
Перед вами обновлённая коллекция вредных советов для C++ программистов, которая превратилась в целую электронную книгу. Всего их 60, и каждый сопровождается пояснением, почему на самом деле ему не стоит следовать. Всё будет одновременно и в шутку, и серьёзно. Как бы глупо ни смотрелся вредный совет, он не выдуман, а подсмотрен в реальном мире программирования.
Я буду публиковать советы по 5 штук, чтобы не утомить вас, так как мини-книга содержит много интересных отсылок на другие статьи, видео и т. д. Однако, если вам не терпится, здесь вы можете сразу перейти к её полному варианту: «60 антипаттернов для С++ программиста«. В любом случае желаю приятного чтения.
Вредный совет N16. sizeof(int) == sizeof(void *)
Размер указателя и int — это всегда 4 байта. Смело используйте это число. Число 4 смотрится намного изящнее, чем корявое выражение с оператором sizeof.
Размер int может быть очень даже разным. На многих популярных платформах размер int действительно 4 байта. Но многие – это не означает все! Существуют системы с различными моделями данных, где int может содержать и 8 байт, и 2 байта и даже 1 байт!
Формально про размер int можно сказать только следующее:
1 == sizeof(char) <= sizeof(short) <= sizeof(int) <= sizeof(long) <= sizeof(long long)
Указатель точно так же легко может отличаться от размера типа int и значения 4. Например, на большинстве 64-битных систем размер указателя составляет 8 байт, а типа int — 4 байта.
С этим связан достаточный распространённый паттерн 64-битной ошибки. В старых 32-битных программах иногда указатель сохраняли в переменные таких типов, как int/unsigned. При портировании таких программ на 64-битные системы возникают ошибки, так как при записи значения указателя в 32-битную переменную происходит потеря старших бит. См. главу «Упаковка указателей» в курсе по разработке 64-битных приложений.
Дополнительные ссылки:
Вредный совет N17. Не проверяй, что вернула функция malloc
Нет смысла проверять, удалось ли выделить память. На современных компьютерах её много. А если не хватило, то и незачем дальше работать. Пусть программа упадёт. Все равно уже больше ничего сделать нельзя.
Упасть, если кончится память, допустимо игре. Это неприятно, но некритично. Ну если, конечно, в этот момент вы не участвуете в игровом чемпионате :).
Куда более грустно будет, если вы полдня делали проект в CAD-системе и приложение упало, когда для очередной операции потребовалось слишком много памяти. Одно дело – не дать выполнить какую-то операцию, и совсем другое – без предупреждения упасть. CAD и подобные системы должны продолжать работать, чтобы хотя бы дать возможность сохранить результат.
Несколько случаев, когда недопустимо писать код, просто падающий при нехватке памяти:
- Встраиваемые системы. Там может быть «некуда падать» :). Многие встроенные программы должны продолжить выполнение в любом случае. Даже если нормально функционировать невозможно, программа должна отработать какой-то особый сценарий. Например, выключить оборудование, а только потом остановиться. В общем случае говорить про встроенное программное обеспечение и давать какие-то рекомендации невозможно. Уж очень эти системы и их назначение разнообразны. Главное, что игнорировать нехватку памяти и падать – это не вариант для таких систем;
- Системы, где пользователь долго работает с каким-то проектом. Примеры: CAD-системы, базы данных, системы видеомонтажа. Падение в произвольный момент времени может привести к потере части работы или порче файлов проектов;
- Библиотеки. Неизвестно, как и в каком проекте будет использоваться библиотека. Поэтому в них просто недопустимо игнорировать ошибки выделения памяти. Задача библиотеки – вернуть статус ошибки или бросить исключение. А уже пользовательскому приложению решать, что делать с возникшей ситуацией;
- Прочее, про что я забыл или не подумал.
Данная тема во многом пересекается с моей статьёй «Четыре причины проверять, что вернула функция malloc«. Рекомендую. С ошибками выделения памяти не всё так просто и очевидно, как кажется на первый взгляд.
Вредный совет N18. Расширяй пространство std
Добавляйте разные вспомогательные функции и классы в пространство имён std. Ведь для вас эти функции и классы стандартные, а значит, им самое место в std.
Несмотря на то, что такая программа успешно компилируется и исполняется, модификация пространства имён std может привести к неопределённому поведению программы. То же самое касается и пространства posix.
Чтобы пояснить ситуацию, приведу часть документации PVS-Studio к диагностике V1061, которая предназначена выявлять как раз такие недопустимые расширения пространства имён.
Содержимое пространства имен std определяется исключительно комитетом стандартизации. Стандарт запрещает добавлять в него:
- декларации переменных;
- декларации функций;
- декларации классов/структур/объединений;
- декларации перечислений;
- декларации шаблонов функций, классов и переменных (C++14).
Стандарт разрешает добавлять следующие специализации шаблонов, определённых в пространстве имен std, если они зависят хотя бы от одного определённого в программе типа (program-defined type):
- полная или частичная специализация шаблона класса;
- полная специализация шаблона функции (до C++20);
- полная или частичная специализация шаблона переменной, не лежащей в заголовочном файле <type_traits> (до C++20).
Однако специализации шаблонов, лежащих внутри классов или шаблонов классов, запрещены.
Наиболее частым вариантом, когда пользователь расширяет пространство имен std, является добавление своей перегрузки функции std::swap и полной/частичной специализации шаблона класса std::hash.
Рассмотрим неправильный фрагмент кода с добавлением перегрузки std::swap:
template <typename T> class MyTemplateClass { .... }; class MyClass { .... }; namespace std { template <typename T> void swap(MyTemplateClass<T> &a, MyTemplateClass<T> &b) noexcept // UB { .... } template <> void swap(MyClass &a, MyClass &b) noexcept // UB since C++20 { .... }; }
Первый шаблон функции не является специализацией std::swap, и такая декларация ведёт к неопределённому поведению. Второй шаблон функции является специализацией, и до C++20 поведение программы определено. Однако в данном случае можно поступить иначе: можно вынести обе функции из пространства имен std и поместить их в то пространство имен, где определены классы:
template <typename T> class MyTemplateClass { .... }; class MyClass { .... }; template <typename T> void swap(MyTemplateClass<T> &a, MyTemplateClass<T> &b) noexcept { .... } void swap(MyClass &a, MyClass &b) noexcept { .... };
Теперь, когда необходимо написать шаблон функции, который применяет функцию swap для двух объектов типа T, можно написать следующий код:
template <typename T> void MyFunction(T& obj1, T& obj2) { using std::swap; // make std::swap visible for overload resolution .... swap(obj1, obj2); // best match of 'swap' for objects of type T .... }
Компилятор выберет нужную перегрузку функции на основе поиска с учётом аргументов (argument-dependent lookup, ADL): пользовательские функции swap для класса MyClass и для шаблона класса MyTemplateClass. И стандартную версию std::swap для остальных типов.
Разберём следующий пример со специализацией шаблона класса std::hash:
namespace Foo { class Bar { .... }; } namespace std { template <> struct hash<Foo::Bar> { size_t operator()(const Foo::Bar &) const noexcept; }; }
С точки зрения стандарта этот код является валидным, и анализатор в этой ситуации не выдаёт предупреждение. Однако, начиная с C++11, можно и в этом случае поступить иначе, написав специализацию шаблона класса за пределами пространства имен std:
template <> struct std::hash<Foo::Bar> { size_t operator()(const Foo::Bar &) const noexcept; };
В отличие от пространства имен std, стандарт C++ запрещает абсолютно любую модификацию пространства имён posix.
Дополнительная информация:
- Стандарт C++17 (working draft N4659), пункт 20.5.4.2.1
- Стандарт C++20 (working draft N4860), пункт 16.5.4.2.1
Вредный совет N19. Старая школа
Коллеги должны знать о вашем богатом опыте с языком C. Не стесняйтесь демонстрировать им в вашем C++ проекте свои умелые навыки ручного управления памятью и longjmp.
Другая вариация этого вредного совета: умные указатели и прочее RAII от лукавого, всеми ресурсами надо управлять вручную, это делает код простым и понятным.
Нет основания отказываться от умных указателей и городить сложные конструкции при работе с памятью. Умные указатели в С++ не требуют дополнительного процессорного времени, это не сборка мусора. При этом код с использованием умных указателей становится короче и проще, что дополнительно снижает вероятность допустить ошибку.
Давайте рассмотрим, почему ручное управление памятью — это муторно и ненадёжно. Начнём с простейшего кода на C, где выделяется и освобождается память.
Примечание. Я рассматриваю в примерах выделение и освобождение памяти. На самом деле, это более широкая тема ручного управления ресурсами. Вместо malloc вполне можно подставить, например, fopen.
int Foo() { float *buf = (float *)malloc(ARRAY_SIZE * sizeof(float)); if (buf == NULL) return STATUS_ERROR_ALLOCATE; int status = Go(buf); free(buf); return status; }
Этот код прост и понятен. Функция выделят память для каких-то нужд, использует её и затем освобождает. Дополнительно приходится проверять, смогла ли функция malloc выделить память. Почему эта проверка обязательно необходима мы разбирали в главе N17.
Теперь представим, что нам требуется выполнить операции с двумя разными буферами. Код сразу начинает пухнуть, так как при ошибки очередном выделении памяти, нужно позаботиться о предыдущем буфере. Плюс теперь нужно учитывать, что вернула функция Go_1.
int Foo() { float *buf_1 = (float *)malloc(ARRAY_SIZE_1 * sizeof(float)); if (buf_1 == NULL) return STATUS_ERROR_ALLOCATE; int status = Go_1(buf_1); if (status != STATUS_OK) { free(buf_1); return status; } float *buf_2 = (float *)malloc(ARRAY_SIZE_2 * sizeof(float)); if (buf_2 == NULL) { free(buf_1); return STATUS_ERROR_ALLOCATE; } status = Go_2(buf_1, buf_2); free(buf_1); free(buf_2); return status; }
Дальше — хуже. Размер кода растёт нелинейно. При трёх буферах:
int Foo() { float *buf_1 = (float *)malloc(ARRAY_SIZE_1 * sizeof(float)); if (buf_1 == NULL) return STATUS_ERROR_ALLOCATE; int status = Go_1(buf_1); if (status != STATUS_OK) { free(buf_1); return status; } float *buf_2 = (float *)malloc(ARRAY_SIZE_2 * sizeof(float)); if (buf_2 == NULL) { free(buf_1); return STATUS_ERROR_ALLOCATE; } status = Go_2(buf_1, buf_2); if (status != STATUS_OK) { free(buf_1); free(buf_2); return status; } float *buf_3 = (float *)malloc(ARRAY_SIZE_3 * sizeof(float)); if (buf_3 == NULL) { free(buf_1); free(buf_2); return STATUS_ERROR_ALLOCATE; } status = Go_3(buf_1, buf_2, buf_3); free(buf_1); free(buf_2); free(buf_3); return status; }
Что интересно, сложность кода по-прежнему низкая. Его легко писать и читать. Но вместе с тем чувствуется, что это какой-то неправильный путь. Больше половины кода функции не делает что-то полезное, а занимается проверкой статусов и выделением/освобождением памяти. Вот этим и плохо ручное управление памятью. Много нужного, но не относящегося к делу кода.
И хотя код, как я сказал, несложен, с ростом его размера всё проще допустить ошибку. Например, можно при досрочном выходе из функции забыть освободить какой-то указатель и получить утечку памяти. И такое мы действительно встречаем в коде различных проектов, когда проверяем их с помощью PVS-Studio. Вот, например, фрагмент кода из проекта PMDK:
static enum pocli_ret pocli_args_obj_root(struct pocli_ctx *ctx, char *in, PMEMoid **oidp) { char *input = strdup(in); if (!input) return POCLI_ERR_MALLOC; if (!oidp) return POCLI_ERR_PARS; .... }
Функция strdup создаёт копию строки в буфере, который затем должен где-то быть освобождён с помощью функции free. Здесь же в случае, если аргумент oidp является нулевым указателем, произойдёт утечка памяти. Корректный код должен быть таким:
char *input = strdup(in); if (!input) return POCLI_ERR_MALLOC; if (!oidp) { free(input); return POCLI_ERR_PARS; }
Или нужно перенести проверку аргумента в начало функции:
if (!oidp) return POCLI_ERR_PARS; char *input = strdup(in); if (!input) return POCLI_ERR_MALLOC;
В любом случае перед нами классическая ошибка в коде с ручным управлением памяти.

Вернёмся к нашему синтетическому коду с тремя буферами. Можно как-то сделать проще? Да, для этого используется паттерн с одной точкой выхода и операторами goto.
int Foo() { float *buf_1 = NULL; float *buf_2 = NULL; float *buf_3 = NULL; int status; buf_1 = (float *)malloc(ARRAY_SIZE_1 * sizeof(float)); if (buf_1 == NULL) { status = STATUS_ERROR_ALLOCATE; goto end; } status = Go_1(buf_1); if (status != STATUS_OK) goto end; buf_2 = (float *)malloc(ARRAY_SIZE_2 * sizeof(float)); if (buf_2 == NULL) { status = STATUS_ERROR_ALLOCATE; goto end; } status = Go_2(buf_1, buf_2); if (status != STATUS_OK) { status = STATUS_ERROR_ALLOCATE; goto end; } buf_3 = (float *)malloc(ARRAY_SIZE_3 * sizeof(float)); if (buf_3 == NULL) { status = STATUS_ERROR_ALLOCATE; goto end; } status = Go_3(buf_1, buf_2, buf_3); end: free(buf_1); free(buf_2); free(buf_3); return status; }
Это лучше, и так часто пишут программисты на C. Я не могу назвать такой код хорошим и красивым, но что делать. Ручное управление ресурсами в любом случае страшненькое…
Кстати, некоторые компиляторы поддерживают специальное расширение языка C, которое помогает упростить жизнь. Можно использовать конструкции вида:
void free_int(int **i) { free(*i); } int main(void) { __attribute__((cleanup (free_int))) int *a = malloc(sizeof *a); *a = 42; } // No memory leak, free_int is called when a goes out of scope
Подробнее про эту магию можно почитать здесь: RAII in C: cleanup gcc compiler extension.
Вернёмся к вредному совету. Беда в том, что некоторые программисты продолжают использовать этот стиль ручного управления ресурсами в С++ коде, хотя в этом нет никакого смысла! Не делайте так. С++ позволяет сделать код простым и коротким.
Можно использовать контейнеры, такие как std::vector. Но, даже если нам нужен именно массив байт, выделенный с помощью оператора new [], всё равно код можно сделать на порядок лучше.
int Foo() { std::unique_ptr<float[]> buf_1 (new float[ARRAY_SIZE_1]); if (int status = Go_1(buf_1); status != STATUS_OK) return status; std::unique_ptr<float[]> buf_2(new float[ARRAY_SIZE_2]); if (int status = Go_2(buf_1, buf_2); status != STATUS_OK) return status; std::unique_ptr<float[]> buf_3(new float[ARRAY_SIZE_3]); reutrn Go_3(buf_1, buf_2, buf_3); }
Красота! Проверять результат вызова оператора new [] не нужно, так как в случае ошибки создания буфера будет сгенерировано исключение. Буферы сами освобождаются, если возникают исключения или при штатном завершении функции.
Так какой же смысл писать по старинке в С++? Никакого. Тогда почему можно встретить такой код? Я думаю, это может происходить вследствие следующих причин.
Первый вариант. Человек делает это просто по привычке. Он не хочет изучать что-то новое, переучиваться. Фактически он пишет код на C с использованием каких-то возможностей C++. Грустный вариант, и непонятно, что тут посоветовать.
Второй вариант. Перед вами С++ код, который когда-то был кодом на C. Его немного изменили, но не переписали и не отрефакторили. Т.е. просто заменили malloc на new, а free на delete. Такой код можно легко распознать по двум артефактам.
Во-первых, в нём присутствуют вот такие проверки-атавизмы:
in_audio_ = new int16_t[AUDIO_BUFFER_SIZE_W16]; if (in_audio_ == NULL) { return -1; }
Нет смысла проверять указатель на равенство NULL, так как в случае ошибки выделения памяти будет сгенерировано исключение типа std::bad_alloc. Очень, очень частный атавизм. Конечно, существует new(std::nothrow), но это не наш случай.
Во-вторых, там часто есть ошибка, которая заключается в том, что память выделяется с помощью оператора new [], а освобождается с помощью delete. Хотя правильно использовать delete []. См. «Почему в С++ массивы нужно удалять через delete[]«. Пример:
char *poke_data = new char [length + 2*sizeof(int)]; .... delete poke_data;
Третий вариант. Боязнь дополнительных накладных расходов. Необоснованный страх. Да, у умных указателей иногда могут быть незначительные накладные расходы по сравнению с простыми указателями. Однако следует принять в расчёт:
- Возможные накладные расходы от умных указателей пренебрежимо малы по сравнению с относительно медленными операциями выделения и освобождения памяти. Если нужна максимальная скорость, то стоит думать, как уменьшить количество операций выделения/освобождения памяти, а не над тем: использовать умный указатель или контролировать указатели вручную. Ещё вариант — написать собственный аллокатор;
- Простота, надёжность и безопасность кода, использующего умные указатели, на мой взгляд, однозначно перевешивает дополнительные накладные расходы (которых, кстати, может и не быть).
Дополнительные ссылки:
- Memory and Performance Overhead of Smart Pointers.
- How much is the overhead of smart pointers compared to normal pointers in C++?
Четвёртый вариант. Программисты просто не осведомлены о том, как можно использовать тот же std::unique_ptr. Условно, они рассуждают так:
Хорошо, есть std::unique_ptr. Он умеет контролировать указатель на объект. Но мне-то ещё нужно работать с массивами объектов. А ещё есть дескрипторы файлов. Местами я вообще вынужден по-прежнему использовать malloc/realloc. Для всего этого unique_ptr не подходит. Так что проще для единообразия продолжать везде управлять ресурсами вручную.
Всё, что описано, очень даже можно контролировать с помощью std::unique_ptr.
// Работа с массивами: std::unique_ptr<T[]> ptr(new T[count]); // Работа с файлами: std::unique_ptr<FILE, int(*)(FILE*)> f(fopen("a.txt", "r"), &fclose); // Работа с malloc: struct free_delete { void operator()(void* x) { free(x); } }; .... std::unique_ptr<int, free_delete> up((int*)malloc(sizeof(int)));
На этом всё. Надеюсь, если у вас оставались сомнения в умных указателях, я их развеял.
P.S. Я ничего не написал про longjmp. И не вижу смысла. В C++ для тех же целей следует использовать исключения.
Вредный совет N20. Компактный код
Используйте как можно меньше фигурных скобок и переносов строк, старайтесь писать условные конструкции в одну строку. Так код будет быстрее компилироваться и занимать меньше места.
Что код будет короче – это бесспорно. Бесспорно и то, что в нём будет больше ошибок.
«Сжатый код» сложнее читать, а значит, с большей вероятностью опечатки не будут замечены ни автором кода, ни коллегами при обзоре кода. Хотите какой-нибудь proof? Легко!
Однажды пользователь написал нам о том, что анализатор PVS-Studio выдаёт странные ложные срабатывания на условие. И прикрепил вот такую картинку:
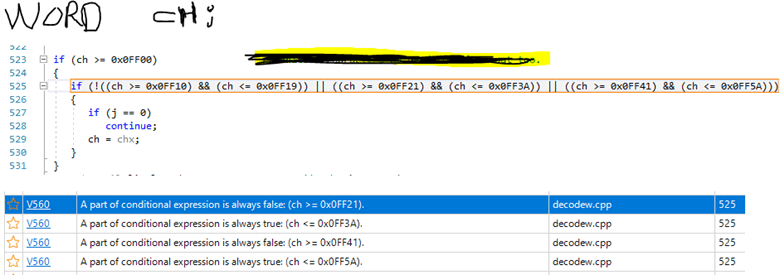
Видите ошибку в коде? Скорее всего, нет. А почему? А потому, что перед нами большое сложное выражение, написанное в одну строчку. Человеку сложно прочитать и осознать этот код. Скорее всего, вы и не стали пробовать разобраться, а сразу продолжили читать статью :).
А вот анализатор не поленился и совершенно справедливо указывает на аномалию: часть подвыражений всегда истинны или ложны. Давайте проведём рефакторинг кода:
if (!((ch >= 0x0FF10) && (ch <= 0x0FF19)) || ((ch >= 0x0FF21) && (ch <= 0x0FF3A)) || ((ch >= 0x0FF41) && (ch <= 0x0FF5A)))
Теперь намного легче заметить, что логический оператор «не» (!) применяется только к первому подвыражению. В общем, здесь не хватает ещё одних скобочек. Эта ошибка, а также то, почему анализатор выдал предупреждения, разбирается в статье «Как PVS-Studio оказался внимательнее, чем три с половиной программиста«.
В наших статьях мы рекомендуем форматировать сложный код «таблицей». Как раз пример такого «табличного» форматирования был показан выше. Такое оформление кода не гарантирует отсутствие опечаток, но позволяет их легче и быстрее замечать.
Давайте разберём эту тему подробнее на другом примере. Возьмём фрагмент кода из проекта ReactOS, в котором я нашёл ошибку благодаря предупреждению PVS-Studio: V560 A part of conditional expression is always true: 10035L.
void adns__querysend_tcp(adns_query qu, struct timeval now) { ... if (!(errno == EAGAIN || EWOULDBLOCK || errno == EINTR || errno == ENOSPC || errno == ENOBUFS || errno == ENOMEM)) { ... }
Здесь приведён маленький фрагмент кода — найти в нём ошибку несложно, но в реальном коде заметить ошибку весьма проблематично. Взгляд просто пропускает блок однотипных сравнений и идёт дальше.
Причина, почему мы пропускаем такие ошибки, в том, что условия плохо отформатированы и не хочется внимательно их читать, это требует усилий. Мы надеемся, что раз проверки однотипные, то всё хорошо, и автор кода не допустил ошибок в условии.
Одним из способов борьбы с опечатками является «табличное» оформление кода.
Для читателей, поленившихся найти ошибку, скажу, что в одном месте пропущено «errno ==». В результате условие всегда истинно, так как константа EWOULDBLOCK равна 10035. Корректный код:
if (!(errno == EAGAIN || errno == EWOULDBLOCK || errno == EINTR || errno == ENOSPC || errno == ENOBUFS || errno == ENOMEM)) {
Теперь рассмотрим, как лучше провести рефакторинг этого фрагмента. Для начала я приведу код, оформленный самым простым «табличным» способом. Мне он не нравится.
if (!(errno == EAGAIN || EWOULDBLOCK || errno == EINTR || errno == ENOSPC || errno == ENOBUFS || errno == ENOMEM)) {
Стало лучше, но ненамного. Такой стиль оформления мне не нравится по двум причинам:
- Ошибка по-прежнему не очень заметна;
- Приходится вставлять большое количество пробелов для выравнивания.
Поэтому надо сделать два усовершенствования в оформлении кода. Первое — не больше одного сравнения на строку, тогда ошибку легко заметить. Смотрите, ошибка стала больше бросаться в глаза:
a == 1 && b == 2 && c && d == 3 &&
Второе — рационально писать операторы &&, || и т.д., не справа, а слева.
Обратите внимание, как много работы для написания пробелов:
x == a && y == bbbbb && z == cccccccccc &&
А вот так работы намного меньше:
x == a && y == bbbbb && z == cccccccccc
Выглядит код немного необычно, но к этому быстро привыкаешь.
Объединим это всё вместе и напишем в новом стиле код, приведённый в начале:
if (!( errno == EAGAIN || EWOULDBLOCK || errno == EINTR || errno == ENOSPC || errno == ENOBUFS || errno == ENOMEM)) {
Да, код стал занимать больше строк кода, но зато ошибка стала намного заметнее.
Согласен, смотрится код непривычно. Тем не менее, я рекомендую именно этот подход. Я пользуюсь им много лет и весьма доволен, поэтому с уверенностью рекомендую его всем читателям.
То, что код стал длиннее, я вообще не считаю проблемой. Я даже написал бы как-то так:
const bool error = errno == EAGAIN || errno == EWOULDBLOCK || errno == EINTR || errno == ENOSPC || errno == ENOBUFS || errno == ENOMEM; if (!error) {
Кто-то ворчит, что это длинно и загромождает код? Согласен. Так давайте вынесем это в функцию!
static bool IsInterestingError(int errno) { return errno == EAGAIN || errno == EWOULDBLOCK || errno == EINTR || errno == ENOSPC || errno == ENOBUFS || errno == ENOMEM; } .... if (!IsInterestingError(errno)) {
Может показаться, что я сгущаю краски и что я слишком перфекционист, однако ошибки в сложных выражениях очень распространены. Я бы не вспомнил о них, если бы они мне постоянно не попадались: эти ошибки повсюду и плохо заметны.
Вот ещё один пример из проекта WinDjView:
inline bool IsValidChar(int c) { return c == 0x9 || 0xA || c == 0xD || c >= 0x20 && c <= 0xD7FF || c >= 0xE000 && c <= 0xFFFD || c >= 0x10000 && c <= 0x10FFFF; }
В функции всего несколько строк, и всё равно в неё закралась ошибка. Функция всегда возвращает true. Вся беда в том, что она плохо оформлена, и многие годы её ленятся читать и не замечают там ошибку.
Давайте отрефакторим код в «табличном» стиле, и я бы еще скобочки добавил:
inline bool IsValidChar(int c) { return c == 0x9 || 0xA || c == 0xD || (c >= 0x20 && c <= 0xD7FF) || (c >= 0xE000 && c <= 0xFFFD) || (c >= 0x10000 && c <= 0x10FFFF); }
Необязательно форматировать код именно так, как я предлагаю. Смысл этой заметки — привлечь ваше внимание к опечаткам в «хаотичном коде». Придавая коду «табличный» вид, можно избежать множества глупых опечаток, и это замечательно. Надеюсь, кому-то эта заметка принесёт пользу.
Ложка дёгтя. Я честный программист, и поэтому должен упомянуть, что иногда форматирование «таблицей» может пойти во вред. Вот один из примеров:
inline void elxLuminocity(const PixelRGBi& iPixel, LuminanceCell< PixelRGBi >& oCell) { oCell._luminance = 2220*iPixel._red + 7067*iPixel._blue + 0713*iPixel._green; oCell._pixel = iPixel; }
Это проект eLynx SDK. Программист хотел выровнять код, поэтому перед 713 дописал 0. К сожалению, программист не учёл, что 0 в начале числа означает, что число будет представлено в восьмеричном формате.
Массив строк. Надеюсь, концепция форматирования «таблицей» понятна, но давайте закрепим тему. С этой целью рассмотрим пример, которым я продемонстрирую, что табличное форматирование можно применять не только к условиям, а к совершенно разным конструкциям языка.
Фрагмент взят из проекта Asterisk. Ошибка выявляется PVS-Studio диагностикой: V653 A suspicious string consisting of two parts is used for array initialization. It is possible that a comma is missing. Consider inspecting this literal: «KW_INCLUDES» «KW_JUMP».
static char *token_equivs1[] = { .... "KW_IF", "KW_IGNOREPAT", "KW_INCLUDES" "KW_JUMP", "KW_MACRO", "KW_PATTERN", .... };
Опечатка — забыта одна запятая. В результате две различные по смыслу строки соединяются в одну, т. е. на самом деле здесь написано:
.... "KW_INCLUDESKW_JUMP", ....
Ошибку можно было бы избежать, выравнивая код таблицей. Тогда, если запятая будет пропущена, это будет легко заметить.
static char *token_equivs1[] = { .... "KW_IF" , "KW_IGNOREPAT" , "KW_INCLUDES" , "KW_JUMP" , "KW_MACRO" , "KW_PATTERN" , .... };
Как и в прошлый раз, обращаю внимание, что если мы ставим разделитель справа (в данном случае это запятая), то приходится добавлять массу пробелов, что неудобно. Особенно неудобно, если появляется новая длинная строка/выражение: придётся переформатировать всю таблицу.
Поэтому я вновь рекомендую оформлять код так:
static char *token_equivs1[] = { .... , "KW_IF" , "KW_IGNOREPAT" , "KW_INCLUDES" , "KW_JUMP" , "KW_MACRO" , "KW_PATTERN" .... };
Теперь очень легко заметить недостающую запятую, и нет необходимости писать много пробелов — код красивый и понятный. Быть может, такое оформление непривычно, но к нему быстро привыкаешь, попробуйте.
И под конец короткий лозунг. Как правило, красивый код — это правильный код.
Об этой мини-книге
Автор: Карпов Андрей Николаевич. E-Mail: karpov [@] viva64.com.
Более 15 лет занимается темой статического анализа кода и качества программного обеспечения. Автор большого количества статей, посвящённых написанию качественного кода на языке C++. С 2011 по 2021 год удостаивался награды Microsoft MVP в номинации Developer Technologies. Один из основателей проекта PVS-Studio. Долгое время являлся CTO компании и занимался разработкой С++ ядра анализатора. Основная деятельность на данный момент — управление командами, обучение сотрудников и DevRel активность.
Ссылки на полный текст:
Подписывайтесь на ежемесячную рассылку, чтобы не пропустить другие публикации автора и его коллег.
ссылка на оригинал статьи https://habr.com/ru/articles/741228/
Добавить комментарий