
Привет, друзья!
В этой серии статей мы разбираем структуры данных и алгоритмы, представленные в этом замечательном репозитории. Это пятая часть серии.
Сегодня мы рассмотрим систему непересекающихся множеств, фильтр Блума и кэш актуальных данных.
Код, представленный в этой и других статьях серии, можно найти в этом репозитории.
Интересно? Тогда прошу под кат.
15. Система непересекающихся множеств
Описание
Система непересекающихся множеств (disjoint set) (также называемая структурой данных поиска объединения (пересечения) (union-find data structure) или множеством поиска слияния (merge-find set)) — это структура данных, которая содержит множество элементов, разделенных на определенное количество непересекающихся подмножеств. Она обеспечивает почти константное время выполнения операций (ограниченное обратной функцией Аккермана) добавления новых множеств, объединения существующих множеств и определения принадлежности элементов к одному множеству. Среди прочего, СНМ играет ключевую роль в алгоритме Краскала для построения минимального остовного дерева взвешенного связного неориентированного графа.
Основные операции СНМ:
MakeSet(x)— создает одноэлементное множество{x}Find(x)— возвращает идентификатор множества (выделенный или репрезентативный элемент), содержащего элементxUnion(x, y)— объединяет множества, содержащиеxиy

8 непересекающихся множеств, созданных с помощью MakeSet

Группировка множеств с помощью Union
Реализация
Начнем с реализации конструктора выделенного элемента множества:
// data-structures/disjoin-set/item.js export default class Item { constructor(value, keyCb) { // Значение this.value = value // Кастомная функция извлечения ключа this.keyCb = keyCb // Родительский узел this.parent = null // Дочерние узлы this.children = {} } }
Методы получения значения узла, корневого узла и определения того, является ли узел корневым:
// Возвращает ключ (значение) getKey() { if (this.keyCb) { return this.keyCb(this.value) } return this.value } // Возвращает корневой узел getRoot() { return this.isRoot() ? this : this.parent.getRoot() } // Определяет, является ли узел корневым isRoot() { return this.parent === null }
Методы получения ранга и потомков узла:
// Возвращает ранг (вес) узла getRank() { const children = this.getChildren() if (children.length === 0) { return 0 } let rank = 0 for (const child of children) { rank += 1 rank += child.getRank() } return rank } // Возвращает потомков getChildren() { return Object.values(this.children) }
Методы установки родительского и добавления дочернего узла:
// Устанавливает предка setParent(parent, forceSettingParentChild = true) { this.parent = parent if (forceSettingParentChild) { parent.addChild(this) } return this } // Добавляет потомка addChild(child) { this.children[child.getKey()] = child child.setParent(this, false) return this }
export default class Item { constructor(value, keyCb) { // Значение this.value = value // Кастомная функция извлечения ключа this.keyCb = keyCb // Родительский узел this.parent = null // Дочерние узлы this.children = {} } // Возвращает ключ (значение) getKey() { if (this.keyCb) { return this.keyCb(this.value) } return this.value } // Возвращает корневой узел getRoot() { return this.isRoot() ? this : this.parent.getRoot() } // Определяет, является ли узел корневым isRoot() { return this.parent === null } // Возвращает ранг (вес) узла getRank() { const children = this.getChildren() if (children.length === 0) { return 0 } let rank = 0 for (const child of children) { rank += 1 rank += child.getRank() } return rank } // Возвращает потомков getChildren() { return Object.values(this.children) } // Устанавливает предка setParent(parent, forceSettingParentChild = true) { this.parent = parent if (forceSettingParentChild) { parent.addChild(this) } return this } // Добавляет потомка addChild(child) { this.children[child.getKey()] = child child.setParent(this, false) return this } }
Приступаем к реализации СНМ:
// data-structures/disjoin-set/index.js import Item from './item' export default class DisjointSet { constructor(cb) { // Кастомная функция извлечения ключа (значения) узла this.cb = cb // Непересекающиеся подмножества this.items = {} } }
Метод создания подмножества:
// Создает подмножество makeSet(value) { // Создаем выделенный элемент const item = new Item(value, this.cb) // Добавляем подмножество в список if (!this.items[item.getKey()]) { this.items[item.getKey()] = item } return this }
Метод поиска выделенного элемента:
// Ищет выделенный элемент find(value) { const temp = new Item(value, this.cb) const item = this.items[temp.getKey()] return item ? item.getRoot().getKey() : null }
Метод объединения двух подмножеств:
// Объединяет подмножества union(value1, value2) { const root1 = this.find(value1) const root2 = this.find(value2) if (!root1 || !root2) { throw new Error('Одно или оба значения отсутствуют!') } if (root1 === root2) { return this } const item1 = this.items[root1] const item2 = this.items[root2] // Определяем, какое подмножество имеет больший ранг. // Подмножество с меньшим рангом становится потомком подмножества с большим рангом if (item1.getRank() < item2.getRank()) { item2.addChild(item1) return this } item1.addChild(item2) return this }
Метод определения принадлежности двух элементов к одному множеству:
// Определяет, принадлежат ли значения к одному множеству isSameSet(value1, value2) { const root1 = this.find(value1) const root2 = this.find(value2) if (!root1 || !root2) { throw new Error('Одно или оба значения отсутствуют!') } return root1 === root2 }
import Item from './item' export default class DisjointSet { constructor(cb) { // Кастомная функция извлечения ключа (значения) узла this.cb = cb // Непересекающиеся подмножества this.items = {} } // Создает подмножество makeSet(value) { // Создаем выделенный элемент const item = new Item(value, this.cb) // Добавляем подмножество в список if (!this.items[item.getKey()]) { this.items[item.getKey()] = item } return this } // Ищет выделенный элемент find(value) { const temp = new Item(value, this.cb) const item = this.items[temp.getKey()] return item ? item.getRoot().getKey() : null } // Объединяет подмножества union(value1, value2) { const root1 = this.find(value1) const root2 = this.find(value2) if (!root1 || !root2) { throw new Error('Одно или оба значения отсутствуют!') } if (root1 === root2) { return this } const item1 = this.items[root1] const item2 = this.items[root2] // Определяем, какое подмножество имеет больший ранг. // Подмножество с меньшим рангом становится потомком подмножества с большим рангом if (item1.getRank() < item2.getRank()) { item2.addChild(item1) return this } item1.addChild(item2) return this } // Определяет, принадлежат ли значения к одному множеству isSameSet(value1, value2) { const root1 = this.find(value1) const root2 = this.find(value2) if (!root1 || !root2) { throw new Error('Одно или оба значения отсутствуют!') } return root1 === root2 } }
Автономную СНМ (без дополнительных зависимостей) можно реализовать следующим образом:
export default class DisjointSetAdHoc { constructor(size) { this.roots = new Array(size).fill(0).map((_, i) => i) this.heights = new Array(size).fill(1) } find(a) { if (this.roots[a] === a) return a this.roots[a] = this.find(this.roots[a]) return this.roots[a] } union(a, b) { const rootA = this.find(a) const rootB = this.find(b) if (rootA === rootB) return if (this.heights[rootA] < this.heights[rootB]) { this.roots[rootA] = rootB } else if (this.heights[rootA] > this.heights[rootB]) { this.roots[rootB] = rootA } else { this.roots[rootB] = rootA this.heights[rootA]++ } } connected(a, b) { return this.find(a) === this.find(b) } }
Тестирование
// data-structures/disjoint-set/__tests__/item.test.js import Item from '../item' describe('Item', () => { it('должен выполнить базовые манипуляции с выделенным элементом', () => { const itemA = new Item('A') const itemB = new Item('B') const itemC = new Item('C') const itemD = new Item('D') expect(itemA.getRank()).toBe(0) expect(itemA.getChildren()).toEqual([]) expect(itemA.getKey()).toBe('A') expect(itemA.getRoot()).toEqual(itemA) expect(itemA.isRoot()).toBe(true) expect(itemB.isRoot()).toBe(true) itemA.addChild(itemB) itemD.setParent(itemC) expect(itemA.getRank()).toBe(1) expect(itemC.getRank()).toBe(1) expect(itemB.getRank()).toBe(0) expect(itemD.getRank()).toBe(0) expect(itemA.getChildren().length).toBe(1) expect(itemC.getChildren().length).toBe(1) expect(itemA.getChildren()[0]).toEqual(itemB) expect(itemC.getChildren()[0]).toEqual(itemD) expect(itemB.getChildren().length).toBe(0) expect(itemD.getChildren().length).toBe(0) expect(itemA.getRoot()).toEqual(itemA) expect(itemB.getRoot()).toEqual(itemA) expect(itemC.getRoot()).toEqual(itemC) expect(itemD.getRoot()).toEqual(itemC) expect(itemA.isRoot()).toBe(true) expect(itemB.isRoot()).toBe(false) expect(itemC.isRoot()).toBe(true) expect(itemD.isRoot()).toBe(false) itemA.addChild(itemC) expect(itemA.isRoot()).toBe(true) expect(itemB.isRoot()).toBe(false) expect(itemC.isRoot()).toBe(false) expect(itemD.isRoot()).toBe(false) expect(itemA.getRank()).toEqual(3) expect(itemB.getRank()).toEqual(0) expect(itemC.getRank()).toEqual(1) }) it('должен выполнить базовые манипуляции с выделенным элементом с кастомной функцией извлечения ключа', () => { const keyExtractor = (value) => value.key const itemA = new Item({ key: 'A', value: 1 }, keyExtractor) const itemB = new Item({ key: 'B', value: 2 }, keyExtractor) const itemC = new Item({ key: 'C', value: 3 }, keyExtractor) const itemD = new Item({ key: 'D', value: 4 }, keyExtractor) expect(itemA.getRank()).toBe(0) expect(itemA.getChildren()).toEqual([]) expect(itemA.getKey()).toBe('A') expect(itemA.getRoot()).toEqual(itemA) expect(itemA.isRoot()).toBe(true) expect(itemB.isRoot()).toBe(true) itemA.addChild(itemB) itemD.setParent(itemC) expect(itemA.getRank()).toBe(1) expect(itemC.getRank()).toBe(1) expect(itemB.getRank()).toBe(0) expect(itemD.getRank()).toBe(0) expect(itemA.getChildren().length).toBe(1) expect(itemC.getChildren().length).toBe(1) expect(itemA.getChildren()[0]).toEqual(itemB) expect(itemC.getChildren()[0]).toEqual(itemD) expect(itemB.getChildren().length).toBe(0) expect(itemD.getChildren().length).toBe(0) expect(itemA.getRoot()).toEqual(itemA) expect(itemB.getRoot()).toEqual(itemA) expect(itemC.getRoot()).toEqual(itemC) expect(itemD.getRoot()).toEqual(itemC) expect(itemA.isRoot()).toBe(true) expect(itemB.isRoot()).toBe(false) expect(itemC.isRoot()).toBe(true) expect(itemD.isRoot()).toBe(false) itemA.addChild(itemC) expect(itemA.isRoot()).toBe(true) expect(itemB.isRoot()).toBe(false) expect(itemC.isRoot()).toBe(false) expect(itemD.isRoot()).toBe(false) expect(itemA.getRank()).toEqual(3) expect(itemB.getRank()).toEqual(0) expect(itemC.getRank()).toEqual(1) }) })
Выполняем тесты:
npm run test ./data-structures/disjoint-set/__tests__/item
Результаты:

// data-structures/disjoint-set/__tests__/disjoint-set.test.js import DisjointSet from '..' describe('DisjointSet', () => { it('должен выбросить исключения при объединении и проверке несуществующих множеств', () => { function mergeNotExistingSets() { const disjointSet = new DisjointSet() disjointSet.union('A', 'B') } function checkNotExistingSets() { const disjointSet = new DisjointSet() disjointSet.isSameSet('A', 'B') } expect(mergeNotExistingSets).toThrow() expect(checkNotExistingSets).toThrow() }) it('должен выполнить базовые манипуляции с системой непересекающихся множеств', () => { const disjointSet = new DisjointSet() expect(disjointSet.find('A')).toBeNull() expect(disjointSet.find('B')).toBeNull() disjointSet.makeSet('A') expect(disjointSet.find('A')).toBe('A') expect(disjointSet.find('B')).toBeNull() disjointSet.makeSet('B') expect(disjointSet.find('A')).toBe('A') expect(disjointSet.find('B')).toBe('B') disjointSet.makeSet('C') expect(disjointSet.isSameSet('A', 'B')).toBe(false) disjointSet.union('A', 'B') expect(disjointSet.find('A')).toBe('A') expect(disjointSet.find('B')).toBe('A') expect(disjointSet.isSameSet('A', 'B')).toBe(true) expect(disjointSet.isSameSet('B', 'A')).toBe(true) expect(disjointSet.isSameSet('A', 'C')).toBe(false) disjointSet.union('A', 'A') disjointSet.union('B', 'C') expect(disjointSet.find('A')).toBe('A') expect(disjointSet.find('B')).toBe('A') expect(disjointSet.find('C')).toBe('A') expect(disjointSet.isSameSet('A', 'B')).toBe(true) expect(disjointSet.isSameSet('B', 'C')).toBe(true) expect(disjointSet.isSameSet('A', 'C')).toBe(true) disjointSet.makeSet('E').makeSet('F').makeSet('G').makeSet('H').makeSet('I') disjointSet.union('E', 'F').union('F', 'G').union('G', 'H').union('H', 'I') expect(disjointSet.isSameSet('A', 'I')).toBe(false) expect(disjointSet.isSameSet('E', 'I')).toBe(true) disjointSet.union('I', 'C') expect(disjointSet.find('I')).toBe('E') expect(disjointSet.isSameSet('A', 'I')).toBe(true) }) it('должен выполнить базовые манипуляции с системой непересекающихся множеств с кастомной функцией извлечения ключа', () => { const keyExtractor = (value) => value.key const disjointSet = new DisjointSet(keyExtractor) const itemA = { key: 'A', value: 1 } const itemB = { key: 'B', value: 2 } const itemC = { key: 'C', value: 3 } expect(disjointSet.find(itemA)).toBeNull() expect(disjointSet.find(itemB)).toBeNull() disjointSet.makeSet(itemA) expect(disjointSet.find(itemA)).toBe('A') expect(disjointSet.find(itemB)).toBeNull() disjointSet.makeSet(itemB) expect(disjointSet.find(itemA)).toBe('A') expect(disjointSet.find(itemB)).toBe('B') disjointSet.makeSet(itemC) expect(disjointSet.isSameSet(itemA, itemB)).toBe(false) disjointSet.union(itemA, itemB) expect(disjointSet.find(itemA)).toBe('A') expect(disjointSet.find(itemB)).toBe('A') expect(disjointSet.isSameSet(itemA, itemB)).toBe(true) expect(disjointSet.isSameSet(itemB, itemA)).toBe(true) expect(disjointSet.isSameSet(itemA, itemC)).toBe(false) disjointSet.union(itemA, itemC) expect(disjointSet.find(itemA)).toBe('A') expect(disjointSet.find(itemB)).toBe('A') expect(disjointSet.find(itemC)).toBe('A') expect(disjointSet.isSameSet(itemA, itemB)).toBe(true) expect(disjointSet.isSameSet(itemB, itemC)).toBe(true) expect(disjointSet.isSameSet(itemA, itemC)).toBe(true) }) it('должен объединить меньшее множество с большим, сделав большее новым выделенным элементом', () => { const disjointSet = new DisjointSet() disjointSet .makeSet('A') .makeSet('B') .makeSet('C') .union('B', 'C') .union('A', 'C') expect(disjointSet.find('A')).toBe('B') }) })
Выполняем тесты:
npm run test ./data-structures/disjoint-set/__tests__/disjoint-set
Результаты:

// data-structures/disjoint-set/__tests__/ad-hoc.test.js import DisjointSetAdhoc from '../ad-hoc' describe('DisjointSetAdhoc', () => { it('должен создать множества и найти соединенные элементы', () => { const set = new DisjointSetAdhoc(10) // 1-2-5-6-7 3-8-9 4 set.union(1, 2) set.union(2, 5) set.union(5, 6) set.union(6, 7) set.union(3, 8) set.union(8, 9) expect(set.connected(1, 5)).toBe(true) expect(set.connected(5, 7)).toBe(true) expect(set.connected(3, 8)).toBe(true) expect(set.connected(4, 9)).toBe(false) expect(set.connected(4, 7)).toBe(false) // 1-2-5-6-7 3-8-9-4 set.union(9, 4) expect(set.connected(4, 9)).toBe(true) expect(set.connected(4, 3)).toBe(true) expect(set.connected(8, 4)).toBe(true) expect(set.connected(8, 7)).toBe(false) expect(set.connected(2, 3)).toBe(false) }) it('должен сохранять высоту дерева маленькой', () => { const set = new DisjointSetAdhoc(10) // 1-2-6-7-9 1 3 4 5 set.union(7, 6) set.union(1, 2) set.union(2, 6) set.union(1, 7) set.union(9, 1) expect(set.connected(1, 7)).toBe(true) expect(set.connected(6, 9)).toBe(true) expect(set.connected(4, 9)).toBe(false) expect(Math.max(...set.heights)).toBe(3) }) })
Выполняем тесты:
npm run test ./data-structures/disjoint-set/__tests__/ad-hoc
Результаты:

16. Фильтр Блума
Описание
Фильтр Блума (Bloom filter) — это пространственно-эффективная вероятностная структура данных, предназначенная для определения наличия элемента во множестве. С одной стороны, эта структура является очень быстрой и использует минимальный объем памяти, с другой стороны, возможны ложноположительные (false positive) результаты. Ложноотрицательные (false negative) результаты невозможны. Другими словами, фильтр возвращает либо «элемент МОЖЕТ содержаться во множестве», либо «элемент ТОЧНО НЕ содержится во множестве». Фильтр Блума может использовать любое количество памяти, но, как правило, чем больше памяти, тем ниже вероятность ложноположительных результатов.
Блум предложил эту технику для применения в областях, где количество исходных данных потребовало бы непрактично много памяти в случае применения условно безошибочных техник хеширования.
Описание алгоритма
Пустой фильтр Блума представлен массивом из m битов, установленных в 0. Должно быть определено k независимых хеш-функций, отображающих каждый элемент множества в одну из m позиций массива, генерируя единообразное случайное распределение. Обычно k задается константой, которая намного меньше m и пропорциональна количеству добавляемых элементов. Точный выбор k и постоянной пропорциональности m определяются уровнем ложных срабатываний фильтра.
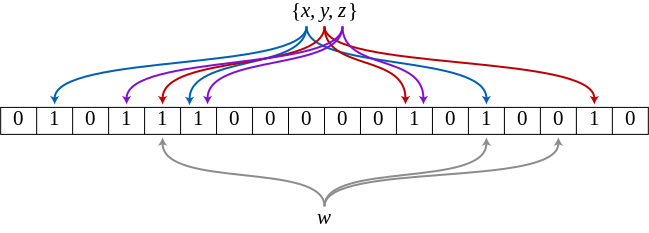
Вот пример фильтра Блума, представляющего множество {x, y, z}. Цветные стрелки показывают позиции (индексы) битового массива, соответствующие элементам множества. Элемент w не содержится во множестве {x, y, z}, потому что он привязан к позиции массива, равной 0. В данном случае m = 18, а k = 3.
Для добавления в фильтр элемента e необходимо записать 1 в каждую позицию h1(e), …, hk(e) (хеш-функции) битового массива.
Для определения наличия элемента e во множестве необходимо проверить состояние битов h1(e), …, hk(e). Если хотя бы один бит имеет значение 0, элемент отсутствует. Если все биты имеют значение 1, структура сообщает, что элемент присутствует. При этом, может возникнуть две ситуации: либо элемент действительно содержится во множестве, либо все биты оказались установлены случайно при добавлении других элементов. Второй случай является источником ложноположительных результатов.
Операции
Фильтр Блума позволяет выполнять две основные операции: вставка и поиск элемента. Поиск может завершаться ложноположительными результатами. Удаление элементов возможно, но проблематично.
Другими словами, в фильтр можно добавлять элементы, а на вопрос о наличии элемента структура отвечает либо «нет», либо «возможно».
Операции вставки и поиска выполняются за время O(1).
Создание фильтра
При создании фильтра указывается его размер. Размер нашего фильтра составляет 100. Все элементы устанавливаются в false (по сути, тоже самое, что 0).
В процессе добавления генерируется хеш элемента с помощью трех хеш-функций. Эти функции возвращают индексы. Значение по каждому индексу обновляется на true.
В процессе поиска также генерируется хеш элемента. Затем проверяется, что все значения по индексам являются true. Если это так, то элемент может содержаться во множестве.
Однако мы не можем быть в этом уверены на 100%, поскольку биты могли быть установлены при добавлении других элементов.
Если хотя бы одно значение равняется false, элемент точно отсутствует во множестве.
Ложноположительные результаты
Вероятность ложноположительных срабатываний определяется тремя факторами: размером фильтра (m), количеством используемых хеш-функций (k) и количеством элементов, добавляемых в фильтр (n).
Формула выглядит следующим образом:
( 1 — e -kn/m ) k
Значения этих переменных выбираются, исходя из приемлемости ложноположительных результатов.
Применение
Фильтр Блума может использоваться в блогах. Он идеально подходит для определения статей, которые пользователь еще не читал, за счет добавления в фильтр статей, прочитанных им.
Некоторые статьи будут отфильтрованы по ошибке, но цена приемлема: пользователь не увидит нескольких статей, зато ему будут показываться новые статьи при каждом посещении сайта.
Подробнее о фильтре Блума можно почитать в этой статье.
Реализация
Приступаем к реализации фильтра Блума:
// data-structures/bloom-filter.js export default class BloomFilter { // Размер фильтра напрямую влияет на вероятность ложноположительных результатов. // Как правило, чем больше размер, тем такая вероятность ниже constructor(size = 100) { // Размер фильтра this.size = size // Хранилище (по сути, сам фильтр) this.storage = this.createStore(size) } }
Метод добавления элемента в фильтр:
// Добавляет элемент в фильтр insert(item) { // Вычисляем хеш элемента (индексы массива в количестве 3 штук) const hashValues = this.getHashValues(item) // Устанавливаем значение по каждому индексу в `true` hashValues.forEach((v) => this.storage.setValue(v)) }
Метод определения наличия элемента в фильтре:
// Определяет наличие элемента в фильтре mayContain(item) { // Вычисляем хеш элемента const hashValues = this.getHashValues(item) // Перебираем индексы for (const v of hashValues) { // Если хотя бы одно значение равняется `false` if (!this.storage.getValue(v)) { // Элемент точно отсутствует return false } } // Элемент может присутствовать return true }
Метод создания хранилища (по сути, фильтра):
// Создает хранилище createStore(size) { // Хранилище - массив указанного размера, заполненный `false` const storage = new Array(size).fill(false) // Возвращается объект с "геттером" и "сеттером" return { getValue(i) { return storage[i] }, setValue(i) { storage[i] = true }, } }
Хеш-функции (довольно примитивные, надо сказать):
// Хеш-функции hash1(item) { let hash = 0 for (let i = 0; i < item.length; i++) { const char = item.charCodeAt(i) hash = (hash << 5) + hash + char hash &= hash // конвертируем значение в 32-битное целое число hash = Math.abs(hash) } return hash % this.size } hash2(item) { let hash = 5381 for (let i = 0; i < item.length; i++) { const char = item.charCodeAt(i) hash = (hash << 5) + hash + char // hash * 33 + char } return Math.abs(hash % this.size) } hash3(item) { let hash = 0 for (let i = 0; i < item.length; i++) { const char = item.charCodeAt(i) hash = (hash << 5) - hash + char hash &= hash // конвертируем значение в 32-битное целое число } return Math.abs(hash % this.size) }
Наконец, метод генерации хеша:
// Генерирует хеш элемента. // Возвращает массив из трех индексов getHashValues(item) { return [this.hash1(item), this.hash2(item), this.hash3(item)] }
export default class BloomFilter { // Размер фильтра напрямую влияет на вероятность ложноположительных результатов. // Как правило, чем больше размер, тем такая вероятность ниже constructor(size = 100) { // Размер фильтра this.size = size // Хранилище (по сути, сам фильтр) this.storage = this.createStore(size) } // Добавляет элемент в фильтр insert(item) { // Вычисляем хеш элемента (индексы массива в количестве 3 штук) const hashValues = this.getHashValues(item) // Устанавливаем значение по каждому индексу в `true` hashValues.forEach((v) => this.storage.setValue(v)) } // Определяет наличие элемента в фильтре mayContain(item) { // Вычисляем хеш элемента const hashValues = this.getHashValues(item) // Перебираем индексы for (const v of hashValues) { // Если хотя бы одно значение равняется `false` if (!this.storage.getValue(v)) { // Элемент точно отсутствует return false } } // Элемент может присутствовать return true } // Создает хранилище createStore(size) { // Хранилище - массив указанного размера, заполненный `false` const storage = new Array(size).fill(false) // Возвращается объект с "геттером" и "сеттером" return { getValue(i) { return storage[i] }, setValue(i) { storage[i] = true }, } } // Хеш-функции hash1(item) { let hash = 0 for (let i = 0; i < item.length; i++) { const char = item.charCodeAt(i) hash = (hash << 5) + hash + char hash &= hash // конвертируем значение в 32-битное целое число hash = Math.abs(hash) } return hash % this.size } hash2(item) { let hash = 5381 for (let i = 0; i < item.length; i++) { const char = item.charCodeAt(i) hash = (hash << 5) + hash + char // hash * 33 + char } return Math.abs(hash % this.size) } hash3(item) { let hash = 0 for (let i = 0; i < item.length; i++) { const char = item.charCodeAt(i) hash = (hash << 5) - hash + char hash &= hash // конвертируем значение в 32-битное целое число } return Math.abs(hash % this.size) } // Генерирует хеш элемента. // Возвращает массив из трех индексов getHashValues(item) { return [this.hash1(item), this.hash2(item), this.hash3(item)] } }
Тестирование
// data-structures/__tests__/bloom-filter.test.js import BloomFilter from '../bloom-filter' describe('BloomFilter', () => { let bloomFilter const people = ['Bruce Wayne', 'Clark Kent', 'Barry Allen'] beforeEach(() => { bloomFilter = new BloomFilter() }) it('должен содержать методы "insert" и "mayContain"', () => { expect(typeof bloomFilter.insert).toBe('function') expect(typeof bloomFilter.mayContain).toBe('function') }) it('должен создать хранилище с указанными методами', () => { const store = bloomFilter.createStore(18) expect(typeof store.getValue).toBe('function') expect(typeof store.setValue).toBe('function') }) it('должен стабильно хешировать элементы с помощью трех хеш-функций', () => { const str1 = 'apple' expect(bloomFilter.hash1(str1)).toEqual(bloomFilter.hash1(str1)) expect(bloomFilter.hash2(str1)).toEqual(bloomFilter.hash2(str1)) expect(bloomFilter.hash3(str1)).toEqual(bloomFilter.hash3(str1)) expect(bloomFilter.hash1(str1)).toBe(14) expect(bloomFilter.hash2(str1)).toBe(43) expect(bloomFilter.hash3(str1)).toBe(10) const str2 = 'orange' expect(bloomFilter.hash1(str2)).toEqual(bloomFilter.hash1(str2)) expect(bloomFilter.hash2(str2)).toEqual(bloomFilter.hash2(str2)) expect(bloomFilter.hash3(str2)).toEqual(bloomFilter.hash3(str2)) expect(bloomFilter.hash1(str2)).toBe(0) expect(bloomFilter.hash2(str2)).toBe(61) expect(bloomFilter.hash3(str2)).toBe(10) }) it('должен создать массив с тремя хешированными значениями', () => { expect(bloomFilter.getHashValues('abc').length).toBe(3) expect(bloomFilter.getHashValues('abc')).toEqual([66, 63, 54]) }) it('должен добавить строки и возвращать `true` при проверке их наличия', () => { people.forEach((person) => bloomFilter.insert(person)) // expect(bloomFilter.mayContain('Bruce Wayne')).toBe(true) // expect(bloomFilter.mayContain('Clark Kent')).toBe(true) // expect(bloomFilter.mayContain('Barry Allen')).toBe(true) expect(bloomFilter.mayContain('Tony Stark')).toBe(false) }) })
Запускаем тесты:
npm run test ./data-structures/__tests__/bloom-filter
Результаты:

17. Кэш актуальных данных
Описание
Кэш актуальных (часто используемых) данных (least recently used (LRU) cache) организует (хранит) элементы таким образом, что мы можем легко определить, какие элементы используются часто, а какие — редко.
Реализация КАД включает в себя:
- конструктор
LRUCache(capacity: number), инициализирующий КАД определенного размера (capacity, положительное целое число) - метод
get(key: string), возвращающий значение по ключу (key) илиnull - метод
set(key: string, value: any), обновляющий или добавляющий значение (value) по ключу (key). При превышенииcapacityиз кэша удаляется (вытесняется) самое старое (наименее используемое) значение
Функции get и set должны выполняться за константное время O(1).
Сложность
Временная
| get | set |
|---|---|
| O(1) | O(1) |
Пространственная
O(n)
Реализация
Двусвязный список и хеш-таблица
В следующей реализации КАД мы будем использовать хеш-таблицу (см. часть 2, раздел 5) для константного (в среднем) доступа к элементам и двойной связный список (см. часть 1, раздел 2) для константного обновления и вытеснения элементов.

Начнем с реализации узла:
// data-structures/lru-cache.js // Узел class Node { constructor(key, val, prev = null, next = null) { // Ключ this.key = key // Значение this.val = val // Ссылка на предыдущий узел this.prev = prev // Ссылка на следующий узел this.next = next } }
Теперь займемся КАД:
// КАД export default class LRUCache { // Конструктор принимает емкость кэша constructor(capacity) { // Максимальный размер кэша this.capacity = capacity // Кэшированные узлы this.nodesMap = {} // Текущий размер кэша this.size = 0 // Головной узел this.head = new Node() // Хвостовой узел this.tail = new Node() } }
Метод получения элемента по ключу:
// Возвращает значение по ключу get(key) { const node = this.nodesMap[key] if (!node) return null // Обновляем "приоритет" узла this.promote(node) return node.val }
Метод добавления элемента в кэш:
// Добавляет узел в кэш set(key, val) { if (this.nodesMap[key]) { // Обновляем значение существующего узла const node = this.nodesMap[key] node.val = val this.promote(node) } else { // Добавляем новый узел const node = new Node(key, val) this.append(node) } }
Метод обновления приоритета узла:
/** * Перемещает узел в конец связного списка. * Это означает, что узел используется наиболее часто. * Это также снижает вероятность удаления такого узла из кэша */ promote(node) { this.evict(node) this.append(node) }
Метод добавления узла в конец связного списка:
// Перемещает узел в конец связного списка append(node) { this.nodesMap[node.key] = node if (!this.head.next) { // Первый узел this.head.next = node this.tail.prev = node node.prev = this.head node.next = this.tail } else { // Добавляем узел в конец const oldTail = this.tail.prev oldTail.next = node node.prev = oldTail node.next = this.tail this.tail.prev = node } // Увеличиваем текущий размер кэша this.size += 1 // Если достигнут максимальный размер кэша, // то удаляем первый узел if (this.size > this.capacity) { this.evict(this.head.next) } }
И метод удаления узла:
// Удаляет (вытесняет) узел из кэша evict(node) { delete this.nodesMap[node.key] // Уменьшаем текущий размер кэша this.size -= 1 const prev = node.prev const next = node.next // Имеется только один узел if (prev === this.head && next === this.tail) { this.head.next = null this.tail.prev = null this.size = 0 return } // Это головной узел if (prev === this.head) { next.prev = this.head this.head.next = next return } // Это хвостовой узел if (next === this.tail) { prev.next = this.tail this.tail.prev = prev return } // Это узел в середине списка prev.next = next next.prev = prev }
// Узел class Node { constructor(key, val, prev = null, next = null) { // Ключ this.key = key // Значение this.val = val // Ссылка на предыдущий узел this.prev = prev // Ссылка на следующий узел this.next = next } } // КАД export default class LRUCache { // Конструктор принимает емкость кэша constructor(capacity) { // Максимальный размер кэша this.capacity = capacity // Кэшированные узлы this.nodesMap = {} // Текущий размер кэша this.size = 0 // Головной узел this.head = new Node() // Хвостовой узел this.tail = new Node() } // Возвращает значение по ключу get(key) { const node = this.nodesMap[key] if (!node) return null // Обновляем "приоритет" узла this.promote(node) return node.val } // Добавляет узел в кэш set(key, val) { if (this.nodesMap[key]) { // Обновляем значение существующего узла const node = this.nodesMap[key] node.val = val this.promote(node) } else { // Добавляем новый узел const node = new Node(key, val) this.append(node) } } /** * Перемещает узел в конец связного списка. * Это означает, что узел используется наиболее часто. * Это также снижает вероятность удаления такого узла из кэша */ promote(node) { this.evict(node) this.append(node) } // Перемещает узел в конец связного списка append(node) { this.nodesMap[node.key] = node if (!this.head.next) { // Первый узел this.head.next = node this.tail.prev = node node.prev = this.head node.next = this.tail } else { // Добавляем узел в конец const oldTail = this.tail.prev oldTail.next = node node.prev = oldTail node.next = this.tail this.tail.prev = node } // Увеличиваем текущий размер кэша this.size += 1 // Если достигнут максимальный размер кэша, // то удаляем первый узел if (this.size > this.capacity) { this.evict(this.head.next) } } // Удаляет (вытесняет) узел из кэша evict(node) { delete this.nodesMap[node.key] // Уменьшаем текущий размер кэша this.size -= 1 const prev = node.prev const next = node.next // Имеется только один узел if (prev === this.head && next === this.tail) { this.head.next = null this.tail.prev = null this.size = 0 return } // Это головной узел if (prev === this.head) { next.prev = this.head this.head.next = next return } // Это хвостовой узел if (next === this.tail) { prev.next = this.tail this.tail.prev = prev return } // Это узел в середине списка prev.next = next next.prev = prev } }
import LRUCache from '../lru-cache' describe('LRUCache', () => { it('должен добавить/извлечь значения в/из кэша', () => { const cache = new LRUCache(100) expect(cache.get('key-1')).toBeNull() cache.set('key-1', 15) cache.set('key-2', 16) cache.set('key-3', 17) expect(cache.get('key-1')).toBe(15) expect(cache.get('key-2')).toBe(16) expect(cache.get('key-3')).toBe(17) expect(cache.get('key-3')).toBe(17) expect(cache.get('key-2')).toBe(16) expect(cache.get('key-1')).toBe(15) cache.set('key-1', 5) cache.set('key-2', 6) cache.set('key-3', 7) expect(cache.get('key-1')).toBe(5) expect(cache.get('key-2')).toBe(6) expect(cache.get('key-3')).toBe(7) }) it('должен вытеснить элементы из кэша размером 1', () => { const cache = new LRUCache(1) expect(cache.get('key-1')).toBeNull() cache.set('key-1', 15) expect(cache.get('key-1')).toBe(15) cache.set('key-2', 16) expect(cache.get('key-1')).toBeNull() expect(cache.get('key-2')).toBe(16) cache.set('key-2', 17) expect(cache.get('key-2')).toBe(17) cache.set('key-3', 18) cache.set('key-4', 19) expect(cache.get('key-2')).toBeNull() expect(cache.get('key-3')).toBeNull() expect(cache.get('key-4')).toBe(19) }) it('должен вытеснить элементы из кэша размером 2', () => { const cache = new LRUCache(2) expect(cache.get('key-21')).toBeNull() cache.set('key-21', 15) expect(cache.get('key-21')).toBe(15) cache.set('key-22', 16) expect(cache.get('key-21')).toBe(15) expect(cache.get('key-22')).toBe(16) cache.set('key-22', 17) expect(cache.get('key-22')).toBe(17) cache.set('key-23', 18) expect(cache.size).toBe(2) expect(cache.get('key-21')).toBeNull() expect(cache.get('key-22')).toBe(17) expect(cache.get('key-23')).toBe(18) cache.set('key-24', 19) expect(cache.size).toBe(2) expect(cache.get('key-21')).toBeNull() expect(cache.get('key-22')).toBeNull() expect(cache.get('key-23')).toBe(18) expect(cache.get('key-24')).toBe(19) }) it('должен вытеснить элемент из кэша размером 3', () => { const cache = new LRUCache(3) cache.set('key-1', 1) cache.set('key-2', 2) cache.set('key-3', 3) expect(cache.get('key-1')).toBe(1) expect(cache.get('key-2')).toBe(2) expect(cache.get('key-3')).toBe(3) cache.set('key-3', 4) expect(cache.get('key-1')).toBe(1) expect(cache.get('key-2')).toBe(2) expect(cache.get('key-3')).toBe(4) cache.set('key-4', 5) expect(cache.get('key-1')).toBeNull() expect(cache.get('key-2')).toBe(2) expect(cache.get('key-3')).toBe(4) expect(cache.get('key-4')).toBe(5) }) it('должен обновить узел при вызове метода `set`', () => { const cache = new LRUCache(2) cache.set('2', 1) cache.set('1', 1) cache.set('2', 3) cache.set('4', 1) expect(cache.get('1')).toBeNull() expect(cache.get('2')).toBe(3) }) it('должен обновить элементы в кэше размером 3', () => { const cache = new LRUCache(3) cache.set('key-1', 1) cache.set('key-2', 2) cache.set('key-3', 3) expect(cache.get('key-1')).toBe(1) cache.set('key-4', 4) expect(cache.get('key-1')).toBe(1) expect(cache.get('key-3')).toBe(3) expect(cache.get('key-4')).toBe(4) expect(cache.get('key-2')).toBeNull() }) it('должен обновить элементы в кэше размером 4', () => { const cache = new LRUCache(4) cache.set('key-1', 1) cache.set('key-2', 2) cache.set('key-3', 3) cache.set('key-4', 4) expect(cache.get('key-4')).toBe(4) expect(cache.get('key-3')).toBe(3) expect(cache.get('key-2')).toBe(2) expect(cache.get('key-1')).toBe(1) cache.set('key-5', 5) expect(cache.get('key-1')).toBe(1) expect(cache.get('key-2')).toBe(2) expect(cache.get('key-3')).toBe(3) expect(cache.get('key-4')).toBeNull() expect(cache.get('key-5')).toBe(5) cache.set('key-6', 6) expect(cache.get('key-1')).toBeNull() expect(cache.get('key-2')).toBe(2) expect(cache.get('key-3')).toBe(3) expect(cache.get('key-4')).toBeNull() expect(cache.get('key-5')).toBe(5) expect(cache.get('key-6')).toBe(6) }) })
Выполняем тесты:
npm run test ./data-structures/__tests__/lru-cache
Результаты:

Упорядоченная карта
Реализация, в которой используется связный список, полезна в целях обучения, поскольку позволяет понять, как достигается время выполнения O(1) операций get и set.
Однако КАД легче реализовать с помощью объекта Map, который хранит пары «ключ-значение» и запоминает порядок добавления ключей. Мы можем хранить последний используемый элемент в конце карты за счет его удаления и повторного добавления. Элемент, находящийся в начале карты, первым вытесняется из кэша. Для проверки порядка элементов можно использовать IteratorIterable, такой как map.keys().
// data-structure/lru-cache-on-map.js export default class LruCacheOnMap { // Конструктор принимает размер кэша constructor(size) { // Размер кэша this.size = size // Хранилище (по сути, сам кэш) this.map = new Map() } // Возвращает значение по ключу get(key) { const val = this.map.get(key) if (!val) return null // Обновляем "приоритет" элемента this.map.delete(key) this.map.set(key, val) return val } // Добавляет элемент в кэш set(key, val) { // Обновляем "приоритет" элемента this.map.delete(key) this.map.set(key, val) // Если кэш переполнен, удаляем первый (самый редко используемый) элемент if (this.map.size > this.size) { for (const key of this.map.keys()) { this.map.delete(key) break } } } }
// data-structure/__tests__/lru-cache-on-map.test.js import LRUCache from '../lru-cache-on-map' describe('LRUCacheOnMap', () => { it('должен добавить/извлечь значения в/из кэша', () => { const cache = new LRUCache(100) expect(cache.get('key-1')).toBeNull() cache.set('key-1', 15) cache.set('key-2', 16) cache.set('key-3', 17) expect(cache.get('key-1')).toBe(15) expect(cache.get('key-2')).toBe(16) expect(cache.get('key-3')).toBe(17) expect(cache.get('key-3')).toBe(17) expect(cache.get('key-2')).toBe(16) expect(cache.get('key-1')).toBe(15) cache.set('key-1', 5) cache.set('key-2', 6) cache.set('key-3', 7) expect(cache.get('key-1')).toBe(5) expect(cache.get('key-2')).toBe(6) expect(cache.get('key-3')).toBe(7) }) it('должен вытеснить элементы из кэша размером 1', () => { const cache = new LRUCache(1) expect(cache.get('key-1')).toBeNull() cache.set('key-1', 15) expect(cache.get('key-1')).toBe(15) cache.set('key-2', 16) expect(cache.get('key-1')).toBeNull() expect(cache.get('key-2')).toBe(16) cache.set('key-2', 17) expect(cache.get('key-2')).toBe(17) cache.set('key-3', 18) cache.set('key-4', 19) expect(cache.get('key-2')).toBeNull() expect(cache.get('key-3')).toBeNull() expect(cache.get('key-4')).toBe(19) }) it('должен вытеснить элементы из кэша размером 2', () => { const cache = new LRUCache(2) expect(cache.get('key-21')).toBeNull() cache.set('key-21', 15) expect(cache.get('key-21')).toBe(15) cache.set('key-22', 16) expect(cache.get('key-21')).toBe(15) expect(cache.get('key-22')).toBe(16) cache.set('key-22', 17) expect(cache.get('key-22')).toBe(17) cache.set('key-23', 18) expect(cache.get('key-21')).toBeNull() expect(cache.get('key-22')).toBe(17) expect(cache.get('key-23')).toBe(18) cache.set('key-24', 19) expect(cache.get('key-21')).toBeNull() expect(cache.get('key-22')).toBeNull() expect(cache.get('key-23')).toBe(18) expect(cache.get('key-24')).toBe(19) }) it('должен вытеснить элемент из кэша размером 3', () => { const cache = new LRUCache(3) cache.set('key-1', 1) cache.set('key-2', 2) cache.set('key-3', 3) expect(cache.get('key-1')).toBe(1) expect(cache.get('key-2')).toBe(2) expect(cache.get('key-3')).toBe(3) cache.set('key-3', 4) expect(cache.get('key-1')).toBe(1) expect(cache.get('key-2')).toBe(2) expect(cache.get('key-3')).toBe(4) cache.set('key-4', 5) expect(cache.get('key-1')).toBeNull() expect(cache.get('key-2')).toBe(2) expect(cache.get('key-3')).toBe(4) expect(cache.get('key-4')).toBe(5) }) it('должен обновить узел при вызове метода `set`', () => { const cache = new LRUCache(2) cache.set('2', 1) cache.set('1', 1) cache.set('2', 3) cache.set('4', 1) expect(cache.get('1')).toBeNull() expect(cache.get('2')).toBe(3) }) it('должен обновить элементы в кэше размером 3', () => { const cache = new LRUCache(3) cache.set('key-1', 1) cache.set('key-2', 2) cache.set('key-3', 3) expect(cache.get('key-1')).toBe(1) cache.set('key-4', 4) expect(cache.get('key-1')).toBe(1) expect(cache.get('key-3')).toBe(3) expect(cache.get('key-4')).toBe(4) expect(cache.get('key-2')).toBeNull() }) it('должен обновить элементы в кэше размером 4', () => { const cache = new LRUCache(4) cache.set('key-1', 1) cache.set('key-2', 2) cache.set('key-3', 3) cache.set('key-4', 4) expect(cache.get('key-4')).toBe(4) expect(cache.get('key-3')).toBe(3) expect(cache.get('key-2')).toBe(2) expect(cache.get('key-1')).toBe(1) cache.set('key-5', 5) expect(cache.get('key-1')).toBe(1) expect(cache.get('key-2')).toBe(2) expect(cache.get('key-3')).toBe(3) expect(cache.get('key-4')).toBeNull() expect(cache.get('key-5')).toBe(5) cache.set('key-6', 6) expect(cache.get('key-1')).toBeNull() expect(cache.get('key-2')).toBe(2) expect(cache.get('key-3')).toBe(3) expect(cache.get('key-4')).toBeNull() expect(cache.get('key-5')).toBe(5) expect(cache.get('key-6')).toBe(6) }) })
Выполняем тесты:
npm run test ./data-structures/__tests__/lru-cache-on-map
Результаты:

На сегодня это все, друзья. Увидимся в следующей части.
Новости, обзоры продуктов и конкурсы от команды Timeweb.Cloud — в нашем Telegram-канале ↩

ссылка на оригинал статьи https://habr.com/ru/articles/838794/
Добавить комментарий