Настройка программного обеспечения
Без промедления начнём. Нам нужно установить следующее ПО:
-
Windows 10
-
Anaconda 3 (Python 3.8)
-
Visual Studio 2019 (Community) — объясню позже, зачем она понадобится.
Открываем Anaconda Prompt (Anaconda3) и устанавливаем следующие пакеты:
pip install opencv-python pip install dlib pip install face_recognitionИ уже на этом моменте начнутся проблемы с dlib.
Решаем проблему с dlib
Я перепробовал все решения, что нашёл в интернете и они оказались неактуальными — раз, два, три, официальное руководство и видео есть. Поэтому будем собирать пакет вручную.
Итак, первая же ошибка говорит о том, что у нас не установлен cmake.
ERROR: CMake must be installed to build dlib

Не закрывая консоль, вводим следующую команду:
pip install cmakeПроблем при установке быть не должно

Пробуем установить пакет той же командой (pip install dlib), но на этот раз получаем новую ошибку:
Отсутствуют элементы Visual Studio

Ошибка явно указывает, что у меня, скорее всего, стоит студия с элементами только для C# — и она оказывается права. Открываем Visual Studio Installer, выбираем «Изменить», в вкладке «Рабочие нагрузки» в разделе «Классические и мобильные приложения» выбираем пункт «Разработка классических приложений на С++»:
Пошагово



Почему важно оставить все галочки, которые предлагает Visual Studio. У меня с интернетом плоховато, поэтому я решил не скачивать пакет SDK для Windows, на что получил следующую ошибку:
Не нашли компилятор
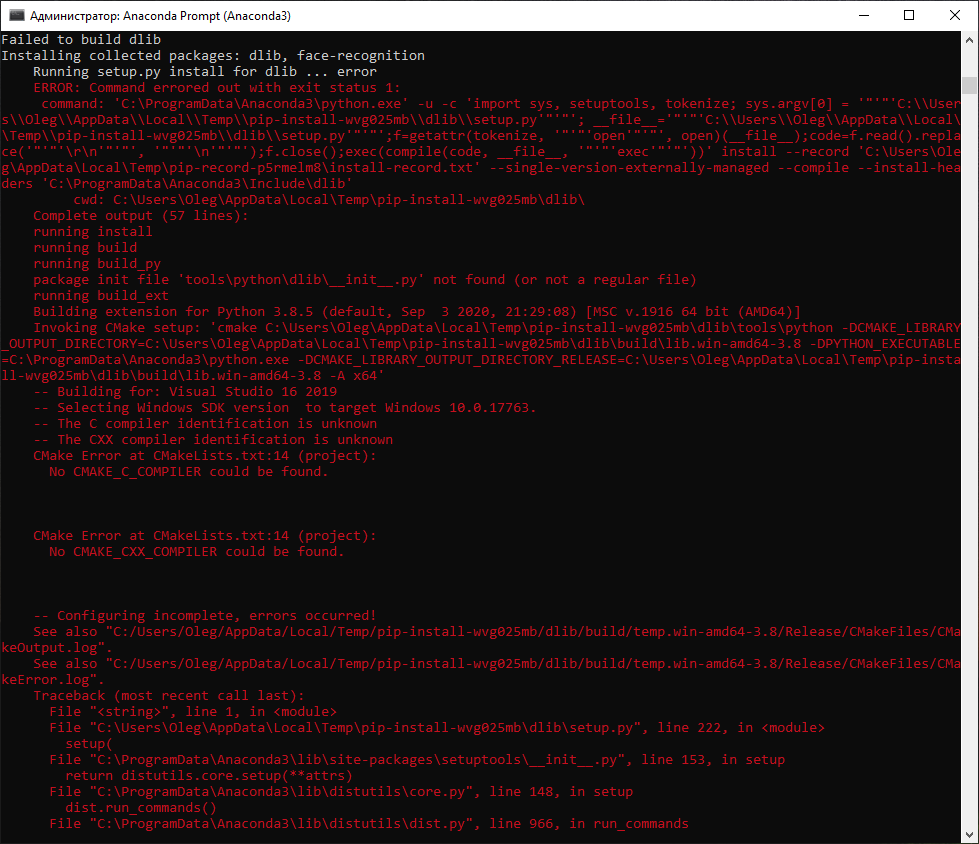
Я начал искать решение этой ошибки, пробовать менять тип компилятора (cmake -G » Visual Studio 16 2019″), но только стоило установить SDK, как все проблемы ушли.
Я пробовал данный метод на двух ПК и отмечу ещё пару подводных камней. Самое главное — Visual Studio должна быть 2019 года. У меня под рукой был офлайн установщик только 2017 — я мигом его поставил, делаю команду на установку пакета и получаю ошибку, что нужна свежая Microsoft Visual C++ версии 14.0. Вторая проблема была связана с тем, что даже установленная студия не могла скомпилировать проект. Помогла дополнительная установка Visual C++ 2015 Build Tools и Microsoft Build Tools 2015.
Открываем вновь Anaconda Prompt, используем ту же самую команду и ждём, когда соберется проект (около 5 минут):
Сборка
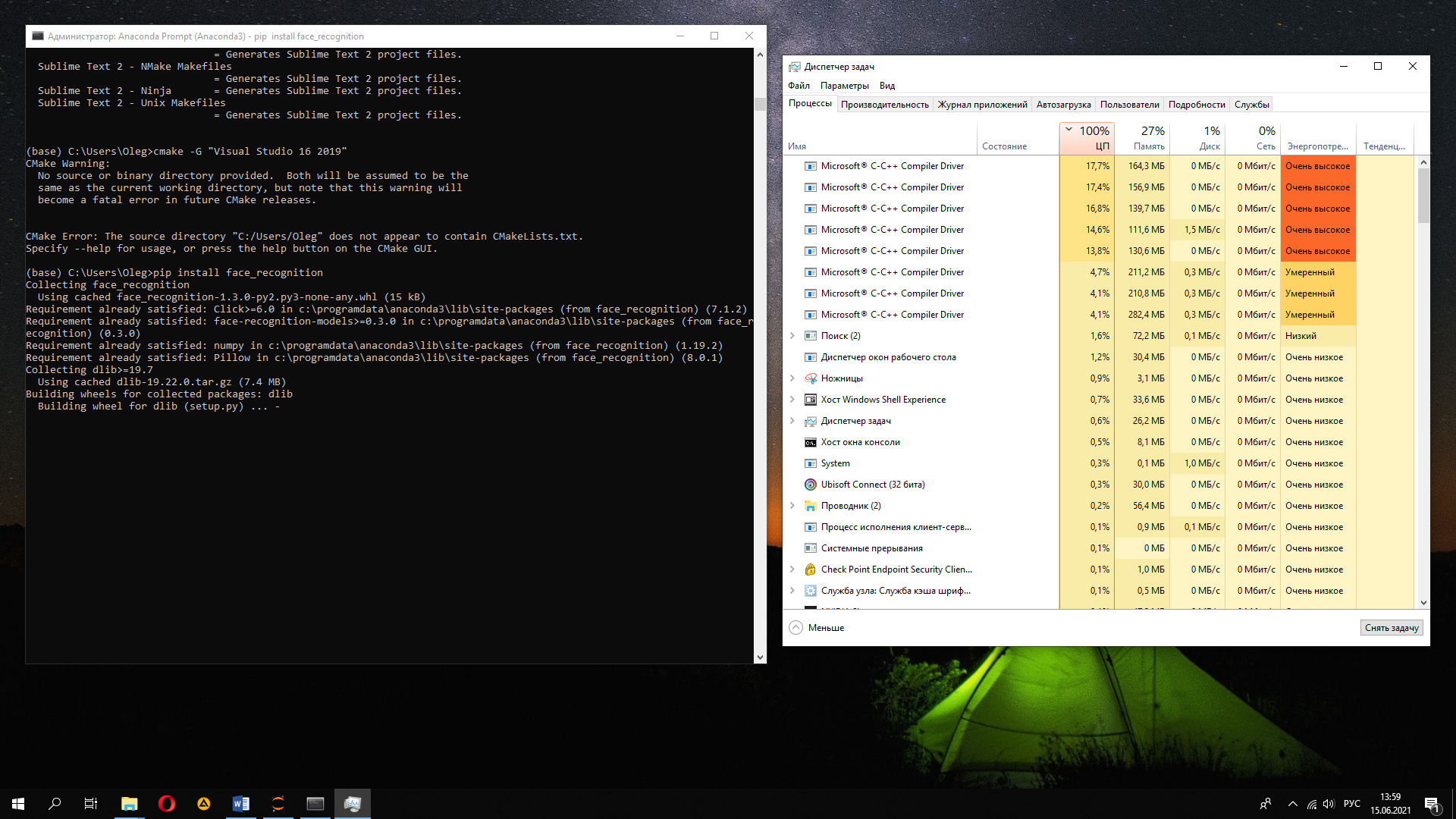

Для удобства залили скомпилированные файлы в репозиторий — https://github.com/OlegBezverhii/python-notebooks/blob/master/For%20dlibs
Управляем громкостью
Вариантов оказалось несколько (ссылка), но чем проще — тем лучше. На русском язычном StackOverflow предложили использовать простую библиотеку от Paradoxis — ей и воспользуемся. Чтобы установить её, нам нужно скачать архив, пройти по пути C:\ProgramData\Anaconda3\Lib и перенести файлы keyboard.py, sound.py из архива. Проблем с использованием не возникало, поэтому идём дальше
Собираем события мыши
Самым популярным модулем для автоматизации управления мышью/клавиатурой оказался pynput. Устанавливаем так же через (pip install pynput). У модуля в целом неплохое описание — https://pynput.readthedocs.io/en/latest/mouse.html . Но у меня возникли сложности при получении событий. Я написал простую функцию:
from pynput import mouse def func_mouse(): with mouse.Events() as events: for event in events: if event: print('Переместил мышку/нажал кнопку/скролл колесиком: {}\n'.format(event)) print('Делаю половину громкости: ', time.ctime()) Sound.volume_set(volum_half) breakВ комментариях к статье придём к истине, как лучше сделать.
А что в итоге?
Adam Geitgey, автор библиотеки face recognition, в своём репозитории имеет очень хороший набор примеров, которые многие используют при написании статей: https://github.com/ageitgey/face_recognition/tree/master/examples
Воспользуемся одним из них и получим следующий код, который можно скачать по ссылке: Activity.ipynb, Activity.py
Код
# Подключаем нужные библиотеки import cv2 import face_recognition # Получаем данные с устройства (веб камера у меня всего одна, поэтому в аргументах 0) video_capture = cv2.VideoCapture(0) # Инициализируем переменные face_locations = [] from sound import Sound Sound.volume_up() # увеличим громкость на 2 единицы current = Sound.current_volume() # текущая громкость, если кому-то нужно volum_half=50 # 50% громкость volum_full=100 # 100% громкость Sound.volume_max() # выставляем сразу по максимуму # Работа со временем # Подключаем модуль для работы со временем import time # Подключаем потоки from threading import Thread import threading # Функция для работы с активностью мыши from pynput import mouse def func_mouse(): with mouse.Events() as events: for event in events: if event == mouse.Events.Scroll or mouse.Events.Click: #print('Переместил мышку/нажал кнопку/скролл колесиком: {}\n'.format(event)) print('Делаю половину громкости: ', time.ctime()) Sound.volume_set(volum_half) break # Делаем отдельную функцию с напоминанием def not_find(): #print("Cкрипт на 15 секунд начинается ", time.ctime()) print('Делаю 100% громкости: ', time.ctime()) #Sound.volume_set(volum_full) Sound.volume_max() # Секунды на выполнение #local_time = 15 # Ждём нужное количество секунд, цикл в это время ничего не делает #time.sleep(local_time) # Вызываю функцию поиска действий по мышке func_mouse() #print("Cкрипт на 15 сек прошел") # А тут уже основная часть кода while True: ret, frame = video_capture.read() ''' # Resize frame of video to 1/2 size for faster face recognition processing small_frame = cv2.resize(frame, (0, 0), fx=0.50, fy=0.50) rgb_frame = small_frame[:, :, ::-1] ''' rgb_frame = frame[:, :, ::-1] face_locations = face_recognition.face_locations(rgb_frame) number_of_face = len(face_locations) ''' #print("Я нашел {} лицо(лица) в данном окне".format(number_of_face)) #print("Я нашел {} лицо(лица) в данном окне".format(len(face_locations))) ''' if number_of_face < 1: print("Я не нашел лицо/лица в данном окне, начинаю работу:", time.ctime()) ''' th = Thread(target=not_find, args=()) # Создаём новый поток th.start() # И запускаем его # Пока работает поток, выведем на экран через 10 секунд, что основной цикл в работе ''' #time.sleep(5) print("Поток мыши заработал в основном цикле: ", time.ctime()) #thread = threading.Timer(60, not_find) #thread.start() not_find() ''' thread = threading.Timer(60, func_mouse) thread.start() print("Поток мыши заработал.\n") # Пока работает поток, выведем на экран через 10 секунд, что основной цикл в работе ''' #time.sleep(10) print("Пока поток работает, основной цикл поиска лица в работе.\n") else: #все хорошо, за ПК кто-то есть print("Я нашел лицо/лица в данном окне в", time.ctime()) Sound.volume_set(volum_half) for top, right, bottom, left in face_locations: cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2) cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break video_capture.release() cv2.destroyAllWindows()Суть кода предельно проста: бегаем в цикле, как только появилось хотя бы одно лицо (а точнее координаты), то звук делаем 50%. Если не нашёл никого поблизости, то запускаем цикл с мышкой.
Тестирование в бою
Ожидание и реальность
Если вы посмотрели видео, то поняли, что результат ещё далёк от реальной эксплуатации.
Признаю честно — до этого момента никогда не сталкивался с многопоточностью на Python, поэтому «с наскоку» тему взять не удалось и результат по видео понятен. Есть неплохая статья на Хабре, описывающая различные методы многопоточности, применяемые в языке. Пока у меня решения нету по этой теме нету — будет повод разобраться лучше и дописать код/статью с учетом этого.
Так же возникает закономерный вопрос — а если вместо живого человека поставить перед монитором картинку? Да, она распознает, что, скорее всего, не совсем верно. Мне попался очень хороший материал по поводу определения живого лица в реальном времени — https://www.machinelearningmastery.ru/real-time-face-liveness-detection-with-python-keras-and-opencv-c35dc70dafd3/ , но это уже немного другой уровень и думаю новичкам это будет посложнее. Но эксперименты с нейронными сетями я чуть позже повторю, чтобы тоже проверить верность и повторяемость данного руководства.
Немаловажным фактором на качество распознавания оказывает получаемое изображение с веб-камеры. Предложение использовать 1/4 изображения (сжатие его) приводит только к ухудшению — моё лицо алгоритм распознать так и не смог. Для повышения качества предлагают использовать MTCNN face detector (пример использования), либо что-нибудь посложнее из абзаца выше.
Другая интересная особенность — таймеры в Питоне. Я, опять же, признаю, что ни разу до этого не было нужды в них, но все статьях сводится к тому, чтобы ставить поток в sleep(кол-во секунд). А если мне нужно сделать так, чтобы основной поток был в работе, а по истечению n-ое количества секунд не было активности, то выполнялась моя функция? Использовать демонов (daemon)? Так это не совсем то, что нужно. Писать отдельную программу, которая взаимодействует с другой? Возможно, но единство программы пропадает.
Заключение
На своём примере могу точно сказать — не все руководства одинаково полезны и простая задача может перерасти в сложную. Я понимаю, что большинство материалов является переводом/простым копированием документации. Но если ты пишешь руководство, то проверь хотя бы на тестовой системе, что написанные тобой действия точно повторимы. Пробуйте, экспериментируйте — это хороший повод изучить и узнать новое.
P.S. Предлагаю вам, читатели, обсудить в комментариях статью — ваши идеи, замечания, уточнения.
ссылка на оригинал статьи https://habr.com/ru/articles/563124/
Добавить комментарий