
Привет, друзья!
Я продолжаю изучать MediaPipe — библиотеку с открытым исходным кодом от Google, предоставляющую «кроссплатформенные и кастомизируемые решения на основе машинного обучения для работы с медиа», и в этой статье хочу рассказать вам о 2 инструментах:
- Selfie Segmentation, выделяющий людей на сцене, что позволяет осуществлять замену фона на кадрах видео в процессе потоковой передачи соответствующих данных;
- Face Mesh, предоставляющий сетку лица человека, состоящую из 468 контрольных точек с координатами в трехмерном пространстве, что позволяет реализовать некоторые интересные визуальные эффекты.
Если вам это интересно, прошу под кат.
В предыдущей статье, посвященной MediaPipe, рассматривалась возможность использования координат суставов кисти руки для управления содержимым веб-страницы. Там шаг за шагом и достаточно подробно показан процесс получения данных с видеокамеры пользователя и их обработка с помощью двумерного контекста рисования холста (HTML-элемент canvas). В этой статье я ограничусь особенностями названных инструментов.
Для работы с зависимостями будет использоваться Yarn, а для создания шаблона проекта — Vite.
Проект будет реализован на чистом JavaScript.
Подготовка и настройка проекта
Создаем шаблон проекта:
# mediapipe_selfie_face - название проекта # vanilla - используемый шаблон yarn create vite mediapipe_selfie_face --template vanilla
Переходим в созданную директорию, устанавливаем зависимости и запускаем сервер для разработки:
cd mediapipe_selfie_face yarn yarn dev
Устанавливаем пакеты MediaPipe:
yarn add @mediapipe/selfie_segmentation @mediapipe/face_mesh @mediapipe/camera_utils @mediapipe/drawing_utils
Определяем начальную разметку в файле index.html:
<body> <video></video> <canvas></canvas> </body>
И начальные стили в файле style.css:
body { margin: 0; overflow: hidden; } canvas { left: 0; position: absolute; top: 0; }
Обратите внимание: холст располагается поверх видео.
Это все, что требуется для подготовки и настройки проекта.
Замена видеофона
Создаем файл selfie_segmentation.js в корне проекта и подключаем его в index.html:
<script type="module" src="/selfie_segmentation.js"></script>
Начнем с примера из официальной документации. В нем выделенный на сцене человек закрашивается зеленым цветом.
Импортируем зависимости и стили:
import { Camera } from "@mediapipe/camera_utils"; import { SelfieSegmentation } from "@mediapipe/selfie_segmentation"; import "./style.css";
Получаем ссылки на элементы video и canvas, а также на 2D-контекст рисования:
const video$ = document.querySelector("video"); const canvas$ = document.querySelector("canvas"); const ctx = canvas$.getContext("2d");
Определяем ширину и высоту холста, равные ширине и высоте области просмотра, и записываем их в переменные:
const WIDTH = (canvas$.width = window.innerWidth); const HEIGHT = (canvas$.height = window.innerHeight);
Создаем экземпляр средства выделения человека на сцене:
const selfieSegmentation = new SelfieSegmentation({ // загружаем дополнительные файлы, необходимые для работы инструмента locateFile: (file) => `./node_modules/@mediapipe/selfie_segmentation/${file}`, });
Устанавливаем настройку modelSelection:
selfieSegmentation.setOptions({ modelSelection: 1, });
Данная настройка принимает числа 0 и 1, определяющие используемую модель распознавания, где 0 означает общую модель (general model), а 1 — ландшафтную модель (landscape model). Распознавание с использованием общей модели является более точным, но менее быстрым (подробнее см. здесь). Мы жертвуем точностью в пользу производительности.
Регистрируем обработку результатов распознавания:
selfieSegmentation.onResults(onResults);
Создаем экземпляр средства захвата данных с видеокамеры пользователя:
const camera = new Camera(video$, { // обработчик захваченного кадра видео onFrame: async () => { await selfieSegmentation.send({ image: video$ }); }, // для захвата видео с USB-камеры // при использовании фронтальной/передней камеры ноутбука, данную настройку можно опустить facingMode: undefined, // ширина и высота видеокадра соответствуют ширине и высоте холста (области просмотра) width: WIDTH, height: HEIGHT, });
Запускаем процесс захвата видео:
camera.start();
Определяем функцию обработки результатов распознавания:
function onResults(results) { console.log(results); // сохраняем состояние холста ctx.save(); // очищаем холст ctx.clearRect(0, 0, WIDTH, HEIGHT); // рисуем маску (выделенную область/человека) ctx.drawImage(results.segmentationMask, 0, 0, WIDTH, HEIGHT); // перезаписываем существующие пиксели (см. ниже) ctx.globalCompositeOperation = "source-in"; // определяем цвет заливки ctx.fillStyle = "#00FF00"; // рисуем прямоугольник ctx.fillRect(0, 0, WIDTH, HEIGHT); // записываем отсутствующие пиксели ctx.globalCompositeOperation = "destination-atop"; // рисуем изображение - кадр видео ctx.drawImage(results.image, 0, 0, WIDTH, HEIGHT); // восстанавливаем состояние холста ctx.restore(); }
Свойство globalCompositeOperation определяет тип операции компоновки (compositing operation), применяемой при рисовании фигур. В нашем случае тип source-in означает, что зеленый прямоугольник рисуется (fillRect()) только в пределах выделенной области (results.segmentationMask), что приводит к ее окрашиванию в зеленый цвет, а тип destination-atop — что кадр видео рисуется за существующим содержимым хоста, что приводит к заполнению/восстановлению недостающих пикселей.
Результат:

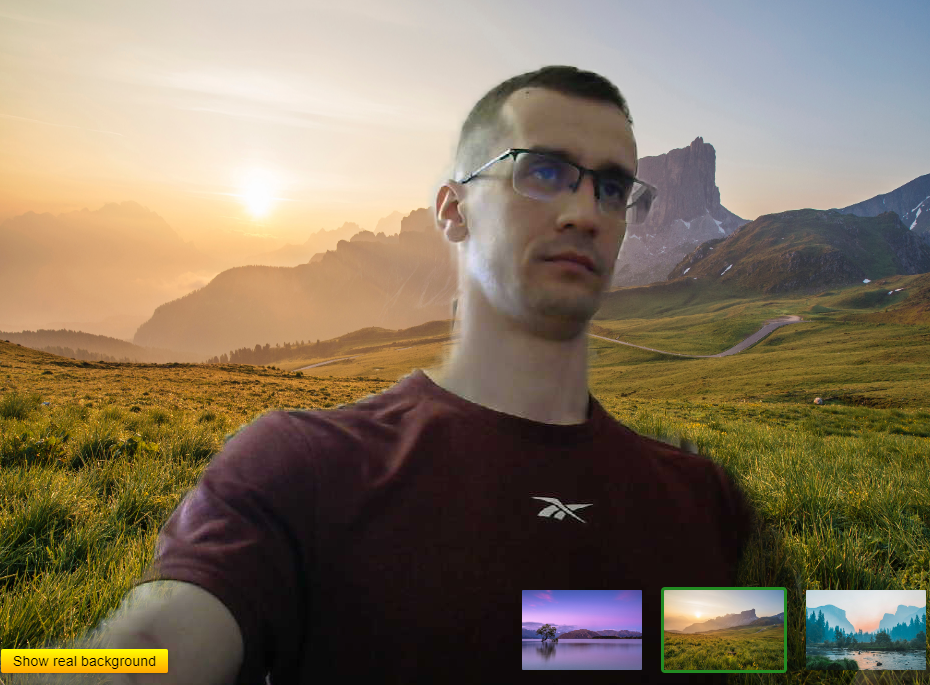
Реализуем замену фона видео.
Идем на Unsplash и скачиваем 3 изображения, которые будут использоваться в качестве фона (или возьмите изображения из репозитория проекта). Помещаем их в директорию public и добавляем в разметку:
<div class="images-box"> <img src="/images/img1.jpg" alt="" /> <img src="/images/img2.jpg" alt="" /> <img src="/images/img3.jpg" alt="" /> </div> <button>Show real background</button>
Обратите внимание, что мы также добавили кнопку для восстановления оригинального фона.
Добавляем стили для изображений и кнопки в style.css:
.images-box { bottom: 1rem; display: flex; gap: 1rem; position: absolute; right: 1rem; } img { border-radius: 4px; border: 3px solid transparent; cursor: pointer; display: block; max-width: 120px; transition: border-color 0.2s ease-in-out; } img:hover { border-color: steelblue; } img.selected { border-color: forestgreen; } button { background-image: linear-gradient(yellow, orange); border-radius: 2px; border: none; bottom: 1rem; box-shadow: 0 1px 2px rgba(0, 0, 0, 0.2); cursor: pointer; font-size: 0.9rem; left: 1rem; outline: none; padding: 0.25rem 0.75rem; position: absolute; transition: box-shadow 0.2s ease-in-out; } button:active { box-shadow: none; }
Изображение, на которое наведен курсор, выделяется синей рамкой, а выбранное — зеленой.
Результат:

Получаем ссылки на контейнер для изображений и кнопку, а также определяем переменную для выбранного изображения:
const imagesBox$ = document.querySelector(".images-box"); const button$ = document.querySelector("button"); let img$ = null;
Определяем функцию обработки клика по контейнеру для изображений:
const onImagesBoxClick = (e) => { // определяем новое выбранное изображение const newSelectedImage = e.target.localeName === "img" ? e.target : e.target.closest("img"); if (!newSelectedImage) return; // определяем предыдущее выбранное изображение const prevSelectedImage = imagesBox$.querySelector(".selected"); if (prevSelectedImage) { prevSelectedImage.classList.remove("selected"); } newSelectedImage.classList.add("selected"); // записываем новое выбранное изображение в переменную img$ = newSelectedImage; };
Определяем функцию обработки нажатия кнопки:
const onButtonClick = () => { // очищаем переменную img$ = null; // очищаем холст ctx.clearRect(0, 0, WIDTH, HEIGHT); const selectedImage = imagesBox$.querySelector(".selected"); if (selectedImage) { selectedImage.classList.remove("selected"); } };
Регистрируем обработчики:
imagesBox$.addEventListener("click", onImagesBoxClick); button$.addEventListener("click", onButtonClick);
Для замены фона в onResults() достаточно изменить тип операции компоновки с source-in на source-out (т.е. рисовать только за пределами выделенной области) и рисовать выбранное изображение вместо зеленого прямоугольника:
// выполнять код функции только при наличии выбранного изображения if (!img$) return; ctx.save(); ctx.clearRect(0, 0, WIDTH, HEIGHT); ctx.drawImage(results.segmentationMask, 0, 0, WIDTH, HEIGHT); // перезаписываем существующие пиксели ctx.globalCompositeOperation = "source-out"; ctx.drawImage(img$, 0, 0, WIDTH, HEIGHT);
Результат:

Применение визуальных эффектов на основе координат лица
Создаем файл face_mesh.js в корне проекта.
Снова возьмем пример из официальной документации. В нем рисуется сетка лица с выделением овала лица, бровей, глаз, зрачков и губ, а также соединительных линий между контрольными точками лица.
Импортируем зависимости и стили:
import "./style.css"; import { Camera } from "@mediapipe/camera_utils"; import { drawConnectors } from "@mediapipe/drawing_utils"; import { FaceMesh, // индексы координат (см. ниже) FACEMESH_FACE_OVAL, FACEMESH_LEFT_EYE, FACEMESH_LEFT_EYEBROW, FACEMESH_LEFT_IRIS, FACEMESH_LIPS, FACEMESH_RIGHT_EYE, FACEMESH_RIGHT_EYEBROW, FACEMESH_RIGHT_IRIS, FACEMESH_TESSELATION, } from "@mediapipe/face_mesh";
Определяем константы:
const video$ = document.querySelector("video"); const canvas$ = document.querySelector("canvas"); const ctx = canvas$.getContext("2d"); const WIDTH = (canvas$.width = window.innerWidth); const HEIGHT = (canvas$.height = window.innerHeight);
Создаем экземпляр средства распознавания лица, устанавливаем настройки и регистрируем обработчик распознавания:
const faceMesh = new FaceMesh({ locateFile: (file) => `../node_modules/@mediapipe/face_mesh/${file}`, }); faceMesh.setOptions({ maxNumFaces: 1, refineLandmarks: true, minDetectionConfidence: 0.5, minTrackingConfidence: 0.5, }); faceMesh.onResults(onResults);
О настройках распознавания можно почитать здесь.
Создаем экземпляр средства захвата данных с камеры и запускаем процесс захвата:
const camera = new Camera(video$, { onFrame: async () => { await faceMesh.send({ image: video$ }); }, facingMode: undefined, width: WIDTH, height: HEIGHT, }); camera.start();
Определяем функцию обработки результатов захвата:
function onResults(results) { console.log(results); // сохраняем состояние холста ctx.save(); // очищаем холст ctx.clearRect(0, 0, WIDTH, HEIGHT); // рисуем кадр видео ctx.drawImage(results.image, 0, 0, WIDTH, HEIGHT); // если имеются результаты распознавания if (results.multiFaceLandmarks.length) { // перебираем контрольные точки лиц // в нашем случае лицо одно (multiFaceLandmarks[0]) // количество распознаваемых лиц определяется настройкой `maxNumFaces` for (const landmarks of results.multiFaceLandmarks) { // рисуем соединительные линии между точками drawConnectors(ctx, landmarks, FACEMESH_TESSELATION, { color: "#C0C0C070", lineWidth: 1, }); // рисуем обводку вокруг правого глаза drawConnectors(ctx, landmarks, FACEMESH_RIGHT_EYE, { color: "#FF3030", }); // ... правой брови drawConnectors(ctx, landmarks, FACEMESH_RIGHT_EYEBROW, { color: "#FF3030", }); // ... правого зрачка drawConnectors(ctx, landmarks, FACEMESH_RIGHT_IRIS, { color: "#FF3030", }); // ... левого глаза, брови и зрачка drawConnectors(ctx, landmarks, FACEMESH_LEFT_EYE, { color: "#30FF30", }); drawConnectors(ctx, landmarks, FACEMESH_LEFT_EYEBROW, { color: "#30FF30", }); drawConnectors(ctx, landmarks, FACEMESH_LEFT_IRIS, { color: "#30FF30", }); // ... овала лица drawConnectors(ctx, landmarks, FACEMESH_FACE_OVAL, { color: "#E0E0E0", }); // ... губ drawConnectors(ctx, landmarks, FACEMESH_LIPS, { color: "#E0E0E0" }); } } // восстанавливаем состояние холста ctx.restore(); }
Результат:

Контрольные точки лица с координатами (multiFaceLandmarks[0]) выглядят следующим образом:

Как видим, это просто массив из 468 элементов. Здесь возникает закономерный вопрос: как определить, какой индекс к какой точке относится? Без ответа на этот вопрос привязка к координатам конкретной точки с целью реализации каких-либо эффектов сводится к перебору всех точек до обнаружения искомой. Процесс перебора, учитывая количество точек, является, мягко говоря, утомительным.
Покопавшись в официальной документации, мне удалось обнаружить эту каноническую модель лица (canonical face model), на которой указаны индексы точек. Следует отметить, что, во-первых, не все индексы соответствуют действительности, т.е. совпадают с индексами массива multiFaceLandmarks[0], во-вторых, некоторые индексы почти нечитаемы (красный на темно-сером — плохое цветовое решение).
{kind=link}
Начнем с чего-нибудь попроще. Как насчет того, чтобы рендерить клоунский нос на носу (простите за тавтологию)?
Находим в сети изображение клоунского носа в формате PNG и добавляем его в разметку:
<img src="/images/nose.png" alt="" class="nose-image" style="display: none" />
Обратите внимание: мы загружаем изображение, но не отображаем его.
Получаем ссылку на изображение и определяем его размер в пикселях:
const noseImage$ = document.querySelector(".nose-image"); const starImage$ = document.querySelector(".star-image"); const NOSE_SIZE = 50;
Заменяем цикл for в onResults() на функцию рисования носа:
drawNose(results.multiFaceLandmarks[0]);
Находим нужную точку на канонической модели лица — точка с индексом 4:

Нас интересуют координаты x и y. Они имеют значения от 0 до 1 и, по сути, представляют собой доли или проценты размеров холста. Поэтому положение изображения по осям x и y (его центральную точку) можно вычислить следующим образом:
const x = landmarks[4].x * WIDTH - NOSE_SIZE / 2; const y = landmarks[4].y * HEIGHT - NOSE_SIZE / 2;
Определяем функцию рисования носа:
function drawNose(landmarks) { const x = landmarks[4].x * WIDTH - NOSE_SIZE / 2; const y = landmarks[4].y * HEIGHT - NOSE_SIZE / 2; ctx.drawImage(noseImage$, x, y, NOSE_SIZE, NOSE_SIZE); }
Результат:

Пойдем немного дальше и реализуем рендеринг звезд в глазах.
Находим в сети изображение звезды в формате PNG и добавляем его в разметку:
<img src="/images/star.png" alt="" class="star-image" style="display: none" />
Получаем ссылку на изображение:
const starImage$ = document.querySelector(".star-image");
Обратите внимание: мы не определяем размер звезды, поскольку он будет зависеть от размера каждого глаза, т.е. вычисляться динамически.
Добавляем функцию рендеринга звезд в onResults():
if (results.multiFaceLandmarks.length) { drawStars(results.multiFaceLandmarks[0]); drawNose(results.multiFaceLandmarks[0]); }
Для вычисления положения звезды по осям x и y, а также ее размера (применительно к каждому глазу), необходимо определить 4 точки глаза, его ширину, высоту и центральную точку. Индексами искомых точек правого глаза являются:
33— левый внутренний край;133— правый внутренний край;159— верхний внутренний край;145— нижний внутренний край.
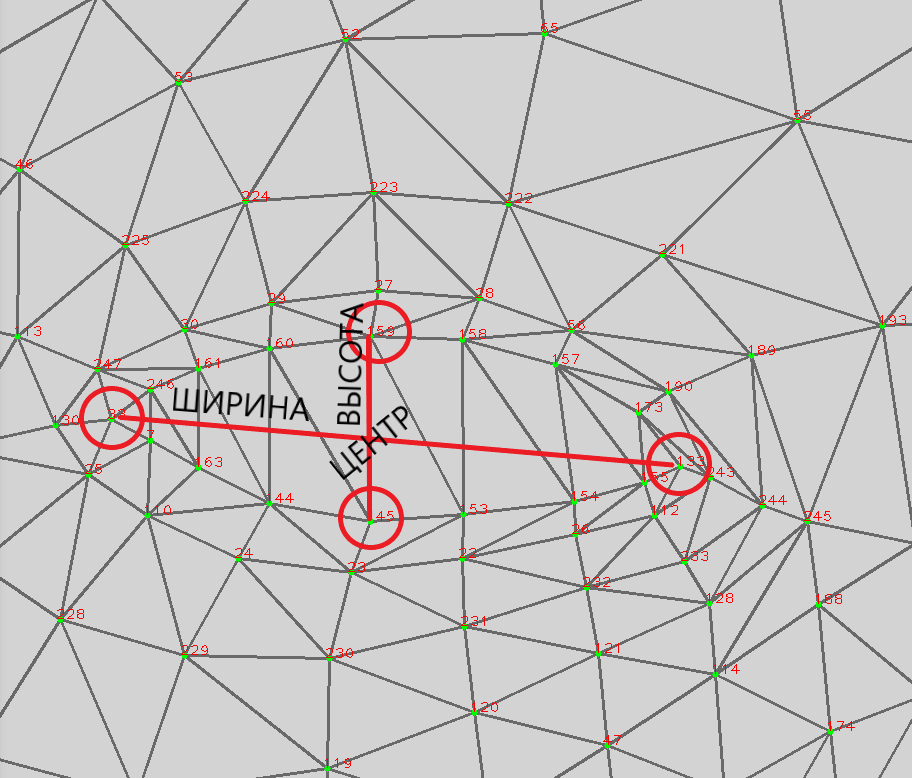
Индексами левого глаза являются 362, 263, 386 и 374.
Определяем функцию рисования звезд:
function drawStars(landmarks) { // правая звезда const rightEyeLeft = landmarks[33].x; const rightEyeRight = landmarks[133].x; // вычисляем ширину правой звезды const rightStarWidth = (rightEyeRight - rightEyeLeft) * WIDTH * 1.5; // ... центр по оси `x` const rightStarX = landmarks[159].x * WIDTH - rightStarWidth / 2; const rightEyeTop = landmarks[159].y; const rightEyeBottom = landmarks[145].y; // ... центр по оси `y` const rightStarY = (rightEyeTop + (rightEyeBottom - rightEyeTop)) * HEIGHT - rightStarWidth / 2; // рисуем правую звезду ctx.drawImage( starImage$, rightStarX, rightStarY, rightStarWidth, rightStarWidth ); // левая звезда const leftEyeLeft = landmarks[362].x; const leftEyeRight = landmarks[263].x; const leftStarWidth = (leftEyeRight - leftEyeLeft) * WIDTH * 1.5; const leftStarX = landmarks[386].x * WIDTH - leftStarWidth / 2; const leftEyeTop = landmarks[386].y; const leftEyeBottom = landmarks[374].y; const leftStarY = (leftEyeTop + (leftEyeBottom - leftEyeTop)) * HEIGHT - leftStarWidth / 2; ctx.drawImage(starImage$, leftStarX, leftStarY, leftStarWidth, leftStarWidth); }
Обратите внимание на 2 вещи:
- поскольку звезда «квадратная», при ее рисовании на холсте в качестве ширины и высоты в
drawImage()передается ширина звезды, вычисленная на основе ширины глаза (которая всегда больше высоты глаза); - звезды в полтора раза больше глаз.
Результат:

Мои попытки продвинуться еще дальше и подружить Face Mesh с Three.js не увенчались успехом, поскольку мне не удалось обнаружить настроек для камеры (camera), которые являются критически важными для рендеринга трехмерных объектов и моделей на холсте по определенным координатам. Если вы обнаружите эти настройки или найдете способ обойти указанное ограничение, поделитесь, пожалуйста, в комментариях.
Пожалуй, это все, о чем я хотел рассказать вам в этой статье. Надеюсь, вы узнали что-то новое и не зря потратили время.
Благодарю за внимание и happy coding! И с наступающим Новым годом (очень хочется верить, что он будет лучше уходящего).

ссылка на оригинал статьи https://habr.com/ru/articles/706880/
Добавить комментарий