Chaos Engineering — это умышленное разрушение системы, которое позволяет выявить слабые места и уязвимости. Эта методика поможет сделать приложение надежнее и избежать возможных репутационных и финансовых проблем. В этой статье RnD-архитектор, техлид Максим Козлов расскажет, как применять Chaos Engineering.

Теория Chaos Engineering
Любое приложение, независимо от архитектуры, должно быть доступно, стабильно и устойчиво к атакам и сбоям. Пользователь должен как можно дольше оставаться доволен его работой. Чтобы улучшать живучесть системы, инженеры инфраструктуры придумали такую практику как Chaos Engineering.
Chaos Engineering — это искусство умышленного разрушения.
Считается, что первыми ее стали применять в компании Netflix. Так появились инструменты под брендом Chaos Monkey. Это порядка 10 приложений, которые моделировали отказы и тестировали систему на надежность.
Сейчас набирает популярность destroy as a service, например от компании Gremlin. Они предоставляют контейнер, который можно поставить себе в окружение и управлять экспериментами.
В целом, не важно, как называются инструменты, важно чтобы практика Chaos Engineering была постоянной. Не нужно останавливаться и сужать круг экспериментов. Наоборот, нужно больше пробовать, чтобы научиться прогнозировать поведение системы при сбоях.
Культура Chaos Engineering
Важно помнить, что нужно провести не просто эксперимент, а эксперимент, который будет полезен. Который покажет, что происходит при реальных сбоях. Из этого тезиса родилось несколько принципов Chaos Engineering:
-
Нужно строить гипотезы вокруг устойчивого состояния. Например, мы будем смотреть на Patroni. Таймаут переключения с одного узла на другой — 10 секунд. Это условие мы прописали в конфигах. И вокруг этого условия и будем проводить эксперимент.
-
Основываться на реальных событиях. Нужно посмотреть логи инцидентов и собрать все возможные варианты проблем. Исходя из них и планировать эксперименты.
-
Выполнять эксперименты именно в рабочем окружении. Иногда задают такой вопрос: зачем нужен Chaos Engineering, если есть нагрузочное тестирование? Затем, что нагрузочное тестирование чаще всего выполняют в одной системе с кучей заглушек. Для Chaos Engineering это не приемлемо. Желательно повторить именно ту транзакцию или систему, которую вы хотите проверить. Тогда точно будете понимать, к чему готовиться.
-
Автоматизировать эксперименты. Когда появляются новые релизы или переход на новые техники поставки, девопс-инженерам желательно проверять системы при каждом релизе.
-
Минимизировать последствия, когда проводите эксперимент. Нужно постараться сделать так, чтобы потом не пришлось несколько дней восстанавливать систему.
Что вы получаете от Chaos Engineering
-
Fun. Особенно весело ломать не свою систему.
-
Понимание работы системы целиком. Узнаете больше об архитектуре всей системы, а не только того сервиса, который вы написали.
-
Улучшение телеметрии. Вы эмулируете ошибки и инциденты, чтобы их детектить. Если они не детектятся, значит надо что-то улучшать в мониторинге.
-
Разработка плана компенсационных действий. Возможно не целесообразно сразу устранять все ошибки, но можно написать инструкцию, которая поможет следующим инженерам. Чем больше будет такой документации, тем понятнее будет работа системы.
Что будет если вы начнете применять Chaos Engineering?
Нужно быть готовым к тому, что команда и владельцы продукта могут сначала воспринимать такие эксперименты болезненно. Проявите терпение и настойчивость — через какое-то время к ним придет понимание.
Лучше всего отдать ломать ваше приложение кому-то другому. У него будет больше азарта, а вы получите взгляд со стороны.
Какие бывают типы экспериментов
-
Application level. Эксперименты на уровне приложений. Например, даете запрещенные или невалидные данные, можете сделать fuzzing api и посмотреть, как отреагирует система.
-
Host failure. Это ресурсные эксперименты на заполнение или максимальное использование памяти и диска. Также это может быть тест железа: пропало питание у серверов, умерла планка памяти.
-
Network attacks. Рекомендую начать именно с этих экспериментов, потому что этот вид атак простой и легко воспроизводимый. Это может быть повышение latency в бизнес процессе, потеря пакетов или отказ DNS-сервера и др.
-
Region attacks. Регион — это дата-центр. Вы можете проделать какие-то эксперименты связанные со split-brain, недоступностью региона и протестировать геораспределенность своего приложения.
Какие бывают инструменты Chaos Engineering
Я выделяю два вида инструментов: специальные, у которых есть приставка Chaos, и обычные, которые есть в любом дистрибутиве Linux.
Специальные хороши тем, что они как раз сделаны под ваши нужны. Они позволяют делать много операций. Это могут быть следующие утилиты:
-
ChaosToolkit
-
Chaosblade
-
Chaos Monkey
-
ChaosKube
-
Kube-monkey
-
Toxiproxy
-
Hastic.io
-
Jepsen
Стандартные инструменты:
-
stress-ng
-
tc
-
iperf
-
shutdown, reboot, kill
-
wrk
-
yandex-tank
-
locust
С tc (traffic control) вы можете делать очень многое: вырубать какие-то соединения, входящий или исходящий трафик, терять пакеты, гасить сетевые соединения. С утилитой stress-ng проводить эксперименты над CPU, RAM, IO.
Скорее всего, вы видели или слышали о stress-ng. Её часто используют для тестирования каких-то систем, которые глушат вентиляторы или наоборот поднимают обороты, когда компьютеры находятся под максимальной нагрузкой.
С утилитой chaosblade можно делать следующие эксперименты:
-
CPU
-
RAM
-
IO
-
packet loss
-
drop packet
-
delay send
Chaosblade — это такой комбайн, который оркеструет сразу много всего. Хотя под капотом у него происходит вызов стандартных инструментов.
Как я уже говорил, благодаря Chaos Engineering вы можете улучшать ваш мониторинг. Нельзя просто взять и пойти что-то сломать. Вы должны сначала развернуть мониторинг, потом провести эксперимент и собирать данные с этих стендов.
Был случай, когда мы проводили эксперименты над развесистой системой и человек из поддержки смотрел в Графану. Но когда лег один из кластеров он ничего не заметил.
Эксперимент с помощью инструментов ChaosBlade и Pumba
Patroni — это Python-приложение для создания высокодоступных PostgreSQL кластеров на основе потоковой репликации. Он позволяет синхронизировать кластеры и переключать активную базу данных.

Мы посмотрим, как происходит это переключение. Что будет если мы убьем одну ноду, где запущен PostgreSQL? Как будет вести себя продукт? Проверим, действительно ли хороша база данных?
Клонируйте репозиторий по ссылке ? https://github.com/dream-x/slerm_webinar
Там в readme есть нужные ссылки и команды. После этого запустите кластер Patroni: docker compose up
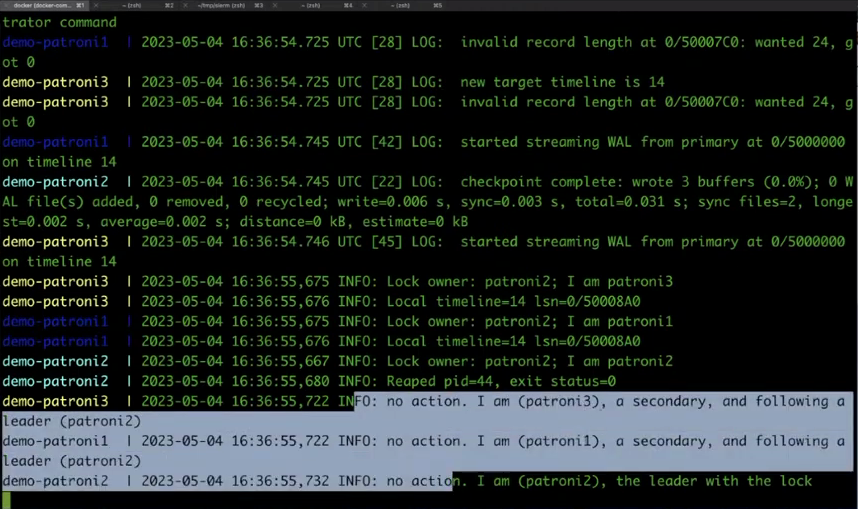
Видим, что есть три ноды: Patroni1, Patroni2, Patroni3. Patroni2 — лидер. Давайте предположим, что у нас могут произойти ошибки в сети. Для этого возьмем утилиту Pumba и проведем эксперимент: в течение 50 секунд будем терять 15% пакетов.
pumba netem --tc-image gaiadocker/iproute2 -d 50s loss -p 15 -c 10 demo-patroni3
Ничего не происходит, лидер не меняется. Тогда пробуем увеличить количество потерянных пакетов.
pumba netem --tc-image gaiadocker/iproute2 -d 30s loss -p 100 -c 100 demo-patroni3
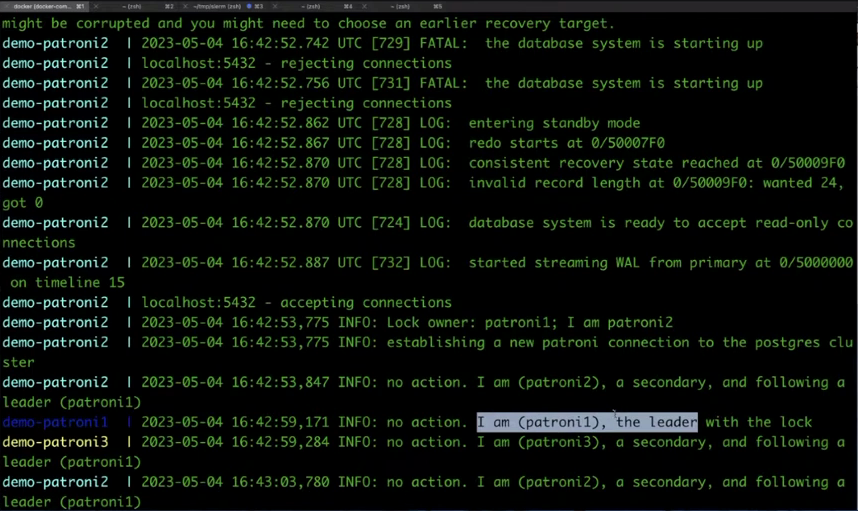
Появляются сигналы об ошибках и произошла смена лидера. Им стал patroni1. Попробуем убить лидера с помощью команды kill.
pumba kill demo-patroni1
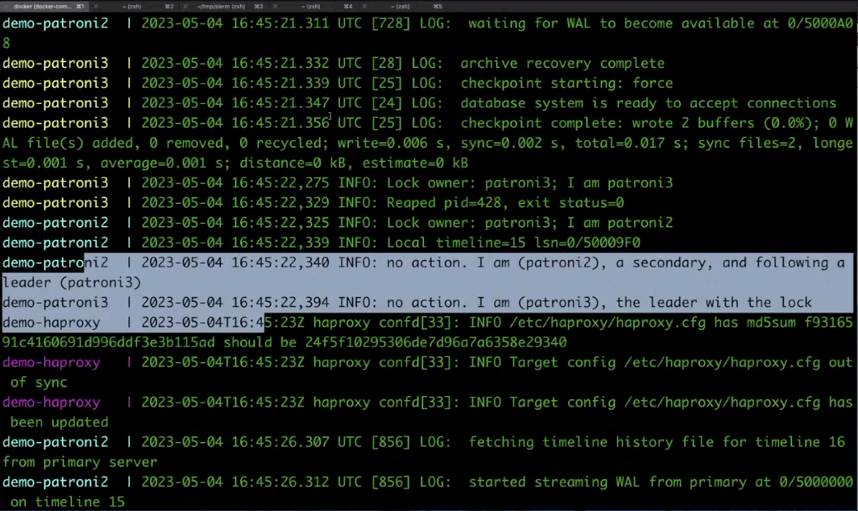
Видим ошибки, что нет соединения с patroni1 и две ноды распределили между собой нагрузки, а patroni3 стал лидером.
Утилита pumba очень удобна, когда интересно посмотреть, как работают с неисправностями контейнерные приложения. Всего десять минут — и вы уверены, что переключение работает.
Попробуем с помощью Chaosblade сделать эксперимент на ресурсы, например CPU.
blade create cpu fullload --cpu-count 4 --timeout 20
Получаем ответ:
{"code":200, "success":true, "result":"fa3a5d5779ecb6dd"}
Chaosblade интересен тем, что результаты команд легко парсить — они возвращаются в виде json.
blade status [hash]
Эта команда выводит данные об эксперименте.

В Chaosblade также есть эксперименты с сетью. Кроме того, неважно монолитное у вас приложение или микросервисное, можно провести эксперименты и понять
А что будет, если…
Это вообще очень важный вопрос, особенно, когда к нам приходят с каким-то архитектурным решением. Задавайте его почаще и проводите контролируемые испытания и улучшайте надежность системы.
Узнать больше о Chaos Engineering можно в Слёрме. Сейчас там идет набор группы на трехдневный курс. Вы научитесь формировать гипотезы и самостоятельно проводить эксперименты с помощью ChaosBlade и ChaosMesh.

Записаться на курс можно на нашем сайте.
?«Настольные книги» для тех, кто хочет изучить Chaos Engineering:
1. Подборка на Github — https://github.com/dastergon/awesome-chaos-engineering
2. Книга на manning — https://www.manning.com/books/chaos-engineering
3. Книга на Amazon — https://www.amazon.com/Chaos-Engineering-System-Resiliency-Practice/dp/1492043869
ссылка на оригинал статьи https://habr.com/ru/companies/southbridge/articles/737296/
Добавить комментарий