Всем привет, думаю у вас на слуху разного рода Diffusion модели последние 2 года. На его основе генерируют реалистичные изображения и видео, поэтому мне захотелось копнуть поглубже и узнать какова кроличья нора…
Меня зовут Юра, я — разработчик, фаундер и временами ML энтузиаст. Я решил разобраться и понять, как устроена Diffusion модель внутри, понять ее математику и постараться объяснить и разложить ее на пальцах. Ну и конечно пописать код, который (спойлер) заработал. На гифке изображены примеры итоговых картинок на моей финальной модели.
Если вам тоже интересно, милости прошу под кат.

Небольшое вступление
Для тех, кто не хочет ждать и сразу взглянуть на код — не буду тянуть, вот ссылка на github проект.
Какой примерно у нас план:
-
Вспоминаем матан и тервер. Разбираем математику прямого и обратного процесса -
От математики приходим к простой функции потерь (быстрый переход)
-
Пишем код (быстрый переход)
Сразу напишу, что без этих людей: Jonathan Ho, Ajay Jain, Pieter Abbeel (авторы оригинального DDPM) не было бы ни бума генераций картинок, ни моей статьи. Поэтому респект и спасибо им и другим ресерчерам, на статьи и работы которых опираются в этом пейпере! Также большое спасибо Lil Log за ее блог с объяснением математики, без этого тоже было бы трудно. Все другие ссылки, на которые я опирался и использовал, укажу в конце статьи.
Также в статье возможно есть неточности или ошибки. Буду благодарен за любой ваш фидбек или найденные ошибки.
Ну что? Погнали!
Math
Прямой процесс
Когда впервые видишь или читаешь пейпер, испытываешь те же чувства, что у Бена снизу. Непонятный набор формул на каждой странице втапливает вас постепенно в землю, но не будем паниковать раньше времени. Попробуем разобраться степ бай степ.

Вообще, что такое Diffusion model? Цитата из оригинального пейпера:
What distinguishes diffusion models from other types of latent variable models is that the approximate posterior
, called the forward process or diffusion process, is fixed to a Markov chain that gradually adds Gaussian noise to the data according to a variance schedule β1 , . . . , βT
Для нас важно здесь, что есть некое апостериорное распределение (или пространство вероятностей), которое представляет собой процесс диффузии. Выглядит оно так:


Вторая формула на пальцах: условное распределение  является нормальным распределение
является нормальным распределение  с мат ожиданием
с мат ожиданием  и дисперсией β_t. Процесс перехода из одного распределения в другое мы делаем T раз. Запишем конечное распределение как .
и дисперсией β_t. Процесс перехода из одного распределения в другое мы делаем T раз. Запишем конечное распределение как .
Читатель, который наверное в легком замешательстве, имеет только один вопрос: как генерация картинок, да и вообще картинки связаны с этими формулами?
Картинок бесконечно много в мире(их конечное число, но много), но для простоты их очень много. Поэтому мы можем говорить о неком распределении картинок. Начальное нами выбранное распределение картинок — это  .
.
Давайте на примере попробуем применить эти формулы. Для простоты будем работать в одномерном пространстве (с картинками работать будет точно также, но их не удобно отображать на графике).
Какой наш аглоритм? Мы выбираем случайную точку из множества , затем  — это случайная точка из нормального распределения
— это случайная точка из нормального распределения  . На всякий случай, нормальное распределение выглядит так:
. На всякий случай, нормальное распределение выглядит так:

Затем  будет случайной точкой из нормального распределения c мат ожиданием
будет случайной точкой из нормального распределения c мат ожиданием  и
и  и так далее. В конце мы получим
и так далее. В конце мы получим  , которая тоже в свою очередь будет некой точкой, выбранная из последнего нормального распределения. В условиях, что у нас есть начальное распределение , то в конце мы получим распределение , все точки которого пройдут T итераций.
, которая тоже в свою очередь будет некой точкой, выбранная из последнего нормального распределения. В условиях, что у нас есть начальное распределение , то в конце мы получим распределение , все точки которого пройдут T итераций.
В случае картинок каждая итерация предсталяет собой добавление шума к картинке. На человеческий взгляд это выглядит, как порча картинки. Через множество итераций вменяемое изображение становится черти пойми чем, но важное уточнение, что это для человека. А в рамках математики этот шум приводит нас к грандиозному результату!

Напишем применение формул выше на питоне с разным набором  , установим в 1(то есть одна единственная начальная точка) и смотреть будем графики на интервале -5 до 5 с 1000 значений. T (общее количество итераций) сделаем равным 800.
, установим в 1(то есть одна единственная начальная точка) и смотреть будем графики на интервале -5 до 5 с 1000 значений. T (общее количество итераций) сделаем равным 800.
Небольшой код на питоне:
timestep = 800 xs = np.arange(-5, 5, 0.01) y_results = norm.pdf(xs, 0, 1) different_schedules = [ # constant np.ones(timestep) * 0.1, np.ones(timestep) * 0.3, np.ones(timestep) * 0.5, np.ones(timestep) * 0.7, np.ones(timestep) * 0.9, # linear change (from paper) np.linspace(1e-4, 0.02, timestep) ] x0 = 1 for bt in different_schedules: # Set xt to zero, which will be used as x(t-1) like in sqrt(1-b) * x(t-1) xt = x0 q_results = None # A simple loop by timestep for t in range(timestep): # Calculate the mean as in the formula mean = math.sqrt(1 - bt[t]) * xt # Calculate the variance variance = bt[t] # Q is a normal distribution, so to get the next xt, we just get random element from our distribution xt = np.random.normal(mean, math.sqrt(variance)) q_results = norm.pdf(xs, mean, math.sqrt(variance)) plt.plot(xs, q_results, label=f"qt for bt {bt[0] if bt[0] == bt[-1] else 'linear'}") plt.plot(xs, y_results, label="Y") plt.legend() plt.show() Получаем это:

То есть в целом, не смотря на разные набор значений , мы приходим к нормальному распределению.
Но с точки зрения будущей нейросети есть проблема в одной строчке кода:
xt = np.random.normal(mean, math.sqrt(variance)) То есть мы берем случайное значение из распределения. Сделать производную по  будет нереально (потому что здесь выбираются случайные значения) и соответственно обратное распространение ошибки нам сделать нельзя.
будет нереально (потому что здесь выбираются случайные значения) и соответственно обратное распространение ошибки нам сделать нельзя.
Чтобы обойти это, используем небольшой трюк (в пейпере про VAE его назвали reparametrization trick)

 , где
, где 
Для нашего случая:
 , где
, где
То есть случайную величину выносим в формулу и записываем через сумму с коэффициентом некой epsilon, которая и будет представлять случайное значенеие из нормального распределения с ожиданием 0 и дисперсией 1.
Выглядит может и странно, но давайте проверим:
for bt in different_schedules: # Set xt to zero, which will be used as x(t-1) like in sqrt(1-b) * x(t-1) xt = x0 q_results = None # A simple loop by timestep for t in range(timestep): # Calculate the mean as in the formula mean = math.sqrt(1 - bt[t]) * xt # Calculate the variance variance = math.sqrt(bt[t]) # Get eps from normal distribution eps = np.random.normal(0, 1) # Calculate our xt xt = mean + variance * eps q_results = norm.pdf(xs, mean, math.sqrt(variance)) plt.plot(xs, q_results, label=f"qt for bt {bt[0] if bt[0] == bt[-1] else 'linear'}") plt.plot(xs, y_results, label="Y") plt.legend() plt.show() 
Результаты очень похожи на те, что были ранее. Можно брать за правду!
Но есть еще одна проблемка: сейчас мы последовательно вычисляем через . Держим в уме, что T может быть очень большим и мы будем работать не в одномерном пространстве(а n-мерном, как картинки например). Как итог — вычисления громоздкие, хочется облегчить себе жизнь. Давайте вспомним тервер и запишем пару формул.


 и
и  . Их объединение будет давать:
. Их объединение будет давать:  . Перепишем формулу выше:
. Перепишем формулу выше:

Продолжая, получим:

Для тех, кто тервер не помнит, вот хорошая ссылка на вспоминание. Можно пока поверить на слово и глянуть на результаты с новой формулой.
Еще немного кода
«`python for bt in different_schedules: alpha_t = 1 — bt cumprod_alpha_t = np.cumprod(alpha_t) mean = math.sqrt(cumprod_alpha_t[-1]) * x0 variance = math.sqrt(1 — cumprod_alpha_t[-1]) eps = np.random.normal(0, 1) variance = variance xt = mean + eps * variance q_results = norm.pdf(xs, mean, math.sqrt(variance)) plt.plot(xs, q_results, label=f»qt for bt {bt[0] if bt[0] == bt[-1] else ‘linear’}») plt.plot(xs, y_results, label=»Y») plt.legend() plt.show() «`

Видим, что такая формула ведет нас к нормальному распределению с ожиданием 0 и дисперсией 1 в итоге.
Кажется, мы разобрались с прямым процессом, переходим к обратному процессу.

Обратный процесс
Спойлер: очень много непростой математики. Прочитать и не понять ничего с первого раза — это нормально. Прочтите еще раз, что-то можно спросить LLM, что-то самому повыводить на бумаге.
Окей, у нас есть  , а что насчет
, а что насчет  ? На словах, добавляя шум к картинке, получаем шум (но мы уже знаем, что это нормальное распределение).
? На словах, добавляя шум к картинке, получаем шум (но мы уже знаем, что это нормальное распределение).
Но теперь самое интересное! Как получить из шума нормальную картинку?
Можно ли это вообще? Без спойлеров, все юзали Stable Diffusion, поэтому видимо можно. Давайте разберемся как.
сходу кажется нельзя вывести. Давайте рассмотрим почему. Немного простого тервера.
 (1)
(1)
 (2)
(2)
 (3)
(3)
Выводя одинаковый числитель из (1) и (3), получаем формулу:


Теперь перепишем формулу (2):

С помощью формулы Баейса запишем  , как
, как 
То есть для вычисления мы должны посчитать интеграл через все (все картинки в нашем датасете), вычисления которого будут долгими и дорогими.
Окей, вывести нельзя, но можно вывести  . Что это означает? Мы пытаемся найти распределение , зная и .
. Что это означает? Мы пытаемся найти распределение , зная и .
Считаем мат ожидание и дисперсию
Разбираемся с .
Прежде всего возьмем за факт, что если  — очень маленькое число и
— очень маленькое число и  — Гауссово распределение, то — тоже будет являться Гауссовым распределением. Цитата из пейпера:
— Гауссово распределение, то — тоже будет являться Гауссовым распределением. Цитата из пейпера:
«For both Gaussian and binomial diffusion, for continuous diffusion (limit of small step size β) the reversal of the diffusion process has the identical functional form as the forward process (Feller, 1949).»
Я попытался прочитать эту теорему и доказательство в оригинале и это было тяжело понимаемо, поэтому примем этот факт за правду.
Итак, если — Гауссово распределение, то попытаемся найти  и
и  (то есть его мат ожидание и дисперсию).
(то есть его мат ожидание и дисперсию).
Воспользовавшись правилом Байеса, мы имеем:

Далее, раскрываем каждый множитель в виде формулы Гауссова распределения (напомню, там будет перемножение 3х экспонент), затем подробно рассмотрим, что у нас будет происходит в экспонентах. Часть вычислений взял из Lil Log article


Напомню, что:

Рассмотрим более детально:

Не сложно заметить, что если  , то
, то  . Аналогично
. Аналогично

Выведем мат ожидание и дисперсию для


Сейчас 
 (4)
(4)
 (5)
(5)
Вспомним, что , выразим через

Затем выразим  без использования
без использования

Вспоминая, что  , запишем
, запишем
 (6)
(6)
Вводим модель
Как мы увидели ранее, мы не можем посчитать , поэтому введем модель  , которая апроксимирует наше неизвестное распределение q. Также ранее мы доказали, что — Гауссово распределение, значит — тоже Гауссово. Запишем
, которая апроксимирует наше неизвестное распределение q. Также ранее мы доказали, что — Гауссово распределение, значит — тоже Гауссово. Запишем

У нас есть модель , которое описывает некое распределение и у нас есть . Наша задача найти оптимальное  , при котором
, при котором  будет наиболее приближено к
будет наиболее приближено к  . Звучит так, что нам нужно найти функцию ошибки.
. Звучит так, что нам нужно найти функцию ошибки.
Чтобы сделать это, запишем функцию правдоподобия для
 `
`
Наша задача максимизировать его, давайте запишем логарифм от функции правдоподобия(который точно также нужно максимизировать):

где E — мат ожидание от функции 
Запишем еще формулу неравенства Jensen:
 , если
, если  — выпуклая функция и
— выпуклая функция и
 , если — вогнутая.
, если — вогнутая.
 — вогнутая, поэтому получаем:
— вогнутая, поэтому получаем:

Перепишем форумулу выше:
![\begin{aligned} \log p_\theta(x) &= \log E_{q(x_{1:T}|x_0)} \frac{p_\theta(x_{0:T})}{q(x_{1:T}|x_0)} \\ &= E_{q(x_{1:T}|x_0)}[ \log \frac {p_\theta(x_T) * p_\theta(x_0|x_1) * \prod_{t=2}^{T} p_\theta(x_{t-1}|x_t) } { q(x_1|x_0) * \prod_{t=2}^{T} q(x_t|x_{t-1}) } ] \\ &= E_{q(x_{1:T}|x_0)}[ \log \frac {p_\theta(x_T) * p_\theta(x_0|x_1) } { q(x_1|x_0) } + \log \prod_{t=2}^{T} \frac { p_\theta(x_{t-1}|x_t) } { q(x_t|x_{t-1}) } ] \\ &= E_{q(x_{1:T}|x_0)}[ \log \frac {p_\theta(x_T) * p_\theta(x_0|x_1) } { q(x_1|x_0) } + \log \prod_{t=2}^{T} \frac { p_\theta(x_{t-1}|x_t) } { \frac { q(x_{t-1}|x_t, x_0) * \cancel { q(x_t|x_0) } } { \cancel { q(x_{t-1} | x_0) } } } ] \\ &= E_{q(x_{1:T}|x_0)}[ \log \frac {p_\theta(x_T) * p_\theta(x_0|x_1) } { q(x_1|x_0) } + \log \frac {q_(x_1|x_0) } { q(x_T|x_0) } + \log \prod_{t=2}^{T} \frac { p_\theta(x_{t-1}|x_t) } { q(x_{t-1}|x_t, x_0) } ] \\ &= E_{q(x_{1:T}|x_0)}[ \log \frac{p_\theta(x_T) * p_\theta(x_0|x_1)}{q(x_T|x_0) }] + E_{q(x_{1:T}|x_0)}[ \log \prod_{t=2}^{T} \frac {p_\theta(x_{t-1}|x_{t})}{q(x_{t-1}|x_{t}, x_0)} ] \\ &= E_{q(x_{1:T}|x_0)} \log p_\theta(x_0|x_1) + E_{q(x_{1:T}|x_0)} \log \frac{p_\theta(x_T)}{q(x_T|x_{0}) } + E_{q(x_{1:T}|x_0)}[ \sum_{t=2}^{T} \log \frac {p_\theta(x_{t - 1}|x_{t})}{q(x_{t-1}|x_{t},x_0)} ] \\ &= E_{q(x_1|x_0)} \log p_\theta(x_0|x_1) + E_{q(x_T|x_0)} \log \frac{p_\theta(x_T)}{q(x_T|x_0) } + \sum_{t=2}^{T} [E_{q(x_{t-1},x_t|x_0)} \log \frac {p_\theta(x_{t-1}|x_{t})}{q(x_{t-1}|x_{t},x_0)} ] \\ &= E_{q(x_1|x_0)} \log p_\theta(x_0|x_1) - D_{KL} (q(x_T|x_0) || p_\theta(x_T)) - \sum_{t=2}^{T} [E_{q(x_{t-1}|x_0)} D_{KL} (q(x_{t-1}|x_t, x_0) || p_\theta(x_{t-1}|x_t)) ] \end{aligned}](https://habrastorage.org/getpro/habr/formulas/f/f4/f49/f498c63c33c11d4962d62169f9ea9de6.svg)
Для тех, кого смущает, что такое  .
.  — KL Divergence или по русски «Расстояние Кульбака — Лейблера», метрика, которая показывает разницу между вероятностным распределением P и Q. В случае если они одинаковые, то
— KL Divergence или по русски «Расстояние Кульбака — Лейблера», метрика, которая показывает разницу между вероятностным распределением P и Q. В случае если они одинаковые, то  . Ссылка на вики
. Ссылка на вики
![\log p_\theta(x) >= E_{q(x_1|x_0)} \log p_\theta(x_0|x_1) - D_{KL} (q(x_T|x_0) || p_\theta(x_T)) - \sum_{t=2}^{T} [E_{q(x_{t-1}|x_0)} D_{KL} (q(x_{t-1}|x_t, x_0) || p_\theta(x_{t-1}|x_t)) ]](https://habrastorage.org/getpro/habr/formulas/2/2c/2cd/2cda52cf6ca080eb5a1bf250ceeae098.svg) (7)
(7)
То что мы вывели выше, называется Evidence Lower Bound (ELBO) или по русски Нижняя граница правдоподобия. Отдельное спасибо Calvin Luo с его замечательной статьей с объяснениями выведения этой формулы.
В формуле выше 1й и 2й член не зависят от , поэтому мы можем убрать их и работать только с последней суммой. Наша цель — максимизировать правдоподобие, то есть смотря на формулу 7, мы должны минимизировать
![\sum_{t=2}^{T} [E_{q(x_{t-1}|x_0)} D_{KL} (q(x_{t-1}|x_t, x_0) || p_\theta(x_{t-1}|x_t)) ]](https://habrastorage.org/getpro/habr/formulas/3/35/353/3533eb72b08b0acdf3fb31dd08161c0d.svg) (8)
(8)
всегда положительное, поэтому наша цель — минимизировать его.
Кажется мы нашли нашу функцию потерь!
Функция потерь
Если подытожить очень кратко, то все вычисления, которые мы делали ранее, нужны для того, чтобы понять, как нам сделать распределение максимально приближенным к , которое как мы доказали ранее невозможно посчитать. Наши вычисления привели к тому, что нужно минимизировать некое расстояние, которое сейчас мы и выведем.
Конечно же, к расстоянию мы пришли не просто так, а потому, что есть формула, как посчитать расстояние между 2мя гауссовыми распределениями. Для любознательных вот линк.

Напомним, что 
Вычислим 

Теперь перепишем нашу формулу 5:

Где  — изображение, которое мы получаем от нейросети.
— изображение, которое мы получаем от нейросети.
Возьмем формулу 6 и перепишем наше расстояние:

В нашем случае с картинками  — шум, который мы добавляем к картинке,
— шум, который мы добавляем к картинке,  — шум, который нам предсказывает нейросеть.
— шум, который нам предсказывает нейросеть.
Теперь наша функция ошибки выглядит так:
![\begin{aligned} Loss(\theta) = \arg \min_{\theta} \sum_{t=2}^{T}E_{q(x_t|x_0)} [\ \frac{1}{2\sigma_q^2(t)} * \frac{(1 - \alpha_t)^2}{\alpha_t (1 - \bar{\alpha_{t}})} ||\epsilon - \epsilon_{\theta}||_2^2 \ ] \end{aligned}](https://habrastorage.org/getpro/habr/formulas/3/33/331/3316c3ed8b827825884e836a488377ad.svg)
Можно использовать более простую формулу:

То есть простыми словами, при обучении на каждую картинку мы будем накладывать шум и будем учить нейросеть определять шум, который мы наложили. Шум будем накладывать по формуле, которую мы записали в самом начале:
При этом t будет разный для разных картинок и будет выбираться случайно на этапе обучения.
Как сгенерировать картинку после обучения
Напомним, что  и
и  в нашем случае, поэтому:
в нашем случае, поэтому:

То есть в цикле по t нам на каждом шагу надо вычислить по формуле выше и в итоге мы придем к . При этом — случайный шум (если более точно, случайное значение, взято из нормального распределения с ожиданием 1 и дисперсией 0),  — посчитанный шум нейросетью на шаге t и
— посчитанный шум нейросетью на шаге t и  — еще один случайный шум.
— еще один случайный шум.
Итог математики
Поздравляю, тех, кто полностью прочитал и проклинает математику выжил. Для тех, кто начал страдать, что он ничего не понял, просьба не сильно унывать. Без должной подготовки, это точно не простое чтиво. Что-то нужно перечитать 10-50 раз и потом придет осознание, где-то пописать формулы, вообщем рецепт у каждого свой!
Ну самое тяжелое на бумаге позади, предлагаю переходить к коду.
Пишем код
Писать код на бумаге — точно не лучшая затея. Поэтому прикрепляю ссылку на репозиторий. А я подсвечу некоторые интересные моменты.
Пойдем от большого к маленькому.

Diffusion model
DDPM(Denoising Diffusion Probalistic Model) или проще наша Diffusion модель. Код.
У модели есть метод forward, который используется для обучения и sample для генерации. Интересный момент в конструкторе этого класса:
self.T = T self.eps_model = eps_model.to(device) self.device = device beta_schedule = torch.linspace(1e-4, 0.02, T + 1, device=device) alpha_t_schedule = 1 - beta_schedule bar_alpha_t_schedule = torch.cumprod(alpha_t_schedule.detach().cpu(), 0).to(device) sqrt_bar_alpha_t_schedule = torch.sqrt(bar_alpha_t_schedule) sqrt_minus_bar_alpha_t_schedule = torch.sqrt(1 - bar_alpha_t_schedule) self.register_buffer("beta_schedule", beta_schedule) self.register_buffer("alpha_t_schedule", alpha_t_schedule) self.register_buffer("bar_alpha_t_schedule", bar_alpha_t_schedule) self.register_buffer("sqrt_bar_alpha_t_schedule", sqrt_bar_alpha_t_schedule) self.register_buffer("sqrt_minus_bar_alpha_t_schedule", sqrt_minus_bar_alpha_t_schedule) self.criterion = nn.MSELoss() Можно сказать, что эта вся основная математика, которая вообще есть в Diffusion модели. То есть мы считаем alpha и beta для вычисления картинки с шумом. Напомню формулу:
И напомню, что из alpha можно вывести beta и наоборот.
Сразу же здесь создаем нашу функцию ошибки или потерь, которая по сути является разницей(или L2 расстоянием) между шумом, который мы будем накладывать на картинку во время обучения и шум, который должна предсказать наша нейросеть. Также передаем на вход конструктора модель, которая и должна будет вычислять этот шум. Ее опишем ниже.
Выводили функцию потерь мы здесь.
Обучение
Напишем еще раз нашу формулу ошибки:
Теперь давайте реализуем это в методе forward у ddpm:
t = torch.randint(low=1, high=self.T+1, size=(imgs.shape[0],), device=self.device) noise = torch.randn_like(imgs, device=self.device) # get noise image as: sqrt(alpha_t_bar) * x0 + noise * sqrt(1 - alpha_t_bar) batch_size, channels, width, height = imgs.shape noise_imgs = self.sqrt_bar_alpha_t_schedule[t].view((batch_size, 1, 1 ,1)) * imgs \ + self.sqrt_minus_bar_alpha_t_schedule[t].view((batch_size, 1, 1, 1)) * noise # get predicted noise from our model pred_noise = self.eps_model(noise_imgs, t.unsqueeze(1)) # calculate of Loss simple ||noise - pred_noise||^2, which is MSELoss return self.criterion(pred_noise, noise) Генерация изображений
Вспомним формулу для генерации:

И код для него
# создаем случайный шум x_t = torch.randn(n_samples, *size, device=self.device) # вычисляем x_(t-1) на каждой итерации for t in range(self.T, 0, -1): t_tensor = torch.tensor([t], device=self.device).repeat(x_t.shape[0], 1) pred_noise = self.eps_model(x_t, t_tensor) z = torch.randn_like(x_t, device=self.device) if t > 0 else 0 x_t = 1 / torch.sqrt(self.alpha_t_schedule[t]) * \ (x_t - pred_noise * (1 - self.alpha_t_schedule[t]) / self.sqrt_minus_bar_alpha_t_schedule[t]) + \ torch.sqrt(self.beta_schedule[t]) * z return x_t По сути наш скелет готов, переходим на уровень ниже.
UNet модель
Как мы видели выше, у нас была загадочная eps_model, которая вычисляла шум, принимая на вход шум текущей итерации и время t.
По сути это может быть какая угодно модель, но в оригинальном пейпере (и даже в самом Stable Diffusion) используется UNet модель. Многим известная картинка из оригинального пейпера UNet, выглядит она схематично так:
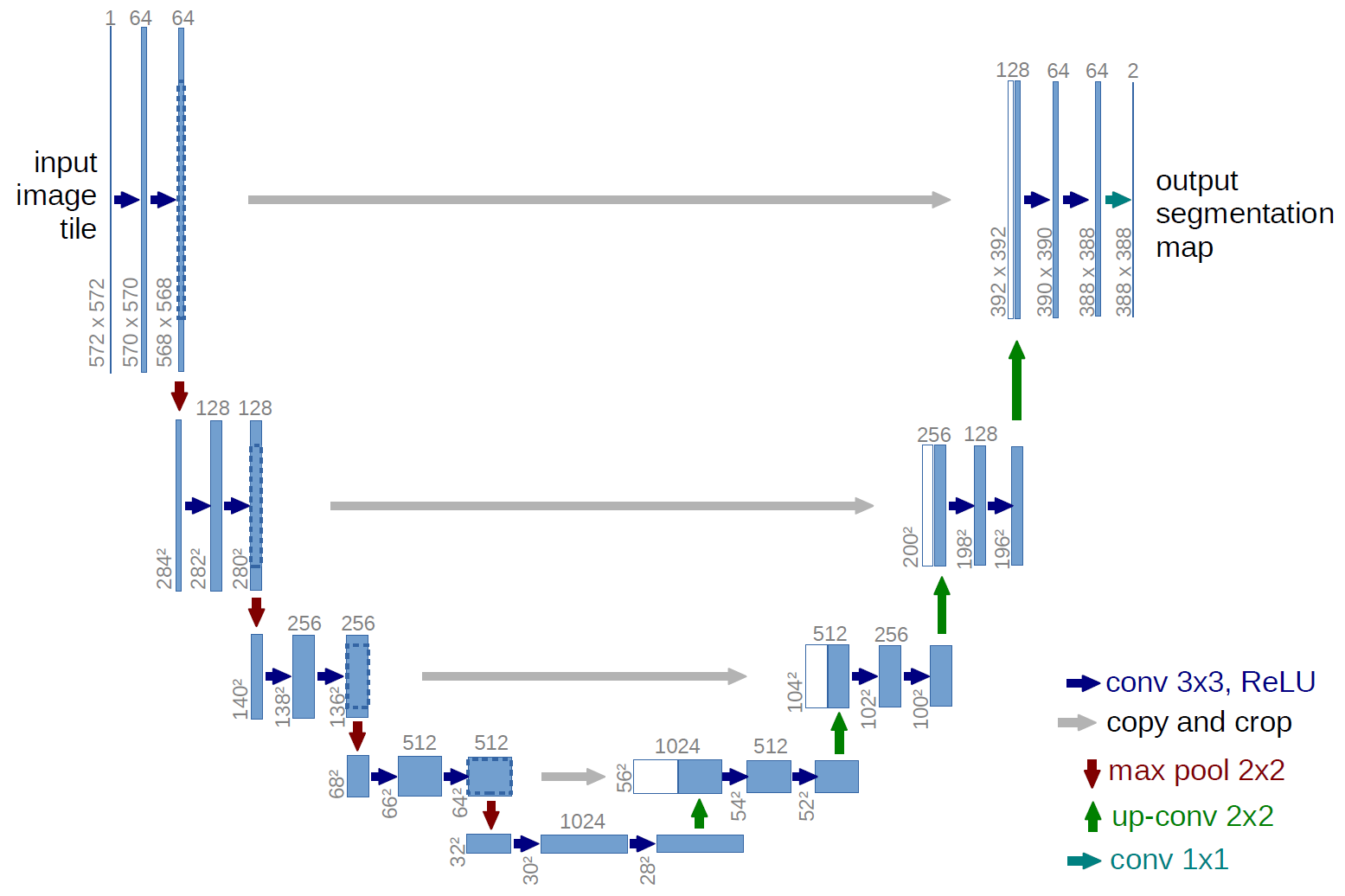
На практике часто использовалась для детектирования изображения. В нашем же случае она немного поменялась, чтобы научиться работать с t.
Парочка интересных моментов:
def __init__( self, in_channels, out_channels, T, steps=(1, 2, 4), hid_size = 128, attn_step_indexes = [1], has_residuals=True, num_resolution_blocks=2, is_debug = False ): На входе мы указываем steps: это кол-во слоев downscale и upscale(смотрим на картинку выше), где каждый элемент — общее число ResnetBlock на этом уровне. Также указываем слои с Attention(который всем нужен), чтобы ускорить обучение модели.
Для самого t, мы создаем embedding:
self.time_embedding = nn.Sequential( PositionalEmbedding(T=T, output_dim=hid_size), nn.Linear(hid_size, time_emb_dim), nn.ReLU(), nn.Linear(time_emb_dim, time_emb_dim) ) И этот embedding мы будем прокидывать во все ResNet блоки при прохождении данных:
time_emb = self.time_embedding(t) x = self.first_conv(x) hx = [] for down_block in self.down_blocks: x = down_block(x, time_emb) if not isinstance(down_block, DownBlock): hx.append(x) x = self.backbone(x, time_emb) А вот как выглядит этот код внутри Resnet блока:
h = self.conv_1(x) if t is None: return self.conv_3(x) + self.conv_2(h) t = self.time_emb(t) batch_size, emb_dim = t.shape t = t.view(batch_size, emb_dim, 1, 1) if self.is_residual: return self.conv_3(x) + self.conv_2(h + t) else: return self.conv_2(h + t) Как видно эмбеддинг времени просто суммируется с внутренним представлением x, пропущенного через Convolutional слой. Но можно найти примеры, где обработка t происходит по-другому.
Результаты
ЭХЕЙ, можем поздравить друг друга! Есть кто еще живой?

Во-первых, спасибо, что прочитали. Я очень рад, что смог сам пройти этот путь осознания с нуля, но главное попытаться донести это в более простой форме для других.
Давайте оглянемся назад и вспомним, что мы узнали:
-
Мы рассмотрели Diffusion модель с точки зрения как и почему это работает
-
Прошлись через самые дебри математики, которая в итоге нас вывела к довольно простой функции потерь
-
Разобрали основные моменты кода и переноса математики в этот код
Если сравнивать результаты модели из пейпера и моей обученной на датасете CIFAR 10, то видно, что до бенчмарков еще далековато, но визуально «на глаз» очень похоже. Я обучал примерно 5-7 часов на RTX 3090 на runpod.io. Для улучшения бенчмарков стоит увеличить обучение модели, еще раз прочекать глубину слоев UNet и возможно пройтись по оптимизациям блоков UNet.
|
Model |
FID (CIFAR 10) |
|---|---|
|
Original Diffusion |
3.17 |
|
My Diffusion |
30 |
References
-
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
-
https://calvinyluo.com/2022/08/26/diffusion-tutorial.html#mjx-eqn%3Aeq%3A79
Если вам понравилась моя статья и вам интересно читать другие материалы от меня, то приглашаю подписаться на мой ТГ канал Jurassimo Park, там я пишу заметки о разработке стартапов, немного о нейронках и других технологиях.
ссылка на оригинал статьи https://habr.com/ru/articles/860400/
Добавить комментарий