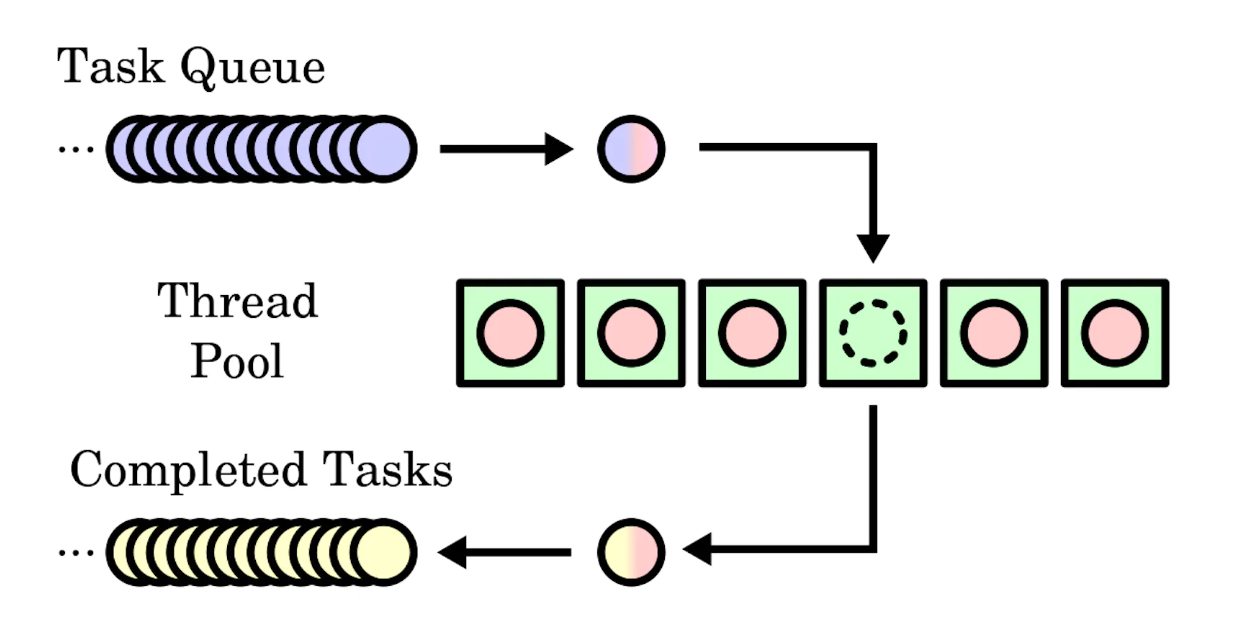
В программировании «пулом потоков» (thread pool) называется паттерн проектирования, обеспечивающий конкурентное выполнение компьютерной программы. Эта модель также может именоваться «worker crew» (рабочая бригада) или «replicated workers» (самовоспроизводящиеся задачи). Пул держит наготове множество потоков, ожидающих, пока владеющая им программа не выделит ему в конкурентное выполнение ряд задач
— по Википедии
Репозиторий: github.com/arindas/sangfroid
Этот пост написан в основном под впечатлением от лекции Роба Пайка «Конкурентность – это не параллелизм«.
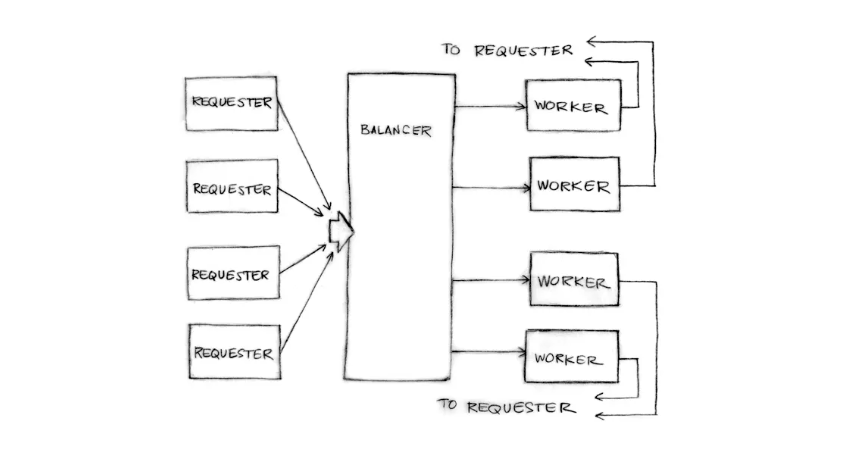
Зачастую, пускаясь в решение задачи, полезно чётко видеть перед собой цель, которую хочешь достичь. Какая же цель стоит перед нами в данном случае? В простейшем смысле нам нужна система, которая позволяла бы:
- Распланировать некоторую работу так, чтобы ею занималось множество исполнителей
- Иметь возможность получать результаты работы, сделанной этими исполнителями
- Обеспечить, что исполнители достаточно загружены, но при этом не страдают от выгорания
Обратите внимание: система такого рода не привязана напрямую к компьютерам. Подобная модель вполне применима и к некоторому человеческому коллективу, которому требуется решить определённые задачи.
Как же нам смоделировать и решить эту проблему?
Допустим, у нас есть клиенты, для которых нужно выполнить некоторую работу. Ещё есть менеджер, координирующий несколько сотрудников, и сами сотрудники организации. Вот, например, как можно обустроить поток задач:
- Клиент электронным письмом сообщает менеджеру, что должно быть сделано.
- Менеджер выбирает сотрудника, у которого меньше всего незавершённых задач, и добавляет новое сообщение в уже адресованную этому сотруднику цепочку писем. Таким образом сотрудник уведомляется, что эта задача поручена ему.
- Сотрудник выбирает задачи из всех писем, которые получил от начальника. Справившись с очередной работой, он прикрепляет её результат в ту же цепочку и отвечает клиенту.
- Менеджер помечает для себя, что теперь этому сотруднику предстоит выполнить на одну задачу меньше.
Обратите внимание: как только менеджер поручает сотруднику конкретную задачу, возникает прямая связь между этим сотрудником и клиентом. Менеджеру не требуется отвечать за передачу работы от сотрудника клиенту. Такой рабочий аспект высоко оценил бы любой менеджер.
Как всё это вписывается в программную систему? – спросите вы.
На место клиентов-людей ставим клиенты-машины, отправляющие веб-запросы на сервер. Исполнители в данном случае – это легковесные процессы или потоки. Веб-сервер назначает поступившие веб-запросы тем или иным потокам, которые передают отклик напрямую клиенту. Именно такова архитектура веб-сервера.
Но невозможно далее создавать по новому потоку на каждый поступающий запрос (ведь на каждый поток требуется выделять память), а также требуется некоторое время на переключение контекста от одного потока к другому. Но в рамках данной модели можно масштабироваться в рамках фиксированного количества потоков.
Всё же, часть задачи мы ещё не решили. Как всякий раз наиболее эффективно выбирать того исполнителя, который загружен меньше всех?
Каждый исполнитель ведёт список актуальных задач, которые ещё требуется решить. В таком случае мы поддерживаем двоичную кучу потоков, ориентируясь на то, сколько у каждого из них «висящих» задач. Мы обновляем эту кучу всякий раз, когда исполнитель получает новую задачу или завершает имеющуюся.
Что ж, довольно слов. Переходим к коду!
❯ Очередь с динамической расстановкой приоритетов
Немного тяжеловесная формулировка, не правда ли?
Мы просто имеем в виду, что нам нужна такая очередь приоритетов, порядок обрабатываемых элементов в которой может меняться во время выполнения. Точно так исполнители отдают приоритет той или иной задаче в зависимости от того, сколько ещё висящих задач у них имеется в каждый конкретный момент.
Код к этому разделу находится по адресу: github.com/arindas/bheap
Начнём!
Смоделируем нашу кучу следующим образом:
/// Типаж для уникальной идентификации элементов в двоичной куче. pub trait Uid { /// Уникальный идентификатор структуры, отвечающей за реализацию. То же /// самое значение должно возвращаться при всех вызовах данного метода в заданной структуре. fn uid(&self) -> u64; } /// Двоичная куча с максимальным элементом в корне, с перестановкой приоритетов, содержит буфер для хранения элементов /// и hashmap-индекс для отслеживания позиций элементов. pub struct BinaryMaxHeap<T> where T: Ord + Uid, { /// хранилище элементов, расположенное в оперативной памяти buffer: Vec<T>, /// отображение с уникальных идентификаторов элементов на позиции в буфере кучи index: HashMap<u64, usize>, }Эта двоичная куча одинаково устроена при работе с любыми типами, поддающимися упорядочиванию и уникальной идентификации. Типажи в основном похожи на интерфейсы, используемые в других языках. Подробнее о типажах рассказано здесь.
В качестве базового хранилища данных для двоичной кучи воспользуемся вектором. Поскольку мы можем динамически упорядочивать наши элементы, нам понадобится механизм, который позволял бы отслеживать уникальность каждого из них и вести их списки.
Вот как выглядит функция swap( ):
impl<T> BinaryMaxHeap<T> where T: Ord + Uid, { // ... /// Меняет местами элементы с заданными индексами, сначала проделывая это с элементами /// в буферном векторе, а затем обновляя `HashMap`, записывая в него /// новые индексы. #[inline] fn swap_elems_at_indices(&mut self, i: usize, j: usize) { let index = &mut self.index; index.insert(self.buffer[i].uid(), j); index.insert(self.buffer[j].uid(), i); self.buffer.swap(i, j); } // ... } Здесь было необходимо позаимствовать self.index как отдельный mut, поскольку в противном случае пришлось бы неоднократно в одной и той же области видимости заимствовать self как mut.
Вот heapify_up():
/// Восстанавливает свойство кучи, перемещая элемент в заданном индексе /// вверх относительно его предков по направлению к корню, до тех пор, пока предков не останется или /// он окажется <= своих предков. /// Возвращает Some(i), где i – новый индекс. Возвращает None, если никаких /// перестановок не потребовалось fn heapify_up(&mut self, idx: usize) -> Option<usize> { let mut i = idx; while i > 0 { let parent = (i - 1) / 2; if let Ordering::Greater = self.cmp(i, parent) { self.swap_elems_at_indices(i, parent); i = parent; } else { break; }; } if i != idx { return Some(i); } else { return None; } } В heapify_dn() также нет ничего особенного. Можете сами проверить в репозитории. Единственная вещь, которую здесь важно отметить – что всякий раз мы используем функцию swap_elems_at_indices().
Наконец, вот как выглядит наша «динамическая расстановка приоритетов»:
// ... /// Восстанавливает свойство кучи на заданной позиции. pub fn restore_heap_property(&mut self, idx: usize) -> Option<usize> { if idx >= self.len() { return None; } self.heapify_up(idx).or(self.heapify_dn(idx)) } /// Возвращает позицию элемента в буфере кучи. pub fn index_in_heap(&self, elem: &T) -> Option<usize> { self.index.get(&elem.uid()).map(|&elem_idx| elem_idx) } } // BinaryMaxHeapТеперь, когда мы избавились от контейнера для исполнителей, давайте реализуем сам пул потоков.
❯ Пул потоков с балансировкой нагрузки
Код к этому разделу находится по адресу: github.com/arindas/sangfroid
Вспомогательные сущности
Для начала нужно определить, какая задача перед нами стоит, или каково задание Job:
/// Представляет задание, которое должно быть передано в пул потоков. pub struct Job<Req, Res> where Req: Send, Res: Send, { /// Задача для выполнения task: Box<dyn FnMut(Req) -> Res + Send + 'static>, /// запрашиваем у сервиса, например, аргументы для задачи req: Req, /// Опциональный канал для результатов, по которому можно /// например, отправить результат выполнения result_sink: Option<Sender<Res>>, }Граница типажей необходима, например, для типов, которые могут передаваться между потоками. В данном случае нам нужно, чтобы результат поддавался отправке от потока-исполнителя к получателю, верно? Следовательно, он необходим.
Текперь давайте детально разберём все члены:
task– это замыкание, в котором может содержаться некоторое изменяемое состояние. Поскольку его возвращаемое значение должно «пережить» его же область видимости, его возвращаемый тип помечается как имеющий время жизни'static. Следовательно, этот результат просуществует в течение всего срока работы программы. Также он поддаётся отправке (Sendable). (как было объяснено выше).req: представляет собой параметр задачиesult_sink: приёмный конец канала, откуда регистр может получить результат.
Хм, последняя часть кажется немного сложноватой, правда?
Всякий раз, создавая Job, мы создаём и канал для коммуникации с исполнителем. Считайте этот канал звеном конвейера (pipe), в котором есть отправной и приёмный конец. Теперь у запрашивающего сохраняется приёмный конец, тогда как в структуре Job содержится отправной конец. Когда планировщик назначит Job, ThreadPool отдаст задание наименее загруженному потоку-исполнителю. Поток-исполнитель выполнит замыкание внутри Job и отправит обратно вычисленный результат, отправит именно в тот приёмный конец, который фигурирует в структуре Job. Именно так потоку-исполнителю удаётся напрямую сообщить результат той стороне, которая его запрашивает.
Обратите внимание: при вышеописанном подходе, чтобы сообщить результат, не требуется никакой синхронизации ни с использованием библиотек, ни на стороне пользователя. Здесь мы совместно используем результат (или участок памяти), сообщая о нём, а не строим коммуникацию через синхронизацию, реализуемую в некоторой структуре данных (равно, как ни прибегаем к разделению памяти). Именно эта мысль формулируется как:
Не коммуницируйте, разделяя память; вместо этого разделяйте память путём коммуникации.
В стандартной библиотеке Rust предоставляются каналы с std::sync::mpsc::{channel, Receiver, Sender}. Каналы создаются примерно так:
let (tx, rx) = channel::<SomeType>(); Например, вот как создаётся Job:
impl<Req, Res> Job<Req, Res> where Req: Send, Res: Send, { // ... pub fn with_result_sink<F>(f: F, req: Req) -> (Self, Receiver<Res>) where F: FnMut(Req) -> Res + Send + 'static, { let (tx, rx) = channel::<Res>(); ( Job { task: Box::new(f), req, result_sink: Some(tx), }, rx, ) } // ... }Теперь нам нужен блок для коммуникации с потоками-исполнителями. Например, вот так:
/// Message – это сообщение, которое нужно отправить исполнителям /// в пул потоков. pub enum Message<Req, Res> where Req: Send, Res: Send, { /// Запрос на выполнение задания Request(Job<Req, Res>), /// Сообщение потоку с требованием завершиться Terminate, }
Потоки-исполнители
Потоки-исполнители представляем следующим образом:
/// Worker – это поток-исполнитель, способный получать задания и справляться с ними. pub struct Worker<Req, Res> where Req: Send + Debug + 'static, Res: Send + Debug + 'static, { /// uid для уникальной идентификации этого исполнителя uid: u64, /// очередь диспетчеризации сообщений disp_q: Sender<Message<Req, Res>>, /// поток-исполнитель для выполнения заданий worker: Option<JoinHandle<Result<(), WorkerError>>>, /// Количество заданий, дожидающихся, пока их выполнят pending: usize, }У нас есть простые сеттеры для инкремента и декремента нагрузки исполнителя:
/// Увеличивает количество ожидающих заданий на 1. #[inline] pub fn inc_load(&mut self) { self.pending += 1; } /// Уменьшает количество ожидающих заданий на 1. #[inline] pub fn dec_load(&mut self) { self.pending -= 1; }Теперь в момент создания исполнителей также создаётся канал, по которому пойдёт диспетчеризация сообщений исполнителю. Отправной конец канала – это часть структуры, им пользуется менеджер исполнителей. В свою очередь, приёмный конец канала находится в исключительном владении потока, который выполняет задания.
impl<Req, Res> Worker<Req, Res> where Req: Send + Debug + 'static, Res: Send + Debug + 'static, { /// Создаём нового исполнителя из заданного источника, диспетчеризуем канал очереди и канал завершения (done). /// Канал done channel и канал job_source перемещаются в замыкание потока-исполнителя, чтобы /// получать запросы и, соответственно, уведомлять о завершении работы над ними. /// /// Исполнитель рассчитывает, что `mpsc::Receiver` для done `mpsc::Sender` переживёт его. pub fn new( job_source: Receiver<Message<Req, Res>>, disp_q: Sender<Message<Req, Res>>, done: Sender<Option<u64>>, uid: u64, ) -> Self { Worker { uid, disp_q, worker: Some(Self::worker_thread(job_source, done, uid)), pending: 0, } } /// Создаём нового исполнителя из заданного источника, канал завершения (done) и uid исполнителя. /// Этот код – не для непосредственного использования. Рекомендуется лучше создать `Worker`, /// поскольку экземпляр `Worker` также управляет жизненным циклом потока и очисткой после его работы. /// /// /// Основной цикл потока-исполнителя /// /// // ... /// while let Ok(Request(job)) = job_source.recv() { /// job.result_channel.send(job.task(job.req)); /// done.send(worker_uid); /// } /// // ... /// pub fn worker_thread( jobs: Receiver<Message<Req, Res>>, done: Sender<Option<u64>>, uid: u64, ) -> JoinHandle<Result<(), WorkerError>> { thread::spawn(move || -> Result<(), WorkerError> { while let Ok(Message::Request(job)) = jobs.recv() { job.resp_with_result() .or(Err(WorkerError::ResultResponseFailed))?; done.send(Some(uid)) .or(Err(WorkerError::DoneNotificationFailed))? } Ok(()) }) }В основе потока-исполнителя лежит обычный цикл while, в котором мы непрерывно получаем сообщения от источника заданий, пока задания не будут исчерпаны. В ответ на каждое задание мы посылаем результат и уведомление о завершении задачи.
Можно диспетчеризовать задания потоку следующим образом:
/// Назначаем задание этому потоку для выполнения. #[inline] pub fn dispatch(&self, job: Job<Req, Res>) -> Result<(), WorkerError> { self.disp_q .send(Message::Request(job)) .or(Err(WorkerError::DispatchFailed)) } Наконец, завершаем поток-исполнитель, посылая ему сообщение Terminate, а затем выполняя с ним join().
/// Завершаем этого исполнителя, отправляя сообщение Terminate соответствующему потоку /// и вызывая в нём join(). pub fn terminate(&mut self) -> Result<(), WorkerError> { if self.worker.is_none() { return Ok(()); } self.disp_q .send(Message::Terminate) .or(Err(WorkerError::TermNoticeFailed))?; return match self.worker.take().unwrap().join() { Ok(result) => result, Err(_) => Err(WorkerError::JoinFailed), }; } // ... } // Исполнитель
ThreadPool
Пул потоков представим следующим образом:
/// Пул потоков ThreadPool, чтобы вести учёт потоков-исполнителей, динамически распределять задания, так /// чтобы соблюдалась балансировка нагрузки (нагрузка должна быть равномерной). pub struct ThreadPool<Req, Res> where Req: Send + Debug + 'static, Res: Send + Debug + 'static, { pool: Option<Arc<Mutex<BinaryMaxHeap<Worker<Req, Res>>>>>, done_channel: Sender<Option<u64>>, balancer: Option<JoinHandle<Result<(), ThreadPoolError>>>, }Разберём все члены:
pool: Структура данных, в которой содержатся наши исполнители. Эту структуру мы обёртываем в мьютекс, поскольку используем её как из членов структуры ThreadPool, так и из потока-балансировщика.Arcздесь нужен для того, чтобы обеспечить возможность отправки.done_channel: Отправной конец канала, используемый для уведомлений о том, что исполнитель с заданным uid завершил задачу, делает это просто путём отправки uid конкретного исполнителя.balancer: Поток-балансировщик, отвечающий за восстановление свойства кучи, как только исполнитель завершит задачу.
Исполнители создаются следующим образом:
/// Создаём заданное количество исполнителей и возвращаем их в векторе, куда также записываем концы канала done /// Исполнители посылают свои Uid в отправной конец канала done, /// сигнализируя таким образом, что выполнение задания завершено. Поток-балансировщик /// забирает на приёмном конце канала done соответствующие Uid и как следует распределяет их. /// /// Одно из ключевых решений, принятых при создании этой библиотеки, таково: мы перемещаем каналы именно туда, /// где они будут использоваться, а не организуем их совместного использования при помощи блокировки. Отправной конец канала /// клонируется и передаётся каждому из исполнителей. Возвращённый приёмный конец затем полагается /// переместить в замыкание потока-балансировщика. pub fn new_workers( workers: usize, ) -> ( Vec<Worker<Req, Res>>, (Sender<Option<u64>>, Receiver<Option<u64>>), ) { let (done_tx, done_rx) = channel::<Option<u64>>(); let mut worker_vec = Vec::<Worker<Req, Res>>::with_capacity(workers); for i in 0..workers { let (wtx, wrx) = channel::<Message<Req, Res>>(); worker_vec.push(Worker::new( wrx, wtx, done_tx.clone(), i.try_into().unwrap(), )); } (worker_vec, (done_tx, done_rx)) } Поток-балансировщик создаётся следующим образом: /// Возвращаем потоку-балансировщику дескриптор `JoinHandle` для заданного пула исполнителей. Балансировщик слушает /// приёмный конец канала done, чтобы получить таким образом Uid тех исполнителей, /// которые справились со своими заданиями и, которым, следовательно, требуется декремент нагрузки. /// Основной цикл балансировщика можно описать на псевдокоде следующим образом: /// /// while uid = done_channel.recv() { /// restore_worrker_pool_order(worker_pool, uid) /// } /// /// Поскольку пул исполнителей также используется главным потоком, занятым диспетчеризацией заданий, нам нужно /// обернуть его в мьютекс. pub fn balancer_thread( done_channel: Receiver<Option<u64>>, worker_heap: Arc<Mutex<BinaryMaxHeap<Worker<Req, Res>>>>, ) -> JoinHandle<Result<(), ThreadPoolError>> { thread::spawn(move || -> Result<(), ThreadPoolError> { while let Ok(Some(uid)) = done_channel.recv() { restore_worker_pool_order( worker_heap .lock() .or(Err(ThreadPoolError::LockError))? .deref_mut(), uid, )?; } Ok(()) }) }Вот какая логика восстановления свойства кучи действует при декременте нагрузки у исполнителя:
/// Восстанавливаем порядок исполнителей в пуле, внеся все изменения в /// дпнные о количестве оставшихся у них незавершенных задач. fn restore_worker_pool_order<Req, Res>( worker_pool: &mut BinaryMaxHeap<Worker<Req, Res>>, worker_uid: u64, ) -> Result<(), ThreadPoolError> where Req: Send + Debug + 'static, Res: Send + Debug + 'static, { if worker_pool.is_empty() { return Ok(()); } let mut pool_restored = false; if let Some(i) = worker_pool.index_in_heap_from_uid(worker_uid) { if let Some(worker) = worker_pool.get(i) { worker.dec_load(); pool_restored = true; } worker_pool.restore_heap_property(i); } return if pool_restored { Ok(()) } else { Err(ThreadPoolError::LookupError) }; }Следовательно, мы создаём ThreadPool с потоками-исполнителями и потоком-балансировщиком вот так:
impl<Req, Res> ThreadPool<Req, Res> where Req: Send + Debug + 'static, Res: Send + Debug + 'static, { // ... pub fn new(workers: usize) -> Self { let (worker_vec, (done_tx, done_rx)) = Self::new_workers(workers); let worker_pool = Arc::new(Mutex::new(BinaryMaxHeap::from_vec(worker_vec))); let balancer = Self::balancer_thread(done_rx, Arc::clone(&worker_pool)); ThreadPool { pool: Some(worker_pool), done_channel: done_tx, balancer: Some(balancer), } } // ... } Далее нам нужен способ диспетчеризации заданий (Jobs) в этом пуле потоков. Идея проста: выталкиваем верхний элемент кучи, обновляем значение его нагрузки, после чего восстанавливаем позицию в корректном виде.
/// Планировщик назначает новое задание конкретному исполнителю, /// выбирая для этой цели наименее загруженный поток-исполнитель fn worker_pool_schedule_job<Req, Res>( worker_pool: &mut BinaryMaxHeap<Worker<Req, Res>>, job: Job<Req, Res>, ) -> Result<(), ThreadPoolError> where Req: Send + Debug + 'static, Res: Send + Debug + 'static, { if worker_pool.is_empty() { return Err(ThreadPoolError::WorkerUnavailable); } if let Some(worker) = worker_pool.get(0) { worker .dispatch(job) .or(Err(ThreadPoolError::JobSchedulingFailed))?; worker.inc_load(); } worker_pool.restore_heap_property(0); Ok(()) } Вот как он используется структурой ThreadPool:
pub fn schedule(&self, job: Job<Req, Res>) -> Result<(), ThreadPoolError> { if let Some(worker_pool) = &self.pool { worker_pool_schedule_job( worker_pool .lock() .or(Err(ThreadPoolError::LockError))? .deref_mut(), job, )?; } Ok(()) }Как упоминалось выше, в пуле исполнителей необходимо применять блокировки, поскольку мы используем его совместно с потоком-балансировщиком.
Наконец, нам нужен механизм, который позволил бы завершить все потоки в двоичной куче исполнителей:
/// Завершает всех исполнителей в заданном пуле, выталкивая их /// и применяя к каждому из них `Worker::terminate()`. fn worker_pool_terminate<Req, Res>( worker_pool: &mut BinaryMaxHeap<Worker<Req, Res>>, ) -> Result<(), ThreadPoolError> where Req: Send + Debug + 'static, Res: Send + Debug + 'static, { while let Some(mut worker) = worker_pool.pop() { worker .terminate() .or(Err(ThreadPoolError::WorkerTermFailed))?; } Ok(()) } Вышеприведённую функцию мы используем в ThreadPool::terminate(). Здесь необходимо завершить как пул исполнителей, так и поток-балагсировщик.
pub fn terminate(&mut self) -> Result<(), ThreadPoolError> { // Убедимся, что все потоки выполнили задачи // также завершаем работу со всеми уведомлениями о висящих задачах. // Это необходимо, поскольку нам понадобится отбросить // приёмный конец канала done. if let Some(worker_pool) = self.pool.take() { worker_pool_terminate( worker_pool .lock() .or(Err(ThreadPoolError::LockError))? .deref_mut(), )?; } if self.balancer.is_none() { return Ok(()); } self.done_channel .send(None) .or(Err(ThreadPoolError::TermNoticeFailed))?; return match self.balancer.take().unwrap().join() { Ok(result) => result, Err(_) => Err(ThreadPoolError::JoinFailed), }; }Вы помните, что мы обернули пул в Option? Это было сделано, чтобы можно было перенести его в актуальную область видимости на этапе деаллокации памяти.
Также вызываем terminate() в drop():
impl<Req, Res> Drop for ThreadPool<Req, Res> where Req: Send + Debug + 'static, Res: Send + Debug + 'static, { /// Вызов `terminate()` fn drop(&mut self) { self.terminate().unwrap() } }Вот и всё, мы закончили реализацию пула потоков.
Тесты ThreadPool можете посмотреть здесь.
Безмерно благодарен вам за то, что вы дочитали такой длинный пост. Надеюсь, из него вы узнали что-то новое, или, как минимум, что вам было интересно.
Возможно, захочется почитать и это:
- ➤ Организуем окружение Rust и сборку Docker с применением Nix Flakes
- ➤ Интероперабельность между С++ и Rust
- ➤ Микросервисы Rust в серверном WebAssembly
- ➤ К дню рождения смайлика: миллионы долларов, многолетние суды, Набоков – история появления и популярности смайлика
- ➤ Удивительные клеточные автоматы: дефицитные правила

ссылка на оригинал статьи https://habr.com/ru/articles/761398/
Добавить комментарий