Привет, Хабр! Меня зовут Алексей Топчий, я уже более 20 лет работаю в IT. Прошёл все уровни: бэкенд, фронтенд, фулстек со множеством языков и технологий. В СберТехе занимался Единой фронтальной системой, в Яндексе участвовал в стартапе, связанном с FMCG. Сейчас занимаюсь сервисом ценообразования в сети магазинов «Пятёрочка» (X5 Group).
В этой статье я приоткрываю тайну бэк-офиса современного магазина и делюсь опытом, как мы развиваем программный комплекс, что интересного при этом происходит, с какими проблемами сталкиваемся и как их решаем. Статья будет полезна архитекторам, техническим менеджерам и всем, кто интересуется преобразованием корпоративных IT-ландшафтов.

Алексей Топчий
Руководитель разработки системы ценообразования в X5 Tech, ментор программы онлайн-бакалавриата «Разработка IT-продуктов и информационных систем» в Нетологии
Как выглядит инфраструктура современного магазина и почему это зоопарк
В моём детстве магазины выглядели как-то так ↓


Сейчас магазины выглядят совершенно по-другому:

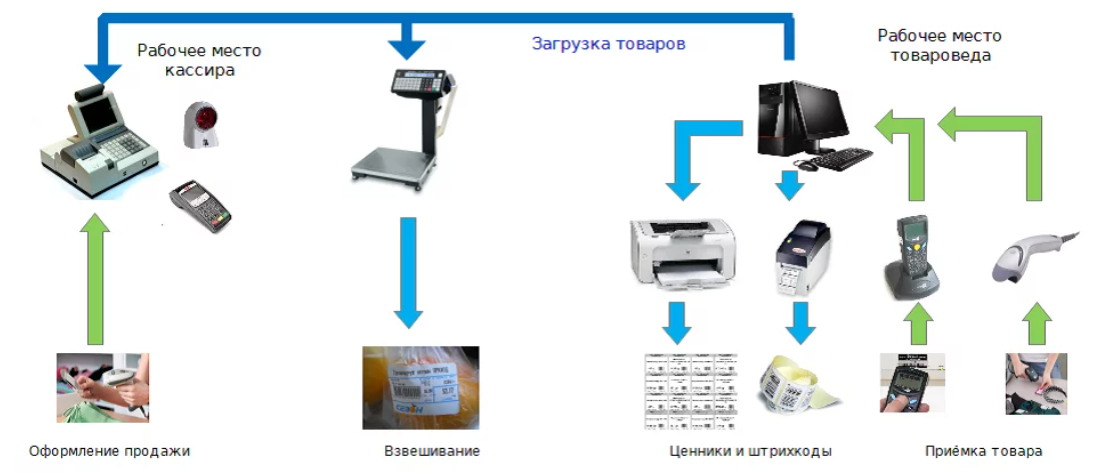{kind=link}
Основным юнитом служит сервер, на котором располагается БД и сервисы обеспечения магазина: товародвижение, ценники, маркировка и прочее. Вокруг сервера собрана сеть, в которую подключены не только кассы, но и терминалы сверки данных (ТСД) — похожие на смартфон устройства с лазером, которым сотрудник пикает по ценнику, — прайс-чекеры (висят на стенах и при поднесении к ним штрихкода говорят человеческим голосом: «Цена по карте лояльности — сто пятьдесят девять рублей девяносто девять копеек»), кассы самообслуживания, весы и так далее. Сеть магазина соединена с облаком, в котором крутятся сервисы публикации цен, учёта остатков и движения денег, расчёта механик скидок по картам лояльности и многое другое. Всё вышеописанное и называется бэк-офисом магазина.
Сервер магазина выполняет много ресурсоёмких операций: сравнивает поступающие из облака цены с имеющимися и печатает новые ценники, синхронизирует информацию о локальных остатках товаров магазина с глобальным облачным хранилищем, учитывает продажи — уменьшает остаток товара на балансе магазина и увеличивает итог по кассе.
Ранее наш бэк-офис был «монолитом», то есть одной большой программой, включающей в себя все функции для работы магазина. Но монолит сложно развивать и обновлять на всех магазинах. Разные функции внутри бэк-офиса могут мешать друг другу, вызывать конфликты при доработке и обновлении.
Так у нас родилась гипотеза, что оптимизировать все процессы можно с помощью перехода на микросервисную архитектуру и облачные решения. По нашей задумке, это должно было уменьшить затраты на обслуживание, повысить гибкость и скорость внедрения новых функций, открыть перспективы для дальнейшего серьёзного улучшения функциональности магазинов. Именно эту гипотезу мы и тестировали.
Что не так с монолитом бэк-офиса магазина, или Зачем мы распилили
Монолитная архитектура в противовес микросервисной обладает рядом недостатков:
-
Только горизонтальное масштабирование. Мы можем лишь «накинуть железа»: добавить памяти, процессоров или диск на сервер, где крутится система.
-
Невозможность масштабирования отдельной функции. Если функция печати ценников должна обрабатывать несколько тысяч запросов одновременно, мы не можем выделить ей больше ресурсов, чем функции проверки акцизной марки, которой нужно обработать несколько запросов в час.
-
Общий даунтайм всей системы при раскатке любой фичи. Если мы меняем только значок на одном виде ценника (например, жёлтый ценник «Промо») и добавляем туда процент скидки, то нам нужно: заблокировать сервер для пользователей, обновить всю систему, запустить её, проверить её работоспособность, разблокировать сервер и снова пустить пользователей.
-
Высокая вероятность поломать что-то рядом с изменяемой функцией. Из-за единой кодовой базы многие функции переиспользуются (это хороший тон): в частности, функция округления цены или преобразования целого значения цены (100.00) к дробной (99.99). Например, для новых ценников мы добавили в эту функцию проверку, что цена не ниже 50 рублей. Печать ценников проверили: всё работает хорошо. Но эта же функция используется при проверке цены прайс-чекером, а его работу мы не проверили. Так, после раскатки обновления прайс-чекеры перестали работать для цен ниже 50 рублей.
Кроме того, сервер в каждом магазине — а их около 25 тысяч — сто́ит немалых денег. Синхронизация и поддержка 25 тысяч экземпляров монолита — сложная задача. Где-то электричество отключили, где-то произошёл технический или сетевой сбой, — обновить версию монолита на всех магазинах синхронно получается редко. Раскатка идёт волнами по 10, 100, 1 000 и более магазинов. При этом от скорости обновления зависит длительность раскатки и стабилизации каждой волны. Если мы обновляем монолит за час — значит, даунтайм на волне среднего размера (это примерно несколько тысяч магазинов) будет равен примерно часу или чуть больше. Если же обновление занимает пять часов, то можно и за ночь не уложиться.
Важнейший показатель для бизнеса в аспекте IT-сервиса — time to market (TTM), то есть длительность периода от заказа новой функции до момента, когда она будет работать во всех магазинах. Например, нужен новый вид ценника (на листе А4 для размещения над витриной). Заказали 1 августа, разработку закончили 18 августа, протестировали до 31 августа, раскатили десятью волнами — по неделе каждая — до 30 сентября. Итого TTM = 30 сентября минус 1 августа = 2 месяца, или 60 дней. TTM сильно зависит от объёма новой функциональности: например, добавить новый тип бумажного ценника — 2 месяца, а добавить поддержку электронных ценников — 6 месяцев. Но бизнесу важно, чтобы TTM для типовых понятных доработок сокращался. То есть в 2024 году TTM для нового типа ценника был 60 дней, а в 2025 году — уже 40 дней. Это на 30% меньше.
Однако при разработке в монолитной архитектуре TTM увеличивается. Это происходит за счёт ряда факторов:
-
Синхронизация релизов. Разные команды делают фичи разного объёма, а выкатывать их по одной нецелесообразно (помним про волны и месяц на полную раскатку). Поэтому выкатку фич разных команд принято синхронизировать и собирать в релизы. Длительность релиза будет равна максимальному TTM из входящих в него фич. То есть если делаем пять маленьких фич по 60 дней и большую — на 120 дней, то в таком случае TTM релиза — 120 дней.
-
Увеличение нагрузки на команды при интеграционном тестировании. Многое меняется в разных частях монолита, нужно собрать все части, устранить конфликты функциональности, проверить доработанную функциональность, провести регресс и нагрузочное тестирование. Координация такого релиза подвластна только очень стрессоустойчивым менеджерам.
-
Синхронизация планов команд и бэклогов. Для изменения формата одного типа ценников нужно доработать механизм промомеханик, а у них бэклог на два года вперёд расписан. Без доработки их системы вносить изменения в сервисе ценообразования и логистики ценников бессмысленно.
И это только задачи, влияющие на прибыль и бизнес в целом. А ведь есть ещё технический долг, задачи развития, технологический роадмап. Для реализации всего этого нужно либо делать технический релиз: откладываем бизнес-фичи и все команды ждут нас, — либо размазывать технические задачи по обычным релизам, увеличивая их TTM. При таком количестве экземпляров наблюдаем большой разброс в конфигурациях. Да, мы стремимся к унификации, но где-то серверы новее, где-то память другого типа, где-то старая ОС. Подстраиваться под этот зоопарк сложно.
Как в теории выглядел переход с монолита на микросервисы
Переход на микросервисную архитектуру потребовал тщательной подготовки и планирования.
Во-первых, мы определили, чего хотим от этого перехода:
-
Получить возможность гибко масштабировать экосистему магазина за счёт увеличения или уменьшения количества инстансов нужных сервисов. Например, пришло обновление цен → увеличиваем количество экземпляров сервиса обработки цен. Пришла фура с товаром → наращиваем экземпляры сервиса товародвижения. Вечерний наплыв покупателей → масштабируем сервис учёта остатков и суммирования по кассе.
-
Упростить раскатку независимых микросервисов: чтобы каждый микросервис разрабатывался, тестировался и деплоился независимо от других, а синхронизация нужна была только при интеграционном тестировании микросервисов.
-
Сократить TTM. Мы хотели, чтобы длина релиза не была равна трудоёмкости реализации самой большой фичи.
-
Получить возможность распределённого размещения: чтобы экземпляры микросервисов можно было размещать на разных серверах и даже на других устройствах, например кассах.
Во-вторых, мы выяснили, какие именно сервисы можно выделить из монолита и сделать независимыми. Определив список сервисов, мы начали с сервиса ценообразования. Именно он отвечает за печать ценников, активацию цен на кассах, проверку ценников терминалами сверки данных, проверку цены товара прайс-чекерами.
Сервис цен (так мы его назвали) включал в себя БД, бэкенд и фронтенд.
Вот так выглядел наш план:

-
Реализовываем микросервис работы с ценами. Пишем его с нуля на Spring Boot. Функциональность микросервиса с точки зрения пользователя не должна отличаться от текущего варианта.
-
Тестируем и раскатываем пилот нового микросервиса. Разворачиваем его на том же сервере в магазине рядом с монолитом. Осуществляем пилот в несколько волн: первая — три магазина, находящиеся на реконструкции и без реальных покупателей внутри, вторая — десять небольших магазинов, третья — сто обычных магазинов.
-
Даём устояться. Несколько недель магазины работают в обычном режиме, группа поддержки усилена командой, выполняющей пилот, все инциденты решаются в ускоренном режиме. Новая конфигурация на пилотной группе стабилизируется до состояния готовности к раскатке на всю сеть магазинов.
-
Стабилизированную сборку запускаем в тираж. Обычная история, как с монолитом раньше: тиражируем волнами по 100, 1 000 и 3 000 магазинов. В этот раз все магазины фиксируем по конкретным группам (волнам) и распределяем волны по датам. Формируем таким образом наш календарный план.
-
После тиража стабилизируем новую конфигурацию на всей сети. Даём устояться несколько недель, анализируем показатели сквозного процесса логистики цен, исправляем проблемы, проявившиеся на большом масштабе.
После этого можно формировать план дальнейшей трансформации монолита: выделять остальные сервисы, их пилот и тираж, а также деинсталлировать монолит после тиража последнего сервиса.
Как это было на самом деле, или Вся правда при переходе с монолита на микросервисы, когда у тебя сеть из десятков тысяч магазинов
В теории всё выглядит несложно, но на практике всплыли нюансы. Конечно, мы столкнулись с рядом сложностей.
Первые проблемные звоночки (спойлер: это были цветочки)
Обычно при развёртывании решения уже в одном магазине возникает ряд проблем на локальном инстансе ↓
Увеличение потребления ресурсов сервера. Раньше ресурсы сервера потреблял только монолит, теперь же их утилизировали ещё и микросервисы, располагающиеся рядом с монолитом.
➡️ Поэтому мы провели базовую оптимизацию монолита, глубокую оптимизацию микросервиса цен. Общее потребление памяти даже снизилось.
Сложности в реализации фронтенда. Фронтенд в монолите был написан на одной из вариаций Java-шаблонизатора. Контент генерировался на сервере и рендерился браузером у пользователей.
➡️ При выделении микросервисов было решено переписать клиента на JavaScript (более отзывчивый и динамичный интерфейс), чтобы часть нагрузки (весь интерактив) перешла на клиентские машины в браузер. Но в команде, отлично знакомой с функциональностью сервиса и технологиями бэкенда на Java, отсутствовала компетенция реализации фронтенда на JavaScript. Ребята изучали технологию на ходу — это замедляло и реализацию, и исправление ошибок.
Вариативность окружения и конфигураций. Монолит развивался много лет. На таких масштабах с десятками тысяч экземпляров сложно синхронизировать конфигурации серверов, окружение, версии ОС и вспомогательных средств. Сейчас наша дирекция магазинных систем развивает это направление, и есть инструменты, которые синхронизируют параметры конфигураций серверов в магазинах и позволяют менять множество параметров одной кнопкой, а также выводят много параметров для мониторинга серверов и вспомогательных систем. Но на момент начала раскатки эти средства только частично поддерживали новый формат конфигурации, так как у микросервиса другие параметры и окружение несколько отличается.
➡️ Поэтому команде управления конфигурациями пришлось отложить свои доработки и подключиться к раскатке, чтобы реализовать автоматизированные средства по управлению новыми параметрами серверов и окружения. Устранив все проблемы, обнаруженные на нескольких экземплярах в первой волне пилота, мы осторожно начали раскатку на большее количество магазинов: 100, 1 000 и 3 000. Но на таких масштабах выявились узкие места массовой установки, большей вариативности конфигураций и даже проблемы смежных систем.
Настоящие проблемы масштабирования на сеть из десятков тысяч магазинов
В любых проектах такого масштаба есть риск столкнуться с большими сложностями на тираже, которые станут препятствием для работоспособности бизнес-процессов. В этом случае тираж останавливается и новая функциональность подлежит откату.
Обычно мы рассчитывали размер волны таким способом, чтобы нагрузка росла плавно. Период стабилизации между волнами был равен неделе, но мог увеличиваться при большом количестве дефектов.
И в этот раз мы ожидали, что нашей основной сложностью станет растущий поток ошибок и увеличение трудоёмкости переустановок и обновлений. На деле же проблемы оказались другими.
Сложность с отправкой всех ценников
При обновлении бэк-офиса магазина хранение ценников переезжало в БД нового сервиса цен. Можно было сделать миграцию данных в каждом магазине. Но процесс миграции выполняется разово, и обычно на его качество, производительность и другие характеристики смотрят сквозь пальцы. То есть делают кучу костылей, которые после миграции можно выкинуть. Костыли на большом объёме магазинов могли посыпаться, и нас завалило бы горой дефектов. Поэтому от этого способа мы отказались.
Решили начальную заливку данных делать из облачной системы управления ценами: просто отправить ценники на весь ассортимент без команды на печать. Звучало просто. Однако при отправке полного объёма данных, то есть всех ценников, — мы это называем «фулл-выгрузка» или «выгрузка фулла» — на первых волнах сильно выросла нагрузка на интеграционный слой. Объём данных фулла — примерно 10 000 ценников, тогда как ежедневная выгрузка содержит от 20 до 200 ценников, максимально 1 000, но очень редко.
Объёмы перегоняемых данных выросли в 100 раз: если на 10 магазинах это было не так заметно, то на 1 000 магазинов… По сути, весь ежедневный обычный объём выгрузки цен на 25 тысяч магазинов эквивалентен 250 магазинам при фулл-выгрузке. То есть на первой же волне с 1 000 магазинов объём интеграционного слоя увеличился в четыре раза по сравнению с полным продуктовым объёмом. Конечно, в промышленные системы такого класса закладывают запас в 10 и более раз, но тут в пике на волне из 3 000 магазинов получилась бы нагрузка уже в 12 раз больше.
Мы решили перестраховаться и провели нагрузочное тестирование на объёме, превышающем максимальный на самой большой волне (из 3 000 магазинов) в 2 раза (нагрузка ×24). Так мы выявили узкие места в нескольких системах, устранили их все и продолжили тираж.
Увеличение количества установок
Установить новый сервис на три магазина просто, но одновременная установка на сотню или тысячу магазинов может быть сложна. Если что-то пошло не так, нужно откатить установку, понять причину, устранить её и установить сервис заново. На тысячах магазинов задача очень усложняется. Если делать всё руками, нужны тысячи сотрудников поддержки: по одному на установку, — чтобы успеть обновить все магазины текущей волны за ночь. Столько сотрудников поддержки нет в штате, и обеспечить одновременно такое количество — очень дорого. Поэтому нужна автоматизация.
Команда поддержки автоматизировала всё: от синхронизации параметров Java-машины до открытия портов для обмена информацией. Это увеличило срок раскатки первых волн, но обеспечило стабильность тиражирования на больших объёмах.
Проблема с обработкой статусов и ответов от магазинов
При масштабировании распределённых систем узких мест бывает очень много, и возникать они могут там, где не ждёшь. Данные можно представить в виде потока воды, то есть где-то на его пути может возникнуть узкое место или засор. Мы оптимизируем этот участок: расширяем русло и расчищаем засор, — но затем поток упирается в следующее подобное место. Каждое из узких мест может быть в разных системах и, не обнаружив первое, нельзя обнаружить и следующие.
В нашем случае заключительным узким местом стал облачный сервис приёма ответов от магазинов. Каждый магазин присылает по каждому ценнику статус, когда он напечатан и цена отправлена на кассу. Этих ответов столько же, сколько и новых цен: несколько миллионов ежедневно при обычной работе и до сотен миллионов при выгрузке фулла. Kafka, который служил транспортом для этих ответов, легко справляется с такой нагрузкой. Сервис-подписчик, который достаёт ответы, — тоже, ведь ему можно выделить десятки экземпляров в облаке на время его работы, а когда все ответы будут обработаны — схлопнуть его до одного экземпляра.
Узким местом оказалась наша архитектура, основанная на БД ClickHouse®. Несмотря на то что она отлично справляется с обработкой терабайт данных, у неё есть слабое место: много вставок данных маленькими порциями. Именно такой сценарий и сработал при обработке ответов: сотни потоков вставляли по несколько тысяч записей каждый. Это горлышко расширили механизмом агрегации ответов: сервис-подписчик собирал много пакетов с ответами в один и вставлял записи миллионами. Обработка ответов стала занимать 30 минут вместо десяти часов.
Трудности с производительностью конвертера
Формат обмена данными (JSON-пакет с ценами) для нового сервиса цен отличается от формата обмена с текущим бэк-офисным монолитом. С момента старта пилота у нас появилось два потока обмена: магазины со старым бэк-офисным монолитом и магазины с новым сервисом цен. Постепенно на протяжении пилота и тиража количество магазинов со старым форматом обмена уменьшается, а количество магазинов, поддерживающих новый формат, растёт.
Чтобы поддержать оба потока, мы сделали конвертер из нового формата в старый. Этот конвертер должен был работать до окончания тиража, у него была база магазинов и информация о формате обмена с каждым. Для магазинов с новым сервисом цен конвертер отправлял посылки без изменений, для магазинов с монолитом старого формата преобразовывал посылку. После окончания тиража этот конвертер не нужен, но на старте, когда количество магазинов старого формата максимальное, конвертер должен был обработать огромный объём информации. С этим были проблемы. Снова всё оптимизировали и увеличили пропускную способность конвертера с 50 RPS до 800+ RPS.
Локальные ошибки сервиса цен
Периодически во время пилота и тиража возникали инциденты в некоторых магазинах: то не печатались ценники, то приходила слишком большая переоценка (1 000+ новых ценников), то отваливался прайс-чекер или ТСД, а иногда на некоторых магазинах возникали блокировки в БД или Out of memory, которая перезагружала серверы. Чем больше магазинов становилось в очередной волне, тем больше проблем вылезало. Команда поддержки героически разбирала каждый случай и исправляла дефекты. Пару раз казалось, что количество ошибок критическое и тираж придётся остановить, но в итоге всё получилось.
В общем, наши изначальные ожидания не оправдались и сложности возникли не там, где мы предполагали. Но несмотря на все трудности, отменять тираж и откатывать функциональность не пришлось. Мы пересмотрели сроки тиража и скорректировали план по количеству магазинов в каждой волне. В целом тираж прошёл успешно.
Наши выводы от перехода с монолита на микросервисы и перспективы, которые нам открылись
Внедрение микросервисной архитектуры в систему управления магазином — это сложный, но перспективный шаг. Он требует тщательной подготовки, анализа текущей архитектуры и поэтапного внедрения микросервисов. Однако результаты этого перехода могут значительно повысить эффективность работы магазина и дать огромный экономический эффект.
Сейчас вся сеть «Пятёрочка» переведена на новый сервис цен.

Пилотная установка, тираж на всю сеть и стабилизация заняли более полугода, но это всё равно очень быстро, так как с нуля внедрить новую функциональность в 25 тысяч точек — масштабная задача. Осталось перевести на новый сервис сети «Перекрёсток» и «Чижик». Это будет значительно проще, так как:
-
количество магазинов в этих сетях на порядок меньше,
-
функциональность стабилизирована и работает уже несколько месяцев в продуктивном окружении без серьёзных инцидентов.
Этот амбициозный проект подсветил узкие места нашей инфраструктуры, процессов разработки и распространения версий ПО магазинов, позволил оптимизировать их. Слаженная работа команды и грамотное управление обеспечило соблюдение сроков и успех проекта в целом. Главное достижение проекта — доказательство того, что распил монолита в магазине на несколько сервисов возможен.
В этом скрыт колоссальный потенциал:
-
после выноса всех функциональных сервисов мы можем строить распределённый магазин: унести часть сервисов в облако, остальные оставить на сервере или даже убрать сервер совсем и разместить сервисы на одной из касс (это тоже своего рода серверы, только маленькие);
-
развивать каждый сервис магазина можно независимо, руководствуясь экономической эффективностью и потребностями бизнеса.
Стратегически выгодно все сервисы магазина вынести в облако. Это позволит напрямую сэкономить на мощностях 20–40%, так как облачные серверы дешевле bare metal. Также можно реализовать динамическую балансировку нагрузки: магазины находятся в разных часовых поясах и многие из них ночью простаивают, — в этом случае можно сэкономить ещё 10–15%. Это огромные цифры, речь о миллиардах рублей. Цель хорошая, хоть и не без ограничений, но это уже совсем другая история 😉
P. S. Минутка благодарности. Проект состоялся благодаря усилиям замечательных менеджеров:

Владимир Казарезов
Ведущий руководитель проектов, X5 Tech

Павел Кокорев
Руководитель направления развития платформы, X5 Tech
Спасибо, что дочитали 🙂 Надеюсь, было интересно и полезно. На все вопросы — в рамках приличий, соблюдая коммерческую тайну и NDA, — готов ответить в комментариях.
Чтобы расти, нужно выйти из привычной зоны и сделать шаг к переменам. Можно изучить новое, начав с бесплатных курсов и занятий:
ссылка на оригинал статьи https://habr.com/ru/articles/857026/
Добавить комментарий