Про цифровой след обычно говорят лишь в общих чертах, и описание программирования для работы с ним лишь упоминают. В данной статье рассмотрен набор библиотек Python и приемов, которые можно использовать для сбора и предобработки данных цифрового следа.
Понятие «Цифровой след»
Юридически понятие «цифровой след» не зафиксировано, в литературе он описывается как данные про конкретного человека, так и данные про организацию или событие. Однако чаще имеются в виду именно информация о людях.
В 2022 году в России был принят профессиональный стандарт специалиста по моделированию, сбору и анализу данных цифрового следа — Профстандарт 06.046 | Специалист по моделированию, цифрового следа | Профессиональные стандарты 2023. В этом документе также говорится про данные о человеке:
|
Общие сведения: Проведение комплексного анализа цифрового следа человека (групп людей) и информационно-коммуникационных систем (далее — ИКС). |
Таким образом, цифровой след представляет собой данные в интернете, относящиеся к конкретному объекту, которым чаще всего выступает человек. Важно иметь в виду законы о защите персональных данных и интеллектуальной собственности при работе с цифровым следом. В этой статье рассмотрен сбор данных из интернета со стороны закона.
Этапы сбора и предобработки цифрового следа
Логичным способом собирать цифровой след программными инструментами является программирование подобной человеку логики работы с общедоступными данными. Люди ищут и собирают информацию про что-то конкретное через поиск, а далее, изучая страницы в интернете, выбирают информацию, где говорится про то, что их интересует.
Предобработка зависит от конкретной цели дальнейшей работы и типа собранных данных. Предобработка текста может включать в себя очистку от ненужных символов и токенизацию — разделение текста на слова/знаки/символы. Предобработка чисел — обработку пропусков и нормализацию. Предобработка изображения — простое форматирование.
Таким образом, основными этапами сбора и предобработки данных цифрового следа являются:
-
Отправка HTTP-запроса веб-серверу поисковика с упоминанием интересующего объекта;

URL-адрес при выполнении поиска -
Получение ссылки на страницу в интернете про интересующий объект из ответа веб-сервера, отправка HTTP-запроса для получения кода этой страницы;

-
Выбор из полученного кода страницы интересующей информации: либо вручную настроенный сбор данных из определенных сегментов страницы, либо проверка на упоминание объекта в тексте, и сбор таких предложений;

-
Предобработка данных цифрового следа:
-
Текст: очистка, токенизация;
-
Числа: обработка пропусков, нормализация;
-
Изображения: простое форматирование.
Библиотеки Python для сбора и предобработки цифрового следа
Сбор данных в интернете посредством программ называется парсингом, существуют различные библиотеки Python для этого. Очень простыми для начинающих являются «Requests» и «Beautiful Soup». Вот статья на эту тему. При работе с цифровым следом выполняются схожие действия, просто дополнительно нужно искать и выбирать информацию про один интересующий объект.
-
Отправку HTTP-запроса веб-серверу поисковика с упоминанием интересующего объекта можно выполнить с помощью библиотеки «Requests«. Нужно указать объект в запросе, в примере он указан в URL-адресе.
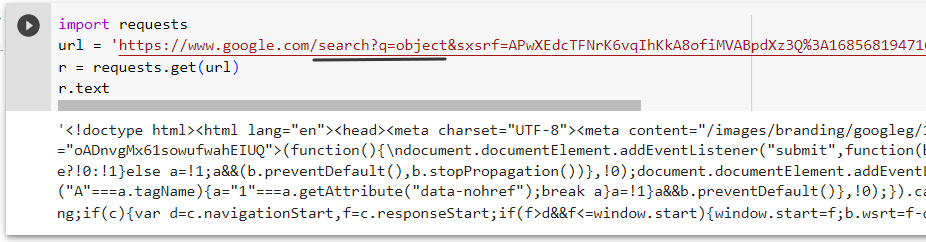
-
Получение ссылки на страницу в интернете про интересующий объект из ответа веб-сервера можно выполнить с помощью «Beautiful Soup» — сохранить атрибут «href» тега «a», который отправляет на новую страницу. Далее отправку HTTP-запроса для получения кода этой страницы можно сделать с помощью «Requests«.

-
Выбор из полученного кода страницы интересующей информации можно сделать либо вручную с помощью поиска сегмента «Beautiful Soup«, либо можно проверить упоминание объекта в тексте через проверку в цикле и использование встроенной библиотеки «String«.
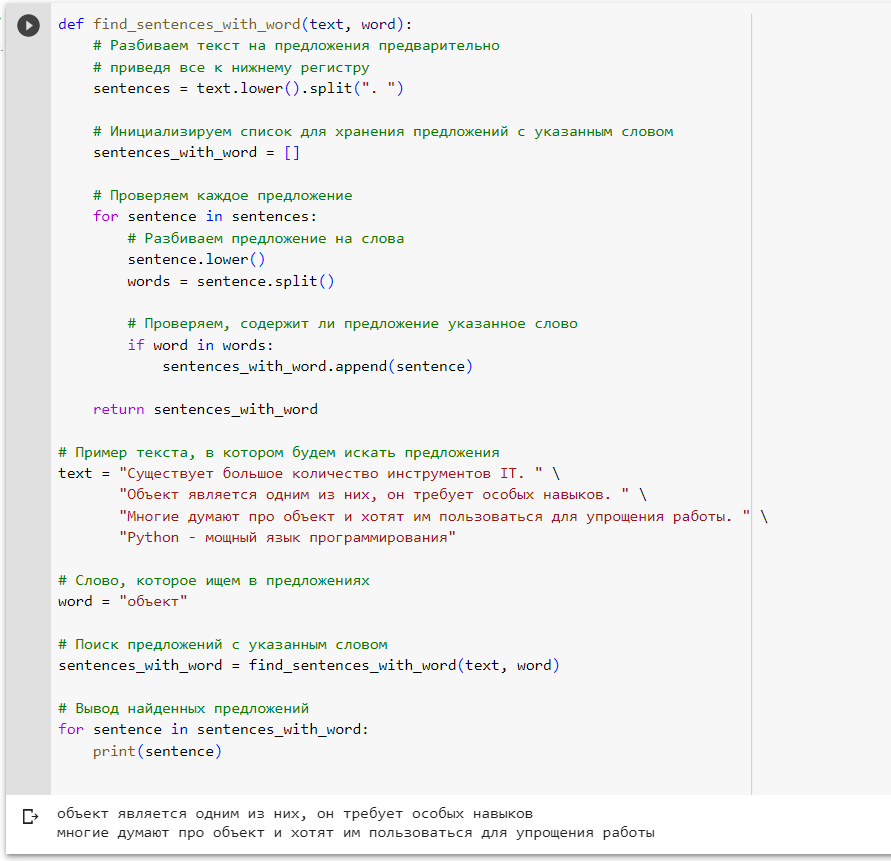
-
Предобработка данных цифрового следа:
-
Текст: для простой очистки можно использовать встроенную библиотеку «String«, для токенизации (разбиения текста на единицы) удобно использовать «NLTK«.
-
Числа: для обработки пропусков можно использовать «NumPy» — удалять пропущенные значения или заменять их на среднее или медианное, для нормализации можно использовать «Scikit-learn«, «Pandas».
-
Изображения: можно выполнять простое форматирование с помощью библиотеки «Pillow«.
ссылка на оригинал статьи https://habr.com/ru/articles/739572/
Добавить комментарий