
Данный туториал пошагово разбирает процесс создания веб-приложения для определения тональности текста на основе NLP-модели.
Мы будем использовать модель из библиотеки Hugging Face Hub, но описанный подход подойдет для любой задачи машинного обучения.
План:
-
Загрузка и подготовка модели машинного обучения для использования в веб-сервисе.
-
Создание веб-сервиса с помощью FastAPI.
-
Изучение пользовательского интерфейса FastAPI для удобного ручного тестирования и демонстрации работы приложения.
-
Написание автоматических тестов с помощью библиотеки pytest.
-
Запуск приложения в Docker-контейнере.
Код доступен на GitHub.
0. Организация кода. Разделяем код ML и код приложения
Будем придерживаться следующей структуры:
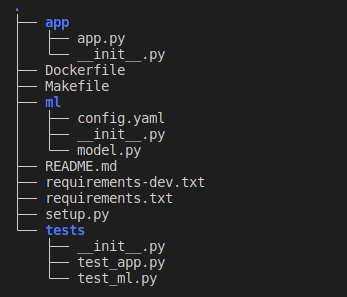
Разделение пакетов ml и app помогает организовать код проекта более логично и удобно для его дальнейшей поддержки и развития.
-
ml содержит код для работы с моделью машинного обучения.
-
app содержит код для запуска веб-приложения.
Кроме этого, в проекте есть другие важные файлы и директории, такие как:
-
tests: содержит скрипты для тестирования кода. В рамках проекта мы также будем отдельно тестировать ml-код и приложение.
-
setup.py: содержит информацию о пакете и его зависимостях.
-
requirements-dev.txt и requirements.txt: это списки зависимостей для локальной разработки и запуска приложения соответственно.
-
Dockerfile: содержит инструкции для создания Docker-контейнера.
1. Загрузка и подготовка модели машинного обучения
Очень полезная практика оформить ML-код так, чтобы с ним можно было работать как с черным ящиком. Позже сервис будет получать всю ML-логику через функцию load_model.
В зависимости от вашей задачи, load_model будет включать:
-
всю логику работы с признаками и препроцессинг,
-
загрузку модели и необходимых артефактов из хранилища,
-
инференс модели,
-
постпроцессинг предсказаний,
-
…
Начнем с загрузки модели. В нашем примере загрузим модель cointegrated/rubert-tiny-sentiment-balanced из Hugging Face Hub:
from transformers import pipeline model_hf = pipeline("sentiment-analysis", model="cointegrated/rubert-tiny-sentiment-balanced")Опишем формат, который будет возвращать модель и с которым будет позже работать сервис. Для этого удобно использовать dataclass:
from dataclasses import dataclass @dataclass class SentimentPrediction: """Class representing a sentiment prediction result.""" label: str score: floatТеперь главное: model — функция, которую будет вызывать сервис, чтобы получить предсказания. Она содержит всю необходимую логику с моделью, пре и пост-процессингом данных. В нашем случае model_hf — уже пайплайн, который содержит препроцессинг текста и токенизацию, инференс модели и постпроцессинг предсказаний. Мы только оставим предсказания лучшего класса и вернем ответ в виде экземпляра класса SentimentPrediction:
def model(text: str) -> SentimentPrediction: pred = model_hf(text) pred_best_class = pred[0] return SentimentPrediction( label=pred_best_class["label"], score=pred_best_class["score"], )Теперь код, связанный с ML закончен. На этом шаге еще полезно вспомнить, что мы использовали константы при загрузке модели из HF.
Любые константы лучше выносить в отдельные конфиги, чтобы:
-
иметь быстрый доступ ко всем параметрам модели,
-
удобно настраивать параметры модели, не залезая в код.
В нашем случае для конфигурации будем использовать YAML-файл config.yaml:
task: sentiment-analysis model: cointegrated/rubert-tiny-sentiment-balancedТогда скрипт получения модели model.py будет выглядеть следующим образом:
from dataclasses import dataclass from pathlib import Path import yaml from transformers import pipeline # load config file config_path = Path(__file__).parent / "config.yaml" with open(config_path, "r") as file: config = yaml.load(file, Loader=yaml.FullLoader) @dataclass class SentimentPrediction: """Class representing a sentiment prediction result.""" label: str score: float def load_model(): """Load a pre-trained sentiment analysis model. Returns: model (function): A function that takes a text input and returns a SentimentPrediction object. """ model_hf = pipeline(config["task"], model=config["model"], device=-1) def model(text: str) -> SentimentPrediction: pred = model_hf(text) pred_best_class = pred[0] return SentimentPrediction( label=pred_best_class["label"], score=pred_best_class["score"], ) return model Мы также добавили device=-1, чтобы модель запускалась на CPU.
2. Пишем приложение на FastAPI
Простейшее приложение на FastAPI выглядит так:
from fastapi import FastAPI app = FastAPI() # create a route @app.get("/") def index(): return {"text": "Sentiment Analysis"} Но, оно пока ничего не умеет делать, в частности, ничего не знает о модели, которую мы подготовили в пакете ml. Добавим загрузку модели во время старта приложения:
from ml.model import load_model model = None # Register the function to run during startup @app.on_event("startup") def startup_event(): global model model = load_model()Теперь осталось добавить предсказание модели. Для начала определим формат ответа SentimentResponse. Используем pydantic для валидации выходных данных:
from pydantic import BaseModel class SentimentResponse(BaseModel): text: str sentiment_label: str sentiment_score: floatМы будем возращать:
-
text— исходный текст, -
sentiment_label— название класса, который предсказала модель, -
sentiment_score— значение скора предсказания.
Напишем GET-запрос для получения предсказания по заданному тексту. Благодаря тому, что model хранит всю логику модели внутри себя, нам достаточно передать ей сырой текст. Вспомним, что model возвращает предсказание в виде объекта класса SentimentPrediction, который мы задали ранее в пакете ml. Далее формируем ответ согласно заданному формату SentimentResponse.
# Your FastAPI route handlers go here @app.get("/predict") def predict_sentiment(text: str): sentiment = model(text) response = SentimentResponse( text=text, sentiment_label=sentiment.label, sentiment_score=sentiment.score, ) return responseНа этом приложение готово! Весь код app.py занял 40 строк:
from fastapi import FastAPI from pydantic import BaseModel from ml.model import load_model model = None app = FastAPI() class SentimentResponse(BaseModel): text: str sentiment_label: str sentiment_score: float # create a route @app.get("/") def index(): return {"text": "Sentiment Analysis"} # Register the function to run during startup @app.on_event("startup") def startup_event(): global model model = load_model() # Your FastAPI route handlers go here @app.get("/predict") def predict_sentiment(text: str): sentiment = model(text) response = SentimentResponse( text=text, sentiment_label=sentiment.label, sentiment_score=sentiment.score, ) return response 3. Настраиваем окружение и запускаем тесты на ML-код
Для локального запуска в процессе разработки удобно использовать виртуальные окружения venv. Внутри виртуальных окружений можно устанавливать и использовать необходимые пакеты и библиотеки без влияния на глобальное окружение Python на системе. Создадим и активируем виртуальное окружение:
# Create a virtual environment python3.11 -m venv env # Activate the virtual environment source env/bin/activateТеперь соберем питоновский пакет, описанный в setup.py, с зависимостями из requirements.txt. Это означает, что мы создадим пакет, который будет включать в себя весь код, описанный в нашем репозитории, а также все необходимые библиотеки, указанные в файлах setup.py.
# Install/upgrade dependencies pip install -U -e .Следующий этап — тестирование ML-кода. Тесты помогают выявлять ошибки в коде на ранних этапах разработки, предотвращать появление новых ошибок при внесении изменений в код, а также сокращать время и затраты на тестирование вручную.
Для тестирования будет использовать библиотеку pytest. Чтобы установить эту библиотеку и другие зависимости, которые необходимы только для разработки, а не для использования проекта в продакшн-среде, мы указали их в файле requirements-dev.txt. Информация о зависимостях также прописана в файле setup.py, поэтому для их установки мы можем использовать команду:
pip install -U -e .[dev]Тесты на код машинного обучения хранятся в test_ml.py. В данном примере у нас 3 теста, которые проверяют, корректно ли модель определяет положительную, отрицательную и нейтральную тональность в тексте:
import pytest from ml.model import SentimentPrediction, load_model @pytest.fixture(scope="function") def model(): # Load the model once for each test function return load_model() @pytest.mark.parametrize( "text, expected_label", [ ("очень плохо", "negative"), ("очень хорошо", "positive"), ("по-разному", "neutral"), ], ) def test_sentiment(model, text: str, expected_label: str): model_pred = model(text) assert isinstance(model_pred, SentimentPrediction) assert model_pred.label == expected_labelБиблиотека pytest предоставляет удобный и интуитивно понятный синтаксис для написания тестов. Здесь мы использовали:
-
фикстуры — позволяют задавать начальные условия для тестов. В нашем случае, фикстура
modelзагружает модель перед началом каждого тестового запуска. -
параметризация — задает различные значения для тестовых параметров, уменьшая необходимость в дублировании кода.
В данном случае, тест проверяет, что модель верно определяет тональность текста, и для каждого параметра (text, expected_label) проверяет соответствующее значение предсказания модели. Если значение не соответствует ожидаемому результату, тест выдает ошибку.
Для запуска тестов нужно воспользоваться командой:
pytest tests/test_ml.py4. Запуск приложения и удобный интерфейс FastAPI
С использованием uvicorn, мы можем запустить наше приложение и обрабатывать входящие HTTP-запросы. Для запуска приложения с помощью uvicorn выполним следующую команду:
# Run app uvicorn app.app:app --host 0.0.0.0 --port 8080где app.app — это путь к файлу с нашим приложением, app — имя экземпляра приложения, --host — параметр, указывающий IP‑адрес, на котором будет запущен сервер (в данном случае 0.0.0.0), и --port — параметр, указывающий порт, на котором будет запущен сервер (в данном случае 8080).
После выполнения этой команды, uvicorn запустит наше приложение и начнет принимать входящие HTTP‑запросы на указанном порту. Информацию о запуске приложения мы увидим в терминале:

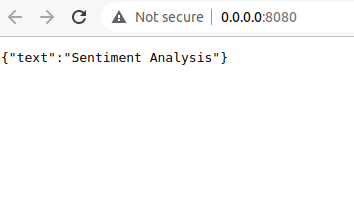
Откроем эту ссылку в браузере и увидим то самое сообщение, которое мы указали, когда начинали писать приложение на FastAPI.
FastAPI дополнительно предоставляет очень удобный интерфейс для отправки запросов. Он доступен, если в строке браузера добавить /docs:
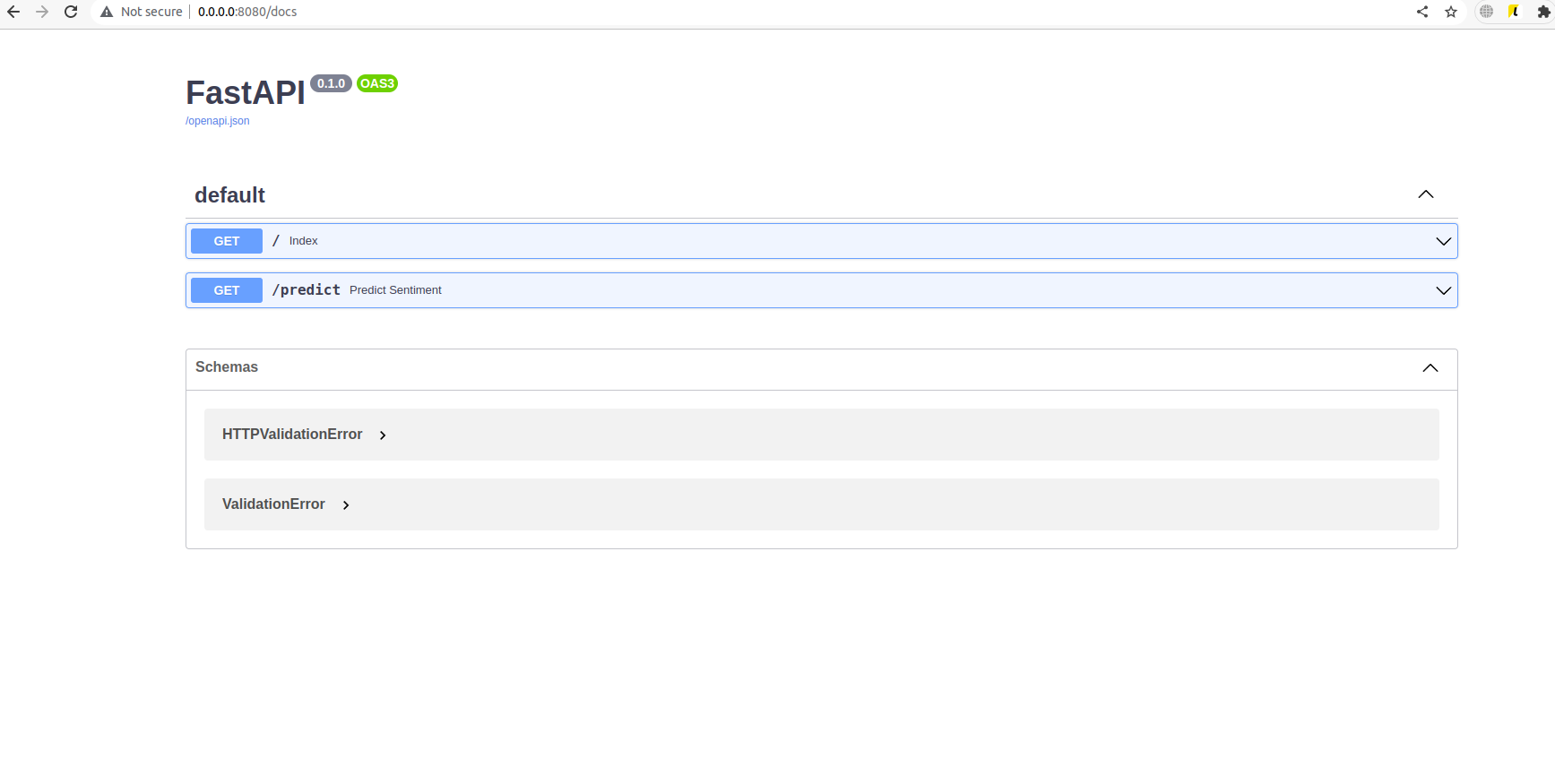
Здесь можно руками потыкать приложение. Нажав на «Try it out», можно вводить любые входные данные и проверять, как отрабатывает приложение:
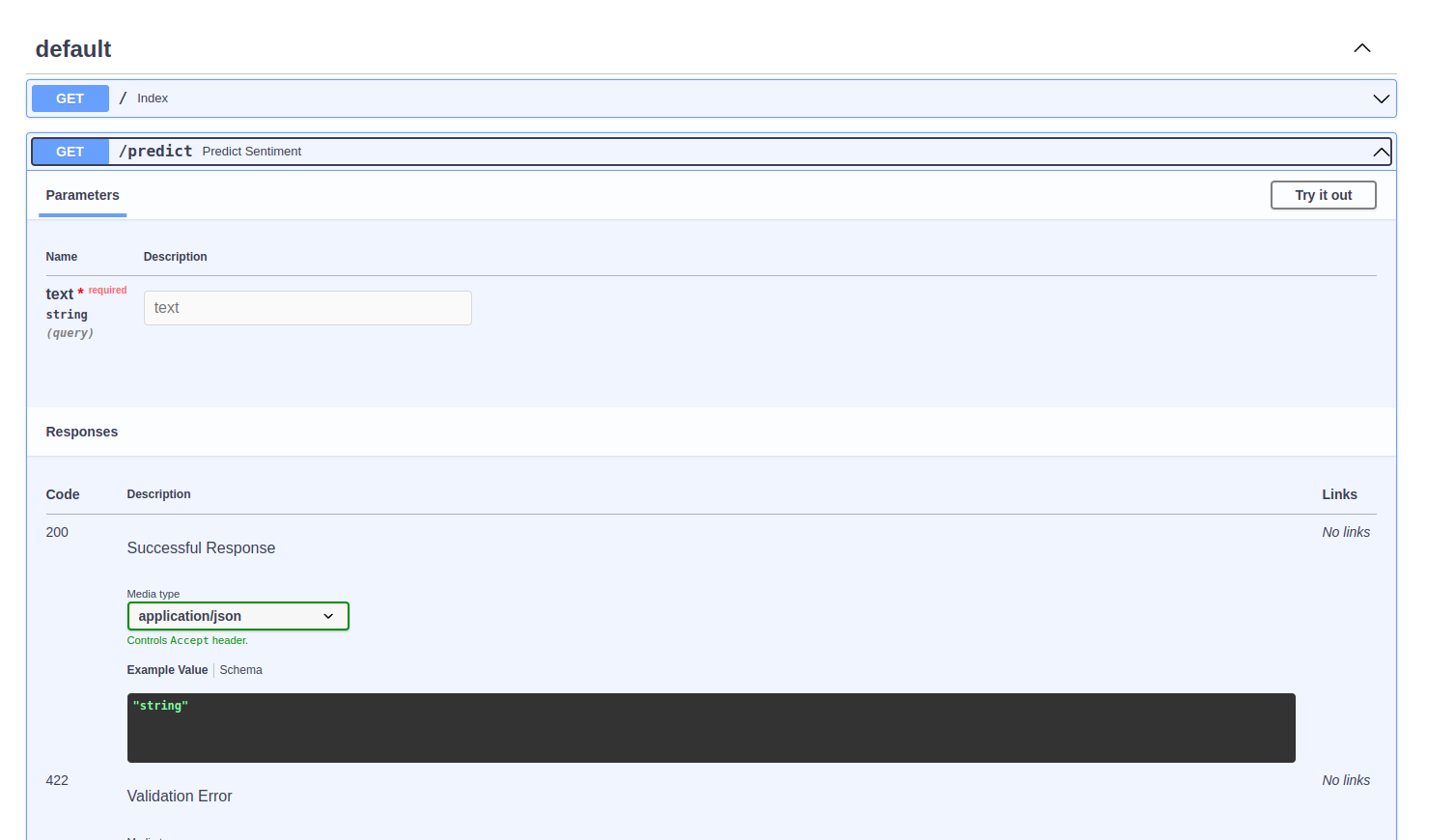
Использование виртуального окружения удобно для разработки и тестирования приложения на локальной машине. Далее обсудим, как запускать приложения в Docker-контейнере.
5. Запуск приложения в Docker-контейнере и тестирование приложения
Docker дает возможность упаковать приложение и запускать его на любой машине. Некоторые из его преимуществ:
-
Абстракция от хост-системы: Docker-контейнер позволяет упаковать приложение со всеми зависимостями и настройками в единый образ, который может быть запущен на любой машине, где установлен Docker.
-
Изоляция: запуск приложения в Docker-контейнере обеспечивает изоляцию от других процессов и приложений на хост-машине, что уменьшает риск взаимодействия с другими приложениями и позволяет управлять ресурсами контейнера.
-
Управление зависимостями: Docker-контейнер позволяет явно определить все зависимости и версии, необходимые для запуска приложения.
Для начального ознакомления с Docker подойдет их страница. Здесь же есть ссылки на инструкции, как установить Docker на разные системы.
Начнем с Dockerfile. Dockerfile — это текстовый файл, который содержит инструкции по созданию образа Docker. Он используется для автоматической сборки образа Docker, который включает все необходимые зависимости, настройки и код для запуска приложения в изолированном контейнере. Наш Dockerfile:
FROM python:3.11 COPY requirements.txt requirements-dev.txt setup.py /workdir/ COPY app/ /workdir/app/ COPY ml/ /workdir/ml/ WORKDIR /workdir RUN pip install -U -e . # Run the application CMD ["uvicorn", "app.app:app", "--host", "0.0.0.0", "--port", "80"]-
Первая инструкция указывает, что мы хотим использовать готовый образ Python версии 3.11 как основу для создания нашего образа.
-
Затем мы копируем весь рабочий код в рабочую директорию /workdir/ внутри контейнера.
-
Строка
WORKDIR /workdirустанавливает рабочую директорию для последующих команд в Dockerfile. Это означает, что все следующие команды в Dockerfile будут выполняться относительно этой директории. -
Далее собираем пакет, по аналогии с тем, как делали в виртуальном окружении.
-
В последней строке указывается команда, которая будет выполнена при запуске контейнера: запуск приложения с помощью
uvicornна порту 80.
Создаем новый Docker-образ с именем ml-app, используя Dockerfile, находящийся в текущей директории:
docker build -t ml-app .После того, как образ собрался, командой
docker run -p 80:80 ml-appзапускаем контейнер из образа ml-app и привязывает порт 80 внутри контейнера к порту 80 на хосте.
Контейнер будет запущен и доступен по адресу http://localhost:80 в браузере. Приложение также можно протестировать вручную, используя UI от FastAPI, как описано в предыдущем пункте.
Мы также можем написать несколько тестов для тестирования приложения, запущенного в контейнере. Будем использовать те же примеры, которые мы использовали для ML-кода. Только теперь будем отправлять HTTP-запросы в сервис, поднятый в контейнере, используя библиотеку requests.
import pytest import requests @pytest.mark.parametrize( "input_text, expected_label", [ ("очень плохо", "negative"), ("очень хорошо", "positive"), ("по-разному", "neutral"), ], ) def test_sentiment(input_text: str, expected_label: str): response = requests.get("http://0.0.0.0/predict/", params={"text": input_text}) assert response.json()["text"] == input_text assert response.json()["sentiment_label"] == expected_labelДля запуска тестов можно использовать созданное нами ранее виртуальное окружение env, так как там уже стоит библиотека pytest. Тогда в другом терминале, не останавливая запущенный контейнер, запустим тесты, предварительно активировав окружение env:
source env/bin/activate pytest tests/test_app.py deactivateЗаключение
-
В этом туториале мы создали веб-приложение для определения тональности текста с помощью FastAPI.
-
Мы также коснулись важных аспектов при разработке приложения: организация кода, тестирование, конфигурация, запуск приложения в Docker-контейнере.
-
Описанный подход может быть использован для любой задачи машинного обучения.
-
Код приложения доступен на GitHub и его можно использовать как отправную точку для создания собственного веб-сервиса.
Следующую статью планирую написать про запуск ML-пайплайна с помощью Airflow. А пока подписывайтесь на мой телеграм-канал. Там будут анонсы новых статей, а также советы для работы и более короткие мысли по DS/ML/AI.
ссылка на оригинал статьи https://habr.com/ru/articles/729380/
Добавить комментарий