Это перевод статьи от Philipp Acsany
Большинство современных веб-приложений работают на основе REST API — методологии, позволяющей разработчикам отделить разработку пользовательского интерфейса (FrontEnd) от разработки внутренней серверной логики (BackEnd), а пользователи получают интерфейс с динамически подгружаемыми данными. В этой серии из трех частей вы создадите REST API с помощью веб-фреймворка Flask.
В первой части вы создали базовый проект Flask и добавили конечные точки, которые вы подключите к базе данных SQLite по ходу текущей статьи. Вы также продолжите дополнять свой API новыми возможностями, для которых создадите аннотации с помощью Swagger UI API.
В первой части вы использовали Flask и Connexion для создания REST API, предоставляющего операции CRUD для словаря в памяти под названием PEOPLE. Вы узнали, как модуль Connexion позволяет создавать REST API и интерактивную документацию.
В этой второй части серии вы узнаете, как:
— Использовать SQL-инструкции в Python
— Настраивать базу данных SQLite для вашего проекта Flask
— Использовать SQLAlchemy для хранения объектов Python в базе данных
— Работать с базой данных через REST API
— Сериализовывать и десериализовывать JSON в объекты Python через Marshmallow
После завершения второй части этой серии вы перейдете к третьей части, где расширите функциональность REST API для работы с открытками для персонажей.
Техзадание
Создать приложение для управления открытками персонажам, от которых вы можете получить подарки в течение года. Вот эти сказочные лица: Tooth Fairy (Зубная фея), Easter Bunny (Пасхальный кролик) и Knecht Ruprecht (Кнехт Рупрехт).
В идеале вы хотите быть в хороших отношениях со всеми тремя из них, вот почему вы будете отправлять им открытки, чтобы увеличить шансы получить от них ценные подарки.
Во второй части этой серии вы улучшите бэкенд вашего приложения, добавив базу данных для хранения информации, таким образом, вы сохраните её даже при перезапуске приложения. С помощью Swagger UI вы сможете взаимодействовать с REST API через веб-интерфейс, производить операции с данными и контролировать результаты этих операций.
План части 2
В первой части этой серии вы работали со словарем PEOPLE для хранения данных. Список выглядел следующим образом:
PEOPLE = { "Fairy": { "fname": "Tooth", "lname": "Fairy", "timestamp": "2022-10-08 09:15:10", }, "Ruprecht": { "fname": "Knecht", "lname": "Ruprecht", "timestamp": "2022-10-08 09:15:13", }, "Bunny": { "fname": "Easter", "lname": "Bunny", "timestamp": "2022-10-08 09:15:27", } }Эта структура данных была полезна для быстрого запуска вашего проекта. Однако любые данные, которые вы добавляли с помощью REST API в словарь PEOPLE, были утеряны при перезапуске приложения.
В этой части вы будете переводить свою структуру данных PEOPLE в таблицу базы данных, которая будет выглядеть следующим образом:
|
id |
lname |
fname |
timestamp |
|
1 |
Fairy |
Tooth |
2022-10-08 09:15:10 |
|
2 |
Ruprecht |
Knecht |
2022-10-08 09:15:13 |
|
3 |
Bunny |
Easter |
2022-10-08 09:15:27 |
В этой части руководства вы не будете вносить никаких изменений в конечные точки REST API. Но изменения, которые вы внесете в бэкэнд, будут значительными, и вы получите гораздо более универсальную кодовую базу, которая поможет масштабировать ваш проект Flask в дальнейшем.
Поехали!
В этой статье вы доработаете проект Flask REST API и подготовите его к следующим шагам в этой статье.
Для преобразования сложных типов данных в типы данных Python и обратно вам понадобится сериализатор, вы будете использовать Flask-Marshmallow. Flask-Marshmallow использует внешний сериализатор Marshmallow и предоставляет дополнительные функции при работе с Flask.
Перед тем, как начать
В идеале вы выполнили первую часть этого руководства, прежде чем продолжить эту вторую часть, которую вы сейчас читаете.
Прежде чем продолжить обучение, убедитесь, что структура вашего проекта (после прохождения части 1) выглядит следующим образом:
rp_flask_api/ ├── templates/ │ └── home.html ├── app.py ├── people.py └── swagger.ymlДобавление зависимостей
Прежде чем продолжить работу над проектом Flask, хорошей идеей будет пересоздать и активировать виртуальную среду. Таким образом, вы установите все зависимости проекта не на всю систему, а только в виртуальную среду вашего проекта.
Если в папке вашего приложения присутствует папка venv с виртуальным окружением, удалите ее, чтобы установить зависимости заново. Потом выберите свою операционную систему ниже и используйте команды создания и первоначальной настройки виртуальной среды:
-
Windows
python -m venv venv .\venv\Scripts\activate-
Linux + macOS
python -m venv venv source venv/bin/activateС помощью команд, показанных выше, вы создаете и активируете виртуальную среду с именем venv, используя встроенный модуль Python venv. Название виртуального окружения в скобочках (venv) перед приглашением указывают на то, что вы успешно активировали виртуальную среду.
Далее установите зависимости, для этого создайте в основной папке проекта файл requirements.txt:
# requirements.txt connexion[Flask]==3.1.0 connexion[uvicorn]==3.1.0 flask-marshmallow==1.2.1 Flask-SQLAlchemy==3.1.1 marshmallow-sqlalchemy==1.1.0 swagger_ui_bundle==1.1.0и запустите установку необходимых пакетов, указанных в этом файле:
(venv) $ pip install -r requirements.txtFlask-Marshmallow работает с библиотекой marshmallow, который обеспечивает сериализацию и десериализацию объектов Python, входящими и выходящими из вашего REST API для первода в/из JSON-формата. Marshmallow преобразует экземпляры классов Python в JSON-объекты и обратно.
SQLAlchemy предоставляет объектно-реляционную модель (ORM) — метод сохранения объектов Python в записях базы данных. Это позволяет использовать непосредственно объекты Python для представления данных в базе данных и не беспокоиться о том, как данные объекты будут в ней храниться.
Проверьте работоспособность вашего проекта
Выполнив указанные выше шаги, вы можете убедиться, что ваше приложение Flask работает без ошибок. Выполните следующую команду в каталоге, содержащем файл app.py:
(venv) $ python app.pyПри запуске этого приложения веб-сервер запустится на порту 8000, который является портом по умолчанию, используемым Flask. Если вы откроете браузер и перейдете по адресу http://localhost:8000, вы должны увидеть Hello, World!:

Инициализация базы данных
В настоящее время вы храните данные своего проекта Flask в словаре. Такое хранение данных не является постоянным — это означает, что любые изменения данных теряются при перезапуске приложения Flask. Кроме того, структура вашего словаря не идеальна.
В этом разделе вы добавите соответствующую базу данных в свой проект Flask, чтобы исправить эти недостатки.
Текущая структура данных
В настоящее время вы храните свои данные в словаре PEOPLE, описанном в файле people.py. Структура данных выглядит следующим образом в коде:
# people.py # ... PEOPLE = { "Fairy": { "fname": "Tooth", "lname": "Fairy", "timestamp": get_timestamp(), }, "Ruprecht": { "fname": "Knecht", "lname": "Ruprecht", "timestamp": get_timestamp(), }, "Bunny": { "fname": "Easter", "lname": "Bunny", "timestamp": get_timestamp(), } } # ...Изменения, которые вы внесете в программу, переместят все данные в таблицу базы данных. Это означает, что данные будут сохраняться на вашем диске и будут существовать между запусками программы app.py.
Концепция таблицы базы данных
Концептуально вы можете представить таблицу базы данных как двумерный массив, где строки являются записями, а столбцы — полями в этих записях.
Таблицы базы данных обычно имеют автоматически увеличивающееся целочисленное значение в качестве ключа, нумерующего каждую строку. Это называется первичным ключом. Каждая запись в таблице будет иметь первичный ключ, значение которого будет уникальным во всей таблице. Наличие первичного ключа, независимого от данных, хранящихся в таблице, дает вам свободу изменять любое другое поле в строке.
Вы собираетесь следовать соглашению базы данных об именовании таблицы, как названия хранящихся данных в единственном числе, поэтому таблица будет называться person.
Перевод структуры PEOPLE в таблицу базы данных с именем person будет выглядеть следующим образом:
|
id |
lname |
fname |
timestamp |
|
1 |
Fairy |
Tooth |
2022-10-08 09:15:10 |
|
2 |
Ruprecht |
Knecht |
2022-10-08 09:15:13 |
|
3 |
Bunny |
Easter |
2022-10-08 09:15:27 |
Каждый столбец в таблице именован следующим образом:
-
id: Поле первичного ключа для каждого персонажа -
lname: Фамилия персонажа -
fname: Имя персонажа -
timestamp: Отметка времени последнего изменения
После того, как эта концепция базы данных будет реализована, пора ее создать.
Создайте базу данных
Вы собираетесь использовать SQLite в качестве движка базы данных для хранения данных PEOPLE. SQLite — это широко используемая система управления реляционными базами данных (СУБД), которой не нужен сервер SQL для работы.
В отличие от других движков баз данных SQL, SQLite работает с одним файлом для поддержания всех функций базы данных. Поэтому для использования базы данных программе нужно просто знать, как читать и записывать в файл SQLite.
Встроенный модуль Python sqlite3 позволяет вам взаимодействовать с базами данных SQLite без каких-либо внешних пакетов. Это делает SQLite особенно полезным при запуске новых проектов на Python.
Создайте файл Python create_db.py для создания и первоначального заполнения базы данных SQLite people.db:
# create_db.py import sqlite3 conn = sqlite3.connect("people.db") print("Database created and opened successfully") # создание таблицы с заданными полями columns = [ "id INTEGER PRIMARY KEY", "lname VARCHAR UNIQUE", "fname VARCHAR", "timestamp DATETIME", ] create_table_cmd = f"CREATE TABLE person ({','.join(columns)})" conn.execute(create_table_cmd) print("Table created successfully") # записываемые в базу данных персонажи people = [ "1, 'Fairy', 'Tooth', '2022-10-08 09:15:10'", "2, 'Ruprecht', 'Knecht', '2022-10-08 09:15:13'", "3, 'Bunny', 'Easter', '2022-10-08 09:15:27'", ] for person in people: insert_cmd = f"INSERT INTO person VALUES ({person})" conn.execute(insert_cmd) conn.commit() print("Records created successfully") # проверка: вывод данных из таблицы базы данных cur = conn.cursor() cur.execute("SELECT * FROM person") people = cur.fetchall() for person in people: print(person)Запустите файл create_db.py для создания и первичного заполнения базы данных:
(venv) $ python create_db.pyПосле запуска в папке вашего проекта появится файл базы данных people.db, с таблицей person и данными персонажей. *этот .db-файл и данные в нём возможно изменять и в других редакторах БД с удобным графическим интерфейсом, типа Database Browser или DB Browser for SQLite.
В нашем коде:
-
Импортируется стандартный модуль
sqlite3для работы с БД SQLite. -
Создается файл базы данных
people.dbв текущем каталоге. -
С помощью запуска SQL-инструкции
CREATE TABLE person (...)в базе данных создается таблица person. -
С помощью запуска SQL-инструкции
INSERT INTO person VALUE (...)в таблицу добавляются значения. -
С помощью запуска SQL-инструкции
SELECT * FROM personиз таблицы получаются все значения и выводятся на печать построчно.
В приведенной выше программе оператор SQL представляет собой строку, которая передается непосредственно в базу данных для выполнения. В этом учебном случае это не будет большой проблемой, поскольку SQL-инструкции исполняются полностью под контролем программы. Однако, REST API проекта будет получать на вход строку, вводимую пользователем из веб-приложения и используемую для создания SQL-запросов. Это может сделать ваше приложение уязвимым для атаки, называемой SQL-инъекция.
Разверните раздел ниже, чтобы узнать, как это происходит:
Little Bobby Tables: поучительная история
Как вы помните из первой части, конечная точка REST API для получения одного персонажа из словаря PEOPLE выглядит следующим образом:
GET /api/people/{lname}Это означает, что ваш API ожидает переменную lname на конечной позиции в URL-адресе, который он использует для поиска этого персонажа. Код Python для SQLite можно преобразовать следующим образом:
lname = "Fairy" cur.execute(f"SELECT * FROM person WHERE lname = '{lname}'")Приведенный выше фрагмент кода делает следующее:
-
В строке 1 устанавливает переменную
lnameв значение Fairy. Это будет происходить из конечного значения из URL-адреса REST API. -
В строке 2 использует форматирование строк Python для создания строки SQL и ее выполнения.
Значение переменной lname может быть любым, переданным пользователем, соответственно, строка SQL-инструкции, после форматирования, выглядит следующим образом:
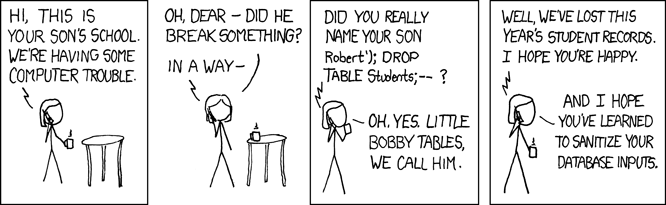
SELECT * FROM person WHERE lname = 'Fairy'Когда этот SQL код выполняется, он ищет в таблице людей запись, в которой фамилия персонажа равна ‘Fairy’. Так это задумано, но любая программа, принимающая пользовательский ввод, открыта и для вредоносных инструкций. Приведенная выше программа, в которой переменная lname устанавливается посредством вводимых пользователем данных, открывает возможность так называемой SQL-инъекции. Ниже приведем такое нападение в картинках, называемое Little Bobby Tables:

{kind=link}
Например, представьте, что злоумышленник вызвал ваш REST API таким образом:
GET /api/people/Fairy';DROP TABLE person;Приведенный выше запрос REST API устанавливает переменную lname для персонажа в значение Fairy;DROP TABLE; который в коде сгенерирует следующую SQL-инструкцию:
SELECT * FROM person WHERE lname = 'Fairy';DROP TABLE person;Приведенный выше код SQL валиден, и при выполнении он найдет одну запись, где lname соответствует Fairy, но затем он найдет символ разделителя операторов SQL ;, пойдет дальше и удалит всю таблицу person. По сути, это сломает ваше приложение.
Вы должны защитить свою программу, проверяя все данные, которые вы получаете от пользователя. Проверка данных в этом контексте означает, что ваша программа валидирует предоставленные пользователем данные, чтобы убедиться, что они не содержат ничего опасного для программы. Это может быть сложно сделать правильно, но это придется делать везде, где вводимые данные взаимодействуют с базой данных.
Было бы намного лучше, если бы то, что вы получили для персонажа, было объектом Python, где каждое из полей является атрибутом. Таким образом, вы будете убеждены, что объекты содержат ожидаемые типы значений, а не какие-либо вредоносные команды.
Когда вы взаимодействуете с базой данных в коде Python, вам нужно дважды подумать о том, хотите ли вы писать команды на чистом SQL. Как вы узнали выше, написание SQL может не только показаться неудобным, но и вызвать проблемы с безопасностью. Если вы не хотите слишком беспокоиться о взаимодействии с базами данных, вам может помочь такой пакет, как SQLAlchemy.
Подключение SQLite базы данных к вашему Flask проекту
В этом разделе вы используете возможности SQLAlchemy для взаимодействия с базой данных и подключении people.db к вашему приложению Flask.
SQLAlchemy обрабатывает множество операций, характерных для определенных баз данных, и позволяет вам сосредоточиться на моделях данных, а также на том, как их использовать. SQLAlchemy валидирует для вас получаемые данные перед созданием операторов SQL. Еще одно большое преимущество и повод использовать SQLAlchemy при работе с базами данных.
В этом разделе вы дополните приложение двумя модулями Python, config.py и models.py:
-
config.pyнастраивает необходимые модули, импортированные в программу, сюда входят Flask, Connexion, SQLAlchemy и Marshmallow. -
models.py— это модуль, в котором вы создадите определения классов SQLAlchemy и Marshmallow.
По завершении этого раздела можно будет удалить прежний словарь PEOPLE и работать с подключенной базой данных.
Конфигурирование Базы данных
Модуль config.py, как следует из названия, является местом создания и инициализации всей вашей конфигурационной информации. В этом файле вы собираетесь настроить Flask, Connexion, SQLAlchemy и Marshmallow.
Создайте файл config.py в папке rp_flask_api/ вашего проекта:
# config.py import pathlib import connexion from flask_marshmallow import Marshmallow from flask_sqlalchemy import SQLAlchemy basedir = pathlib.Path(__file__).parent.resolve() connex_app = connexion.App(__name__, specification_dir=basedir) app = connex_app.app app.config["SQLALCHEMY_DATABASE_URI"] = f"sqlite:///{basedir / 'people.db'}" app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False db = SQLAlchemy(app) ma = Marshmallow(app)Вот что делает приведенный выше код:
-
Вначале импортируется стандартная библиотека
pathlib, а также сторонние библиотекиconnexion,SQLAlchemyиMarshmallow. -
Далее создается переменная basedir, указывающая на каталог, в котором запускается программа.
-
Потом переменная basedir используется для создания экземпляра приложения Connexion и указания ему пути к каталогу, содержащему файл спецификации.
-
После этого создается переменная app, которая является экземпляром Flask, инициализированным Connexion, далее для SQLAlchemy указывается, что нужно использовать SQLite в качестве базы данных и файл с именем people.db в текущем каталоге в качестве файла базы данных, а также отключается система событий SQLAlchemy. Система событий генерирует события, которые полезны в программах с их обработкой, но это значительно увеличивает загруженность ресурсов компьютера. Поскольку ваша программа не использует обработку управляющих событий, эта возможность отключена.
-
В последних двух строках инициализируется SQLAlchemy с передачей конфигурационной информации о SQLite-приложении в создаваемую переменную db, тоже происходит при инициализации Marshmallow. *Если вы хотите узнать больше о конфигурировании SQLAlchemy, то вы можете ознакомиться с документацией по ключам Flask-SQLALchemy.
Модели данных в SQLAlchemy
SQLAlchemy — это большой проект, предоставляющий множество функций для работы с базами данных с использованием Python. Одной из функций, которые он предоставляет, является объектно-реляционный преобразователь (ORM). Этот ORM позволяет вам взаимодействовать с таблицей базы данных person более Python-ским, а не SQL-ским способом, сопоставляя строки полей из таблицы базы данных с атрибутами объектов Python.
Создайте файл models.py с определением класса SQLAlchemy для данных в таблице person базы данных:
# models.py from datetime import datetime from config import db class Person(db.Model): __tablename__ = "person" id = db.Column(db.Integer, primary_key=True) lname = db.Column(db.String(32), unique=True) fname = db.Column(db.String(32)) timestamp = db.Column( db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow )Вот что делает приведенный выше код:
-
Вначале импортирует объект datetime из модуля datetime, который поставляется с Python и предлагает различные функции для работы с датой и временем. Также импортируется объект db — экземпляр SQLAlchemy, который вы определили в модуле config.py, что дает models.py доступ к атрибутам и методам SQLAlchemy.
-
Далее определяется класс Person с наследованием от db.Model дает Person функции SQLAlchemy для подключения к базе данных и доступа к таблицам.
-
После этого определение класса подключается к таблице базы данных
person. -
Далее объявляются столбцы: id — содержащий целое число, выступающее в качестве первичного ключа для таблицы; фамилия со строковым значением, это поле должно быть уникальным, поскольку вы используете lname в качестве идентификатора для человека в URL-адресе REST API; имя персонажа со строковым значением; временная метка со значением даты и времени.
Параметр default=datetime.utcnow устанавливает значение метки времени по умолчанию на текущее время — значение utcnow при создании записи. Параметр onupdate=datetime.utcnow обновляет метку времени текущим временем — значением utcnow при обновлении записи. Чтобы узнать больше о временных метках UTC, разверните сворачиваемый раздел ниже:
Примечание о временных метках UTC
Вам может быть интересно, почему временная метка в приведенном выше классе по умолчанию установлена на и обновляется методом datetime.utcnow(), который возвращает UTC или всемирное координированное время. Это способ независимости значений временной метки от часовых поясов, где будет запускаться ваше приложение.
Нулевой меридиан — это линия, проходящая от северного до южного полюса Земли через Великобританию, точнее через Гринвич, еще точнее — через Гринвичскую обсерваторию. Это нулевой часовой меридиан, от которого отсчитываются все остальные часовые пояса. Используя его в качестве нулевого времени, ваши локальные временные метки смещаются от этой стандартной точки отсчета, например UTC+3 — плюс три часа для Москвы.
Если бы вы использовали местные часовые пояса в качестве источника временной метки, то вы не смогли бы выполнять вычисления даты и времени без информации о смещении местного часового пояса от нулевого меридиана. Без информации об источнике временной метки вы не смогли бы выполнять никаких сравнений даты и времени или вообще никаких математических вычислений.
Работа с временной меткой на основе UTC — это хороший стандарт для подражания.
Использование SQLAlchemy позволяет вам мыслить в терминах объектов программирования, а не иметь дело с чистым SQL. Это становится еще более полезным, когда таблицы вашей базы данных становятся больше, а взаимодействия сложнее.
Сериализация моделей данных с помощью Marshmallow
Работа с моделями данными SQLAlchemy внутри ваших программ очень удобна. Однако REST API работает с данными JSON, и здесь вы можете столкнуться с проблемой при работе с SQLAlchemy: поскольку SQLAlchemy возвращает данные как экземпляры классов Python, Connexion не может сериализовать эти экземпляры классов в данные в формате JSON.
Примечание: в этом контексте сериализация означает преобразование объектов Python, которые могут содержать другие объекты Python и сложные типы данных, в более простые структуры данных, которые можно преобразовать в типы данных JSON, которые перечислены здесь:
-
string: Строка -
number: Числовые значения, совместимые с типами Python (целые, с плавающей точкой, длинные целые) -
object: JSON-объект — эквивалент словаря в Python -
array: эквивалент списка в Python -
boolean: представляется в JSON какtrueилиfalse, но в Python этот тип представляется значениямиTrueилиFalse -
null: эквивалент None в Python.
Например, ваш класс Person содержит временную метку, которая является классом Python DateTime. В JSON нет определения DateTime, поэтому временную метку необходимо преобразовать в строку, чтобы она в таком виде оказалась в структуре JSON. Вы используете базу данных в качестве постоянного хранилища данных. С помощью SQLAlchemy вы можете удобно взаимодействовать с базой данных из вашей программы Python. Однако вам необходимо решить две проблемы:
-
Ваш REST API передает и получает JSON вместо объектов Python.
-
Вы должны убедиться, что данные, которые вы добавляете в базу данных, являются допустимыми.
Вот где в игру вступает модуль Marshmallow! Marshmallow помогает вам создать класс PersonSchema, который похож на класс SQLAlchemy Person, который вы только что создали. Класс PersonSchema определяет, как атрибуты класса будут преобразованы в форматы, представимые в JSON. Marshmallow также гарантирует, что все атрибуты в наличии и содержат ожидаемый тип данных.
Вот дополнение в файл models.py с представлением класса Marshmallow для данных в вашей таблице person:
# models.py #... from config import db, ma #... class PersonSchema(ma.SQLAlchemyAutoSchema): class Meta: model = Person load_instance = True sqla_session = db.session person_schema = PersonSchema() people_schema = PersonSchema(many=True)Вы импортируете ma из config.py, чтобы PersonSchema могла наследовать от ma.SQLAlchemyAutoSchema. Чтобы определить SQLAlchemy модель и сессию, SQLAlchemyAutoSchema определяет и использует внутренний класс Meta.
Для PersonSchema задается модель — Person, а sqla_session — db.session. Вот как Marshmallow задает атрибуты в классе Person и определяет типы этих атрибутов, чтобы показать, как их сериализовать и десериализовать.
С помощью load_instance вы можете разрешить десериализацию данных JSON и загружать из них экземпляры модели Person. Наконец, вы создаете экземпляры двух схем, person_schema и people_schema, которые будете использовать позже.
Сделайте некоторую очистку
Теперь пришло время избавиться от старой структуры данных — словаря PEOPLE. Это гарантирует, что любые изменения, которые вы вносите в данные о персонажах, будут выполняться в базе данных, а не в устаревшей структуре хранения данных PEOPLE.
Откройте people.py и избавьтесь от импорта, функций и структур данных, которые вам больше не нужны, и используйте новый импорт для добавления db и данных из models.py:
# people.py # Remove: from datetime import datetime from flask import make_response, abort from config import db from models import Person, people_schema, person_schema # Remove: get_timestamp(): # Remove: PEOPLE # ...Вы удаляете подключение datetime, функцию get_timestamp() и весь словарь PEOPLE. Взамен вы добавляете объекты из config.py и models.py, которые вы будете использовать с этого момента.
В тот момент, когда вы удалили словарь PEOPLE, ваш IDE мог пожаловаться на неопределенную переменную PEOPLE в вашем коде. Далее вы замените все ссылки PEOPLE запросами к базе данных и снова сделаете свой редактор без жалоб.
Подключение базы данных к вашему API
Ваша база данных подключена к вашему проекту Flask, но пока не к REST API. Потенциально, вы можете использовать интерактивную оболочку Python, чтобы добавить больше персонажей в вашу базу данных. Но, будет гораздо интереснее улучшить ваш REST API и использовать существующие конечные точки для добавления данных!
В этом разделе вы подключите свой API к базе данных и используете свои существующие конечные точки, связанные с базой данных, для управления персонажами. Если вы хотите подвести итоги того, как вы создали конечные точки API, то можете перейти к первой статье этого руководства. Вот как на данный момент выглядит ваш Flask REST API:
|
Действие |
HTTP-метод |
URL-путь |
Описание |
|
Чтение |
GET |
/api/people |
Получает список персонажей. |
|
Создание |
POST |
/api/people |
Создает нового персонажа. |
|
Чтение |
GET |
/api/people/<lname> |
Получает заданного персонажа. |
|
Обновление |
PUT |
/api/people/<lname> |
Обновляет заданного персонажа. |
|
Удаление |
DELETE |
/api/people/<lname> |
Удаляет заданного персонажа. |
Далее вы переделаете существующие функции в people.py, подключенные к конечным точкам, перечисленным выше, чтобы они могли работать с базой данных people.db.
Чтение из базы данных
Сначала переделайте функции в people.py, которая считывает данные из базы данных, ничего не записывая в базу данных. Начните с read_all():
# people.py # ... def read_all(): people = Person.query.all() return people_schema.dump(people) # ...Функция read_all() отвечает на конечную точку URL REST API GET /api/people и возвращает все записи в таблице базы данных person.
Вы используете people_schema, которая является экземпляром класса Marshmallow PersonSchema, созданного с параметром many=True. С помощью этого параметра вы сообщаете PersonSchema, какой объект нужно сериализовать. Это важно, поскольку переменная people содержит список всех элементов базы данных.
Наконец, вы сериализуете объекты Python с помощью .dump() и возвращаете данные всех персонажей в ответ на вызов REST API. Другая функция в people.py, которая только получает данные, — это read_one():
# people.py # ... def read_one(lname): person = Person.query.filter(Person.lname == lname).one_or_none() if person is not None: return person_schema.dump(person) else: abort(404, f"Person with last name {lname} not found") # ...Функция read_one() получает параметр lname из пути URL REST, указывающий, что пользователь ищет определенного человека. Вы используете lname в запросе .filter() метода. Вместо использования .all() вы используете метод .one_or_none(), чтобы получить одного человека, или возвращаете None, если совпадений не найдено.
Если персонаж найден, то person содержит объект Person, и вы возвращаете сериализованный объект. В противном случае вы вызываете abort() с ошибкой.
Запись в базу данных
Еще одно изменение в people.py — создание нового персонажа в базе данных. Это дает вам возможность использовать Marshmallow PersonSchema для десериализации структуры JSON, отправленной HTTP-запросом, чтобы создать объект SQLAlchemy Person. Вот часть обновленного модуля people.py, показывающая обработчик для конечной точки URL REST POST /api/people:
# people.py # ... def create(person): lname = person.get("lname") existing_person = Person.query.filter(Person.lname == lname).one_or_none() if existing_person is None: new_person = person_schema.load(person, session=db.session) db.session.add(new_person) db.session.commit() return person_schema.dump(new_person), 201 else: abort(406, f"Person with last name {lname} already exists") # ...Вместо получения только фамилии, как в read_one(), create() получает объект person. Этот объект должен содержать lname, который до этого не должен был существовать в базе данных. Значение lname является вашим идентификатором для вашего персонажа, поэтому в вашей базе данных не может быть нескольких персонажей с одной и той же фамилией.
Если фамилия уникальна, то вы десериализуете объект person как new_person и добавляете его в db.session. После того, как вы добавите new_person в базу данных, ваша СУБД назначает новое значение первичного ключа и UTC временную метку для объекта. После этого вы увидите созданный набор данных в ответе API.
Настройте update() и delete() аналогично тому, как вы настраивали другие функции:
# people.py # ... def update(lname, person): existing_person = Person.query.filter(Person.lname == lname).one_or_none() if existing_person: update_person = person_schema.load(person, session=db.session) existing_person.fname = update_person.fname db.session.merge(existing_person) db.session.commit() return person_schema.dump(existing_person), 201 else: abort(404, f"Person with last name {lname} not found") def delete(lname): existing_person = Person.query.filter(Person.lname == lname).one_or_none() if existing_person: db.session.delete(existing_person) db.session.commit() return make_response(f"{lname} successfully deleted", 200) else: abort(404, f"Person with last name {lname} not found")После всех этих изменений пришло время обновить код вашего клиентского приложения и использовать Swagger UI, чтобы проверить, работает ли ваша база данных так, как ожидалось.
Отображение данных в интерфейсе пользователя
Теперь, когда вы добавили конфигурацию SQLite и определили свою модель Person, ваш проект Flask содержит всю информацию для работы с базой данных. Прежде чем вы сможете отобразить данные в пользовательском интерфейсе, вам нужно внести некоторые изменения в app.py:
# app.py from flask import render_template # Remove: import connexion import config from models import Person app = config.connex_app app.add_api(config.basedir / "swagger.yml") @app.route("/") def home(): people = Person.query.all() return render_template("home.html", people=people) if __name__ == "__main__": app.run(host="0.0.0.0", port=8000)Теперь вы работаете с config.py и models.py. Поэтому вы удаляете импорт Connexion и добавляете импорт из config и Person из models.
Модуль config предоставляет вам приложение Flask с дополнением Connexion. Поэтому вам больше не нужно создавать новое приложение Flask в app.py, а нужно сослаться на config.connex_app.
Далее вы запрашиваете модель Person, чтобы получить все данные из таблицы person, и передаете их в render_template(). Чтобы отобразить данные о персонажах во внешнем интерфейсе, вам нужно настроить для этого шаблон home.html:
<!-- templates/home.html --> <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>RP Flask REST API</title> </head> <body> <h1>Hello, People!</h1> <ul> {% for person in people %} <li>{{ person.fname }} {{ person.lname }}</li> {% endfor %} </ul> </body> </html>Вы можете запустить свое приложение с помощью этой команды в каталоге, содержащем файл app.py (не забудьте предварительно активировать виртуальное окружение venv со всеми зависимостями):
(venv) $ python app.pyПри запуске этого приложения веб-сервер запустится на порту 8000, который вы определили в app.py. Если вы откроете браузер и перейдете по адресу http://localhost:8000, что эквивалентно http://127.0.0.1:8000, вы увидите приветствие и данные из базы данных:

Использование аннотаций API
С внесенными выше изменениями база данных теперь функциональна и сохраняет данные даже при перезапуске приложения.
Вы можете использовать свой API для добавления, обновления и удаления персонажей. С изменениями, внесенными вами во внешний интерфейс, вы можете видеть всех людей, которые в данный момент хранятся в вашей базе данных.
При перезапуске приложения Flask вы больше не теряете изменения в данных. Поскольку теперь у вас есть база данных, прикрепленная к вашему проекту Flask, ваши данные сохраняются.
Заключение
Поздравляем, вы рассмотрели много нового материала в этом руководстве и добавили полезные инструменты в свой арсенал!
В этой второй части серии вы узнали, как:
— Использовать SQL-инструкции в Python
— Настраивать базу данных SQLite для вашего проекта Flask
— Использовать SQLAlchemy для хранения объектов Python в базе данных
— Работать с базой данных через REST API
— Сериализовывать и десериализовывать JSON в объекты Python через Marshmallow
Навыки, которые вы приобрели, безусловно, стали шагом вперед по сравнению с REST API из первой части, но этот шаг дал вам мощные инструменты для использования при создании более сложных приложений. Их использование даст вам большое преимущество в создании собственных веб-приложений с использованием баз данных.
Чтобы просмотреть код для второй части этой серии руководств, нажмите ниже:
Полный исходный код
Структура файлов и папок
rp_flask_api/ ├── templates/ │ └── home.html ├── venv/ # виртуальное окружение ├── app.py ├── config.py ├── create_db.py # файл создания и первоначального заполнения базы данных ├── models.py ├── people.db # файл базы данных ├── people.py ├── requirements.txt # файл с указанием зависимостей, установка через pip install -r requirements.txt └── swagger.ymltemplates/home.html
<!-- templates/home.html --> <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>RP Flask REST API</title> </head> <body> <h1>Hello, World!</h1> </body> </html>app.py
# app.py import config from flask import render_template from models import Person app = config.connex_app app.add_api(config.basedir / "swagger.yml") @app.route("/") def home(): people = Person.query.all() return render_template("home.html", people=people) if __name__ == "__main__": app.run(host="0.0.0.0", port=8000)config.py
# config.py import pathlib import connexion from flask_marshmallow import Marshmallow from flask_sqlalchemy import SQLAlchemy basedir = pathlib.Path(__file__).parent.resolve() connex_app = connexion.App(__name__, specification_dir=basedir) app = connex_app.app app.config["SQLALCHEMY_DATABASE_URI"] = f"sqlite:///{basedir / 'people.db'}" app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False db = SQLAlchemy(app) ma = Marshmallow(app)create_db.py
# create_db.py import sqlite3 conn = sqlite3.connect("people.db") print("Database created and opened successfully") # создание таблицы с заданными полями columns = [ "id INTEGER PRIMARY KEY", "lname VARCHAR UNIQUE", "fname VARCHAR", "timestamp DATETIME", ] create_table_cmd = f"CREATE TABLE person ({','.join(columns)})" conn.execute(create_table_cmd) print("Table created successfully") # записываемые в базу данных персонажи people = [ "1, 'Fairy', 'Tooth', '2022-10-08 09:15:10'", "2, 'Ruprecht', 'Knecht', '2022-10-08 09:15:13'", "3, 'Bunny', 'Easter', '2022-10-08 09:15:27'", ] for person in people: insert_cmd = f"INSERT INTO person VALUES ({person})" conn.execute(insert_cmd) conn.commit() print("Records created successfully") # проверка: вывод данных из таблицы базы данных cur = conn.cursor() cur.execute("SELECT * FROM person") people = cur.fetchall() for person in people: print(person)models.py
# models.py from datetime import datetime from config import db, ma class Person(db.Model): __tablename__ = "person" id = db.Column(db.Integer, primary_key=True) lname = db.Column(db.String(32), unique=True) fname = db.Column(db.String(32)) timestamp = db.Column( db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow ) class PersonSchema(ma.SQLAlchemyAutoSchema): class Meta: model = Person load_instance = True sqla_session = db.session person_schema = PersonSchema() people_schema = PersonSchema(many=True)people.py
# people.py from config import db from flask import abort, make_response from models import Person, people_schema, person_schema def read_all(): people = Person.query.all() return people_schema.dump(people) def create(person): lname = person.get("lname") existing_person = Person.query.filter(Person.lname == lname).one_or_none() if existing_person is None: new_person = person_schema.load(person, session=db.session) db.session.add(new_person) db.session.commit() return person_schema.dump(new_person), 201 else: abort(406, f"Person with last name {lname} already exists") def read_one(lname): person = Person.query.filter(Person.lname == lname).one_or_none() if person is not None: return person_schema.dump(person) else: abort(404, f"Person with last name {lname} not found") def update(lname, person): existing_person = Person.query.filter(Person.lname == lname).one_or_none() if existing_person: update_person = person_schema.load(person, session=db.session) existing_person.fname = update_person.fname db.session.merge(existing_person) db.session.commit() return person_schema.dump(existing_person), 201 else: abort(404, f"Person with last name {lname} not found") def delete(lname): existing_person = Person.query.filter(Person.lname == lname).one_or_none() if existing_person: db.session.delete(existing_person) db.session.commit() return make_response(f"{lname} successfully deleted", 200) else: abort(404, f"Person with last name {lname} not found")requirements.txt
# requirements.txt connexion[Flask]==3.1.0 connexion[uvicorn]==3.1.0 flask-marshmallow==1.2.1 Flask-SQLAlchemy==3.1.1 marshmallow-sqlalchemy==1.1.0 swagger_ui_bundle==1.1.0swagger.yml
# swagger.yml openapi: 3.0.0 info: title: "RP Flask REST API" description: "An API about people and notes" version: "1.0.0" servers: - url: "/api" components: schemas: Person: type: "object" required: - lname properties: fname: type: "string" lname: type: "string" parameters: lname: name: "lname" description: "Last name of the person to get" in: path required: True schema: type: "string" paths: /people: get: operationId: "people.read_all" tags: - "People" summary: "Read the list of people" responses: "200": description: "Successfully read people list" post: operationId: "people.create" tags: - People summary: "Create a person" requestBody: x-body-name: "person" description: "Person to create" required: True content: application/json: schema: $ref: "#/components/schemas/Person" responses: "201": description: "Successfully created person" /people/{lname}: get: operationId: "people.read_one" tags: - People summary: "Read one person" parameters: - $ref: "#/components/parameters/lname" responses: "200": description: "Successfully read person" put: tags: - People operationId: "people.update" summary: "Update a person" parameters: - $ref: "#/components/parameters/lname" responses: "200": description: "Successfully updated person" requestBody: x-body-name: "person" content: application/json: schema: $ref: "#/components/schemas/Person" delete: tags: - People operationId: "people.delete" summary: "Delete a person" parameters: - $ref: "#/components/parameters/lname" responses: "204": description: "Successfully deleted person"Код имеет некоторые отличия от оригинала: использованы новые версии пакетов, код проверен и 100% работоспособен.
В следующей части третьей части вы расширите свой REST API, чтобы вы могли создавать, читать, обновлять и удалять открытки для персонажей. Открытки будут храниться в новой таблице базы данных. Каждая открытка будет связана с персонажем, поэтому вы добавите связи между открытками и персонажами в свою базу данных.
Третья часть будет последней частью этого руководства. В конце у вас получится полноценный Flask REST API взаимодействующий с таблицами базы данных в фоновом режиме.
ссылка на оригинал статьи https://habr.com/ru/articles/859528/
Добавить комментарий