
Всем привет! Меня зовут Оксана, я ведущий системный аналитик в компании Evapps. Мне хотелось бы поделиться опытом миграции (переноса) данных. Под миграцией я имею в виду получение данных из одной системы и их сохранение в другую. Для меня эта задача была достаточно болезненна, и я допустила много ошибок в силу того, что не сталкивалась с подобным раньше. Пока боль свежа в сердце и памяти я решила написать статью, возможно, кому-то мой опыт будет полезен и позволит избежать косяков, которые были у меня.
Данная тема вызвала бурное обсуждение и споры в нашем коллективе по поводу того, что миграцию правильно делать через дамп. Возможно, так и есть. Но я считаю, что все зависит от задачи. Например, у меня сейчас одна из задач, где мы обновляем версию PostgreSQL c 9.6 до 16.3. И тут мы будем при миграции данных использовать дамп. В моей же задаче, про которую я пишу в статье, мы выбрали другие способы получения данных. Мы не могли использовать дамп, как минимум потому, что структура базы в новой и старой системах отличались.
А вы как считаете: какой способ является “правильным” и как вообще определить тот самый верный способ в таких задачах?
Немного о проекте и задаче.
У меня был госпроект. Заказчики пользовались системой на Битриксе, ее было сложно дорабатывать и поддерживать, много чего было неудобно. Нужно было разработать новую систему. Я подключилась на проект, когда уже было много чего реализовано. И перед нашей командой стояла задача: разработка новой подсистемы. На проекте была микросервисная архитектура, новая подсистема – это был отдельный микросервис. Помимо этого нужно было проработать интеграцию с SOAP-сервисом (одна из государственных информационных систем — ГИС). Пишу максимально обезличено, так как NDA.
Когда планировали задачи по проекту, мы не уделяли особого внимания переносу данных из старой системы в новую. Прорабатывали основные функции и интеграцию. Миграцию вынесли в отдельный этап, и ее проработку оставили на потом.
До реализации миграции данных мы дошли уже гораздо позже, уже после внедрения интеграции с SOAP-сервисом. И это оказалось большой ошибкой, которая нам стоила много времени и нервов.
Для наглядности накидала схему, как у нас происходило взаимодействие и откуда мы получали данные:

Часть данных мы получали из внешней системы, а часть данных из старой системы. У нас получились разные источники данных из-за особенностей бизнес-логики и хранения информации в старой системе.
С какими проблемами столкнулись
Проблема 1: типы данных

Когда мы проектировали БД на начальном этапе, мы закладывали тип данных в соответствии с тем, какие данные нам нужно было передавать во внешний сервис (ГИС). На тот момент у нас были доступы только от тестовой среды. Получение доступов к проду внешнего сервиса это была отдельная история, и получили мы их гораздо позже. Изначально была информация, что можем ориентироваться на тот тип данных, который был указан в спецификации внешнего сервиса. Мы так и сделали. Но потом, когда мы уже дошли до этапа переноса данных из внешнего сервиса в свою систему (а мигрировали данные мы уже с прода), мы столкнулись с ошибками, из-за того, что приходили данные не того типа. Например, мы заложили тип данных в бд int и ожидаем число, а приходили числа со знаками (111_222). Пришлось сверять все типы данных в соответствии с продом и править БД.
Как избежать проблему.
Если есть интеграция с внешним сервисом и в дальнейшем планируется получение данных от него, то обязательно сразу запрашивать доступ к проду и запрашивать актуальную спецификацию. И уделить внимание тому, какие типы данных планируется получать, чтобы сразу закладывать это при проектировании БД. Понятно, что это не всегда возможно, так как с получением доступов часто бывают сложности. Но в таком случае тогда сразу закладывать риски (которые повлияют на увеличение сроков реализации и бюджета проекта), что могут быть (и в 90% точно будут) расхождения и несоответствия между тестовой средой и рабочей.
Проблема 2: поддержка интеграции мигрированных записей.

Эта часть вызвала у меня наибольшее количество проблем и тут хотелось бы остановиться подробнее. Как я уже писала выше, когда я прорабатывала интеграцию с ГИС, о миграции данных мы на этом этапе даже и не думали. И я этого не учитывала. Но как только мы дошли до задачи переноса данных из внешней системы, всплыла куча косяков. Внешний сервис, с которым у нас была интеграция, имел свои особенности. При передачи данных нужно было указывать, какое действие мы совершаем с элементом: создаем новый, редактируем уже имеющийся или удаляем. Если создаем новый, то в запросе передаем id элемента из своей системы, и в ответе получаем id, присвоенный во внешней системе. Также могли быть вложенные элементы, то есть в одном запросе мы передавали информацию о родительском элементе и о вложенных в него элементах. Тут сразу хочу сказать, что этот случай очень специфичен, и связан именно с логикой работы внешнего сервиса.
Чтобы было понятнее, приведу пример с частью запроса.
<item action="update"> <!--указываем, какое действие совершаем с элементом--> <section="999"> <!--код раздела--> <data> <!--список атрибутов--> <attribute id="1"><!--код идентификатора родительского элемента во внешней системе--> <values>100</values> <!--значение идентификатора родительского элемента во внешней системе--> </attribute> <attribute id="2"><!--код идентификатора родительского элемента в нашей системе (может не заполняться, если действие update)--> <values>1</values> <!--значение идентификатора родительского элемента в нашей системе (может не заполняться, если действие update)--> </attribute> <attribute id="10"><!--код атрибута "телефон"--> <values></values> <!--значение атрибута "телефон", тут ничего не указывается, потому что имеются вложенные элементы--> </attribute> </data> </item> <parent_section="999"> <!--код родительского раздела--> <item action="update"> <section="99"> <!--код вложенного раздела (где хранятся телефоны)--> <data> <attribute id="1"><!--код идентификатора родительского элемента во внешней системе--> <values>100</values> </attribute> <attribute id="3"><!--код идентификатора дочернего элемента во внешней системе--> <values>100</values> </attribute> <attribute id="20"><!--код атрибута "телефон" в дочернем элементе--> <values>(999) 999-99-99</values> </attribute> </data> </item> <item action="added"> <section="99"> <!--код вложенного раздела (где хранятся телефоны)--> <data> <attribute id="2"><!--код идентификатора родительского элемента в нашей системе --> <values>1</values> </attribute> <attribute id="4"><!--код идентификатора дочернего элемента в нашей системе --> <values>20</values> </attribute> <attribute id="20"><!--код атрибута "телефон" в дочернем элементе--> <values>(999) 999-11-11</values> </attribute> </data> </item>Для наглядности, как это выглядело на фронте:

В нашем примере, телефон будет относится к вложенному элементу (он может иметь несколько значений). Вложенность элементов может иметь несколько уровней (такая логика была заложена у ГИС).
И вот у каждого вложенного элемента во внешней системе присваивается тоже свой идентификатор. И если при передаче изменений по вложенным элементам из нашей новой системы нам достаточно было указывать свой идентификатор, то для изменения мигрированных вложенных элементов нам обязательно нужен был идентификатор из внешней системы. Иначе бы мы не смогли корректно поддерживать интеграцию.
Во внешнем сервисе в запросе каждый атрибут имел свой код (в примере это attribute id). Например, нам нужно передать id нашей системы, id из внешней системы, телефон, почту и тд. И каждый параметр, который мы передаем имеет свой код, который указывался в запросе (эта информация вся предоставлялась от ГИС) и тд. То есть в зависимости от того, какой элемент мы передаем: мигрированный или нет, менялся запрос.
Пример для мигрированной записи:
<item action="update"> <!--указываем, какое действие совершаем с элементом--> <section="999"> <!--код раздела--> <data> <!--список атрибутов--> <attribute id="1"><!--код идентификатора родительского элемента во внешней системе--> <values>100</values> <!--значение идентификатора родительского элемента во внешней системе--> </attribute> <attribute id="2"><!--код идентификатора родительского элемента в нашей системе (может не заполняться, если действие update)--> <values>1</values> <!--значение идентификатора родительского элемента в нашей системе (может не заполняться, если действие update)--> </attribute> <attribute id="10"><!--код атрибута "телефон"--> <values></values> <!--значение атрибута "телефон", тут ничего не указывается, потому что имеются вложенные элементы--> </attribute> </data> </item> <parent_section="999"> <!--код родительского раздела--> <item action="update"> <section="99"> <!--код вложенного раздела (где хранятся телефоны)--> <data> <attribute id="1"><!--код идентификатора родительского элемента во внешней системе--> <values>100</values> </attribute> <attribute id="3"><!--код идентификатора дочернего элемента во внешней системе--> <values>100</values> </attribute> <attribute id="20"><!--код атрибута "телефон" в дочернем элементе--> <values>(999) 999-99-99</values> </attribute> </data> </item>Пример для немигрированной записи:
<item action="update"> <!--указываем, какое действие совершаем с элементом--> <section="999"> <!--код раздела--> <data> <!--список атрибутов--> <attribute id="1"><!--код идентификатора родительского элемента во внешней системе--> <values>100</values> <!--значение идентификатора родительского элемента во внешней системе--> </attribute> <attribute id="2"><!--код идентификатора родительского элемента в нашей системе (может не заполняться, если действие update)--> <values>1</values> <!--значение идентификатора родительского элемента в нашей системе (может не заполняться, если действие update)--> </attribute> <attribute id="10"><!--код атрибута "телефон"--> <values></values> <!--значение атрибута "телефон", тут ничего не указывается, потому что имеются вложенные элементы--> </attribute> </data> </item> <parent_section="999"> <!--код родительского раздела--> <item action="added"> <section="99"> <!--код вложенного раздела (где хранятся телефоны)--> <data> <attribute id="2"><!--код идентификатора родительского элемента в нашей системе --> <values>1</values> </attribute> <attribute id="4"><!--код идентификатора дочернего элемента в нашей системе --> <values>20</values> </attribute> <attribute id="20"><!--код атрибута "телефон" в дочернем элементе--> <values>(999) 111-11-11</values> </attribute> </data> </item>То есть для корректной интеграции мигрированных записей необходимо было использовать разные атрибуты, потому что в одном случае нам нужно передавать идентификаторы внешней системы, а в другом свои.
Тут нам пришлось делать много правок.
1. Мы опять правили базу. Данные хранили в json. Нужно было хранить еще идентификаторы нашей системы и внешней. Приведу пример с телефоном (дочерние элементы). Было так:
["(999) 999-99-99","(111) 111-11-11"]Стало так:
[{"id":1,"childExtId":"6","value":"(999)999-99-99","isDeleted":false,"isDeletedGisEhd":false}, {"id":2,"childExtId":"119","value":"(111)111-11-11","isDeleted":false,"isDeletedGis":false}]2. Нужно было вносить правку в интеграцию и формировать структуру запроса в соответствии с типом записей.
А еще надо было учесть, что основной элемент может быть мигрирован, но вложенные в него элементы могут быть не мигрированы (как в примере выше). То есть для мигрированной записи сочетание атрибутов было: <attribute id=»1″> и <attribute id=»3″>. А для не мигрированной: <attribute id=»2″> и <attribute id=»4″>.
3. Нужно было дорабатывать текущие методы в нашей системе, потому что мы добавляли новые параметры.
4. Нужно было вносить правки на фронте, т.к. нам нужно было определять, какие вложенные элементы добавились новые, а какие изменялись, какие удалялись.
В общем эта часть была самой сложной и интересной. Это все было связано с особенностями внешнего сервиса, в другом случае при миграции данных таких нюансов скорее всего и не возникнет.
Как избежать проблему: если есть интеграция с какими-либо внешними сервисами, то стоит проверить, а всего ли будет хватать для поддержания интеграции мигрированных записей: проверить, будет ли отличаться запрос, какие идентификаторы будут нужны, достаточно ли данных в БД. И самое важное, сделать это нужно до проработки интеграции (желательно на этапе проектирования модели хранения данных).
Проблема 3: не учли, что в старой системе была ежедневная отправка данных во внешнюю систему.

Мы мигрировали часть данных, проверили, отдали заказчикам, и они уже активно пользовались новой системой (выводили в прод мы по частям). Потом ко мне приходит бизнес и говорит, что внесли изменения, передали во внешнюю систему, а на следующий день во внешней системе старые данные. Начали разбираться: я пошла к тех поддержке внешнего сервиса, они начали разбирать логи. В итоге оказалось, что старая система продолжает отправлять данные (а пользовали в старой системе с этими данным не работали, тк мы закрыли им доступ, потому что перешли в новую систему). Я пошла к разработчику, который поддерживал старую систему и выяснилось, что ежедневно по крону происходит автоматическая отправка данных во внешнюю систему. Ее в итоге отключили и все пришло в норму.
Как избежать проблему: проверить, какие есть интеграции в старой системе и есть ли автоматическая отправка данных. Если есть, то после того, как происходит переход в новую систему, необходимо отключить интеграции в старой системе.
По этому пункту мы долго спорили с коллегами, когда обсуждали эту тему. Кто-то говорит, что такого случиться в принципе не должно, потому что после миграции все должны пользоваться новой системой. И это действительно так, и я с этим согласна. Но у меня был вот именно такой опыт, и я тоже понимаю, почему так произошло. Была огромная система. Мы переводили пользователей в новую систему в несколько итераций (по мере разработки и внедрения подсистем). Схема была такая:
1. Провели демонстрацию функциональности пользователям на препроде
2. Получили согласование на запуск в прод
3. Выкатили в прод
4. Сделали миграцию данных и сверку
5. Отключили доступ пользователям в старой системе
6. Выдали доступ пользователям в новую систему
И к сожалению, в нашем случае помимо отключения доступов (п 5 ) в старой системе, нужно было еще отключить все автоматические отправки данных во внешний сервис. А об этом никто не знал, и узнали вот при тех обстоятельствах, которые я описала в проблеме.
Проблема 4: в результате миграции были перенесены не все данные.

После каждой миграции я проводила сверку данных. Честно сказать, то еще удовольствие. И для некоторых разделов были расхождения в количестве записей. Не сильно много, но было. На тот момент, я определяла каких записей не хватает и ручками создавала их в новой системе и добавляла в базе нужные данные.
Как избежать проблему: предусмотреть возможность миграции конкретных записей. Например, изначально у нас был метод (api), который запускал миграцию по всем данным для каждого раздела. Потом мы доработали и добавили параметр с идентификатором, с помощью которого можно было мигрировать конкретные записи и не запускать заново получение всех записей.
Пример: изначально был API на получение всех данных POST
/site/api/v1/migration/some-dataМы добавили возможность получения конкретных данных по идентификатору (в теле запроса):
POST /site/api/v1/migration/some-data Body: localId (array) Пример: [1, 2, 3 ]Проблема 5: версионирование записей.
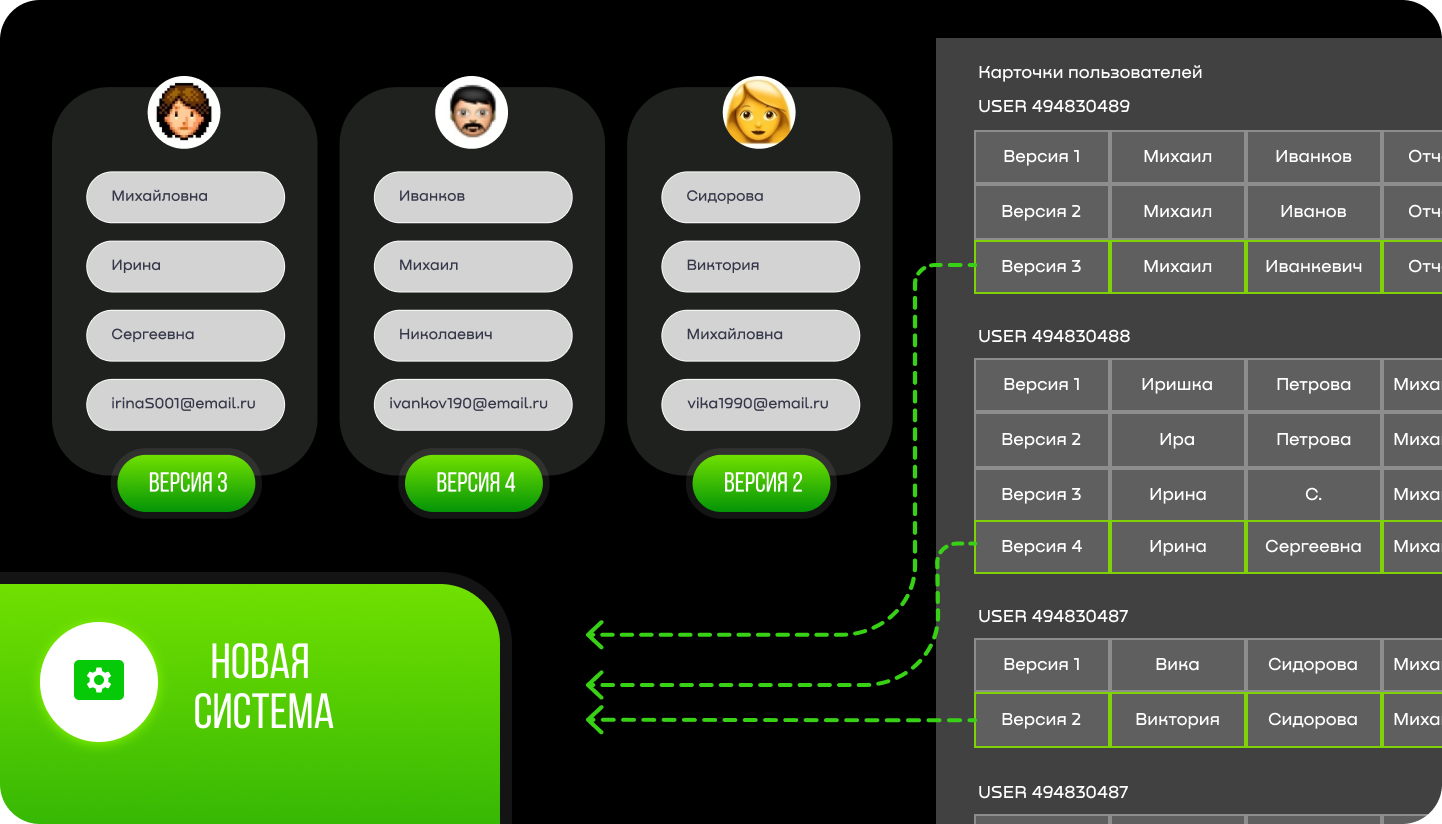
В моей подсистеме (микросервис “А”) часть данных мы получали из микросервиса “Б” (см схему). В микросервисе “Б” было версионирование записей. Когда я прорабатывала миграцию, я это не учла (чисто мой косяк, потому что не особо хорошо знала другой микросервис и логику работы в нем). В итоге после миграции ничего не работало, так как не была заполнена в БД таблица с версиями. Тут у нас было нестандартное решение проблемы. Разработчики были заняты, а нам срочно нужно было исправлять ситуацию. Нам помог тестировщик. Я подготовила эксель файлы с данными (это то, что мы планировали получать от ГИС), он написал автотесты, которые в нужной последовательности запускают методы микросервиса “Б” (где есть версионирование). Потом осталось только в бд проставить нужные признаки, что все корректно заработало. И так мы смогли мигрировать еще часть данных. И все заработало.
Как избежать проблему: проверить, есть ли версионирование в системе и учитывать это при миграции данных. Как можно проверить: посмотреть сами в БД, изучить документацию, спросить у коллег.
Вот такие ошибки я допустила во время этой задачи. Мне, как аналитику, эта задача была очень интересна, но некоторые проблемы для меня были неочевидны. Сейчас-то я уже понимаю, на что в следующий раз буду обращать внимание и что буду с этим делать. Но на тот момент мне не хватило опыта работы с подобными задачами. Плюс ко всему, осложнялось все получением доступов к проду внешнего сервиса, отсутствием полной актуальной информации по его работе, процессом планирования задач, свободными ресурсами. Но тем не менее это был очень крутой опыт, мы в итоге получили нужный результат, пользователи активно работают с новой системой, все работает корректно и сейчас мы с разработчиком радуемся, что полностью сдали этот проект.
Для себя решила составить пошаговый план по работе с такими задачами и на что обращать внимание в следующий раз.
-
При разработке новой системы взамен старой сразу уточнять: планируется ли миграция данных.
-
Определить каким образом планируется получение данных: из старой системы или еще каких-либо источников.
-
Определить, какие данные нужно получать и их тип.
-
При проектировании БД заложить нужные типы и поля, добавить поля с признаком мигрированной записи (чтобы можно было определять такие записи).
-
Проверить есть ли интеграции и будет ли отличаться интеграция для мигрированных и не мигрированных записей.
-
Проверить, есть ли версионирование записей. Если есть, определить все таблицы, в которые необходимо будет «складывать» данные.
-
Перед миграцией договориться с пользователями и остановить все работы в старой системе на время переноса и сверки данных.
-
Реализовать возможность получения конкретных данных (например, по идентификатору).
-
Если в старой системе есть интеграция с внешними сервисами и автоматическая передача данных, то после перехода в новую систему отключить ее.
-
Разбивать миграцию данных на части.
-
Перед миграцией данных договориться с девопсом, чтобы он был на связи. Если вдруг что-то пойдет не так и упадет сервер, чтобы была возможность оперативно восстановить работу.
-
Подробное логирование (какой запрос отправляем, что получаем в ответе и тд). Чтобы была возможность определить на каком этапе возникла ошибка и проанализировать данные.
-
Делать для себя пометки и шпаргалки, чтобы в случае повторной миграции можно было быстро вспомнить последовательность действий.
На этом все. Буду благодарна, если поделитесь своим опытом и с какими проблемами при миграции данных сталкивались вы, и как их решали. Спасибо за уделенное время 😊
ссылка на оригинал статьи https://habr.com/ru/articles/862324/
Добавить комментарий