В первой части было сделано несколько запусков обучения с различными количествами нейронов в скрытом слое и различными размерами батчей. Запускали 128-256-512-1024 нейронов в скрытом слое с размером батча 16-32-64-128, а также привели примеры уменьшения шага обучения и Dropout.

Во второй части рассмотрели вариативность и пришли к выводу, что при запуске с одними и теми же количествами нейронов скрытого слоя и размерами батчей точность может отличаться на несколько десятых процента, в среднем 0,3%, но при этом весь интервал точности в целом, за исключением редких выбросов, повышается по мере увеличения количества нейронов от 128 до 1024.

В этой части более подробно рассмотрим уменьшение шага обучения и применение Dropout.
Сравниваем уменьшение шага обучения
По предыдущим статьям видно, что увеличение количества нейронов скрытого слоя в 2 раза не приводит к существенным изменениям в точности, поэтому будем увеличивать сразу в 4 раза.
100 эпох.
Количество нейронов 128-512-2048-8192.
Батч 128.
Уменьшаем в 2 раза, если 3 эпохи нет улучшения
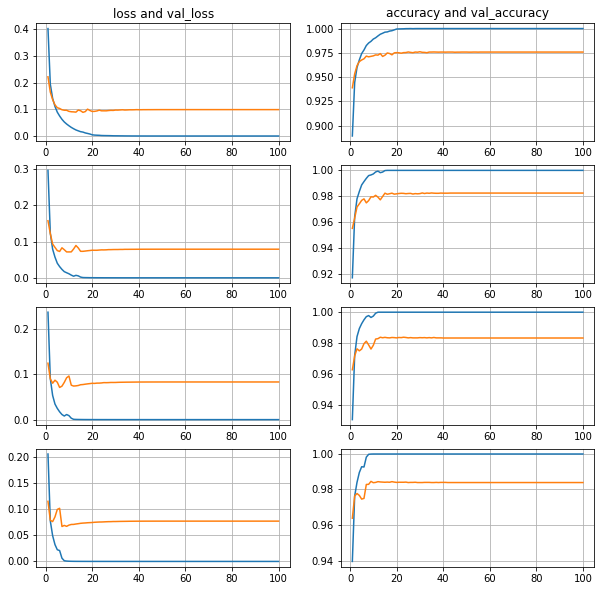


Видно, что чем больше нейронов в скрытом слое, тем ошибка валидационной выборки меньше, а точность валидационной выборки больше, и во всех случаях примерно к 40 эпохам все стабилизируется.
Уменьшаем в 2 раза, если 3 эпохи нет улучшения, с ограничением
Для сравнения, добавим ограничение по минимальному шагу обучения.
min_lr=0.0000001
Без ограничения шаг обучения уменьшился до lr: 4.6566e-13.



Глобально, результаты схожи.
Возможно, минимальный шаг взят слишком маленький, и при таких маленьких шагах ничего существенно не меняется.
Уменьшаем в 2 раза, если 10 эпох нет улучшения



Видно, что ошибку валидационной выборки сильно разносит по мере увеличения количества нейронов скрытого слоя. Примерно к 40 эпохам точность также стабилизируется, хотя ошибка продолжает расти. То есть явное переобучение, нужно выбирать момент для остановки или сохранять лучший результат.
Интересно, что при уменьшении шага через 3 эпохи, а не через 10, мы не видим такого разноса и роста ошибки, то есть к этому моменту шаг обучения уже стал настолько маленький, что движение происходило вокруг найденного к тому моменту локального минимума и уже никуда не скакало.
Конечные результаты схожи: чем больше нейронов в скрытом слое, тем точность валидационной выборки больше, и во всех случаях примерно к 40 эпохам стабилизируется.
100 эпох batch128 с уменьшением шага обучения,
точность на тестовой выборке:
128 нейронов: 0.9787
512 нейронов: 0.9822
2048 нейронов: 0.9849
8192 нейронов: 0.9869
Не видно существенного прироста точности при уменьшении шага обучения, точность попадает в тот же интервал, что и без уменьшения, с учетом вариативности, хотя следует также провести по несколько запусков с одними и теми же параметрами и сравнить вариативность.
Dropout
Помимо выбора момента остановки и сохранения лучшего результата, пробуем уменьшать переобучение применением Dropout.
100 эпох, 1024 нейрона, batch128, без уменьшения шага
Dropout 0.1-0.2-0.3-0.4-0.5



Видно, что ошибка катастрофически резко летит вверх, то есть пока переобучение не уменьшилось.
Dropout (0.1-0.2-0.3-0.4-0.5)
100 эпох, 1024 нейрона, batch128, без уменьшения шага обучения,
точность на тестовой выборке:
Dropout 0.1: 0.9816
Dropout 0.2: 0.9834
Dropout 0.3: 0.9840
Dropout 0.4: 0.9846
Dropout 0.5: 0.9854
100 эпох, 1024 нейрона, batch512, без уменьшения шага
Dropout 0.1-0.2-0.3-0.4-0.5
Увеличим размер батча со 128 до 512.



(на графике опечатка, корректный размер батча — 512)
Ожидаемо, увеличение размера батча со 128 до 512 улучшило стабильность, ошибка взлетает не так резко, хотя точность примерно в том же интервале.
100 эпох, 8192 нейрона, batch1024, без уменьшения шага
Dropout no-0.2-0.4-0.8
Попробуем «очень много» нейронов и «большой» батч и сделаем сравнительную разницу в Dropout более существенной (no-0.2-0.4-0.8).



(на графике опечатка, корректный размер батча — 1024)
В общем, ситуация похожа. Точность крутится на десятые доли процента выше 98%.
Dropout (no-0.2-0.4-0.8)
100 эпох, 8192 нейрона, batch1024, без уменьшения шага обучения,
точность на тестовой выборке:
Dropout no: 0.9840
Dropout 0.2: 0.9850
Dropout 0.4: 0.9834
Dropout 0.8: 0.9846
100 эпох, 4096 нейронов, batch512, с уменьшением шага обучения
(patience=3, factor=0.5, min_lr=0.0000001)
Dropout no-0.2-0.4-0.8
Для сравнения уменьшим в 2 раза и количество нейронов, и размер батча.



В данном варианте ошибка уже не задирается вверх, все быстро стабилизируется, хотя точность находится интервале 0.9835-0.9860.
Видно, что чем больше Dropout, тем чуть выше точность, и лучший результат при Dropout 0.8, то есть слишком много нейронов в скрытом слое.
Dropout (no-0.2-0.4-0.8)
100 эпох, 4096 нейрона, batch512, с уменьшением шага обучения,
точность на тестовой выборке:
Dropout no: 0.9835
Dropout 0.2: 0.9840
Dropout 0.4: 0.9842
Dropout 0.8: 0.9860
Не видно существенного прироста точности при применении Dropout, точность попадает в тот же интервал, что и без Dropout, с учетом вариативности, хотя следует также провести по несколько запусков с одними и теми же параметрами и сравнить вариативность.
Результат
Уменьшение шага обучения не дает в данном случае существенного прироста, хотя теперь видно, что из-за вариативности не следует делать выводы на основании единичных запусков — следует делать несколько запусков с одними и теми же параметрами и сравнивать интервалы в целом.
Хорошие сочетания количества нейронов и Dropout могут давать хорошие результаты, но сочетания нужно подбирать, и при этом также не делать выводы на основании единичных запусков — следует делать несколько запусков с одними и теми же параметрами и сравнивать интервалы в целом.
Хорошие сочетания количества нейронов и Dropout дают точность тестовой выборки в интервале 0.984-0.987, что в целом соответствует интервалу без уменьшения шага обучения и без Dropout.
Таким образом во всех случаях целесообразно делать несколько запусков с одними и теми же параметрами и отлавливать лучшие индивидуальные результаты, так итоговая точность будет выше, хотя и в рамках соответствующей вариативности.
Примечания
Если замечены грубые ошибки, которые могут существенно изменить результаты и выводы эксперимента, то прошу указать в комментариях. И, наоборот, если в целом рассуждения и ход эксперимента видятся корректными, то также прошу указать в комментариях.
ссылка на оригинал статьи https://habr.com/ru/articles/733082/
Добавить комментарий