
Небольшой пост о том, как собрать в единый pdf все записи о сданных анализах в поликлинике из электронной медицинской карты. Данные располагаются на сайте (https://lk.emias.mos.ru/medical-records), однако пользоваться ими неудобно, так как на сайте все свалено в несколько pdf куч. И, чтобы посмотреть, все позиции по анализам, сданным, например, в один день, необходимо заходить в каждую из этих куч и смотреть только эту одну позицию. Итого можно посмотреть до 15 pdf с анализами, сданных в один день. А уж если хочется за несколько дней посмотреть результаты анализов, умножай на n и затем вручную сравнивай!
В качестве опции также будет осуществлен вывод табличных данных из pdf в excel.
Выглядит все это примерно следующим образом:
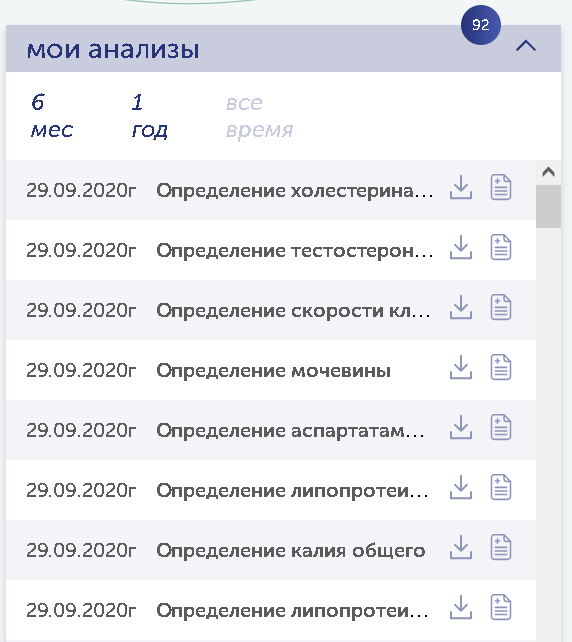
Нажимая на стрелочку вниз, предлагается скачивать файлы pdf и далее их изучать вручную.
За два года может накопиться до 125 файлов и в них легко запутаться, так как при скачивании они принимают одинаковые имена, а об их дате можно узнать, лишь открыв их.
Что будет делать программа ?
Программа будет «заходить» на сайт медкарты, позволяя пользователю ввести только код из смс (необходимое требование при регистрации на сайте), находить раздел с анализами, «проваливаться» туда, скачивать все pdf. Далее, исходя из дат сдачи анализов, программа разложит их по папкам с соответствующей датой, склеит в каждой папке все файлы в один pdf.
В итоговом pdf файле программа выделит цветом, если есть отклонение:

Во второй части мини-проекта будет осуществлен вывод всех данных из всех pdf с анализами в единую excel таблицу с использованием несколько различных подходов.
Приступаем.
Импорты библиотек:
import webbrowser,time from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.firefox.options import Options import shutil import PyPDF2, os import fitz *При установке модуля fitz, может потребоваться модуль PyMuPDF. При установке последнего (pip install PyMuPDF) можно столкнуться с ошибкой «error: Microsoft Visual C++ 14.0 is required. Get it with „Microsoft Visual…“ Чтобы ее обойти можно попробовать установить модуль следующим образом: „pip install —only-binary :all: PyMuPDF“.
Заходить на сайт будем с помощью модуля selenium и браузера chrome. Поэтому все настройки для них:
options = webdriver.ChromeOptions() options.add_argument("start-maximized") # options.add_argument("--headless") options.add_experimental_option("excludeSwitches", ["enable-automation"]) options.add_experimental_option('useAutomationExtension', False) browser = webdriver.Chrome(options=options) #browser = webdriver.Firefox(options=options) browser.get ('https://lk.emias.mos.ru/medical-records') time.sleep (5) *Для запуска браузера может потребоваться chromedriver. Если web-страница не открывается программой и вылетает с ошибкой, в которой присутствует chromedriver — обновите chromedriver, скачайте версию для своего браузера.
Далее идет блок авторизации на сайте медкарты, проходящий через сайт mos.ru.
Программа сама вбивает логин и пароль в нужные поля (эти поля необходимо предварительно заполнить в программе), нажимает кнопку „Войти“. Однако, так как требуется еще и ввести код из смс на странице, пользователю необходимо ввести его вручную на сайте, когда появится соответствующее сообщение. В оболочке, в которой работает программа python, также необходимо нажать любую кнопку, чтобы программа продолжила работу:
act = browser.find_element_by_id('login') for i in 'login@yandex.ru': act.send_keys(i) time.sleep (0.1) act = browser.find_element_by_id('password') for i in 'password': act.send_keys(i) time.sleep (0.1) act = browser.find_element_by_id('bind').click() x=input('Введите код sms на странице и нажмите любую кнопку здесь') Переход на сайте в раздел с анализами и переход в директорию на диске, куда будет производиться сохранение:
act = browser.find_element_by_css_selector('#analyzes_card_open_button > div > span') act.click() time.sleep(3) act = browser.find_element_by_css_selector('#analyzes_card_all > div > span') act.click() time.sleep(3) cwd = os.path.join(os.path.expandvars("%userprofile%"),"Downloads") os.chdir(cwd)
Основной цикл программы
Теперь программа будет брать дату на сайте перед каждой записью анализа и создавать
одноименную папку на диске. Скачивать без подтверждения pdf с сайта, а так как директория скачивания едина для всех файлов (задана при создании browser), то еще и перемещать каждый pdf в целевую директорию с помощью shututil.
#переходим в папку для скачивания и скачиваем, создавая папки по датам x=0 try: while True: text=browser.find_element_by_xpath('/html/body/div[1]/div[1]/div[3]/div[2]/div/div[2]/div[1]/div[1]/div[2]/div[3]/div/div[3]/div[2]/div/div['+str(x+1)+']/span').text if not os.path.exists(text): os.makedirs(text) act=browser.find_element_by_css_selector('#analyzes_list_download-'+str(x)+' > div > svg') act.click() time.sleep(2) for root, dirs, files in os.walk("."): for file in files: if file.endswith('pdf'): try: shutil.move(file, text) #перенос файла в целевую директорию except: pass x+=1 except: pass В результате должны появиться папки с датами сдачи анализов, а внутри папок — все анализы, сданные в эту дату:

Вспомогательные функции
Создадим функцию, которая склеит все pdf в один файл.
#работаем с текстом в файлах def join_pdfs(): pdfFiles = [] for filename in os.listdir('.'): if filename.endswith('.pdf'): pdfFiles.append(filename) pdfFiles.sort() pdfWriter = PyPDF2.PdfFileWriter() # Loop through all the PDF files. for filename in pdfFiles: pdfFileObj = open(filename, 'rb') pdfReader = PyPDF2.PdfFileReader(pdfFileObj) # Loop through all the pages and add them. for pageNum in range(0, pdfReader.numPages): pageObj = pdfReader.getPage(pageNum) pdfWriter.addPage(pageObj) # Save the resulting PDF to a file. pdfOutput = open('all.pdf', 'wb') pdfWriter.write(pdfOutput) pdfOutput.close() А также функцию, которая подсветит желтым маркером результаты анализа, если есть отклонения. Здесь просто поиск по тексту искомой фразы.
def highlight(): #помечаем отклонения в файле all.pdf желтым цветом и сохраняем как highlighted_text.pdf with fitz.open('all.pdf') as doc: for page in doc: areas = page.searchFor("отклонение от") page.addHighlightAnnot(areas) doc.save("highlighted_text.pdf") Теперь применим созданные функции ко всем папкам с анализами.
for root, dirs, files in os.walk("."): for i in dirs: os.chdir(i) join_pdfs() highlight() os.chdir('..') В результате в каждой папке создается файл all.pdf и файл highlighted_text.pdf, в которых собраны результаты, а во втором файле еще и подсвечены отклонения.
Сформируем единую таблицу excel, собрав данные из таблиц pdf
Для этих целей воспользуемся двумя сторонними пакетами и посмотрим, насколько корректно они обработают таблицы в pdf файлах с анализами.
Первый пакет — camelot —
pip install camelot-py[cv]Для работы с ним также придется установить стороннее приложение ghostscript и добавить его в PATH (например, C:\gostscript\gs9.55.0\bin).
Сама программа выглядит так:
import os import shutil import pandas as pd df1 = pd.DataFrame() for root, dirs, files in os.walk("."): for i in dirs: os.chdir(i) date_my = {'Тест': i} #добавили дату в датафрейм df1=df1.append(date_my,ignore_index=True) for root, dirs, files in os.walk("."): for file in files: if file.endswith('.pdf'): print(file) tables = camelot.read_pdf(file) print("Total tables extracted:", tables.n) for n in range(len(tables)): df1=df1.append(tables[n].df[1:],ignore_index=True)#добавили датафрейм os.chdir('..') df1.to_excel('out1.xlsx',header=False, index=False) Camelot создает датафреймы, которые понимает pandas. В данном случае мы первоначально создали свой датафрейм, далее добавили в него строку с датой сдачи анализов в целом и, далее, в цикле добавили все извлеченные таблицы из всех pdf.
По непонятным причинам camelot обрабатывает не все pdf c табличными данными и из некоторых файлов не извлекает таблицы, несмотря на то, что структурно файлы схожи между собой:

Тем не менее, результат для извлеченных данных неплохой:

Теперь посмотрим на альтернативный пакет — tabula.
pip install tabula-pyОн также требует установки дополнительного ПО, в данном случае java (jre). Путь к последней, также необходимо добавить в PATH (Например, C:\Program Files (x86)\Java\jre1.8.0_221\bin).
Текст программы схож с предыдущей:
import tabula #https://www.thepythoncode.com/article/extract-pdf-tables-in-python-camelot #tabula-py #необходима java (jre), путь к которой доваить в PATH - C:\Program Files (x86)\Java\jre1.8.0_221\bin #выводит итоговый результат из всех директорий в out2.xlsx import csv,os import shutil import pandas as pd df1 = pd.DataFrame() for root, dirs, files in os.walk("."): for i in dirs: #print(i) #print(os.getcwd()) os.chdir(i) date_my = {'Тест': i} #добавили дату в датафрейм df1=df1.append(date_my,ignore_index=True) for root, dirs, files in os.walk("."): for file in files: if file.endswith('.pdf'): if file=='Определение ГГТ-γ-глютамилтрансферазы.pdf': os.rename(file, 'Определение ГГТ-глютамилтрансферазы.pdf') file='Определение ГГТ-глютамилтрансферазы.pdf' print(file) tables = tabula.read_pdf(file, pages="all") df1=df1.append(tables,ignore_index=True)#добавили датафрейм os.chdir('..') df1.to_excel('out2.xlsx',header=False, index=False) Обработка pdf идет также, через преобразование таблиц в датафреймы.
Tabula обработала в итоге все файлы pdf, даже те, что не смог camelot. Однако в excel таблицы
отобразились не идеально:

На этом все, теперь можно наслаждаться результатами анализов, созерцая все вместе.
Надеюсь, программы окажутся полезными. Хотя бы до тех пор, пока в личном кабинете электронной медицинской карты не появится схожий функционал.
Скачать программы — здесь.
ссылка на оригинал статьи https://habr.com/ru/articles/581424/
Добавить комментарий