 Привет, Хаброжители!
Привет, Хаброжители!
Если вы аналитик или инженер по обработке данных и используете SQL, популярный карманный справочник станет для вас идеальным помощником. Найдите множество примеров, раскрывающих все сложности языка, а также ключевые аспекты SQL при его использовании в Microsoft SQL Server, MySQL, Oracle Database, PostgreSQL и SQLite.
В обновленном издании Элис Жао описывает, как в этих СУБД используется SQL для формирования запросов и внесения изменений в базу. Получите подробную информацию о типах данных и их преобразованиях, синтаксисе регулярных выражений, оконных функциях, операторах PIVOT и UNPIVOT и многом другом.
- Синтаксис обновлен для Microsoft SQL Server, MySQL, Oracle Database и PostgreSQL. Информация о Db2 от IBM была удалена вследствие уменьшения ее популярности, а об SQLite — добавлена в связи с ростом ее востребованности.
- В третьем издании разделы были даны в алфавитном порядке. В четвертом я изменила их расположение так, чтобы схожие понятия были сгруппированы.
- В связи с тем что аналитики и специалисты по исследованию данных стали применять SQL в своей работе, я добавила разделы с информацией о том, как использовать этот язык с Python и R (популярные языки программирования с открытым исходным кодом), а также краткий курс по SQL для тех, кому нужно быстро освежить знания.
I. Основные понятия
- В главах 1–3 представлены основные ключевые слова, концепции и инструменты для написания SQL-кода.
- В главе 4 рассматривается каждое предложение SQL-запроса.
II. Объекты базы данных, типы данных и функции
- В главе 5 перечислены распространенные способы создания и модификации объектов в базе данных.
- В главе 6 перечислены типы данных, широко используемые в SQL.
- В главе 7 перечислены операции и функции, широко используемые в SQL.
III. Расширенные концепции
- В главах 8 и 9 раскрываются расширенные концепции построения запросов, в том числе описываются соединения, операторы case, оконные функции и т. д.
- В главе 10 рассматриваются решения некоторых часто встречающихся вопросов по SQL.
Расширенные концепции запросов
В этой главе мы поговорим о некоторых расширенных возможностях работы с данными с помощью SQL-запросов, помимо шести основных предложений и общих ключевых слов, с которыми мы познакомились в главах 4 и 7 соответственно.
В табл. 8.1 приведены описания и примеры кода четырех концепций, рассматриваемых в этой главе.


В этой главе подробно описывается каждая из концепций, представленных в табл. 8.1, а также типичные случаи их использования.
Операторы CASE
Оператор CASE используется для применения логики IF-ELSE в запросе. Например, с его помощью можно указать значения. Если встречается 1, то вывести vip. В противном случае отобразить general admission (общий вход).

В Oracle можно также встретить функцию DECODE, которая является более старой функцией, работающей аналогично оператору CASE.
С помощью оператора CASE можно обновить значения на время выполнения запроса. Для сохранения обновленных значений можно использовать оператор UPDATE.
В следующих двух подразделах рассматриваются два типа операторов CASE:
- простой оператор CASE для одного столбца данных;
- поисковый оператор CASE для нескольких столбцов данных.
Отображение значений на основе логики IF-THEN для одного столбца
Равенство в пределах одного столбца данных проверяется с помощью простого синтаксиса оператора CASE.
Наша цель — вместо отображения значений 1/0/NULL отобразить значения vip/reserved seating/general admission:
- если flag = 1, то ticket = vip;
- если flag = 0, то ticket = reserved seating (зарезервированное место);
- в противном случае ticket = general admission (общий вход).
Рассмотрим пример таблицы:
SELECT * FROM concert;

Реализуем логику IF-THEN с помощью простого оператора CASE:
SELECT name, flag, CASE flag WHEN 1 THEN 'vip' WHEN 0 THEN 'reserved seating' ELSE 'general admission' END AS ticket FROM concert; 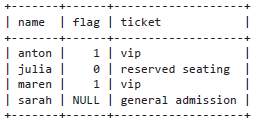
Если ни одно из предложений WHEN не соответствует указанному и не задано значение ELSE, то будет возвращено значение NULL.
Отображение значений на основе логики IF-THEN для нескольких столбцов
Любое условие (=, <, IN, IS NULL и т. д.) в потенциально нескольких столбцах данных проверяется с помощью синтаксиса искомого оператора CASE.
Наша цель — вместо отображения значений 1/0/NULL отобразить значения vip/reserved seating/general admission:
- если name = anton, то ticket = vip;
- если flag = 0 или flag = 1, то ticket = reserved seating (зарезервированное место);
- в противном случае ticket = general admission (общий вход).
Рассмотрим пример таблицы:
SELECT * FROM concert;

Реализуем логику IF-THEN с помощью простого оператора CASE:
SELECT name, flag, CASE WHEN name = 'anton' THEN 'vip' WHEN flag IN (0,1) THEN 'reserved seating' ELSE 'general admission' END AS ticket FROM concert; 
Если выполняется несколько условий, то приоритет имеет первое из перечисленных условий.
Чтобы заменить все значения NULL в столбце другим значением, можно использовать оператор CASE, но чаще всего вместо него используется NULL-функция COALESCE.
Группировка и агрегирование
SQL позволяет разделять строки на группы и агрегировать строки внутри каждой группы определенным образом, возвращая в конечном итоге только одну строку на группу.
В табл. 8.2 перечислены концепции, связанные с группировкой и агрегированием данных.

Основы работы с GROUP BY
В этой таблице показано количество калорий, сожженных двумя людьми:
SELECT * FROM workouts;

Для создания сводной таблицы необходимо решить, как это сделать:
- сгруппировать данные: разделить все значения имен на две группы — ally и jess;
- агрегировать данные по группам: найти общее количество калорий внутри каждой группы.
Для создания сводной таблицы используем предложение GROUP BY:
SELECT name, SUM(calories) AS total_calories FROM workouts GROUP BY name; 
Более подробно о том, как работает GROUP BY, можно прочитать в разделе «Предложение GROUP BY» главы 4.
Группировка по нескольким столбцам
В этой таблице показано количество калорий, сжигаемых двумя людьми во время ежедневных тренировок:
SELECT * FROM daily_workouts;

Если вы пишете запрос с предложением GROUP BY, который группирует по нескольким столбцам и/или содержит несколько агрегатов, то:
- предложение SELECT должно содержать все имена столбцов и агрегатов, которые вы хотите отображать в выходных данных;
- предложение GROUP BY должно содержать те же имена столбцов, которые есть и в предложении SELECT.
Используем предложение GROUP BY для суммирования статистики по каждому человеку, возвращая id и name, а также два агрегата:
SELECT id, name, COUNT(date) AS workouts, SUM(calories) AS calories FROM daily_workouts GROUP BY id, name; 
СОКРАЩЕНИЕ СПИСКА GROUP BY ДЛЯ ПОВЫШЕНИЯ ЭФФЕКТИВНОСТИ
Если известно, что каждый идентификатор связан с одним именем, то можно исключить столбец name из предложения GROUP BY и получить те же результаты, которые дал предыдущий запрос:
SELECT id, MAX(name) AS name, COUNT(date) AS workouts, SUM(calories) AS calories FROM daily_workouts GROUP BY id;Этот механизм работает более эффективно, будучи скрытым, так как GROUP BY должно выполняться только для одного столбца.
Чтобы компенсировать исключение имени из предложения GROUP BY, можно заметить, что к столбцу name в предложении SELECT была применена произвольная агрегатная функция (MAX). Поскольку в каждой группе идентификаторов существует только одно значение имени, MAX(name) просто вернет имя, связанное с каждым идентификатором.
Агрегирование строк в одно значение или список
В предложении GROUP BY необходимо указать, как должны быть агрегированы строки данных в каждой группе:
- агрегатная функция для объединения строк в одно значение: COUNT, SUM, MIN, MAX и AVG;
- агрегатная функция для объединения строк в список (показана в примере таблицы): GROUP_CONCAT и другие, перечисленные в табл. 8.3 (см. ниже).
Рассмотрим пример таблицы:
SELECT * FROM workouts;

Используем GROUP_CONCAT в MySQL, чтобы создать список калорий:
SELECT name, GROUP_CONCAT(calories) AS calories_list FROM workouts GROUP BY name; 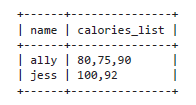
Функция GROUP_CONCAT в каждой РСУБД имеет различия.
В табл. 8.3 приведен синтаксис, поддерживаемый каждой РСУБД.
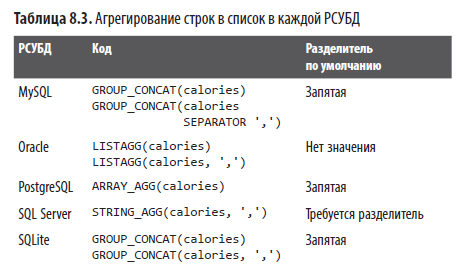
В MySQL, Oracle и SQLite разделитель (‘,’) является необязательным. PostgreSQL не принимает разделитель, а SQL Server требует его наличия.
Кроме того, можно вернуть отсортированный список или список уникальных значений.
В табл. 8.4 приведен синтаксис, поддерживаемый каждой РСУБД.

ROLLUP, CUBE и GROUPING SETS
В дополнение к предложению GROUP BY можно добавить ключевые слова ROLLUP, CUBE или GROUPING SETS, позволяющие вносить дополнительную итоговую информацию.
В этой таблице перечислены пять покупок, совершенных в течение трех месяцев:
SELECT * FROM spendings;

Примеры, приведенные в этом подразделе, основаны на этом примере GROUP BY, который возвращает ежемесячные суммарные расходы:
SELECT year, month, SUM(amount) AS total FROM spendings GROUP BY year, month ORDER BY year, month; 
ROLLUP
MySQL, Oracle, PostgreSQL и SQL Server поддерживают функцию ROLLUP, которая расширяет GROUP BY за счет добавления дополнительных строк, предназначенных для показа промежуточных итогов и общего итога.
Используем ROLLUP для отображения годовых и суммарных расходов.
Строки 2019, 2020 и суммарных расходов добавляются с помощью ROLLUP:
SELECT year, month, SUM(amount) AS total FROM spendings GROUP BY ROLLUP(year, month) ORDER BY year, month; 
Приведенный выше синтаксис работает в Oracle, PostgreSQL и SQL Server. Синтаксис в MySQL выглядит так: GROUP BY year, month WITH ROLLUP — и работает в SQL Server.
CUBE
Oracle, PostgreSQL и SQL Server поддерживают функцию CUBE, которая расширяет ROLLUP за счет добавления дополнительных строк, в которых показываются все возможные комбинации столбцов, по которым производится группировка, а также общий итог.
С помощью CUBE также можно отображать ежемесячные расходы (один месяц за несколько лет). Строки расходов за январь и февраль вставляются при добавлении CUBE:
SELECT year, month, SUM(amount) AS total FROM spendings GROUP BY CUBE(year, month) ORDER BY year, month; 

Приведенный выше синтаксис работает в Oracle, PostgreSQL и SQL Server. Кроме того, SQL Server поддерживает синтаксис GROUP BY year, month WITH CUBE.
GROUPING SETS
Oracle, PostgreSQL и SQL Server поддерживают GROUPING SETS, позволяющие указать конкретные группы, которые необходимо отобразить.
Эти данные представляют собой подмножество результатов, сгенерированных функцией CUBE, и содержат группировки лишь по одному столбцу. В данном случае возвращаются только общие годовые и общие ежемесячные расходы:
SELECT year, month, SUM(amount) AS total FROM spendings GROUP BY GROUPING SETS(year, month) ORDER BY year, month; 
Элис пишет об аналитике и поп-культуре в своем блоге A Dash of Data. Ее работы были опубликованы в Huffington Post, Thrillist и Working Mother. Она выступала на различных конференциях, включая Strata в Нью-Йорке и ODSC в Сан-Франциско, по самым разным темам: от обработки естественного языка до визуализации данных. Получила в Северо-Западном университете степень магистра в области аналитики и степень бакалавра в области электротехники.
Более подробно с книгой можно ознакомиться на сайте издательства:
» Оглавление
» Отрывок
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — SQL
ссылка на оригинал статьи https://habr.com/ru/articles/806187/
Добавить комментарий