Привет, Хабр!
В данной статье мы рассмотрим актуальные методы проверки работоспособности сетевого оборудования. Конкретно в этой статье мы поговорим про протоколы мониторинга. Статья является переваренным опытом компании Netopia, которая занимается разработкой программного обеспечения для сетей. Цель статьи – найти единомышленников, которым интересны сетевые технологии, для обсуждения актуальных проблем. Планируется цикл статей, и мы постараемся не сильно растягивать удовольствие.
Введение. Описание общего подхода в работе с сетевым оборудованием
Рассмотрим общий подход к процессу работы с сетевым оборудованием:
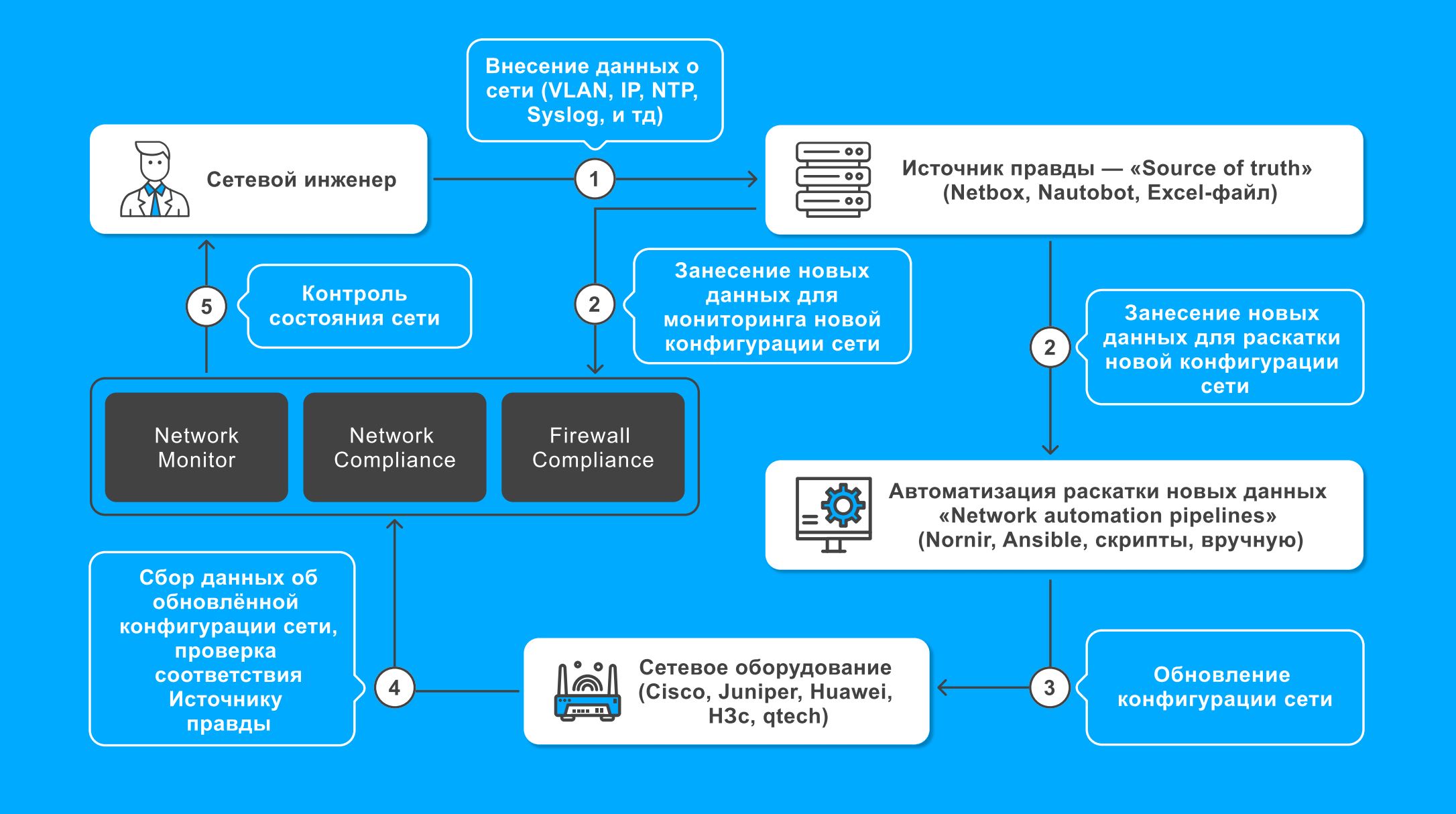
Мы видим стандартный цикл PDCA с учетом сетевой специфики. Первым элементом системы является источник правды (source of truth), это в каком-то формате ipam- система, мы тут храним полный перечень сетевого оборудования (не обязательно только сетевого, но в нашем контексте важно именно сетевое), подсети, актуальные используемые ip адреса, vlan и тд., все что нам необходимо для описания текущего состояния сетевой инфраструктуры. Важное условие – данные в нашей системе должны быть актуальными и консистентными, то есть мы должны опираться на эти данные и не сомневаться в них (поэтому мы называем его источником правды).
На основании вносимых изменений в эти данные мы производим изменения в сети вручную или с помощью различных инструментов автоматизации, Ansible, Nornir, Netbrain, кому что больше нравится и подходит для решения конкретной задачи.
Хорошо, мы раскатили изменения в сети. Что происходит дальше? Дальше мы как-то должны понять, что все раскатилось хорошо и сеть работает. Сеть работает так, как мы и запланировали, в соответствии с источником правды.
Постановка проблемы
Обратимся к опыту крупных компаний по настройке сетевого оборудования, чтобы понять в среднем температуру по больнице.
Для компании Cisco готовят различные исследования по сетевым технологиям. В рамках исследования авторы статьи пообщались с сетевыми инженерами из крупных компаний, в частности с одной из компаний Fortune 50 (Это Wallmart, Amazon, Apple, Alphabet, Microsoft и тд). (Если кто-то захочет прочитать оригинал)
Свободный перевод из документа выше: «После того как мы запушили изменения в сеть, мы ждем, когда наша система мониторинга получит snmp-trap, который говорит нам о том, что сеть легла. Если через 15 минут после того как мы внесли изменения ничего не произошло, мы считаем, что изменения прошли успешно.»
Как мы видим — жизнь такова какова она есть и больше никакова. (цитаты великих)
Собственно, задача, которую мы перед собой поставим, это понимание актуального состояния сети на основании различных проверок и срезов данных, которые нам показывают отклонения от источника правды.
Существует определенная сложность в контроле того, что происходит с сетью, и насколько она соответствуем тем настройкам, которые сетевые инженеры хотели заложить в работу оборудования. Такому положению дел есть много причин:
-
Размеры сети (сотни-тысячи единиц сетевого оборудования)
-
Большая нагрузка на эту сеть (дополнительная нагрузка не приветствуется)
-
Растянутая во времени настройка (сегодня один инженер настраивал по-своему, через год другой инженер по-своему)
-
Где-то надо было быстро накостылить, оставили как есть (работает же)
-
Как ни странно, сложность сети, количество взаимодействий и протоколов очень большое (можно выгрузить таблицу маршрутизации из bgp и уже приуныть)
Мы бы хотели выделить три проблемы, которые на наш взгляд охватывают большую часть решаемых задач:
-
актуальный срез состояния сети
-
консистентная конфигурация сетевого оборудования
-
проходимость данных по сети
В данной статье мы рассмотрим первую задачу – актуальный срез состояния сети, здесь мы подразумеваем мониторинг.
Актуальный срез состояния сети
Ситуация:
-
Происходит много событий, которые могут влиять на работу сети и привести к сбою/снижению производительности
-
Нужна актуальная «кардиограмма» сети, чтобы понимать, что происходит
-
Среднее время сбора данных через SNMP 5-10 минут в нагруженных сетях (ссылка).
Тут мы никакой Америки не открыли. Это то, с чем приходится сталкиваться сетевому инженеру в рамках своей работы. Самым распространенным протоколом по сбору телеметрии является протокол SNMP. Можно ли собрать по SNMP актуальную информацию в режиме онлайн? Для больших сетей похоже, что нет.
Рассмотрим альтернативные способы получения данных.
Потоковая телеметрия
Потоковая телеметрия какое-то время назад уже пришла в нашу жизнь, но наверняка не все в курсе, о чем речь, поэтому дадим небольшое пояснение по этому вопросу.
Потоковая телеметрия – это зонтичный термин, под которым собраны различные технологии по сбору телеметрии. Ключевые особенности этого подхода:
-
Скорость обработки информации. Сетевое оборудование само отправляет данные (метод push, а не pull как в snmp, где надо постоянно делать запросы на получение данных), это приводит нас к тому, что уменьшается нагрузка на оборудование, и увеличивается частота сбора данных

Исследования показывают, что среднее время обработки запроса через snmp и через потоковую телеметрию значительно отличается.
-
Простота и полнота получаемых данных

Все вы прекрасно представляете, как выглядят шаблоны Zabbix для любого сетевого оборудования. Обычно сложно найти подходящие шаблоны, если нет нужных параметров, то написание шаблона — это отдельная головная боль. Поиск самих параметров (oid) тоже дело нетривиальное. Дерево значений oid оставляет желать лучшего.
Сравним с тем, как это выглядит при сборе потоковой телеметрии по протоколу gRPC в формате JSON.

На картинке представлен сэмпл потока данных, полученного с сетевого оборудования Cisco с операционной системой IOS XE. Вот, например, мы хотим посмотреть данные по интерфейсам, открыли любой интерфейс (к примеру, GE1). Можем отфильтровать данные по vrf, по ipv4 или ipv6, хотим посмотреть статистику по конкретному интерфейсу– пожалуйста. Здесь есть понятная иерархическая структура, перечень получаемых данных понятен и прозрачен, сразу есть значения.

Дальше просто отфильтровываем нужные параметры, они у нас справа. Выбранные данные сохраняются в базу данных. Все, готово, данные уже собираются, осталось построить график. То есть нет никаких шаблонов, не надо погружаться в создание шаблонов, не надо искать OID, в этом плане гораздо удобнее. Вот графики, построенные на полученных данных.

SSH\Netconf
Данная конструкция не нова и в принципе применяется на практике, но здесь добавилось немного гибкости. Мы делаем запрос данных с помощью команд по ssh или netconf. При этом запросить эти данные через SNMP нет возможности. Результат вывода надо распарсить и сложить в базу данных для дальнейшего вывода. Понятная ситуация, когда из неструктурированных данных надо сделать структурированные. Существует модуль, разработанный Google, который называется TextFSM. Он решает данную задачу. Пример, команды и шаблон textFSM представлены ниже.

Получаем структурированные данные

По ним можно построить таблицу мак адресов

Данные из лаборатории, поэтому просим строго не судить по однотипности данных.
Syslog
Syslog-ом сложно удивить, но и тут есть небольшая интересность. Мы вам рассказывали про потоковую телеметрию. Теперь появилась возможность отправлять syslog через протоколы потоковой телеметрии в структурированном виде.
Для NX-OS это доступно по следующим путям:
-
Cisco-NX-OS-Syslog-oper:syslog
-
Cisco-NX-OS-Syslog-oper:syslog/messages·
Принципиальная разница по сравнению с обычным сислогом – данные прилетают в структурированном виде (json\gpb) и не надо делать парсинг.
Sample JSON Output

Единая консоль как вывод
Собирая данные по этим протоколам, мы сможем мониторить:
-
end-to-end connectivity физики
-
underlay- сети
-
overlay-сети
По физике строим мозаику-матрицу на основании grpc потоков по состоянию интерфейсов, в потоках выбрать нужное оборудование, нужные интерфейсы. Между любой парой устройств если линк свалится — сразу квадрат другого цвета станет. Другие метрики — рост ошибок на интерфейсах и срабатывание триггера по превышению скорости роста этих ошибок.
По underlay — смотрим информацию с потоков по состоянию ospf, bgp neighborship и уже на эти данные ориентируемся, показатель — живая сессия или упала.
С overlay (сервисы) примерно то же что с bgp и ospf — сильно зависит от сервиса — смотрим сигнализацию по l2, l3 vpn, например, состояния нужных сессий address-family в bgp, ну и какие-то специфичные метрики конкретного сервиса — на наличие нужных маршрутов в таблицах маршрутизации и т. п.
Получается единая консоль для сбора различных срезов состояния сети, которой так не хватало.
ссылка на оригинал статьи https://habr.com/ru/articles/761314/
Добавить комментарий