-ного количества итераций тест-фикс-деплой-тест, доводим бота до ума.
Попробовать самому можно по ссылке https://t.me/SaveFromVkBot. Бот находится в бета-версии, поэтому возможны косяки и баги. Со временем всё починим.
Планы
В планах расширение функционала бота, а именно:
-
Поддержка видео-хостингов: rutube, одноклассников, instagram-а.
-
Автоматическое «вырезание» нативной рекламы, а также доставших всех блоков «ставьте лайки, подписывайтесь на канал» из видео (с помощью SponsorBlock).
-
Поддержка скачивания видео большого размера: телеграм накладывает ограничение в 2 ГБ на файл, так что большие файлы нужно разбивать на части.
-
Поддержка скачивания плейлистов.
-
Подписка на определенные каналы, чтобы бот сам присылал видео, как только они публикуются в канале.
Ссылки
Бот: https://t.me/SaveFromVkBot
Канал с обновлениями: https://t.me/SaveFromVkChannel
Бот обратной связи: https://t.me/SaveFromVkFeedbackBot
P.S.
Статья и так получилась довольно большой, поэтому за бортом осталось довольно много тем:
-
более подробно рассказать про бота, с примерами кода
-
написание unit- и integration- тестов с помощью kotest и mockk
-
использование testcontainers для локального и CI тестирования
-
контейнеризация spring-boot приложения с помощью buildpacks
-
настройка gitlab ci/cd для сборки image и деплоя
-
настройка terrafrom для быстрого разворачивания необходимых helm-chart-ов
-
настройка opentelemetry для логов, метрик и трейсов
-
создание dashboard-ов с помощью grafana-labs
Если статья в целом или эти тему окажутся интересны хабра-сообществу, расскажу про них в следующей статье.
P.P.S.
Буду благодарен, если кто-то поможет разобраться с проблемой большого лага между завершением работы kubernetes pod и соответствующей kubernetes job. Подробное описание проблемы — https://stackoverflow.com/questions/76024532/why-there-is-such-a-big-lag-between-kubernetes-pod-finished-and-job-completed-st/76105487#76105487
ссылка на оригинал статьи https://habr.com/ru/articles/735902/
Добавить комментарий