В связи с ситуацией и отключением плагинов табеля рабочего времени в Jira я начал изучать тему получения нужной информации по трудозатратам через Jira API. Даже нашел несколько статей на эту тему на уважаемом ресурсе. Но, как оказалось, некоторые моменты устарели, а некоторые были упущены авторами, либо они на них просто не наткнулись.
Итак, для работы с Jira через python есть уже готовая библиотека с документацией.
Задумка возникла следующая: писать в базу PG данные по трудозатратам и визуализировать их с помощью Yandex DataLens. Дополнительно для экономистов и PM готовить выгрузку в EXCEL. Соответственно, изначально получилось вот так:
from pickle import TRUE from jira import JIRA import re import time import traceback from datetime import datetime , timedelta import psycopg2 import pandas as pdДалее приведу примеры того, что поменялось с момента написания аналогичных статей.
Подключение к Jira
Подключится удалось только через логин и … внимание — токен. Аутентификация через логин-пароль или только через токен была неуспешной.
Соответственно в Jira под админом создаете токен. Его имя неважно, оно нигде не используется. Далее используете его и логин (я использовал свой админский).
login = 'your_jira_login@gmail.com' token_val = 'you_jira_token_generated_for_app' jira_options = {'server': 'https://you_project.atlassian.net'} jira = JIRA(options=jira_options, basic_auth= (login,token_val))Далее есть куча примеров, и описано в документации, как получать список issue. Тут также важный момент, что по умолчанию Jira отдает не более 100 issues за запрос, и важно отключить это ограничение, иначе данные будут неполные. Выясняется это, когда начинаешь тестировать и сравнивать выгруженный результат со старыми выгрузками из плагина Timesheet (нужно добавить maxResults=0 в метод search_issues).
jsql_str = f"worklogDate >= {work_date_start_str} AND worklogDate <= {work_date_end_str} ORDER BY created DESC" issues_list = jira.search_issues(jql_str = jsql_str,maxResults=0)Следующие грабли связаны с получением журнала логов. Аналогично, есть лимит на получение записей work_log. Тут ограничение установлено в 20 записей. Просто установкой параметра здесь не обойтись, и нужно использовать вместо issue.fields.worklog.worklogs — jira.worklogs(issue = issue.key). Он не имеет ограничений на количество записей. Другого способа обойти ограничение я не нашел.
work_log_df = [] for work_logs in jira.worklogs(issue = issue.key): # надо делать именно так. чтобы обойти ограничение в 20 записей на issue print (work_logs.started) print (work_logs.created) print (work_logs.self) worklog_date_str = re.search(r'(\d{4}-\d{2}-\d{2})', work_logs.started) worklog_date = datetime.strptime(worklog_date_str.group(0), '%Y-%m-%d') if work_logs.timeSpent is not None and worklog_date >= work_date_from and worklog_date <= work_date_to: work_line = {} #print(issue.key) isuekey = issue.key work_line['key'] = isuekey #print(issue.fields.project.key) projkey = issue.fields.project.key proj_name = issue.fields.project.name work_line['project'] = projkey work_line['project_name'] = proj_nameДалее собираем данные для Excel и вставки в БД. Данные в БД удаляются перед вставкой за выбранный период, после чего определяется курсор для вставки. В этой версии вставляем по одной строке:
try: conn = psycopg2.connect('postgresql://jiraapi:user@host:port/jiradb') print("Connect to database successfully") cur = conn.cursor() sql = """delete from public.jira_tasks where work_date >= %s and work_date <= %s;""" cur.execute(sql,(work_date_start_str,work_date_end_str)) conn.commit() cur.close() print("Data in period deleted") cur = conn.cursor() sql = """INSERT INTO public.jira_tasks(project,project_name,task,work_time,work_time_sec,wuser,work_date) VALUES(%s,%s,%s,%s,%s,%s,%s);""" except: print("Can't connect to database")Для удобства анализа данных в EXCEL сразу выводим месяц и дату в файл:
work_line['worklog_date'] = worklog_date work_line['work_hours'] = round(swork_time_sec / 3600,2) work_line['month'] = worklog_date.strftime("%m") work_line['day'] = worklog_date.strftime("%d") work_line['year'] = worklog_date.strftime("%Y")Непосредственно запись в БД и вывод файла в EXCEL с обработкой возможных ошибок.
cur.execute(sql, (projkey,proj_name,isuekey,swork_time,swork_time_sec,sauthor,worklog_date)) work_log_df.append(work_line) n = n + 1 conn.commit() cur.close() if n >= 1: file_name = 'WorkLog_' + str(n) + '_' + work_date_start_str + '_' + work_date_end_str + '.xlsx' pd.DataFrame(work_log_df).to_excel(file_name, index=False) print ('Выгружено ' + str(n) + ' записей') else: Print('Нет данных для выгрузки') except: cur.close() print('Ошибка при записи данных', traceback.format_exc())Работа с DataLens
Решил попробовать, что такое DataLens от Yandex.
Первое, что надо сделать — создать «подключение к БД». Выбираем Postgress из возможных вариантов.

После создания подключения создаем датасет. Тут все просто. Выбираем наше подключение, ниже выводятся доступные таблицы и view. Вытаскиваем нужный в область справа.
После создания датасета можно делать диаграммы, а затем из готовых создавать дашборд. Набор диаграмм стандартный, жаль, что нет ничего типа календаря. Пришлось использовать сводную таблицу. И не успел разобраться с drill_down, и есть ли он вообще в DataLens, пока непонятно.
После того как вытащили диаграммы на дашборд, можно создать единые фильтры для всего дашборда.
В итоге получилось вот так:
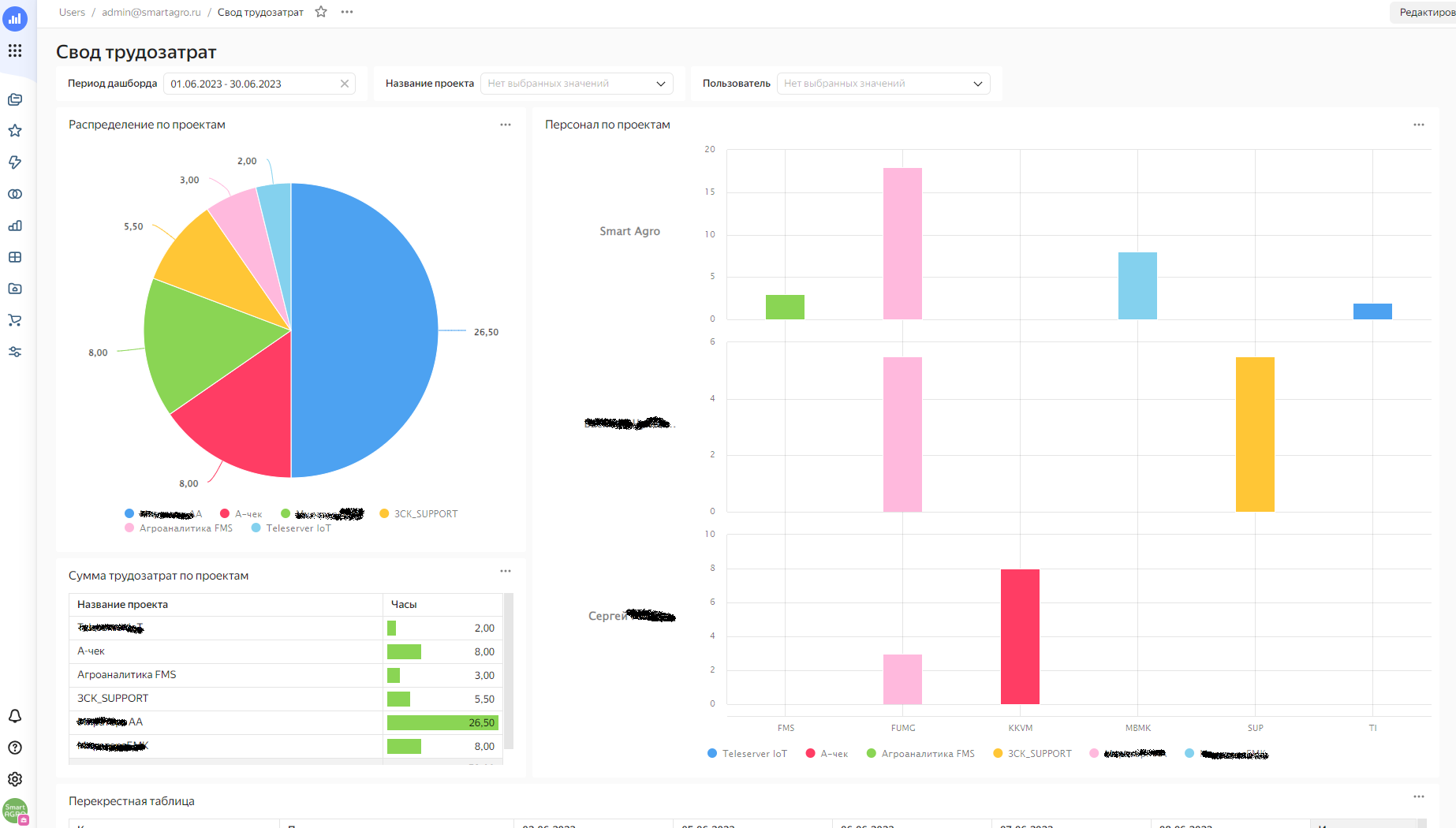
Вторая часть дашборда:
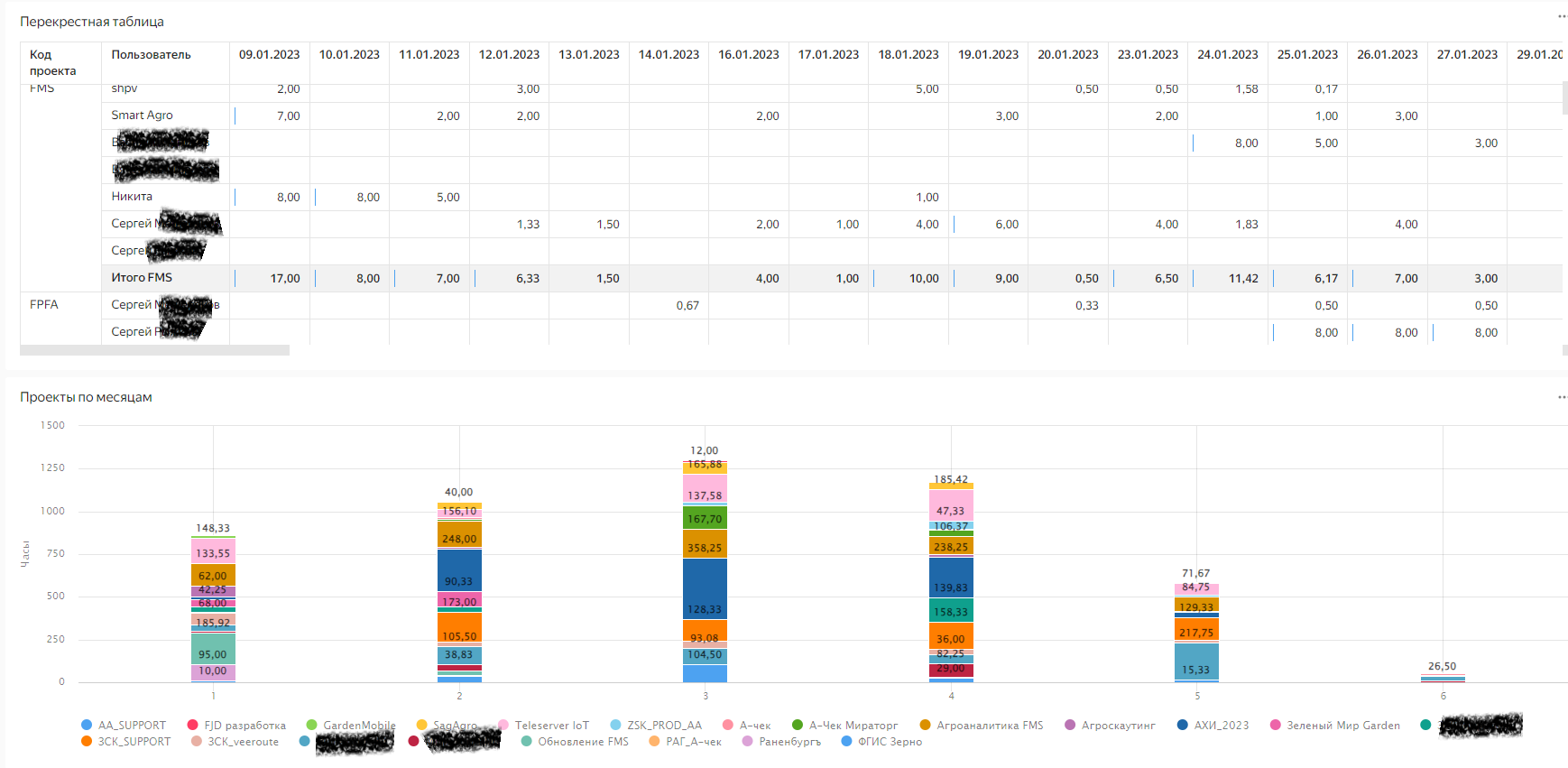
К сожалению, периодически возникает ошибка при обращении к датасету и иногда какие-то «глюки», но в целом BI работает. DataLense + Excel дали функционал по аналитике даже немного больший, чем плагины, НО, конечно, анализировать трудозатраты и сразу закрывать пропуски непосредственно в Jira разработчикам было удобнее )

ссылка на оригинал статьи https://habr.com/ru/articles/749362/
Добавить комментарий