Сразу извиняюсь за свою манеру повествования, ибо она похоже больше на поток сознания, но главное уловить суть, которую я хочу донести.
Я хочу подготовить небольшой цикл публикаций про работу с данными:
-
Общий обзор FOR-архитектуры (эта статья)
-
Взгляд на валидацию данных и частные применения
-
Разбор FOR со стороны поставщика данных (ключевая часть, нужная для понимания всей картины)
-
Гомогенность данных в больших распределенных системах (идея, выросшая из валидации и использующая те же механизмы)
Начнем с определения кому надо
Если рассматривать разработку веб приложений, то я бы выделил 2 вектора:
Первый — будем называть студийная, когда глубина проработки ниже и обусловлена срочностью бизнеса, ему «надо продавать сегодня».
Второй — enterprise, это когда есть 1 продукт (или больше, что не важно в данном контексте) и он должен быть сделан на уровне, когда поддержка должна быть простой и легкой десятилетиями.
Если мы рассматриваем студийный подход — то имеем более низкую вовлеченность в предметную область (domain driven) и подходы ограничены более простым и менее проработанным ТЗ (как правило, судя по моему опыту, не пытаюсь сказать, что в студиях пишут хуже, просто там как правила оплата не по часам, а по проектно, а с большими студиями я не сталкивался) а вот в энтерпрайзе уже надо сделать более качественно, потому что нам (писателям кода) и надо будет поддерживать и расширять код под постоянно изменчивый бизнес (и лишь такой бизнес хорошо живет, а не тот, кто может позволить быть в статике).
Данный параграф обозначил аудиторию моего подхода и моих идей, я полагаю не стоит в «быстрой» разработке использовать то, что я предлагаю, потому что это будет сильно дольше и, соответственно, дороже.
Начнем с ситуации. Рассмотрим 2 кейса.
Первый:
-
У вас react/vue/что-то иное
-
Есть некий компонент (форма создания какой-то элемента)
-
Поля формы сильно отличаются от контекста и типа этого элемента (к примеру, товары в магазине)
-
Программист в начале имел всего 3 типа и всё было хорошо. Он за каждым ходит на бек, прямо внутри всего чудного компонента
Где-то в дебрях:
let form_data = axios.get(element_type);По моему видению, это всегда должно быть иначе
let form_data = FormProvider.get_by_type(element_type);Плюсы очевидны по мне.
-
Низкая связанность
-
Не зависимость от поставщика
-
Легкий рефакторинг (данных)
-
Мы можем добавить ttl-кеш в наш провайдер (логи, единая точка валидации отправляемых и получаемых данных по роута и многое другое), формы редко меняются. В таком случае форма будет уже мгновенно вызываться
Концепция работы Data Providers на фронте:
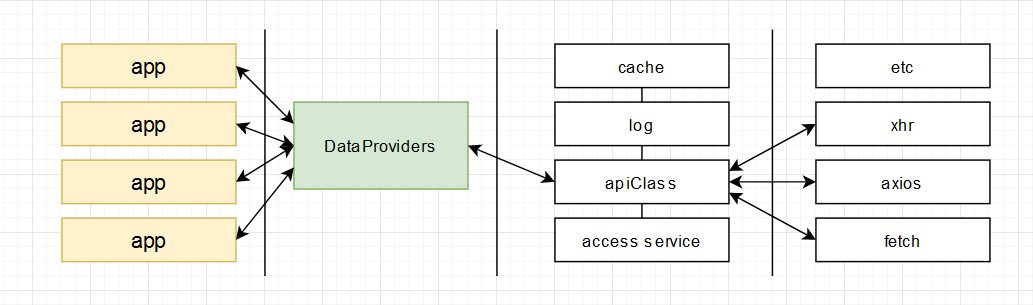
На бекенде, это выглядит примерно также:

Итого мы имеем определение Data Provider — это интерфейс работы с данными внутри вашего приложения
И второе нужное нам определение FOR — это аббревиатура filters+options+response
Моё видение реализации
Data Provider имеет 2 механизма работы:
-
DataProvider::search($filters, $options, $response) статичный метод на входе, который покрывает 80% задач. Если всё в вашей системе представлено в виде элементов — то данный метод даст высший уровень гибкости вашему API, потому что позволит находить что угодно в рамках свои полномочий.
-
Также мы тут добавляем некий массив примитивных операций со статичным интерфейсом, когда фильтры избыточны, их может быть достаточно много и они также могут скрывать внутри себя фильтры, обеспечивая единообразие и одновременно упрощенный синтаксис.
Примеры:
-
CompanyProvider::get_by_id()
-
JobProvider::get_actual()
Конкретика
Архитектура состоит из 2 частей: пользователь и поставщик.
Поставщика я хочу детальнее описать позже, пока приведу пример реализации, который более нагляден
(код размещен в папке: DataProvider ElementSearch, эта часть будет подробно разобрана в другой статье) https://gitlab.com/dev_docs/software_architecture/for-architecture/-/blob/main/code_examples/DataProvider%20ElementSearch%20%5Bprototype%5D/BaseFilters.php
Концепция его работы:
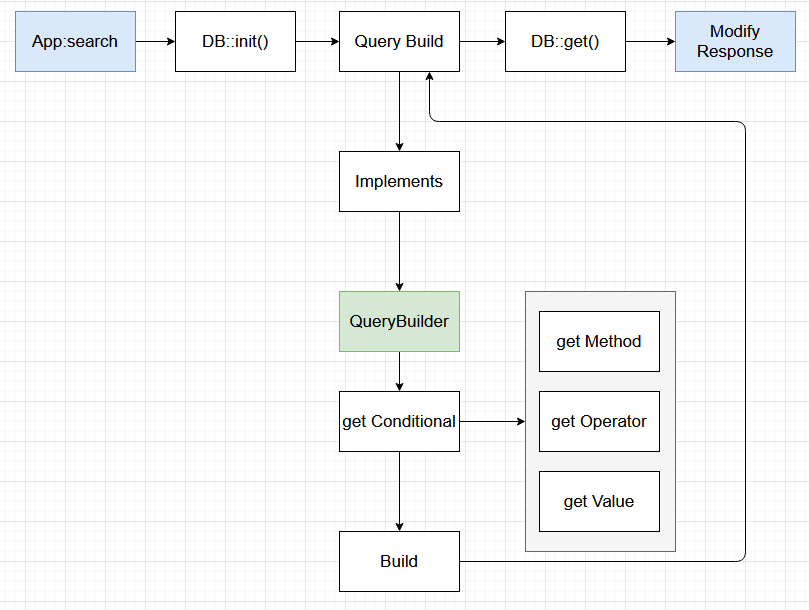
:
Теперь взгляд со стороны использования:
-
Filters — определяет условия поиска (что и где ищем)
-
Options — определяет область поиска (все что не filter и не response)
-
Response — определяет модификацию / формат ответа (как обработаем ответ)
Примеры запроса будут размещены тут: https://gitlab.com/dev_docs/software_architecture/for-architecture/-/tree/main/code_examples/DataProvider%20ElementSearch%20%5Bprototype%5D/Examples
Реализация внутри системы (back / php)
(код размещен в папке: DataProvider ElementSearch, эта часть будет подробно разобрана в другой статье) https://gitlab.com/dev_docs/software_architecture/for-architecture/-/tree/main/code_examples/DataProvider%20ElementSearch%20%5Bprototype%5D
Фильтр — массив условий, фильтр состоит из:
-
object — объект поиска, состоит из:
-
element_type_id (element_type) — сама сущность (user, sku, company, news, properties …)
-
element_id — подсущность. к примеру, id свойства или поле, к примеру: user_name или если props, то 69
-
operator_id (operator) — оператор поиска (у меня они все зарегистрированы и есть в виде констант, это лучше, чем их строковое представление) https://gitlab.com/dev_docs/software_architecture/for-architecture/-/blob/main/code_examples/DataProvider%20ElementSearch%20%5Bprototype%5D/Operators.php
-
value — значение поиска (может быть любой тип, все зависит от контекста)
Примеры фильтров:
DataProvider.search( { filters : [ { object : { element_type_id : _CONSTANTS.ELEMENT_TYPES.SOME_ELEMENT_TYPE_ID, element_id : 'some_id' }, operator_id : _CONSTANTS.OPERATORS.EQUAL, value : options.element_id } ] } )PaymentProvider.search( { filters : [ { object : { element_type_id : _CONSTANTS.ELEMENT_TYPES.PAYMENT, element_id : 'payment_id' }, operator_id : _CONSTANTS.OPERATORS.EQUAL, value : this.element_id } ], response : { structure_mode : 'listing' } })И немного посложнее
{ filters : [ { object : { element_type_id : _CONSTANTS.ELEMENT_TYPES.CATEGORY, element_id : null }, operator_id : _CONSTANTS.OPERATORS.EQUAL, value : 27 }, { object : { element_type_id : _CONSTANTS.ELEMENT_TYPES.ITEM_STATUS, element_id : null }, operator_id : _CONSTANTS.OPERATORS.IN, value : [103, 101] } ], response : { structure_mode : 'listing', add : { relations : [ { relation_id : 160, // связь - подчинённые relation_field : 'master', data_fields : 'IDS' }, { relation_id : 125, // связь с должностью relation_field : 'slave', data_fields : { general : ['item_full_name'] } }, { relation_id : 163, // связь с физическим лицом relation_field : 'slave', data_fields : { property : [ 18, // фамилия 389 // инициалы ] } } ] } } }Именно это часть из архитектуры идёт в модель, а затем в БД (если речь про бек) или на апи (если речь про фронт).
Options — это специальные параметры, которые будут уникальны в каждом отдельно взятом продукте. Пояснение: В не релизном состоянии, когда код все ещё пишется и нет абсолютно точного описания задачи и конечной цели, когда не проработана вся комбинаторика — есть кейсы, когда в запрос надо добавить некие опции, чтобы получить результат (назовем это прототипный код, к примеру). Это место, куда вы можете пихать, пока не поймете как с этим быть.
Response — определяет тот формат (модель, дата-класс, …) который вы хотите получить или, к примеру, вы хотите получить только ids элементов.
Дополнительный плюс этого подхода (как и любого другого, где есть сразу заложенная абстракция) — вы в любой момент без изменения бизнес логики сможете отказаться от реализации (которая в примере) и заменить её на более оптимизированный код (или даже отдельный сервис)
Немного рефлексии, для цельности картины:
Основные тезисы, которых точно стоит придерживаться в работе с данными
-
Абстракции — наше всё
-
Принцип единой ответственности (в чуть более широкой интерпретации) — должен быть в основе каждого вашего технического и не очень решения
-
Простота — во всём, простой код — легче понять и развить (исправить)
-
Бизнес логика и отдельные модули — не должны зависеть от поставщика решений (низкая связанность)
-
Каждое разрабатываемое приложение должно иметь четкую, единообразную структуру (но бывает много исключений)
ссылка на оригинал статьи https://habr.com/ru/articles/587014/
Добавить комментарий