
Привет!
Меня зовут Александр, я руковожу backend-разработкой в КТS. Сегодня расскажу, как написать асинхронный краулер.
Такая задача часто встречается на практике, когда нужно реализовать периодическую синхронизацию/обкачку между сервисами.
Статья написана по мотивам вебинара, который мы проводили в рамках курса «Асинхронное программирование на Python для джуниор-разработчиков». Если интересно, загляните посмотреть.
Что будет в статье:
Цель
У нас есть краулер, который обкачивает страницы. Это может быть поисковый бот Google, который ходит по сайтам, скачивает данные, кладет в базу и индексирует, или какой-нибудь агрегатор: аптек, маркетплейсов и т.д.
Задача в том, что краулер должен работать и не положить сервис, который он обкачивает.
Код для начала работы:
import asyncio from dataclasses import dataclass from typing import Optional class Pool: def __init__(self, max_rate: int, interval: int = 1, concurrent_level: Optional[int] = None): self.max_rate = max_rate self.interval = interval self.concurrent_level = concurrent_level async def start(pool): await asyncio.sleep(5) def main(): loop = asyncio.get_event_loop() try: loop.run_until_complete(start()) except KeyboardInterrupt: loop.close() if __name__ == '__main__': main()Краулеру нужно посетить и скачать много страниц, следовательно, много раз обратиться к ресурсу. Мы можем позволить себе отправлять много запросов, но сервис, на который мы приходим, может не выдержать большой нагрузки. Поэтому к источнику данных нужно ходить управляемо — сделать rate-limit.
Если в какой-то момент задача прервалась, или мы сами решили остановить краулер, нужно сделать корректную и аккуратную остановку работы. Для этого начатые задачи должны завершиться, а новые задачи из очереди должны прекратить поступать.
Исходный код
У нас есть сущность Pool. Эта сущность умеет управлять количеством запросов в единицу времени. Pool принимает:
-
max_rate — максимальное количество запросов
-
interval — интервал. Если мы передаем значения max_rate = 5 и interval = 1, в секунду может исполняться 5 запросов
-
concurrent_level — обозначает допустимое количество параллельных запросов
max_rate и concurrent_level могут не совпадать, когда время выполнения запроса больше, чем interval. Например, мы делаем 5 запросов в секунду, как заявлено в переменных, но API все равно отвечает медленнее. Чтобы не положить сервис, мы вводим переменную concurrent_level.
Планировщик
Для начала нужно написать что-то, что позволит делать ровно 5 запросов в секунду, не обращая внимание на время запроса. Для этого мы запустим планировщик, который назовем scheduler. Он будет просыпаться раз в секунду и ставить количество задач, равное max_rate. Планировщик не ждет их исполнения, просто создает 5 задач каждую секунду.
Дополним class Pool и напишем функцию scheduler:
from task import Task class Pool: def __init__(self, max_rate: int, interval: int = 1, concurrent_level: Optional[int] = None): self.max_rate = max_rate self.interval = interval self.concurrent_level = concurrent_level self.is_running = False async def _scheduler(self): while self.is_running: for _ in range(self.max_rate): passОбратите внимание на две вещи:
-
функция бесконечная, пока работает наш краулер
-
раз в период функция выполняет max_rate раз какое-то действие
Задача для краулера
Scheduler должен откуда-то взять задачи, которые нужно запланировать. Для этого нам нужно сделать очередь, которую мы возьмем из библиотеки asyncio. Примитив называется asyncio.Queue(). В class Pool дописываем:
class Pool: def __init__(self, max_rate: int, interval: int = 1, concurrent_level: Optional[int] = None): self.max_rate = max_rate self.interval = interval self.concurrent_level = concurrent_level self.is_running = False self._queue = asyncio.Queue()Теперь мы просыпаемся раз в интервал и получаем количество задач, равное max_rate. Но нужно что-то сделать, чтобы они исполнялись.
Для этого в asyncio есть функция create_task. Она запускает выполнение корутины, но при этом не дожидается ее исполнения, а создает фоновую задачу. В create_task передадим метод perform.
async def _scheduler(self): while self.is_running: for _ in range(self.max_rate): task = await self._queue.get() asyncio.create_task(task.perform)) await asyncio.sleep(self.interval)Пробный запуск
Давайте попробуем все это запустить. Сделаем функцию start и таким же образом запустим scheduler. Нам нужно не ждать его, а просто запустить в фоне корутину с помощью create_task:
async def _scheduler(self): while self.is_running: for _ in range(self.max_rate): task = await self._queue.get() asyncio.create_task(self._worker(task)) await asyncio.sleep(self.interval) def start(self): self.is_running = True asyncio.create_task(self._scheduler())В будущем для корректного завершения работы краулера нужно завершить работу scheduler. Для этого нужно вызвать cancel у задачи, поэтому возвращаемое значение из create_task мы сохраняем в переменную scheduler_task:
class Pool: def __init__(self, max_rate: int, interval: int = 1, concurrent_level: Optional[int] = None): self.max_rate = max_rate self.interval = interval self.concurrent_level = concurrent_level self.is_running = False self._queue = asyncio.Queue() self._scheduler_task: Optional[asyncio.Task] = NoneВыставим rate-limit на 3 и внутри start запустим наш Pool:
def start(self): self.is_running = True self._scheduler_task = asyncio.create_task(self._scheduler()) async def start(pool): pool = Pool(3) pool.start() await asyncio.sleep(5) Запускаем и видим, что ничего не произошло:

Это потому, что внутри очереди ничего нет. Мы сделали старт и поспали 5 секунд, а на момент окончания задачи у нас осталась фоновая задача scheduler.
Промежуточный итог
-
У нас есть Pool с параметрами:
— ограничение количества запросов max_rate
— интервал активизации планировщика interval
— максимальное количество параллельных запросов concurrent_level -
Мы написали планировщик scheduler, который работает постоянно, просыпается раз в объявленный интервал, достает из очереди max_rate задач и запускает их исполнение.
-
Задача task — просто дата-класс с функцией perform. Для описания поведения задачи нужно создать класс-наследник и в нем переопределить perform.
-
Еще мы написали функцию start, в которой выставили признак работы is_running и в фоне запустили наш планировщик.
Функции put и join
Перед тем, как запустить Pool, попробуем положить туда задачку. Для этого напишем функцию put, которая принимает задачу и кладет ее в нашу внутреннюю очередь.
Дополнительно добавим tid (task_id) и print в код задачи:
import asyncio from dataclasses import dataclass @dataclass class Task: tid: int async def perform(self, pool): print('start perform', self.tid) await asyncio.sleep(3) print('complete perform', self.tid)И добавим 10 задач перед стартом pool:
async def start(pool): pool = Pool(3) for tid in range(10): await pool.put(Task(tid)) pool.start() await asyncio.sleep(5)Добавим еще кое-что. У стандартной библиотеки queue есть метод join. Тогда краулер будет ждать не 5 секунд, как мы указали в начале, а до тех пор, пока очередь не опустеет:
async def start(pool): pool = Pool(3) for tid in range(10): await pool.put(Task(tid)) pool.start() await pool.join()Запустим и посмотрим, что произойдет:

Хотя все зависло, планировщик работал.
Вы можете увидеть, что задача выполняется 3 секунды. И, несмотря на то, что предыдущие задачи еще не завершились, планировщик все равно создает новые. Это плохо, потому что если API отвечает медленнее, чем мы шлем к нему запросы, есть вероятность «положить» сервис. Эту проблему мы решим чуть позже.
Чтобы join отработал, нужно помечать задачи выполненными. Не будем усложнять код scheduler и сделаем отдельную функцию _worker. В нее перенесем perform и ниже добавим self._queue.task_done(). Это означает, что задачу мы выполнили:
async def _worker(self, task: Task): await task.perform(self) self._queue.task_done()Обратите внимание, что _worker вызывается без await, потому что scheduler не должен ждать его завершения. Иначе он не успеет запланировать задачи.
В scheduler вместо perform нужно передать _worker и task:
async def _scheduler(self): while self.is_running: for _ in range(self.max_rate): task = await self._queue.get() asyncio.create_task(self._worker(task)) await asyncio.sleep(self.interval)Снова попробуем запустить:
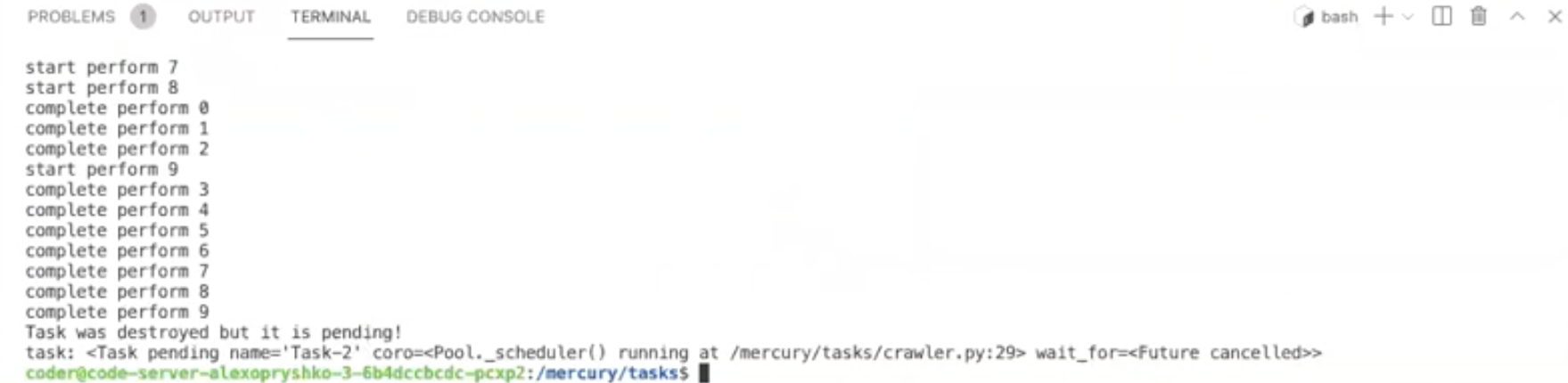
Программа завершилась, но осталось предупреждение о том, что scheduler остался работать в фоне. Функцию stop напишем чуть позже.
Semaphore
На этом этапе видим, что:
-
метод start запускает наш Pool и планировщик scheduler
-
планировщик раз в секунду ставит новые задачи и запускает _worker
-
_worker эти задачи выполняет
-
метод join ждет, пока очередь не станет пустой
Если время выполнения задач больше интервала активизации планировщика (interval), он накидывает дополнительные задачи сверху тех, которые еще не выполнились.
В таком случае количество параллельных запросов к сервису за interval будет больше rate_limit. Поэтому нужно ограничить количество параллельных запросов. Для этого нам потребуется переменная concurrent_level, которая по умолчанию равна rate_limit.
В asyncio есть примитив синхронизации Semaphore. С его помощью можно ограничить количество параллельных исполняемых worker. Если количество запланированных задач больше заданного значения, мы ждем их исполнения. В нашем примере задач 3.
Объявим Semaphore и передадим в него либо concurrent_level, либо max_rate.
Когда worker начинает исполняться, нам нужно занять Semaphore. Для этого используем «асинхронный контекстный менеджер»: async with self._sem. Мы занимаем Semaphore, пока не закончатся операции ниже — await task.perform(self) и self._queue.task_done().
async def _worker(self, task: Task): async with self._sem: await task.perform(self) self._queue.task_done()Добавим Semaphore внутрь scheduler, чтобы scheduler не запускал новые worker’ы, если количество параллельных worker’ов уже достигло максимума:
async def _scheduler(self): while self.is_running: for _ in range(self.max_rate): async with self._sem: task = await self._queue.get() asyncio.create_task(self._worker(task)) await asyncio.sleep(self.interval)Запускаем:

Мы добавили 3 задачи и ждем, пока они исполнятся. Таким образом мы соблюдаем максимальное параллельное количество запросов.
Остановка фонового планировщика
У нас осталась проблема с корректным завершением планировщика. После завершения остановки краулера появляется предупреждение о незавершенной корутине.
Чтобы этого не было, напишем функцию stop:
async def stop(self): self.is_running = False self._scheduler_task.cancel()Теперь после того, как внутри пула закончатся задачи, его нужно корректно остановить. Добавим метод stop в конце функции start:
async def start(): pool = Pool(3) for tid in range(10): await pool.put(Task(tid)) pool.start() await pool.join() await pool.stop()Попробуем:

Теперь все работает корректно.
Мы остановили планировщик, когда задачи в очереди закончились. Но если мы остановим краулер в процессе работы, начнут появляться предупреждения о том, что какая-то задача не завершилась:

А чем больше время выполнения perform, тем больше будет таких уведомлений.
Поэтому нам нужно ожидать, когда все worker завершатся. Для этого введем дополнительную переменную, обозначающую количество параллельно работающих worker: concurrent_workers. Изначально она равна 0. При запуске воркера мы увеличиваем concurrent_workers на 1. При выходе, наоборот, уменьшаем на 1:
async def _worker(self, task: FetchTask): async with self._sem: self._cuncurrent_workers += 1 await task.perform(self) self._queue.task_done() self._cuncurrent_workers -= 1Теперь нужно как-то сказать функции stop, что все параллельные worker завершились. Это произойдет, когда is_running будет false и concurrent_workers станет равной 0.
Для этого есть примитив синхронизации Event. В нашем коде мы добавим его в Pool и назовем stop_event. Это переменная, на которой можно ждать await self._stop_event.wait() до тех пор, пока кто-то не вызовет self._stop_event.set():
class Pool: def __init__(self, max_rate: int, interval: int = 1, concurrent_level: Optional[int] = None): self.max_rate = max_rate self.interval = interval self.concurrent_level = concurrent_level self.is_running = False self._queue = asyncio.Queue() self._scheduler_task: Optional[asyncio.Task] = None self._sem = asyncio.Semaphore(concurrent_level or max_rate) self._cuncurrent_workers = 0 self._stop_event = asyncio.Event()Если равна, то все worker завершили свою работу, планировщик отменен и не создает новые задачи. В таком случае все компоненты Pool остановлены или завершили свою работу — программу можно завершать.
Но если concurrent_workers не равна 0, нам нужно внутри метода stop подождать событие stop_event:
async def stop(self): self.is_running = False self._scheduler_task.cancel() if self._cuncurrent_workers != 0: await self._stop_event.wait()Когда Pool остановлен, последний работающий worker должен отправить уведомление:
async def _worker(self, task: FetchTask): async with self._sem: self._cuncurrent_workers += 1 await task.perform(self) self._queue.task_done() self._cuncurrent_workers -= 1 if not self.is_running and self._cuncurrent_workers == 0: self._stop_event.set()Обновим функцию main, чтобы все корректно работало:
def main(): loop = asyncio.get_event_loop() pool = Pool(3) try: loop.run_until_complete(start(pool)) except KeyboardInterrupt: loop.run_until_complete(pool.stop()) loop.close()Теперь все работает. После нажатия Ctrl + C выполняются оставшиеся задачи, и программа завершается:

Работа краулера на примере обкачки нашего блога на Хабре
Мы реализовали механику пула на нашей абстрактной задачке task.
Для следующего этапа я подготовил задачу FetchTask.
fetch_task
MAX_DEPTH = 2 PARSED_URLS = set() @dataclass class FetchTask(Task): url: URL depth: int def parser(self, data: str) -> List['FetchTask']: if self.depth + 1 > MAX_DEPTH: return [] soup = BeautifulSoup(data, 'lxml') res = [] for link in soup.find_all('a', href=True): new_url = URL(link['href']) if new_url.host is None and new_url.path.startswith('/'): new_url = URL.build( scheme=self.url.scheme, host=self.url.host, path=new_url.path, query_string=new_url.query_string ) if new_url in PARSED_URLS: continue PARSED_URLS.add(new_url) res.append(FetchTask( tid=self.tid, url=new_url, depth=self.depth + 1 )) return res async def perform(self, pool): async with aiohttp.ClientSession() as session: async with session.get(self.url) as resp: print(self.url, resp.status) data = await resp.text() res: List[FetchTask] = await asyncio.get_running_loop().run_in_executor( None, self.parser, data ) for task in res: await pool.put(task)Внутри функции parcer есть переменная soup, которая объявлена как soup = BeautifulSoup(data, ’lxml’). Дам небольшие пояснения.
BeautifulSoup — парсер для анализа HTML/XML.
lxml — реализация HTML/XML парсера. Из-за GIL мы специально запускаем res внутри функции perform через executor:
async def perform(self, pool): async with aiohttp.ClientSession() as session: async with session.get(self.url) as resp: print(self.url, resp.status) data = await resp.text() res: List[FetchTask] = await asyncio.get_running_loop().run_in_executor( None, self.parser, data ) for task in res: await pool.put(task)GIL — блокировка, которая запрещает параллельные потоки в Python. Но если вы пишите расширение на С, есть возможность «отпустить» GIL.
Парсер lxml написан на С. У себя под капотом он умеет отпускать GIL и выполняться в отдельном потоке. Это относится и к некоторым другим расширениям: https://lxml.de/2.0/FAQ.html#id1
В fetch_task также переопределяем функцию perform, в которой нужно сходить в сеть. Для этого я взял aiohttp client.
В задаче FetchTask мы идем на указанный URL, оттуда получаем данные и запускаем executor для их обработки. Нужно взять все ссылки в документе, перейти на них и тоже обкачать:
def parser(self, data: str) -> List['FetchTask']: if self.depth + 1 > MAX_DEPTH: return [] soup = BeautifulSoup(data, 'lxml') res = [] for link in soup.find_all('a', href=True): new_url = URL(link['href']) if new_url.host is None and new_url.path.startswith('/'): new_url = URL.build( scheme=self.url.scheme, host=self.url.host, path=new_url.path, query_string=new_url.query_string ) if new_url in PARSED_URLS: continue PARSED_URLS.add(new_url) res.append(FetchTask( tid=self.tid, url=new_url, depth=self.depth + 1 )) return resВ конце мы добавляем в результат новую задачу и увеличиваем на 1 глубину depth.
Например, когда мы поставили задачку habr.com, глубина была равна 1. Мы скачали этот документ, в котором есть и другие ссылки: блоги Mail.ru, Yandex или KTS. Когда мы стали обкачивать следующие страницы, глубина увеличилась до 2. Этот параметр нужен для ограничения количества обкачиваемых ресурсов, фактически — глубины.
Обратите внимание, что у нас есть список посещенных страничек PARSED_URLS. Так мы не будем дважды посещать одни и те же страницы.
Теперь импортируем задачи в краулер из fetch_task и изменяем start:
async def start(pool): await pool.put( FetchTask(URL('https://habr.com/ru/company/kts/blog/'), 1) ) pool.start() await pool.join() await pool.stop()Выставляем 3 запроса в секунду и смотрим, как наш краулер потихоньку обкачивает Хабр:
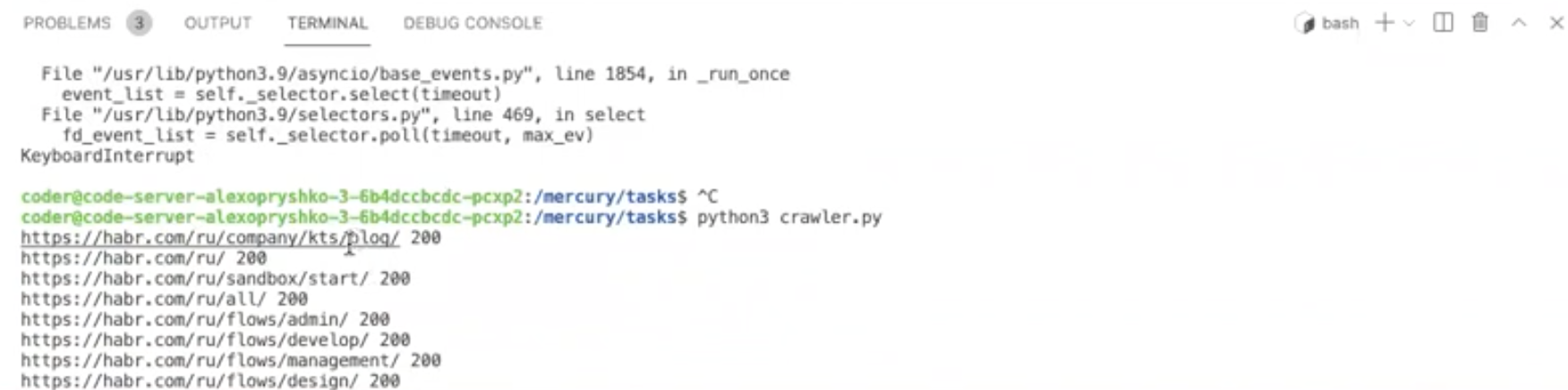
Спасибо за внимание
На этом все! Спасибо всем, кто дочитал статью.
Если сталкивались с подобными задачами, пожалуйста, поделитесь своим опытом в комментариях.
Другие наши статьи по бэкенду и асинхронному программированию для начинающих:
-
Цикл статей «Первые шаги в aiohttp»: пишем первое hello-world-приложение, подключаем базу данных, выкладываем проект в Интернет
Другие наши статьи по бэкенду и асинхронному программированию для продвинутого уровня:
Несколько слов о курсе по асинхронному программированию на Python ?
Этот курс — маст хев для тех, кто хочет прокачать харды и стать специалистом, который не боится сложных проектов.
-
Вы разберётесь, как работает асинхронное программирование и где его лучше применять.
-
Научитесь мыслить нелинейно и сможете продумывать более сложные архитектуры приложений.
-
Получите опыт работы с микросервисами и узнаете best practices написания асинхронных приложений на Python.
? Посмотреть программу курса и дату старта: https://vk.cc/cmUy1v
ссылка на оригинал статьи https://habr.com/ru/articles/583036/
Добавить комментарий